Clusters instellen in HDInsight met Apache Hadoop, Spark, Kafka en meer
In dit artikel leert u hoe u Apache Hadoop, Apache Spark, Apache Kafka, Interactive Query of Apache HBase instelt en configureert in Azure HDInsight. U leert ook hoe u clusters aanpast en beveiliging toevoegt door ze aan een domein toe te voegen.
Een Hadoop-cluster bestaat uit verschillende virtuele machines (VM's, ook wel knooppunten genoemd) die worden gebruikt voor de gedistribueerde verwerking van taken. HDInsight verwerkt de implementatiedetails van de installatie en configuratie van afzonderlijke knooppunten. U geeft alleen algemene configuratiegegevens op.
Belangrijk
Facturering van HDInsight-clusters wordt gestart nadat een cluster is gemaakt en stopt wanneer het cluster wordt verwijderd. Facturering wordt naar rato per minuut uitgevoerd, dus verwijder altijd uw cluster wanneer het niet meer wordt gebruikt. Meer informatie over het verwijderen van een cluster.
Als u meerdere clusters samen gebruikt, wilt u een virtueel netwerk maken. Als u een Spark-cluster gebruikt, wilt u ook de Hive Warehouse-connector gebruiken. Zie Plan a virtual network voor Azure HDInsight en Integrate Apache Spark and Apache Hive with the Hive Warehouse Connector voor meer informatie.
Methoden voor het instellen van clusters
In de volgende tabel ziet u de verschillende methoden die u kunt gebruiken om een HDInsight-cluster in te stellen.
| Clusters gemaakt met | Webbrowser | Opdrachtregel | REST-API | SDK |
|---|---|---|---|---|
| Azure-portal | ✅ | |||
| Azure Data Factory | ✅ | ✅ | ✅ | ✅ |
| Azure-CLI | ✅ | |||
| Azure PowerShell | ✅ | |||
| cURL | ✅ | ✅ | ||
| Azure Resource Manager-sjablonen | ✅ |
Dit artikel begeleidt u bij het instellen in Azure Portal, waar u een HDInsight-cluster kunt maken.
Basisprincipes
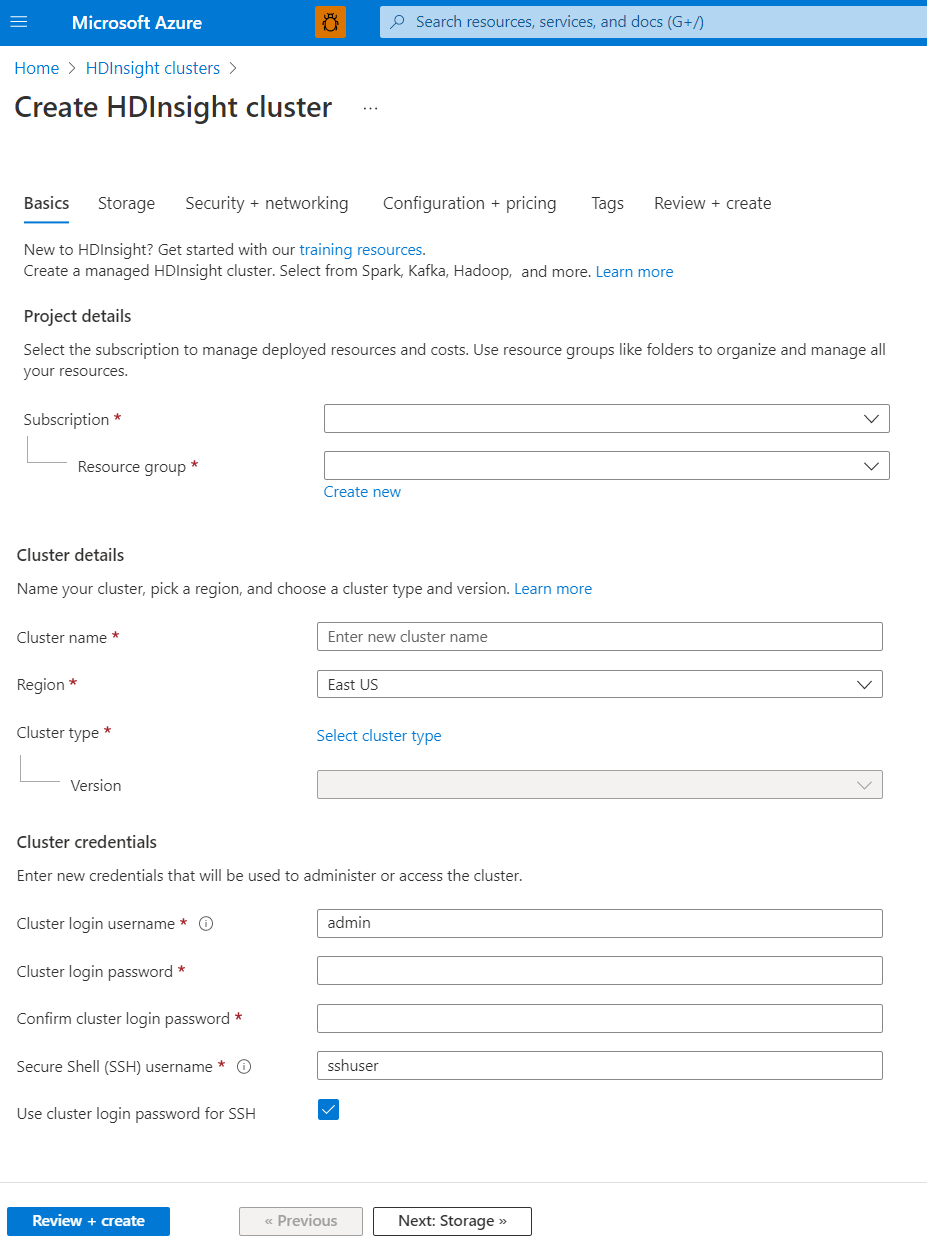
Projectdetails
Azure Resource Manager helpt u bij het werken met de resources in uw toepassing als een groep, die ook wel een Azure-resourcegroep wordt genoemd. U kunt alle resources voor uw toepassing implementeren, bijwerken, bewaken of verwijderen in één gecoördineerde bewerking.
Clusterdetails
Clusterdetails omvatten de naam, regio, type en versie.
Clusternaam
HdInsight-clusternamen hebben de volgende beperkingen:
- Toegestane tekens: a-z, 0-9 en A-Z
- Maximale lengte: 59
- Gereserveerde namen: apps
- Clusternaamgeving: het bereik is voor alle Azure-abonnementen. De clusternaam moet wereldwijd uniek zijn. De eerste zes tekens moeten uniek zijn binnen een virtueel netwerk.
Regio
U hoeft de clusterlocatie niet expliciet op te geven. Het cluster bevindt zich op dezelfde locatie als de standaardopslag. Voor een lijst met ondersteunde regio's selecteert u de vervolgkeuzelijst Regio in HDInsight-prijzen.
Clustertype
In de volgende tabel biedt HDInsight momenteel de clustertypen, elk met een set onderdelen om bepaalde functionaliteiten te bieden.
Belangrijk
HDInsight-clusters zijn beschikbaar in verschillende typen, elk voor één workload of technologie. Er wordt geen ondersteunde methode gemaakt waarin meerdere typen, zoals HBase, in één cluster worden gecombineerd. Als uw oplossing technologieën vereist die zijn verdeeld over meerdere HDInsight-clustertypen, kan een virtueel Azure-netwerk de vereiste clustertypen verbinden.
| Clustertype | Functionaliteit |
|---|---|
| Hadoop | Batchquery en analyse van opgeslagen gegevens. |
| HBase | Verwerking voor grote hoeveelheden schemaloze NoSQL-gegevens. |
| Interactieve query | Caching in geheugen voor interactieve en snellere Hive-query's. |
| Kafka | Een gedistribueerd streamingplatform dat u kunt gebruiken om realtime streaminggegevenspijplijnen en -toepassingen te bouwen. |
| Spark | In-memory verwerking, interactieve query's, verwerking van microbatchstromen. |
Versie
Kies de versie van HDInsight voor dit cluster. Raadpleeg Ondersteunde HDInsight-versies voor meer informatie.
Clusterreferenties
Met HDInsight-clusters kunt u twee gebruikersaccounts configureren tijdens het maken van het cluster:
- Gebruikersnaam voor clusteraanmelding: de standaardgebruikersnaam is beheerder. Deze maakt gebruik van de basisconfiguratie in Azure Portal. Het wordt ook wel Clustergebruiker of HTTP-gebruiker genoemd.
- SSH-gebruikersnaam (Secure Shell): wordt gebruikt om via SSH verbinding te maken met het cluster. Zie SSH gebruiken met HDInsight voor meer informatie.
De HTTP-gebruikersnaam heeft de volgende beperkingen:
- Toegestane speciale tekens: _ en @
- Tekens zijn niet toegestaan: #;.",/:!*?$()[]{}<>|&--=+%~^spatie
- Maximale lengte: 20
De SSH-gebruikersnaam heeft de volgende beperkingen:
- Toegestane speciale tekens: _ en @
- Tekens zijn niet toegestaan: #;.",/:!*?$()[]{}<>|&--=+%~^spatie
- Maximale lengte: 64
- Gereserveerde namen: hadoop, gebruikers, oozie, hive, mapred, ambari-qa, zookeeper, tez, hdfs, sqoop, yarn, hcat, ams, hbase, administrator, admin, user, user1, test, user2, test1, user3, admin1, 1, 123, a, actuser, adm, admin2, aspnet, backup, console, David, guest, John, owner, root, server, sql, support, support_388945a0, sys, test2, test3, user4, user5, spark
Storage
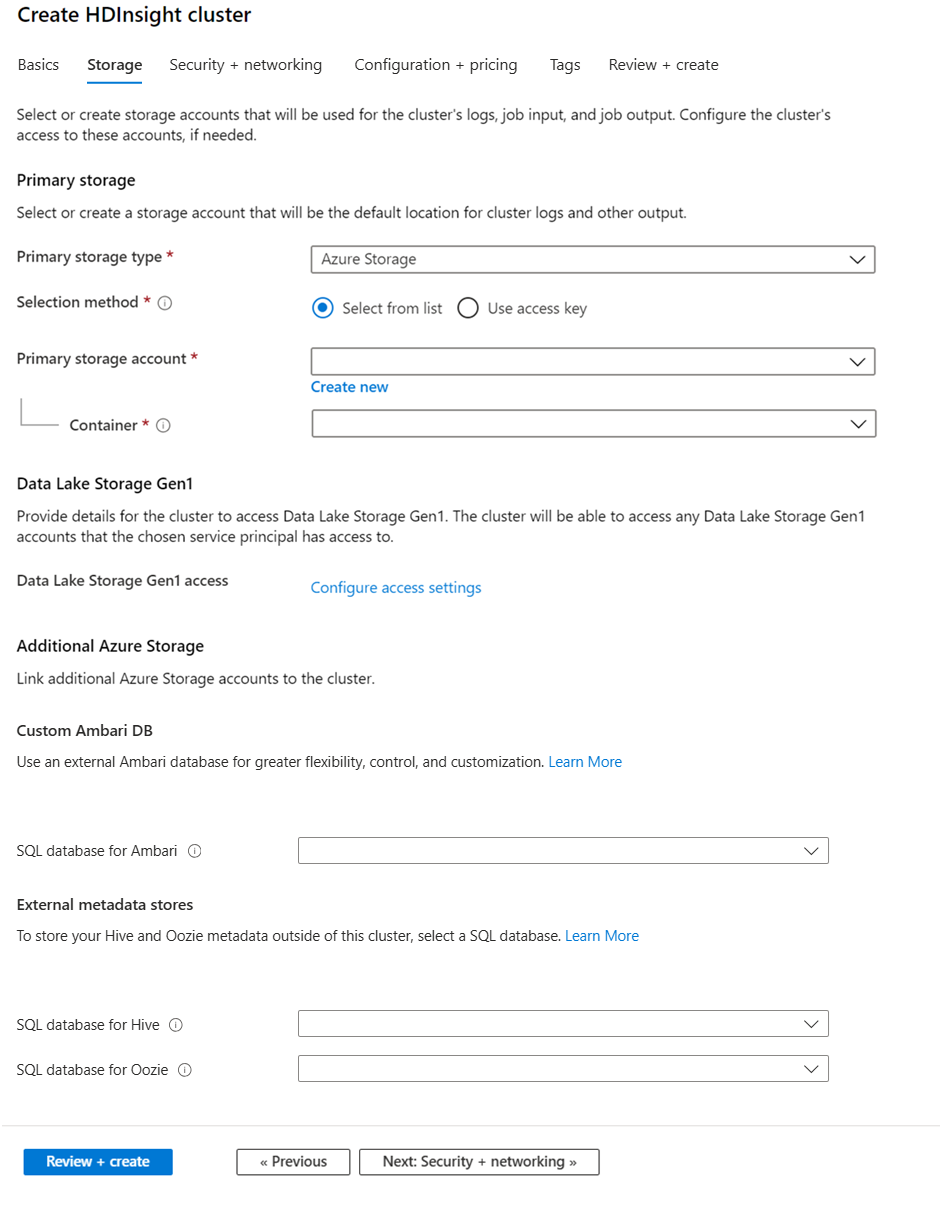
Hoewel voor een on-premises installatie van Hadoop hdfs (Hadoop Distributed File System) wordt gebruikt voor opslag op het cluster, gebruikt u in de cloud opslageindpunten die zijn verbonden met het cluster. Als u cloudopslag gebruikt, kunt u de HDInsight-clusters die worden gebruikt voor berekeningen veilig verwijderen terwijl u uw gegevens nog steeds bewaart.
HDInsight-clusters kunnen gebruikmaken van de volgende opslagopties:
- Azure Data Lake Storage Gen2
- Azure Storage Algemeen gebruik v2
- Blok-blob van Azure Storage (alleen ondersteund als secundaire opslag)
Zie Opslagopties vergelijken voor gebruik met Azure HDInsight-clusters voor meer informatie over opslagopties met HDInsight.
Het gebruik van meer opslagaccounts op een andere locatie dan het HDInsight-cluster wordt niet ondersteund.
Tijdens de configuratie geeft u voor het standaardopslageindpunt een blobcontainer van een opslagaccount of Data Lake Storage op. De standaardopslag bevat toepassings- en systeemlogboeken. U kunt desgewenst meer gekoppelde opslagaccounts en Data Lake Storage-accounts opgeven waartoe het cluster toegang heeft. Het HDInsight-cluster en de afhankelijke opslagaccounts moeten zich op dezelfde Azure-locatie bevinden.
Notitie
Met de functie waarvoor beveiligde overdracht is vereist, worden alle aanvragen voor uw account afgedwongen via een beveiligde verbinding. Alleen HDInsight-clusterversie 3.6 of hoger ondersteunt deze functie. Zie Apache Hadoop-cluster maken met opslagaccounts voor veilige overdracht in Azure HDInsight voor meer informatie.
Schakel beveiligde opslagoverdracht niet in nadat u een cluster hebt gemaakt, omdat het gebruik van uw opslagaccount kan leiden tot fouten. Het is beter om een nieuw cluster te maken met behulp van een opslagaccount waarvoor beveiligde overdracht al is ingeschakeld.
IN HDInsight worden uw gegevens die zijn opgeslagen in de opslag, niet automatisch overgedragen, verplaatst of gekopieerd van de ene regio naar de andere.
Metastore-instellingen
U kunt optionele Hive- of Apache Oozie-metastores maken. Niet alle clustertypen ondersteunen metastores en Azure Synapse Analytics is niet compatibel met metastores.
Zie Externe metagegevensarchieven gebruiken in Azure HDInsight voor meer informatie.
Wanneer u een aangepaste metastore maakt, gebruikt u geen streepjes, afbreekstreepjes of spaties in de databasenaam. Deze tekens kunnen ertoe leiden dat het proces voor het maken van het cluster mislukt.
SQL-database voor Hive
Als u uw Hive-tabellen wilt behouden nadat u een HDInsight-cluster hebt verwijderd, gebruikt u een aangepaste metastore. Vervolgens kunt u de metastore koppelen aan een ander HDInsight-cluster.
Een HDInsight-metastore die is gemaakt voor één HDInsight-clusterversie, kan niet worden gedeeld in verschillende HDInsight-clusterversies. Zie Ondersteunde HDInsight-versies voor een lijst met HDInsight-versies.
U kunt beheerde identiteiten gebruiken om te verifiëren met SQL-database voor Hive. Zie Beheerde identiteit gebruiken voor SQL Database-verificatie in HDInsight voor meer informatie.
De standaard-metastore biedt een SQL-database met een basic DTU-limiet van laag 5 (kan niet worden bijgewerkt). Het is geschikt voor eenvoudige testdoeleinden. Voor grote of productieworkloads raden we u aan om te migreren naar een externe metastore.
SQL-database voor Oozie
Gebruik een aangepaste metastore om de prestaties te verbeteren wanneer u Oozie gebruikt. Een metastore kan ook toegang bieden tot Oozie-taakgegevens nadat u uw cluster hebt verwijderd.
U kunt beheerde identiteiten gebruiken om te verifiëren met SQL Database for Oozie. Zie Beheerde identiteit gebruiken voor SQL Database-verificatie in HDInsight voor meer informatie.
SQL-database voor Ambari
Ambari wordt gebruikt voor het bewaken van HDInsight-clusters, het aanbrengen van configuratiewijzigingen en het opslaan van informatie over clusterbeheer en taakgeschiedenis. Met de aangepaste Ambari-databasefunctie kunt u een nieuw cluster implementeren en Ambari instellen in een externe database die u beheert. Zie Aangepaste Ambari-database voor meer informatie.
U kunt beheerde identiteiten gebruiken om te verifiëren met SQL Database for Ambari. Zie Beheerde identiteit gebruiken voor SQL Database-verificatie in HDInsight voor meer informatie.
U kunt een aangepaste Oozie-metastore niet opnieuw gebruiken. Als u een aangepaste Oozie-metastore wilt gebruiken, moet u een lege SQL-database opgeven wanneer u het HDInsight-cluster maakt.
Beveiliging en netwerk
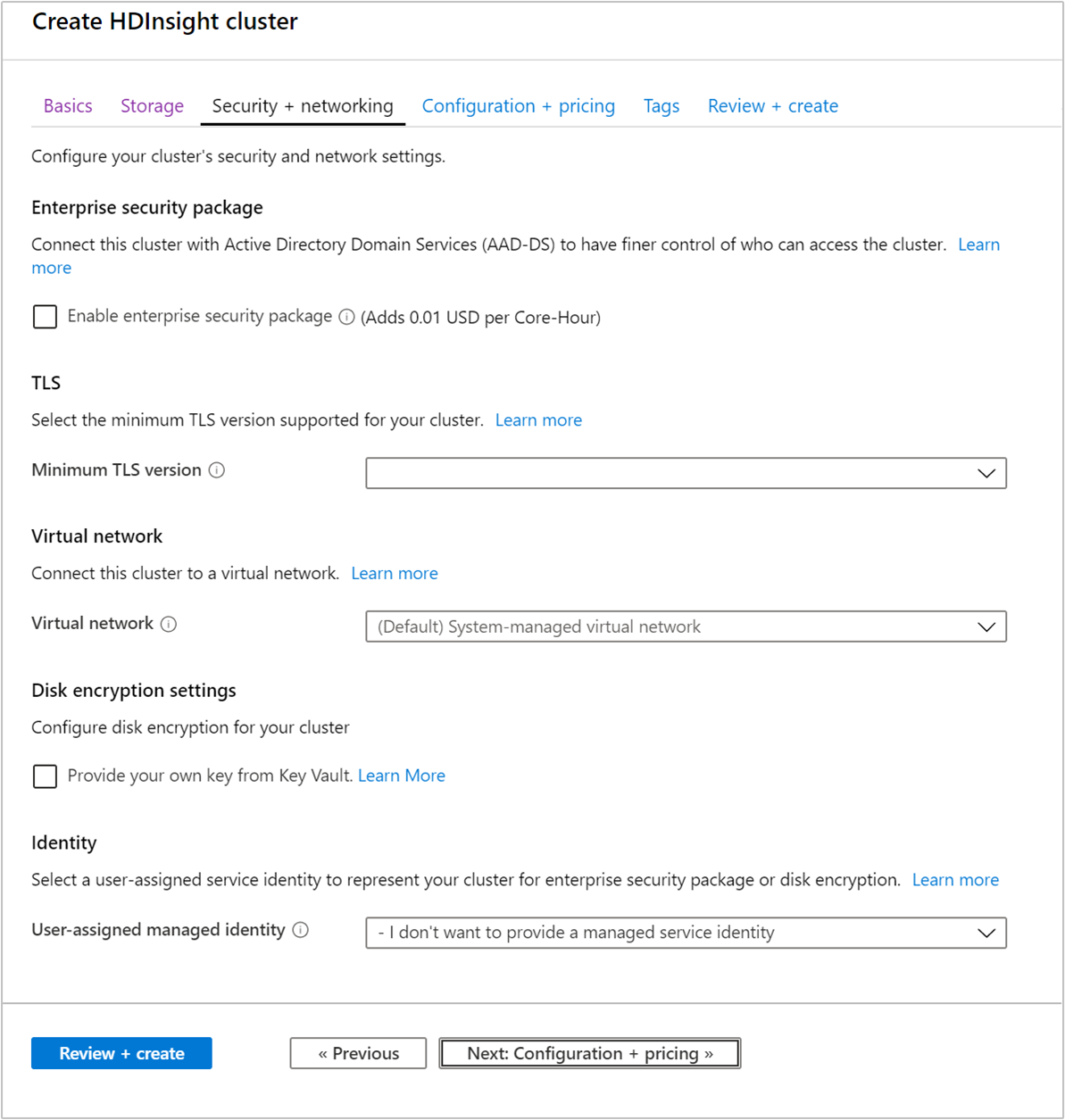
Enterprise Security Package
Voor Hadoop-, Spark-, HBase-, Kafka- en Interactive Query-clustertypen kunt u ervoor kiezen om het beveiligingspakket voor ondernemingen in te schakelen. Dit pakket biedt de mogelijkheid om een veiligere clusterinstallatie te hebben met behulp van Apache Ranger en integratie met Microsoft Entra. Zie Overzicht van bedrijfsbeveiliging in Azure HDInsight voor meer informatie.
Met het bedrijfsbeveiligingspakket kunt u HDInsight integreren met Microsoft Entra en Apache Ranger. U kunt het enterprise-beveiligingspakket gebruiken om meerdere gebruikers te maken.
Zie Sandbox-omgeving maken die lid is van een domein voor meer informatie over het maken van een HDInsight-cluster dat lid is van een domein.
Transport Layer Security
Zie Transport Layer Security voor meer informatie.
Virtueel netwerk
Als uw oplossing technologieën vereist die zijn verdeeld over meerdere HDInsight-clustertypen, kan een virtueel Azure-netwerk de vereiste clustertypen verbinden. Met deze configuratie kunnen de clusters en alle code die u erop implementeert, rechtstreeks met elkaar communiceren.
Zie Apache Spark Structured Streaming gebruiken met Apache Kafka voor een voorbeeld van het gebruik van twee clustertypen in een virtueel Azure-netwerk. Zie Een virtueel netwerk plannen voor HDInsight voor HDInsight voor meer informatie over het gebruik van HDInsight met een virtueel netwerk, inclusief specifieke configuratievereisten voor het virtuele netwerk.
Instelling voor schijfversleuteling
Zie Schijfversleuteling die door de klant wordt beheerd voor meer informatie.
Kafka REST-proxy
Deze instelling is alleen beschikbaar voor het Kafka-clustertype. Zie Een REST-proxy gebruiken voor meer informatie.
Identiteit
Zie Beheerde identiteiten in Azure HDInsight voor meer informatie.
Configuratie en prijzen
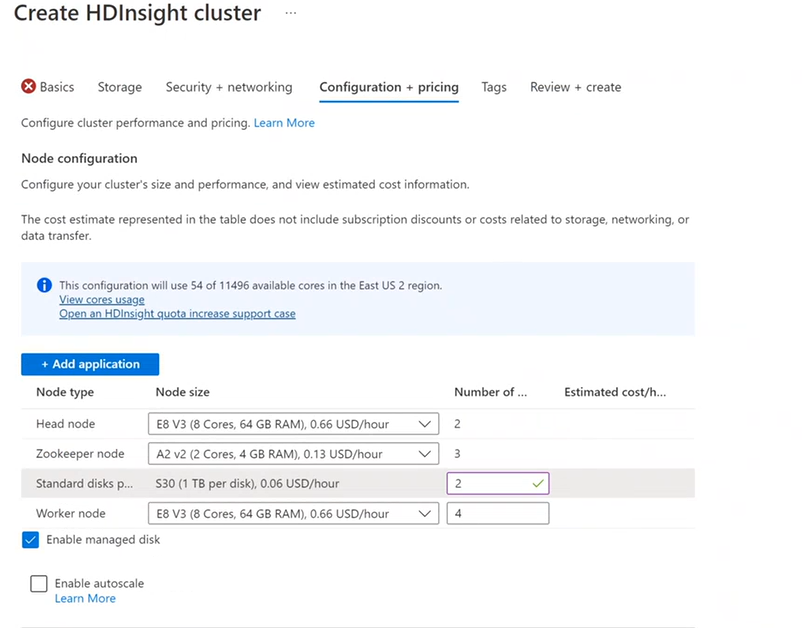
U wordt gefactureerd voor het gebruik van knooppunten zolang het cluster bestaat. Facturering wordt gestart wanneer een cluster wordt gemaakt en stopt wanneer het cluster wordt verwijderd. Clusters kunnen de toewijzing niet ongedaan worden gemaakt of in bewaring worden geplaatst.
Knooppuntconfiguratie
Elk clustertype heeft een eigen aantal knooppunten, terminologie voor knooppunten en standaard-VM-grootte. In de volgende tabel wordt het aantal knooppunten voor elk knooppunttype tussen haakjes weergegeven.
| Type | Knooppunten | Diagram |
|---|---|---|
| Hadoop | Hoofdknooppunt (2), Werkknooppunt (1+) |
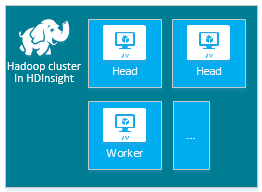
|
| HBase | Hoofdserver (2), Regioserver (1+), Master/ZooKeeper-knooppunt (3) |
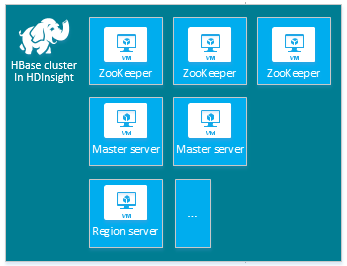
|
| Spark | Hoofdknooppunt (2), Werkknooppunt (1+), ZooKeeper-knooppunt (3) (gratis voor de grootte van de ZooKeeper-VM) |
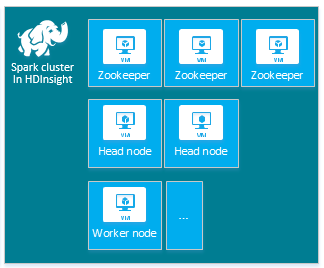
|
Zie Standaardknooppuntconfiguratie en VM-grootten voor clusters voor meer informatie.
De kosten van HDInsight-clusters die worden bepaald door het aantal knooppunten en de VM-grootten voor de knooppunten.
Verschillende clustertypen hebben verschillende knooppunttypen, aantallen knooppunten en knooppuntgrootten:
Standaard van hadoop-clustertype:
- Twee hoofdknooppunten
- Vier werkknooppunten
Als u HDInsight probeert, raden we u aan één werkknooppunt te gebruiken. Zie hdInsight-prijzen voor meer informatie over prijzen voor HDInsight.
Notitie
De limiet voor de clustergrootte verschilt per Azure-abonnement. Neem contact op met de ondersteuning van Azure-facturering om de limiet te verhogen.
Wanneer u Azure Portal gebruikt om het cluster te configureren, is de knooppuntgrootte beschikbaar via het tabblad Configuratie en prijzen . In de portal kunt u ook de kosten zien die zijn gekoppeld aan de verschillende knooppuntgrootten.
Grootten van virtuele machines
Wanneer u clusters implementeert, kiest u rekenresources op basis van de oplossing die u wilt implementeren. De volgende VM's worden gebruikt voor HDInsight-clusters:
- VM's uit de A- en D1-4-serie: Linux-VM-grootten voor algemeen gebruik
- Vm uit de D11-14-serie: Voor geheugen geoptimaliseerde Linux-VM-grootten
Als u wilt achterhalen welke waarde u moet gebruiken om een VM-grootte op te geven wanneer u een cluster maakt met behulp van de verschillende SDK's of Azure PowerShell, raadpleegt u VM-grootten voor HDInsight-clusters. Gebruik in dit gekoppelde artikel de waarde in de kolom Grootte van de tabellen.
Belangrijk
Als u meer dan 32 werkknooppunten in een cluster nodig hebt, moet u een hoofdknooppuntgrootte met ten minste 8 kernen en 14 GB RAM-geheugen selecteren.
Zie Grootten voor VM's voor meer informatie. Zie HDInsight-prijzen voor meer informatie over prijzen van de verschillende grootten.
Schijfbijlage
Notitie
De toegevoegde schijven zijn alleen geconfigureerd voor lokale mappen van knooppuntbeheer en niet voor datanodemappen.
Een HDInsight-cluster wordt geleverd met vooraf gedefinieerde schijfruimte op basis van de versie. Het uitvoeren van een aantal grote toepassingen kan leiden tot onvoldoende schijfruimte, met de schijf-volledige fout LinkId=221672#ERROR_NOT_ENOUGH_DISK_SPACE en taakfouten.
U kunt meer schijven aan het cluster toevoegen met behulp van de nieuwe functie NodeManager in de lokale map. Op het moment dat hive- en Spark-clusters zijn gemaakt, kunt u het aantal schijven selecteren en toevoegen aan de werkknooppunten. De geselecteerde schijven kunnen elk 1 TB zijn en maken deel uit van lokale mappen van NodeManager .
- Selecteer Op het tabblad Configuratie en prijzen de optie Beheerde schijf inschakelen.
- Voer bij Standard-schijven het aantal schijven in.
- Selecteer het werkknooppunt.
U kunt het aantal schijven controleren op het tabblad Controleren en maken onder Clusterconfiguratie.
Toepassing toevoegen
U kunt HDInsight-toepassingen installeren op een HDInsight-cluster op basis van Linux. U kunt toepassingen gebruiken die worden geleverd door Microsoft of derden of die u hebt ontwikkeld. Zie Apache Hadoop-toepassingen van derden installeren in Azure HDInsight voor meer informatie.
De meeste HDInsight-toepassingen worden geïnstalleerd op een leeg edge-knooppunt. Een leeg edge-knooppunt is een Virtuele Linux-machine waarop dezelfde clienthulpprogramma's zijn geïnstalleerd en geconfigureerd als in het hoofdknooppunt. U kunt het edge-knooppunt gebruiken voor toegang tot het cluster, het testen van uw clienttoepassingen en het hosten van uw clienttoepassingen. Zie Lege edge-knooppunten gebruiken in HDInsight voor meer informatie.
Scriptacties
U kunt meer onderdelen installeren of clusterconfiguratie aanpassen met behulp van scripts tijdens het maken. Dergelijke scripts worden aangeroepen via scriptacties. Dit is een configuratieoptie die u kunt gebruiken vanuit Azure Portal, HDInsight Windows PowerShell-cmdlets of de HDInsight .NET SDK. Zie HDInsight-cluster aanpassen met behulp van scriptacties voor meer informatie.
Sommige systeemeigen Java-onderdelen, zoals Apache Mahout en Cascading, kunnen op het cluster worden uitgevoerd als JAR-bestanden (Java Archive). U kunt deze JAR-bestanden distribueren naar opslag en ze verzenden naar HDInsight-clusters met hadoop-mechanismen voor het indienen van taken. Zie Apache Hadoop-taken programmatisch verzenden voor meer informatie.
Notitie
Als u problemen ondervindt met het implementeren van JAR-bestanden in HDInsight-clusters of het aanroepen van JAR-bestanden op HDInsight-clusters, neemt u contact op met Microsoft Ondersteuning.
HDInsight biedt geen ondersteuning voor trapsgewijze ondersteuning en komt niet in aanmerking voor Microsoft Ondersteuning. Zie Wat is er nieuw in de clusterversies van HDInsight voor lijsten met ondersteunde onderdelen.
Soms wilt u de volgende configuratiebestanden configureren tijdens het maken:
- clusterIdentity.xml
- core-site.xml
- gateway.xml
- hbase-env.xml
- hbase-site.xml
- hdfs-site.xml
- hive-env.xml
- hive-site.xml
- mapred-site
- oozie-site.xml
- oozie-env.xml
- tez-site.xml
- webhcat-site.xml
- yarn-site.xml
Zie HDInsight-clusters aanpassen met Bootstrap voor meer informatie.