Wat is Interactive Query in Azure HDInsight?
Interactive Query (ook wel Apache Hive LLAP genoemd, of analyse met lage latentie) is een Azure HDInsight-clustertype. Interactive Query biedt ondersteuning voor caching in het geheugen, waardoor Apache Hive query's sneller en veel meer interactief worden uitgevoerd. Klanten gebruiken Interactive Query om zeer snel gegevens op te vragen die zijn opgeslagen in Azure Storage en Azure Data Lake Storage. Met Interactive Query kunnen ontwikkelaars en gegevenswetenschappers eenvoudig samenwerken aan big data met behulp van de BI-tools die ze het liefst gebruiken. HDInsight Interactive Query ondersteunt diverse hulpprogramma's waarmee u op eenvoudige wijze toegang kunt krijgen tot big data.
Een Interactive Query-cluster is anders dan een Apache Hadoop-cluster. Het bevat alleen de Hive-service.
U hebt alleen toegang tot de Hive-service in het Interactive Query-cluster via Apache Ambari Hive View, Beeline en het Microsoft Hive Open Database Connectivity-stuurprogramma (Hive ODBC). U hebt geen toegang via de Hive-console, Templeton, de klassieke Azure-CLI of Azure PowerShell.
Een Interactive Query-cluster maken
Zie Apache Hadoop-clusters maken in HDInsight voor meer informatie over het maken van HDInsight-clusters. Kies het clustertype Interactive Query.
Belangrijk
De minimale grootte van het hoofdknooppunt voor Interactive Query-clusters is Standard_D13_v2. Zie de grafiek voor het aanpassen van de grootte van virtuele Azure-machines voor meer informatie.
Apache Hive-query's uitvoeren vanuit Interactive Query
Als u Hive-query's wilt uitvoeren, hebt u de volgende opties:
De verbindingsreeks voor Java Database Connectivity (JDBC) zoeken:
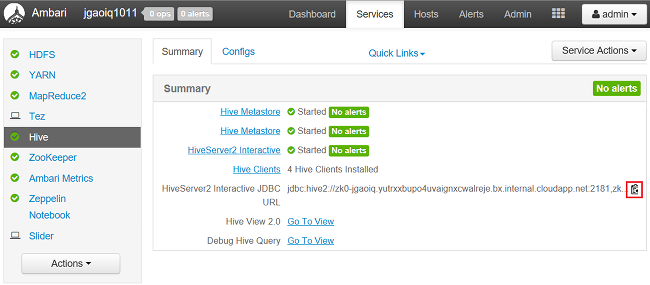
Navigeer in een webbrowser naar
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary, waarbijCLUSTERNAMEde naam van uw cluster is.Selecteer het klembordpictogram om de URL naar het klembord te kopiëren:
Volgende stappen
- Meer informatie over het maken van Interactive Query-clusters in HDInsight.
- Meer informatie over Interactive Query Hive-gegevens visualiseren met Power BI in Azure HDInsight.
- Meer informatie over Apache Zeppelin gebruiken voor het uitvoeren van Apache Hive-query's in Azure HDInsight.