Zelfstudie deel 2: Gegevens verkennen en visualiseren met Behulp van Microsoft Fabric-notebooks
In deze zelfstudie leert u hoe u experimentele gegevensanalyse (EDA) uitvoert om de gegevens te onderzoeken en te onderzoeken terwijl u de belangrijkste kenmerken ervan samenvat door gebruik te maken van technieken voor gegevensvisualisatie.
U gebruikt seaborn, een Python-bibliotheek voor gegevensvisualisatie die een interface op hoog niveau biedt voor het bouwen van visuals op gegevensframes en matrices. Zie Seaborn: Visualisatie van statistische gegevensvoor meer informatie over seaborn.
U gebruikt ook Data Wrangler, een hulpprogramma op basis van een notebook dat u een meeslepende ervaring biedt voor het uitvoeren van verkennende gegevensanalyse en het opschonen van gegevens.
De belangrijkste stappen in deze zelfstudie zijn:
- Lees de gegevens die zijn opgeslagen uit een deltatabel in het Lakehouse.
- Converteer een Spark DataFrame naar Pandas DataFrame, dat door Python-visualisatiebibliotheken wordt ondersteund.
- Gebruik Data Wrangler om initiële gegevens op te schonen en te transformeren.
- Experimentele gegevensanalyse uitvoeren met behulp van
seaborn.
Voorwaarden
Een Microsoft Fabric-abonnementophalen. Of meld u aan voor een gratis microsoft Fabric-proefversie.
Meld u aan bij Microsoft Fabric-.
Gebruik de ervaringswisselaar aan de linkerkant van de startpagina om over te schakelen naar Fabric.

Dit is deel 2 van 5 in de reeks zelfstudies. Als u deze zelfstudie wilt voltooien, moet u eerst het volgende voltooien:
Volg mee in het notitieboekje
2-explore-cleanse-data.ipynb is het notebook dat bij deze zelfstudie hoort.
Als u het bijbehorende notitieblok voor deze zelfstudie wilt openen, volgt u de instructies in Uw systeem voorbereiden op zelfstudies voor gegevenswetenschap om het notebook in uw werkruimte te importeren.
Als u liever de code van deze pagina kopieert en plakt, kunt u een nieuw notitieblok maken.
Zorg ervoor dat u een lakehouse aan het notebook koppelt voordat u begint met het uitvoeren van code.
Belangrijk
Koppel hetzelfde lakehouse dat u in deel 1 hebt gebruikt.
Onbewerkte gegevens lezen uit het lakehouse
Lees onbewerkte gegevens uit de sectie Files van het lakehouse. U hebt deze gegevens geüpload in het vorige notitieblok. Zorg ervoor dat u hetzelfde lakehouse dat u in deel 1 hebt gebruikt aan dit notebook hebt gekoppeld voordat u deze code uitvoert.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Een Pandas DataFrame maken op basis van de gegevensset
Converteer het Spark DataFrame naar pandas DataFrame voor eenvoudigere verwerking en visualisatie.
df = df.toPandas()
Onbewerkte gegevens weergeven
Verken de onbewerkte gegevens met display, voer enkele basisstatistieken uit en toon grafiekweergaven. U moet eerst de vereiste bibliotheken importeren, zoals Numpy, Pnadas, Seabornen Matplotlib voor gegevensanalyse en visualisatie.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Data Wrangler gebruiken om initiële gegevens op te schonen
Als u pandas Dataframes in uw notebook wilt verkennen en transformeren, start u Data Wrangler rechtstreeks vanuit het notebook.
Notitie
Data Wrangler kan niet worden geopend terwijl de notebook-kernel bezet is. De uitvoering van de cel moet worden voltooid voordat Data Wrangler wordt gestart.
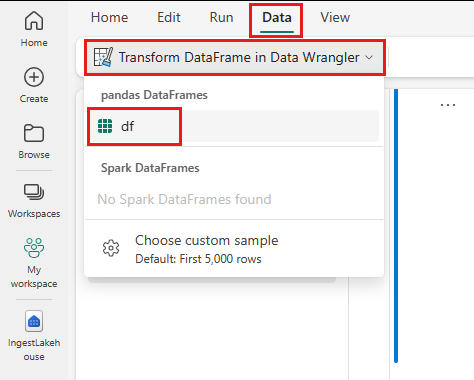
- Selecteer op het lint van het notitieblok het tabblad Gegevens en kies Data Wrangler starten. U ziet een lijst met geactiveerde pandas DataFrames die beschikbaar zijn voor bewerking.
- Selecteer het DataFrame dat u wilt openen in Data Wrangler. Omdat dit notebook slechts één DataFrame bevat,
df, selecteert udf.
Data Wrangler wordt gestart en genereert een beschrijvend overzicht van uw gegevens. In de tabel in het midden ziet u elke gegevenskolom. Het deelvenster Samenvatting naast de tabel bevat informatie over het DataFrame. Wanneer u een kolom in de tabel selecteert, wordt de samenvatting bijgewerkt met informatie over de geselecteerde kolom. In sommige gevallen zijn de weergegeven en samengevatte gegevens een afgekapte weergave van uw DataFrame. Als dit gebeurt, ziet u een waarschuwingsafbeelding in het samenvattingsvenster. Beweeg de muisaanwijzer over deze waarschuwing om tekst weer te geven waarin de situatie wordt uitgelegd.

Elke bewerking die u uitvoert, kan worden toegepast in een kwestie van klikken, het in realtime bijwerken van de gegevensweergave en het genereren van code die u als herbruikbare functie kunt opslaan in uw notitieblok.
In de rest van deze sectie wordt u begeleid bij de stappen voor het opschonen van gegevens met Data Wrangler.
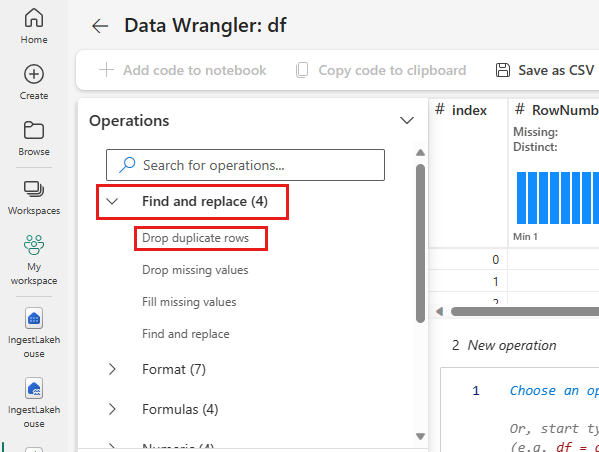
Dubbele rijen verwijderen
In het linkerdeelvenster ziet u een lijst met bewerkingen (zoals Zoeken en vervangen, Format, Formulas, Numerieke) die u kunt uitvoeren op de gegevensset.
Vouw Zoeken en Vervangen uit en selecteer Dubbele Rijen Verwijderen.
Er wordt een deelvenster weergegeven om de lijst met kolommen te selecteren die u wilt vergelijken om een dubbele rij te definiëren. Selecteer RowNumber en CustomerId.
In het middelste deelvenster ziet u een voorbeeld van de resultaten van deze bewerking. Onder de preview is de code voor het uitvoeren van de bewerking. In dit geval lijken de gegevens ongewijzigd te zijn. Maar omdat u een afgekapte weergave bekijkt, is het een goed idee om de bewerking nog steeds toe te passen.
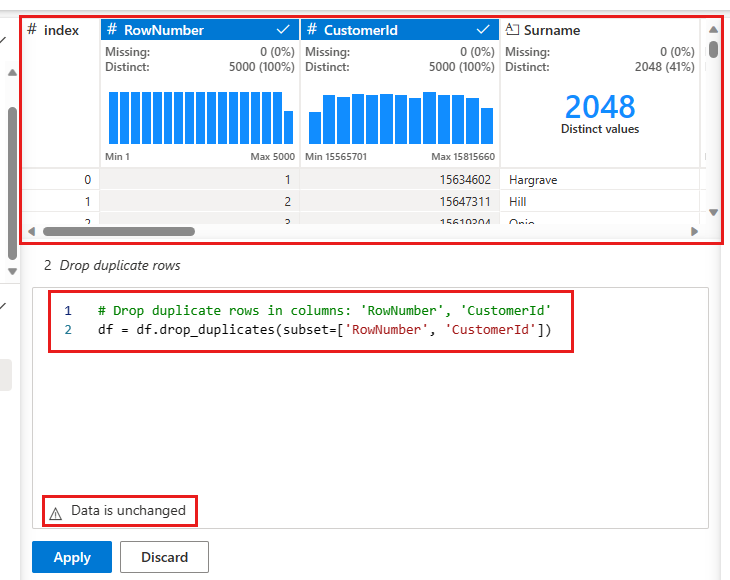
Selecteer Toepassen (aan de zijkant of onderaan) om naar de volgende stap te gaan.

Rijen verwijderen met ontbrekende gegevens
Gebruik Data Wrangler om rijen met ontbrekende gegevens in alle kolommen te verwijderen.
Selecteer Ontbrekende waarden verwijderen van Zoeken en vervangen.
Kies Alle selecteren in de doelkolommen.
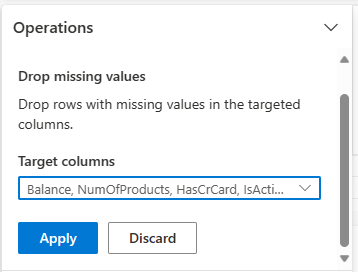
Klik op Toepassen om door te gaan naar de volgende stap.

Kolommen verwijderen
Gebruik Data Wrangler om kolommen te verwijderen die u niet nodig hebt.
Vouw Schema uit en selecteer Kolommen verwijderen.
Selecteer RowNumber, CustomerId, Achternaam. Deze kolommen worden rood weergegeven in het voorbeeld om te laten zien dat ze worden gewijzigd door de code (in dit geval verwijderd.)
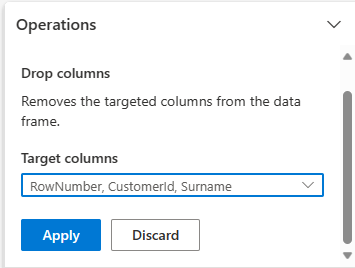
Selecteer , klik op Toepassen om verder te gaan met de volgende stap.

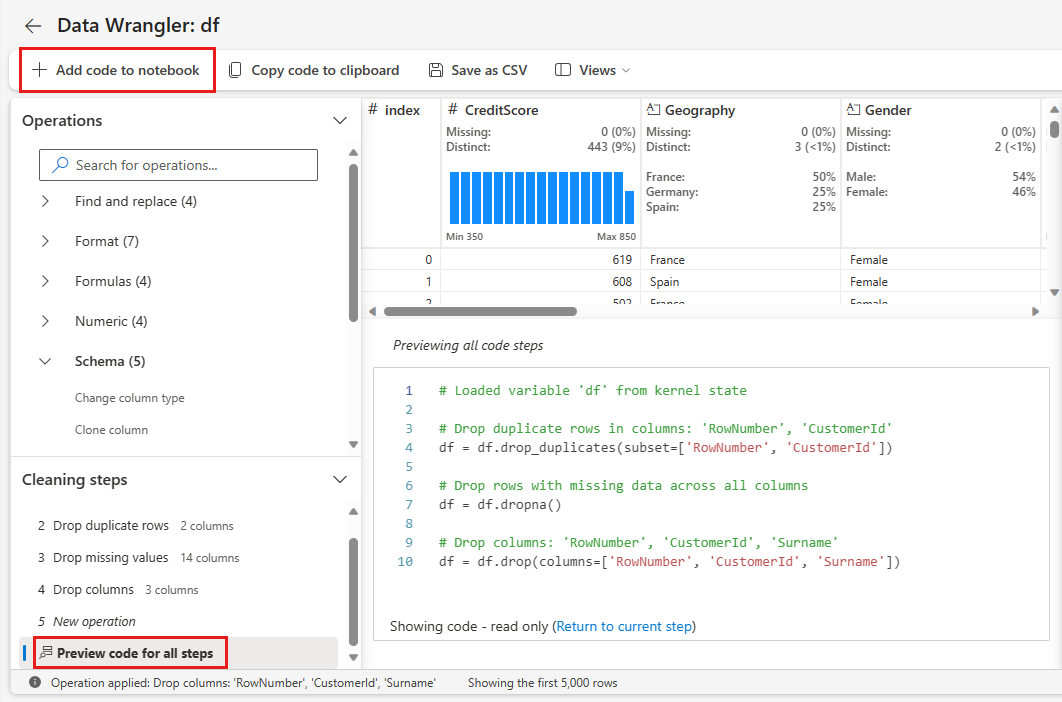
Code toevoegen aan notebook
Telkens wanneer u Toepassenselecteert, wordt er een nieuwe stap gemaakt in de stappen voor opschonen deelvenster linksonder. Selecteer onderaan het deelvenster Preview-code voor alle stappen om een combinatie van alle afzonderlijke stappen weer te geven.
Selecteer Code toevoegen aan notebook linksboven om Data Wrangler te sluiten en de code automatisch toe te voegen. De Code toevoegen aan notebook verpakt de code in een functie en roept vervolgens die functie aan.
Tip
De code die door Data Wrangler wordt gegenereerd, wordt pas toegepast wanneer u de nieuwe cel handmatig uitvoert.
Als u Data Wrangler niet hebt gebruikt, kunt u in plaats daarvan deze volgende codecel gebruiken.
Deze code is vergelijkbaar met de code die wordt geproduceerd door Data Wrangler, maar voegt het argument toe inplace=True aan elk van de gegenereerde stappen. Door inplace=Truein te stellen, overschrijft Pandas het oorspronkelijke DataFrame in plaats van een nieuw DataFrame als uitvoer te produceren.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
De gegevens verkennen
Enkele samenvattingen en visualisaties van de opgeschoonde gegevens weergeven.
Categorische, numerieke en doelkenmerken bepalen
Gebruik deze code om categorische, numerieke en doelkenmerken te bepalen.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
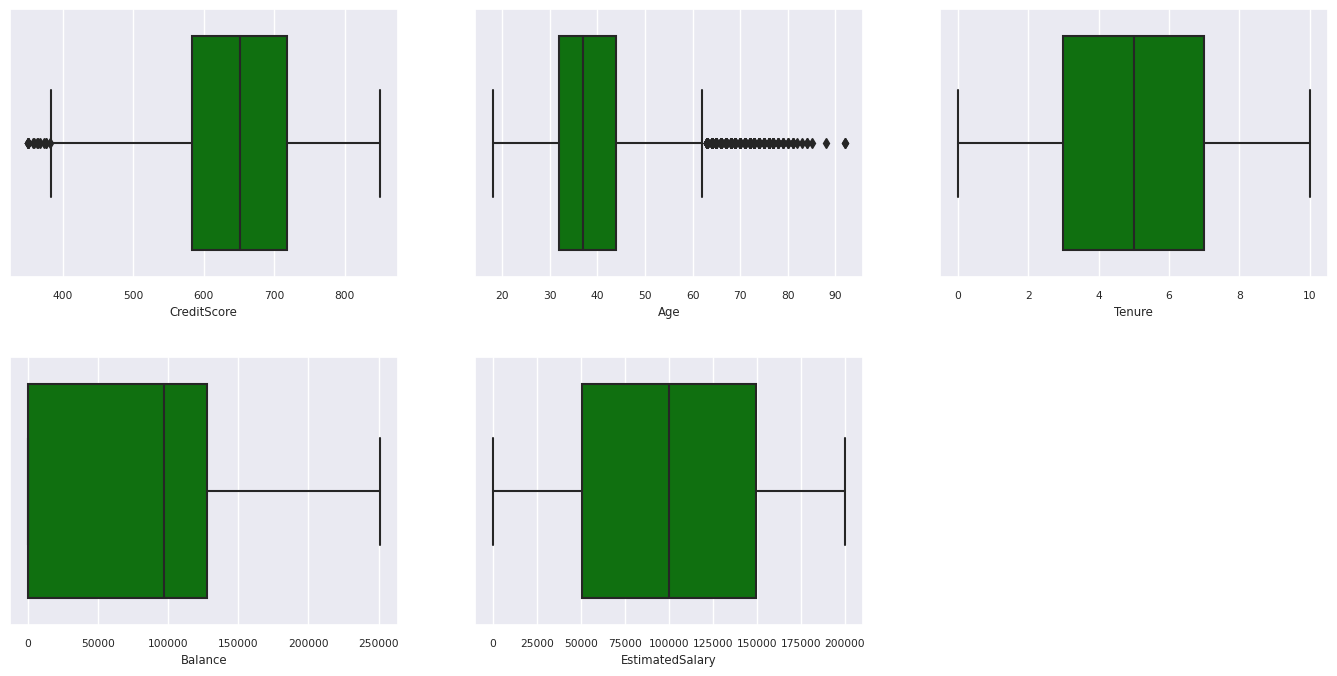
Het overzicht van vijf getallen
Geef de samenvatting van vijf getallen weer (de minimumscore, het eerste kwartiel, de mediaan, het derde kwartiel, de maximumscore) voor de numerieke kenmerken, met behulp van boxplots.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
Distributie van vertrokken en gebleven klanten
De distributie van vertrokken versus niet-vertrokken klanten weergeven over de categorische attributen.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)

Verdeling van numerieke kenmerken
De frequentieverdeling van numerieke kenmerken weergeven met behulp van histogram.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Functie-engineering uitvoeren
Functie-engineering uitvoeren om nieuwe kenmerken te genereren op basis van huidige kenmerken:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Data Wrangler gebruiken om one-hot codering uit te voeren
Data Wrangler kan ook worden gebruikt om one-hot codering uit te voeren. Hiervoor opent u Data Wrangler opnieuw. Selecteer deze keer de df_clean gegevens.
- Vouw Formules uit en selecteer one hot encode.
- Er verschijnt een deelvenster waarmee u de lijst met kolommen kunt selecteren waarop u one-hot encoding wilt uitvoeren. Selecteer Geografie en Geslacht.
U kunt de gegenereerde code kopiëren, Data Wrangler sluiten om terug te keren naar het notebook en vervolgens in een nieuwe cel plakken. Of selecteer Code toevoegen aan notebook linksboven om Data Wrangler te sluiten en de code automatisch toe te voegen.
Als u Data Wrangler niet hebt gebruikt, kunt u in plaats daarvan deze volgende codecel gebruiken:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Samenvatting van waarnemingen van de verkennende gegevensanalyse
- De meeste klanten zijn van Frankrijk vergeleken met Spanje en Duitsland, terwijl Spanje het laagste verlooppercentage heeft vergeleken met Frankrijk en Duitsland.
- De meeste klanten hebben creditcards.
- Er zijn klanten met een leeftijds- en kredietscore van meer dan 60 en minder dan 400, maar ze kunnen niet worden beschouwd als uitbijters.
- Zeer weinig klanten hebben meer dan twee van de producten van de bank.
- Klanten die niet actief zijn, hebben een hoger verlooppercentage.
- Geslachts- en dienstjaren lijken geen invloed te hebben op de beslissing van de klant om de bankrekening te sluiten.
Een deltatabel maken voor de opgeschoonde gegevens
Je gebruikt deze gegevens in het volgende notitieblok van deze reeks.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Volgende stap
Machine Learning-modellen trainen en registreren met deze gegevens: