Apache Spark en Apache Hive integreren met Hive Warehouse Connector in Azure HDInsight
De Apache Hive Warehouse Connector (HWC) is een bibliotheek waarmee u eenvoudiger kunt werken met Apache Spark en Apache Hive. Het ondersteunt taken zoals het verplaatsen van gegevens tussen Spark DataFrames en Hive-tabellen. Door Spark-streaminggegevens door te leiden naar Hive-tabellen. Hive Warehouse Connector werkt als een brug tussen Spark en Hive. Het biedt ook ondersteuning voor Scala, Java en Python als programmeertalen voor ontwikkeling.
Met de Hive Warehouse-connector kunt u profiteren van de unieke functies van Hive en Spark om krachtige big data-toepassingen te bouwen.
Apache Hive biedt ondersteuning voor databasetransacties die Atomic, Consistent, Isolated en Durable (ACID) zijn. Zie Hive-transacties voor meer informatie over ACID en transacties in Hive. Hive biedt ook gedetailleerde beveiligingscontroles via Apache Ranger en LLAP (Low Latency Analytical Processing) die niet beschikbaar zijn in Apache Spark.
Apache Spark heeft een Structured Streaming-API die streamingmogelijkheden biedt die niet beschikbaar zijn in Apache Hive. Vanaf HDInsight 4.0 hebben Apache Spark 2.3.1 & hoger en Apache Hive 3.1.0 afzonderlijke metastore-catalogi, waardoor de interoperabiliteit moeilijk wordt.
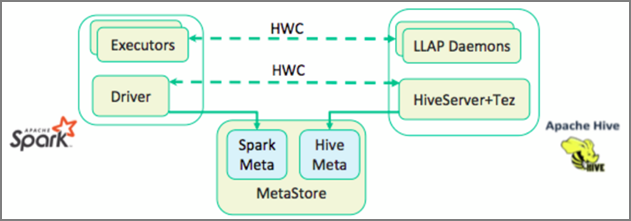
De Hive Warehouse Connector (HWC) maakt het eenvoudiger om Spark en Hive samen te gebruiken. De HWC-bibliotheek laadt gegevens van LLAP-daemons parallel naar Spark-uitvoerders. Dit proces maakt het efficiënter en aanpasbaarer dan een standaard JDBC-verbinding van Spark naar Hive. Dit brengt twee verschillende uitvoeringsmodi voor HWC naar buiten:
- Hive JDBC-modus via HiveServer2
- Hive LLAP-modus met LLAP-daemons [aanbevolen]
HWC is standaard geconfigureerd voor het gebruik van Hive LLAP-daemons. Zie HWC-API's voor het uitvoeren van Hive-query's (zowel lezen als schrijven) met behulp van de bovenstaande modi.
Enkele van de bewerkingen die worden ondersteund door de Hive Warehouse-connector zijn:
- Een tabel beschrijven
- Een tabel maken voor met ORC opgemaakte gegevens
- Hive-gegevens selecteren en een DataFrame ophalen
- Een DataFrame in batch naar Hive schrijven
- Een Hive-update-instructie uitvoeren
- Tabelgegevens lezen uit Hive, deze transformeren in Spark en schrijven naar een nieuwe Hive-tabel
- Een DataFrame- of Spark-stream naar Hive schrijven met HiveStreaming
Installatie van Hive Warehouse-connector
Belangrijk
- Het interactieve HiveServer2-exemplaar dat is geïnstalleerd op Spark 2.4 Enterprise Security Package-clusters, wordt niet ondersteund voor gebruik met de Hive Warehouse-connector. In plaats daarvan moet u een afzonderlijk HiveServer2 Interactive-cluster configureren om uw HiveServer2 Interactive-workloads te hosten. Een Hive Warehouse Connector-configuratie die gebruikmaakt van één Spark 2.4-cluster wordt niet ondersteund.
- HWC-bibliotheek (Hive Warehouse Connector) wordt niet ondersteund voor gebruik met Interactive Query Clusters waarvoor de functie Workloadbeheer (WLM) is ingeschakeld.
In een scenario waarin u alleen Spark-workloads hebt en HWC-bibliotheek wilt gebruiken, moet u ervoor zorgen dat het Interactive Query-cluster de functie Workloadbeheer niet heeft ingeschakeld (hive.server2.tez.interactive.queueconfiguratie is niet ingesteld in Hive-configuraties).
Voor een scenario waarin zowel Spark-workloads (HWC) als LLAP-workloads bestaan, moet u twee afzonderlijke Interactive Query-clusters maken met een gedeelde metastore-database. Eén cluster voor systeemeigen LLAP-workloads waarbij WLM-functie kan worden ingeschakeld op basis van behoefte en een ander cluster voor alleen HWC-werkbelasting waarbij de WLM-functie niet mag worden geconfigureerd. Het is belangrijk te weten dat u de WLM-resourceplannen van beide clusters kunt bekijken, zelfs als deze in slechts één cluster is ingeschakeld. Breng geen wijzigingen aan in resourceplannen in het cluster waarin de WLM-functie is uitgeschakeld, omdat dit van invloed kan zijn op de WLM-functionaliteit in een ander cluster. - Hoewel Spark ondersteuning biedt voor R-computingtaal voor het vereenvoudigen van de gegevensanalyse, wordt de HWC-bibliotheek (Hive Warehouse Connector) niet ondersteund voor gebruik met R. Als u HWC-workloads wilt uitvoeren, kunt u query's uitvoeren van Spark naar Hive met behulp van de HiveWarehouseSession-API in JDBC-stijl die alleen Ondersteuning biedt voor Scala, Java en Python.
- Het uitvoeren van query's (zowel lezen als schrijven) via HiveServer2 via de JDBC-modus wordt niet ondersteund voor complexe gegevenstypen, zoals matrices/struct/kaarttypen.
- HWC ondersteunt alleen schrijven in ORC-bestandsindelingen. Niet-ORC-schrijfbewerkingen (bijvoorbeeld parquet- en tekstbestandsindelingen) worden niet ondersteund via HWC.
Hive Warehouse Connector heeft afzonderlijke clusters nodig voor Spark- en Interactive Query-workloads. Volg deze stappen om deze clusters in te stellen in Azure HDInsight.
Ondersteunde clustertypen en -versies
| HWC-versie | Spark-versie | InteractiveQuery-versie |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | Interactive Query 3.1 | HDI 4.0 |
| v2 | Spark 3.1 | HDI 5.0 | Interactive Query 3.1 | HDI 5.0 |
Clusters maken
Maak een HDInsight Spark 4.0-cluster met een opslagaccount en een aangepast virtueel Azure-netwerk. Zie HDInsight toevoegen aan een bestaand virtueel netwerk voor informatie over het maken van een cluster in een virtueel Azure-netwerk.
Maak een HDInsight Interactive Query (LLAP) 4.0-cluster met hetzelfde opslagaccount en het virtuele Azure-netwerk als het Spark-cluster.
HWC-instellingen configureren
Voorlopige informatie verzamelen
Navigeer in een webbrowser naar
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVEde locatie waar LLAPCLUSTERNAME de naam van uw Interactive Query-cluster is.Navigeer naar summary>HiveServer2 Interactive JDBC URL en noteer de waarde. De waarde kan vergelijkbaar zijn met:
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive.Navigeer naar Configs>Advanced Advanced>hive-site>hive.zookeeper.quorum en noteer de waarde. De waarde kan vergelijkbaar zijn met:
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181.Navigeer naar Configs>Advanced>General>hive.metastore.uris en noteer de waarde. De waarde kan vergelijkbaar zijn met:
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083.Navigeer naar Advanced>Advanced>Hive-interactive-site>hive.llap.daemon.service.hosts en noteer de waarde. De waarde kan vergelijkbaar zijn met:
@llap0.
Spark-clusterinstellingen configureren
Navigeer in een webbrowser naar
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configsde locatie waar CLUSTERNAME de naam van uw Apache Spark-cluster is.Vouw aangepaste spark2-standaardwaarden uit.
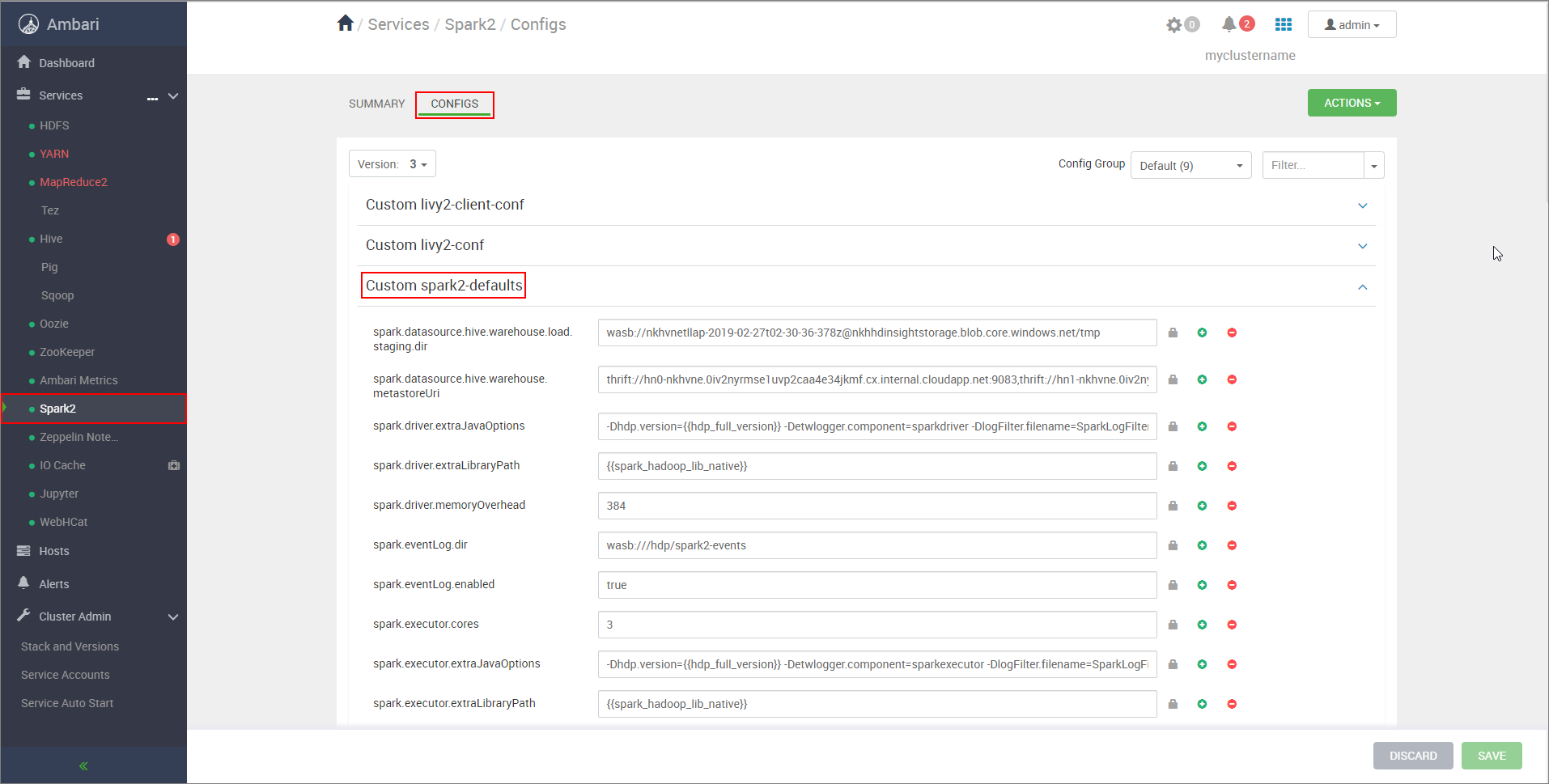
Selecteer Eigenschap toevoegen... om de volgende configuraties toe te voegen:
Configuratie Weergegeven als spark.datasource.hive.warehouse.load.staging.dirAls u een ADLS Gen2-opslagaccount gebruikt, gebruikt u abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp
Als u een Azure Blob Storage-account gebruikt, gebruikt uwasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp.
Ingesteld op een geschikte, met HDFS compatibele faseringsmap. Als u twee verschillende clusters hebt, moet de faseringsmap een map zijn in de faseringsmap van het opslagaccount van het LLAP-cluster, zodat HiveServer2 er toegang toe heeft. VervangSTORAGE_ACCOUNT_NAMEdoor de naam van het opslagaccount dat wordt gebruikt door het cluster enSTORAGE_CONTAINER_NAMEdoor de naam van de opslagcontainer.spark.sql.hive.hiveserver2.jdbc.urlDe waarde die u eerder hebt verkregen van de Interactieve JDBC-URL van HiveServer2 spark.datasource.hive.warehouse.metastoreUriDe waarde die u eerder hebt verkregen van hive.metastore.uris. spark.security.credentials.hiveserver2.enabledtruevoor YARN-clustermodus enfalsevoor YARN-clientmodus.spark.hadoop.hive.zookeeper.quorumDe waarde die u eerder hebt verkregen van hive.zookeeper.quorum. spark.hadoop.hive.llap.daemon.service.hostsDe waarde die u eerder hebt verkregen van hive.llap.daemon.service.hosts. Sla wijzigingen op en start alle betrokken onderdelen opnieuw op.
HWC configureren voor ESP-clusters (Enterprise Security Package)
Het Enterprise Security Package (ESP) biedt hoogwaardige mogelijkheden, zoals verificatie op basis van Active Directory, ondersteuning voor meerdere gebruikers en op rollen gebaseerd toegangsbeheer voor Apache Hadoop-clusters in Azure HDInsight. Zie Enterprise Security Package gebruiken in HDInsight voor meer informatie over ESP.
Voeg afgezien van de configuraties die in de vorige sectie worden genoemd, de volgende configuratie toe om HWC te gebruiken op de ESP-clusters.
Navigeer vanuit de Ambari-webgebruikersinterface van het Spark-cluster naar de aangepaste spark2-standaardinstellingen van Spark2>>.
Werk de volgende eigenschap bij.
Configuratie Weergegeven als spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>Navigeer in een webbrowser naar
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summaryde locatie waar CLUSTERNAME de naam van uw Interactive Query-cluster is. Klik op HiveServer2 Interactive. U ziet de FQDN (Fully Qualified Domain Name) van het hoofdknooppunt waarop LLAP wordt uitgevoerd, zoals wordt weergegeven in de schermopname. Vervang<llap-headnode>door deze waarde.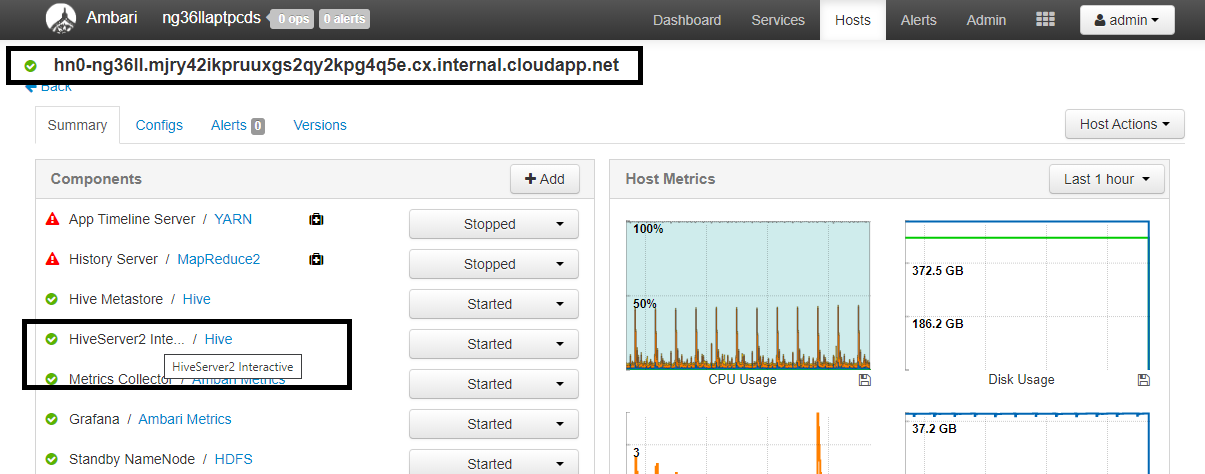
Gebruik de SSH-opdracht om verbinding te maken met uw Interactive Query-cluster.
default_realmZoek naar de parameter in het/etc/krb5.confbestand. Vervang<AAD-DOMAIN>door deze waarde als een tekenreeks in hoofdletters, anders wordt de referentie niet gevonden.
Bijvoorbeeld
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET.
Sla de wijzigingen op en start de onderdelen zo nodig opnieuw op.
Gebruik van Hive Warehouse Connector
U kunt kiezen tussen een paar verschillende methoden om verbinding te maken met uw Interactive Query-cluster en query's uit te voeren met behulp van de Hive Warehouse-connector. Ondersteunde methoden omvatten de volgende hulpprogramma's:
Hieronder ziet u enkele voorbeelden om vanuit Spark verbinding te maken met HWC.
Spark-shell
Dit is een manier om Spark interactief uit te voeren via een gewijzigde versie van de Scala-shell.
Gebruik de ssh-opdracht om verbinding te maken met uw Apache Spark-cluster. Bewerk de onderstaande opdracht door CLUSTERNAME te vervangen door de naam van uw cluster. Voer vervolgens deze opdracht in:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netVoer vanuit uw ssh-sessie de volgende opdracht uit om de
hive-warehouse-connector-assemblyversie te noteren:ls /usr/hdp/current/hive_warehouse_connectorBewerk de onderstaande code met de
hive-warehouse-connector-assemblyhierboven geïdentificeerde versie. Voer vervolgens de opdracht uit om de Spark Shell te starten:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseNadat u de Spark-shell hebt gestart, kan een Hive Warehouse Connector-exemplaar worden gestart met behulp van de volgende opdrachten:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-submit
Spark-submit is een hulpprogramma voor het verzenden van een Spark-programma (of taak) naar Spark-clusters.
De spark-submit-taak stelt spark- en Hive Warehouse-connector in en configureert deze volgens onze instructies, voert het programma uit dat we hieraan doorgeven en laat vervolgens de resources die zijn gebruikt, op een schone manier vrij.
Zodra u de scala/java-code samen met de afhankelijkheden in een assembly-JAR hebt gebouwd, gebruikt u de onderstaande opdracht om een Spark-toepassing te starten. Vervang en <APP_JAR_PATH> door <VERSION>de werkelijke waarden.
YARN-clientmodus
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarYARN-clustermodus
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
Dit hulpprogramma wordt ook gebruikt wanneer we de hele toepassing in pySpark hebben geschreven en in .py bestanden (Python) zijn verpakt, zodat we de volledige code kunnen verzenden naar het Spark-cluster voor uitvoering.
Voor Python-toepassingen geeft u een .py-bestand door in de plaats van /<APP_JAR_PATH>/myHwcAppProject.jaren voegt u het onderstaande configuratiebestand (Python .zip) toe aan het zoekpad met --py-files.
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
Query's uitvoeren op ESP-clusters (Enterprise Security Package)
Gebruik kinit deze voordat u de spark-shell of spark-submit start. Vervang USERNAME door de naam van een domeinaccount door machtigingen voor toegang tot het cluster en voer vervolgens de volgende opdracht uit:
kinit USERNAME
Gegevens beveiligen op Spark ESP-clusters
Maak een tabel
demomet enkele voorbeeldgegevens door de volgende opdrachten in te voeren:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');Bekijk de inhoud van de tabel met de volgende opdracht. Voordat u het beleid toepast, wordt in de
demotabel de volledige kolom weergegeven.hive.executeQuery("SELECT * FROM demo").show()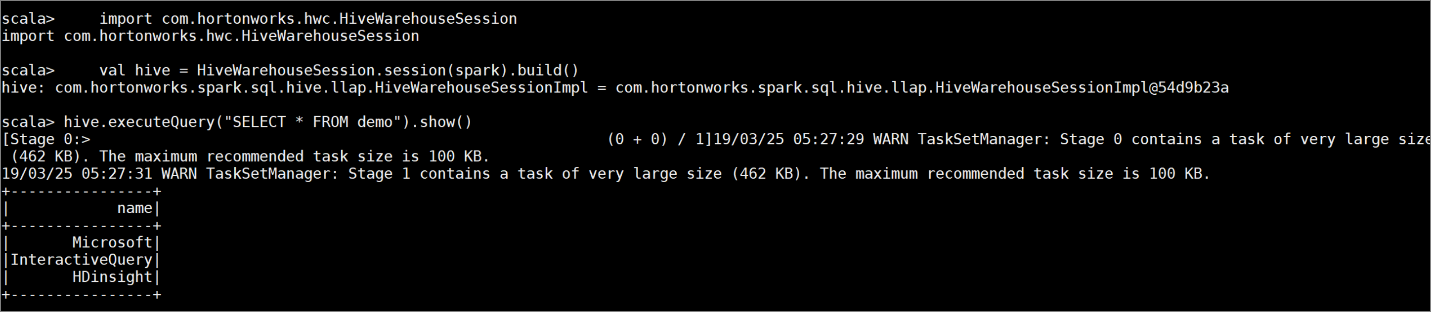
Pas een beleid voor kolommaskering toe dat alleen de laatste vier tekens van de kolom weergeeft.
Ga naar de gebruikersinterface van Ranger Admin op
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/.Klik op de Hive-service voor uw cluster onder Hive.
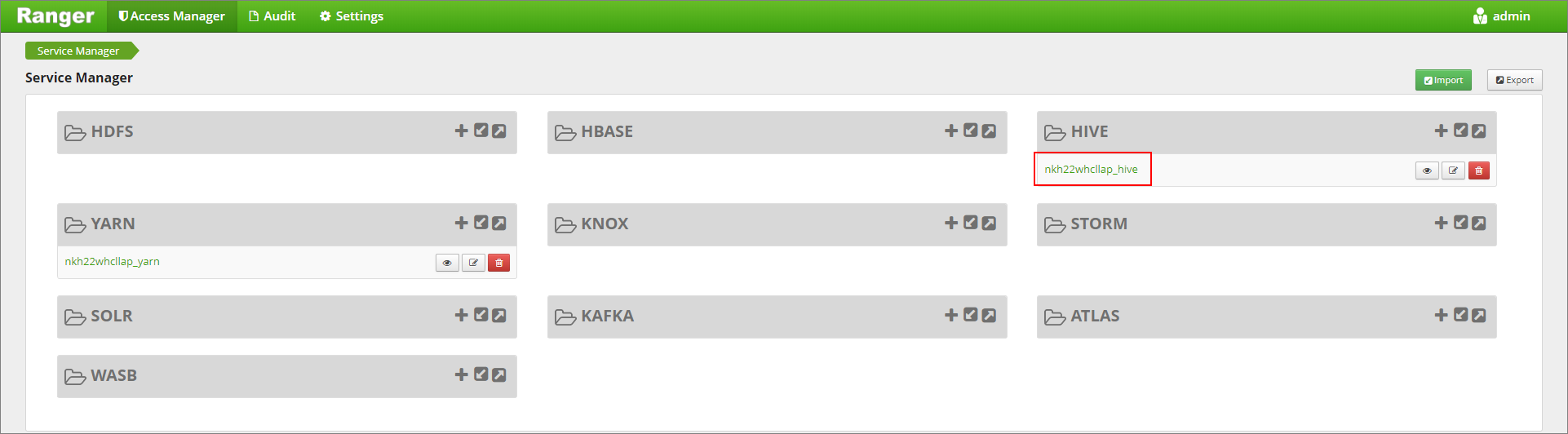
Klik op het tabblad Maskering en voeg vervolgens nieuw beleid toe
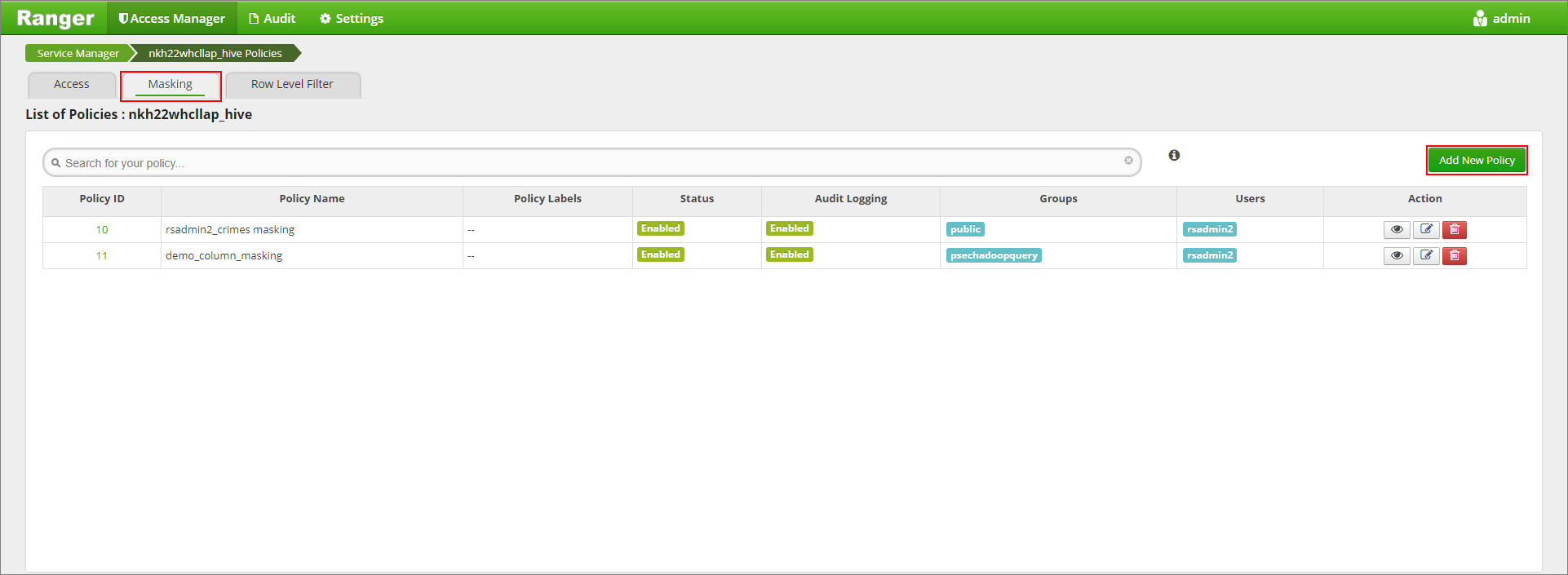
Geef een gewenste beleidsnaam op. Database selecteren: Standaard, Hive-tabel: demo, Hive-kolom: naam, Gebruiker: rsadmin2, Toegangstypen: selecteren en Gedeeltelijk masker: laatste 4 weergeven in het menu Maskeringsoptie selecteren. Klik op Toevoegen.
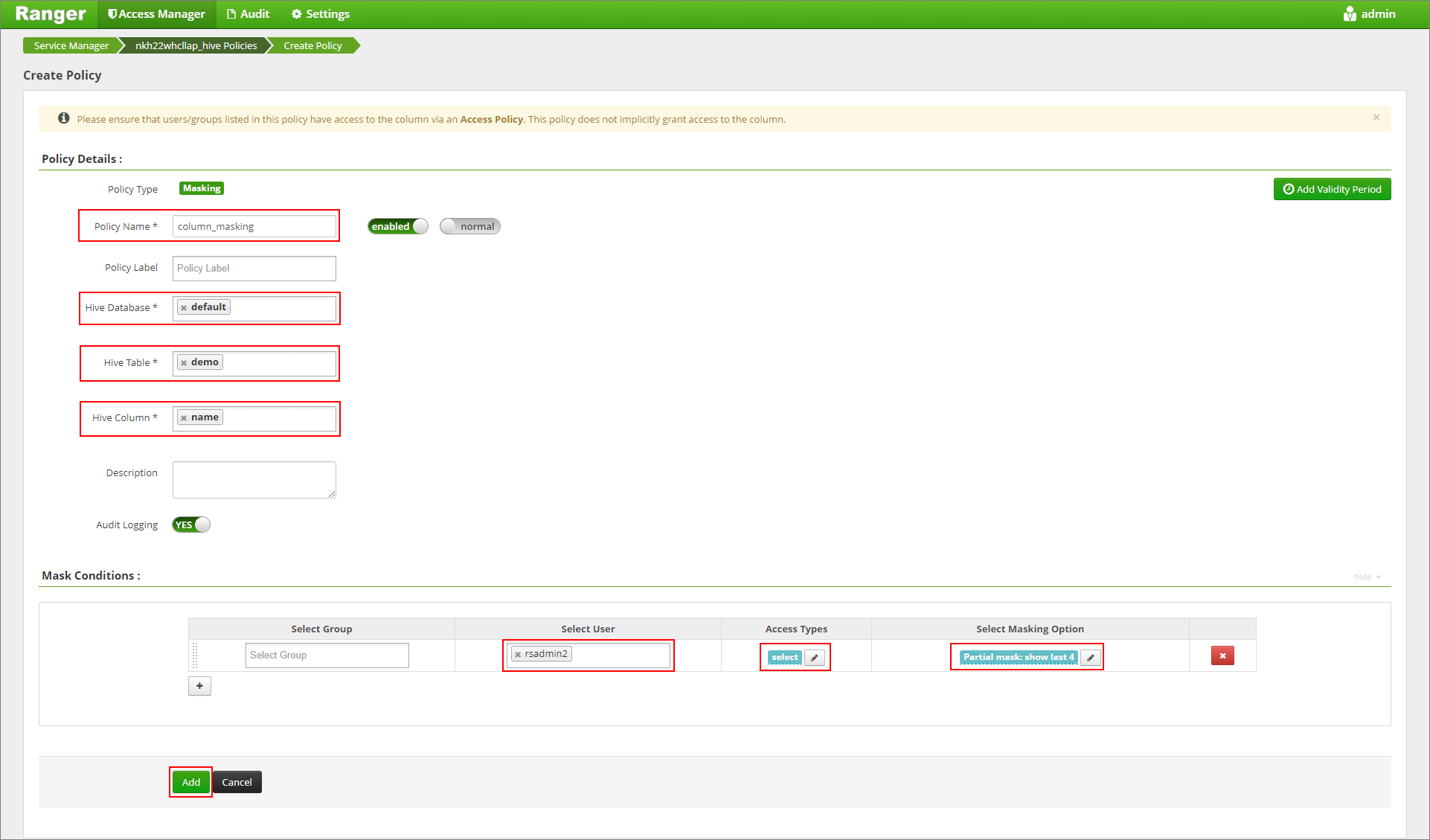
Bekijk de inhoud van de tabel opnieuw. Nadat het bereikbeleid is toegepast, kunnen we alleen de laatste vier tekens van de kolom zien.
