Apache Spark-bibliotheken beheren in Microsoft Fabric
Een bibliotheek is een verzameling vooraf geschreven code die ontwikkelaars kunnen importeren om functionaliteit te bieden. Door bibliotheken te gebruiken, kunt u tijd en moeite besparen door geen volledig nieuwe code te schrijven om algemene taken uit te voeren. Importeer in plaats daarvan de bibliotheek en gebruik de bijbehorende functies en klassen om de gewenste functionaliteit te bereiken. Microsoft Fabric biedt meerdere mechanismen om bibliotheken te beheren en te gebruiken.
- Ingebouwde bibliotheken: Elke Fabric Spark-runtime biedt een uitgebreide set populaire vooraf geïnstalleerde bibliotheken. U vindt de volledige ingebouwde bibliotheeklijst in Fabric Spark Runtime.
- Openbare bibliotheken: openbare bibliotheken zijn afkomstig uit opslagplaatsen zoals PyPI en Conda, die momenteel worden ondersteund.
- Aangepaste bibliotheken: Aangepaste bibliotheken verwijzen naar code die u of uw organisatie bouwt. Fabric ondersteunt ze in de indelingen .whl, .jar en .tar.gz . Fabric ondersteunt alleen .tar.gz voor de R-taal. Voor aangepaste Python-bibliotheken gebruikt u de .whl-indeling .
Samenvatting van aanbevolen procedures voor bibliotheekbeheer
In de volgende scenario's worden aanbevolen procedures beschreven bij het gebruik van bibliotheken in Microsoft Fabric.
Scenario 1: Beheerder stelt standaardbibliotheken in voor de werkruimte
Als u standaardbibliotheken wilt instellen, moet u de beheerder van de werkruimte zijn. Als beheerder kunt u deze taken uitvoeren:
- Een nieuwe omgeving maken
- De vereiste bibliotheken installeren in de omgeving
- Deze omgeving koppelen als de standaardinstelling voor de werkruimte
Wanneer uw notebooks en Spark-taakdefinities zijn gekoppeld aan de werkruimte-instellingen, starten ze sessies met de bibliotheken die zijn geïnstalleerd in de standaardomgeving van de werkruimte.
Scenario 2: Bibliotheekspecificaties behouden voor een of meer code-items
Als u algemene bibliotheken voor verschillende code-items hebt en niet regelmatig moet worden bijgewerkt, installeert u de bibliotheken in een omgeving en koppelt u deze aan de code-items .
Het duurt enige tijd om de bibliotheken in omgevingen effectief te maken bij het publiceren. Het duurt normaal gesproken 5-15 minuten, afhankelijk van de complexiteit van de bibliotheken. Tijdens dit proces helpt het systeem bij het oplossen van de mogelijke conflicten en het downloaden van vereiste afhankelijkheden.
Een voordeel van deze aanpak is dat de geïnstalleerde bibliotheken gegarandeerd beschikbaar zijn wanneer de Spark-sessie wordt gestart met de omgeving die is gekoppeld. Het bespaart moeite om algemene bibliotheken voor uw projecten te onderhouden.
Het wordt ten zeerste aanbevolen voor pijplijnscenario's met de stabiliteit.
Scenario 3: Inline-installatie in interactieve uitvoering
Als u de notebooks gebruikt om interactief code te schrijven, kunt u met behulp van inline-installatie extra nieuwe PyPI/conda-bibliotheken toevoegen of uw aangepaste bibliotheken valideren voor eenmalig gebruik. Met inlineopdrachten in Fabric kunt u de bibliotheek effectief hebben in de huidige Spark-sessie van het notebook. Hiermee kan de snelle installatie worden uitgevoerd, maar de geïnstalleerde bibliotheek blijft niet behouden in verschillende sessies.
Omdat %pip install het genereren van verschillende afhankelijkheidsstructuren van tijd tot tijd kan leiden tot bibliotheekconflicten, worden inlineopdrachten standaard uitgeschakeld in de pijplijnuitvoeringen en WORDT NIET aanbevolen om te worden gebruikt in uw pijplijnen.
Overzicht van ondersteunde bibliotheektypen
| Bibliotheektype | Omgevingsbibliotheekbeheer | Inline-installatie |
|---|---|---|
| Python Public (PyPI & Conda) | Ondersteund | Ondersteund |
| Python Custom (.whl) | Ondersteund | Ondersteund |
| R Public (CRAN) | Niet ondersteund | Ondersteund |
| Aangepaste R (.tar.gz) | Ondersteund als aangepaste bibliotheek | Ondersteund |
| Pot | Ondersteund als aangepaste bibliotheek | Ondersteund |
Inline-installatie
Inlineopdrachten ondersteunen het beheren van bibliotheken in elke notebooksessies.
Inline-installatie van Python
Het systeem start de Python-interpreter opnieuw op om de wijziging van bibliotheken toe te passen. Variabelen die zijn gedefinieerd voordat u de opdrachtcel uitvoert, gaan verloren. We raden u ten zeerste aan om alle opdrachten voor het toevoegen, verwijderen of bijwerken van Python-pakketten aan het begin van uw notebook te plaatsen.
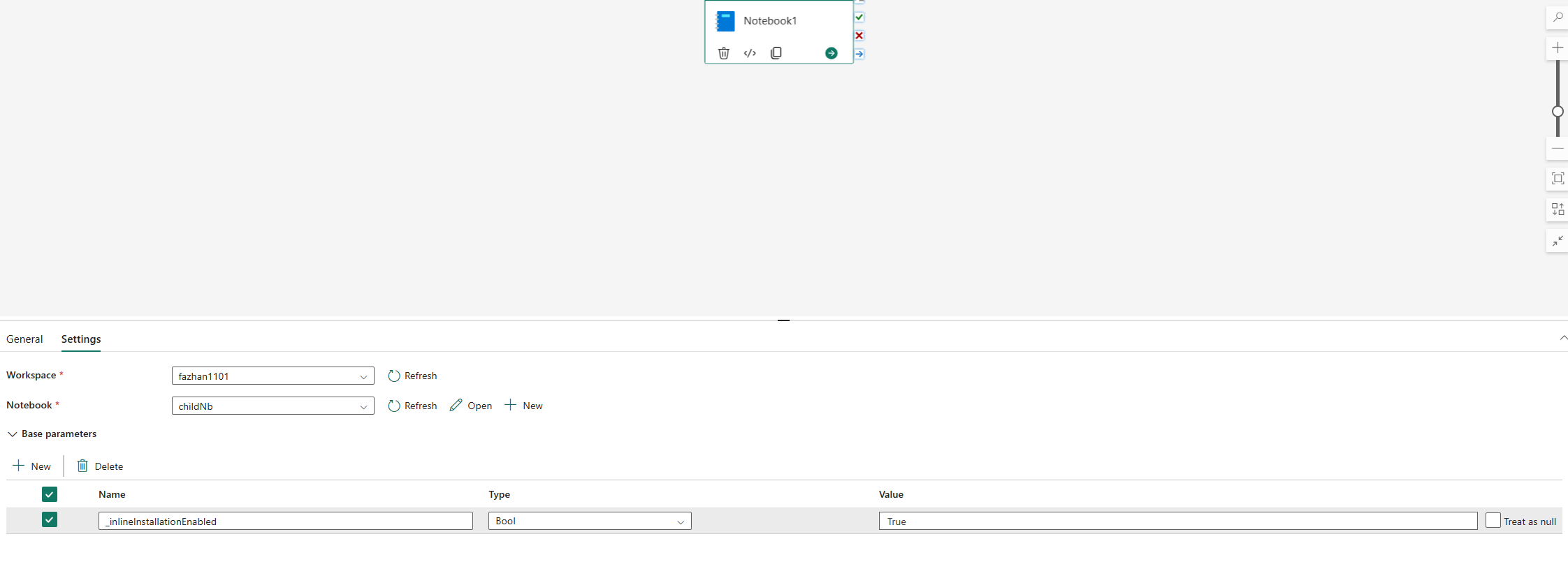
De inlineopdrachten voor het beheren van Python-bibliotheken zijn standaard uitgeschakeld in de notebook-pijplijn. Als u pijplijn wilt inschakelen %pip install , voegt u '_inlineInstallationEnabled' toe als boolparameter is gelijk aan Waar in de notebookactiviteitsparameters.
Notitie
Dit %pip install kan leiden tot inconsistente resultaten van tijd tot tijd. Het is raadzaam om bibliotheek in een omgeving te installeren en deze in de pijplijn te gebruiken.
In notebookreferentieuitvoeringen worden inlineopdrachten voor het beheren van Python-bibliotheken niet ondersteund. Om ervoor te zorgen dat de uitvoering correct is, wordt u aangeraden deze inlineopdrachten uit het notebook waarnaar wordt verwezen te verwijderen.
We raden u aan %pip in plaats van !pip. !pip is een ingebouwde IPython-shell-opdracht, die de volgende beperkingen heeft:
!pipinstalleert alleen een pakket op het stuurprogrammaknooppunt, niet op uitvoerknooppunten.- Pakketten die worden
!pipgeïnstalleerd, hebben geen invloed op conflicten met ingebouwde pakketten of of pakketten al in een notebook zijn geïmporteerd.
%pip Verwerkt deze scenario's echter. Bibliotheken die %pip via zijn geïnstalleerd, zijn beschikbaar op zowel stuurprogramma- als uitvoerknooppunten en zijn nog steeds effectief, zelfs als de bibliotheek al is geïmporteerd.
Tip
De %conda install opdracht duurt meestal langer dan de %pip install opdracht om nieuwe Python-bibliotheken te installeren. Hiermee worden de volledige afhankelijkheden gecontroleerd en conflicten opgelost.
Mogelijk wilt u deze gebruiken %conda install voor meer betrouwbaarheid en stabiliteit. U kunt gebruiken %pip install als u zeker weet dat de bibliotheek die u wilt installeren, geen conflict veroorzaakt met de vooraf geïnstalleerde bibliotheken in de runtime-omgeving.
Zie %pip-opdrachten en %conda-opdrachten voor alle beschikbare inlineopdrachten en verduidelijkingen van Python.
Openbare Python-bibliotheken beheren via inline-installatie
In dit voorbeeld ziet u hoe u inlineopdrachten gebruikt om bibliotheken te beheren. Stel dat u trap, een krachtige visualisatiebibliotheek voor Python, wilt gebruiken voor een eenmalige gegevensverkenning. Stel dat de bibliotheek niet is geïnstalleerd in uw werkruimte. In het volgende voorbeeld worden conda-opdrachten gebruikt om de stappen te illustreren.
U kunt inlineopdrachten gebruiken om trap in te schakelen op uw notebooksessie zonder dat dit van invloed is op andere sessies van het notitieblok of andere items.
Voer de volgende opdrachten uit in een notebookcodecel. Met de eerste opdracht wordt de altair-bibliotheek geïnstalleerd. Installeer ook vega_datasets, dat een semantisch model bevat dat u kunt gebruiken om te visualiseren.
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda commandDe uitvoer van de cel geeft het resultaat van de installatie aan.
Importeer het pakket en het semantische model door de volgende code uit te voeren in een andere notebookcel.
import altair as alt from vega_datasets import dataU kunt nu spelen met de bibliotheek met sessiebereik.
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
Aangepaste Python-bibliotheken beheren via inline-installatie
U kunt uw aangepaste Python-bibliotheken uploaden naar de map resources van uw notebook of de gekoppelde omgeving. De resourcesmappen zijn het ingebouwde bestandssysteem dat door elke notebook en omgeving wordt geleverd. Zie Notebook-resources voor meer informatie. Nadat u de bibliotheek hebt geüpload, kunt u de aangepaste bibliotheek slepen en neerzetten naar een codecel. De inlineopdracht voor het installeren van de bibliotheek wordt automatisch gegenereerd. U kunt ook de volgende opdracht gebruiken om te installeren.
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
R inline-installatie
Voor het beheren van R-bibliotheken ondersteunt Fabric de install.packages(), remove.packages()en devtools:: opdrachten. Zie de opdracht install.packages en remove.package voor alle beschikbare R inline-opdrachten en verduidelijkingen.
Openbare R-bibliotheken beheren via inline-installatie
Volg dit voorbeeld om de stappen voor het installeren van een openbare R-bibliotheek te doorlopen.
Een R-feedbibliotheek installeren:
Schakel de werktaal over naar SparkR (R) op het notebooklint.
Installeer de caesar-bibliotheek door de volgende opdracht uit te voeren in een notebookcel.
install.packages("caesar")U kunt nu experimenteren met de sessiegerichte caesarbibliotheek met een Spark-taak.
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
Jar-bibliotheken beheren via inline-installatie
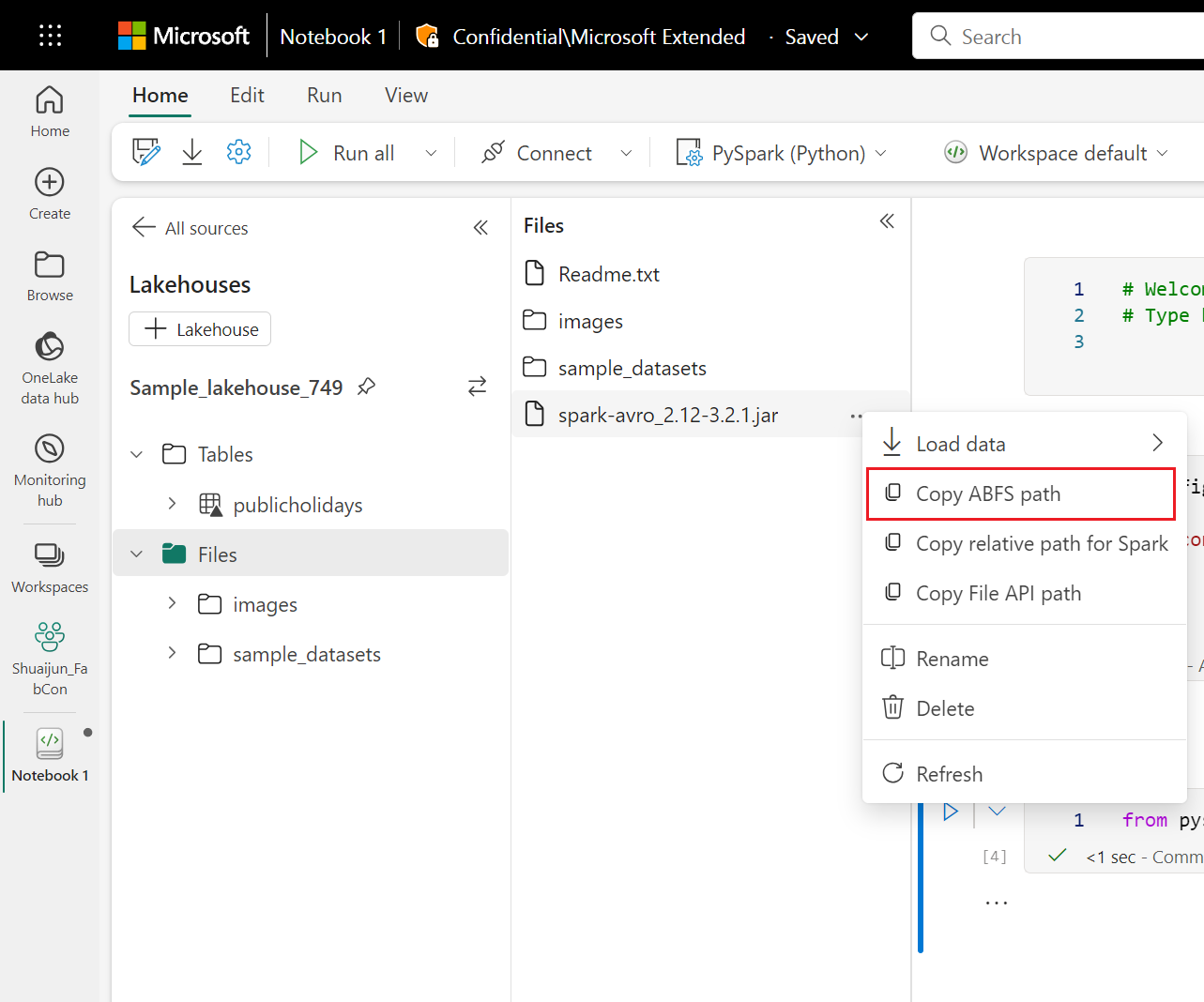
De .jar-bestanden worden ondersteund bij notebooksessies met de volgende opdracht.
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
In de codecel wordt de opslag van Lakehouse gebruikt als voorbeeld. In de notebook explorer kunt u het volledige ABFS-pad kopiëren en vervangen in de code.