Zelfstudie: Apache Spark Structured Streaming gebruiken met Apache Kafka op HDInsight
Deze zelfstudie laat zien hoe u Apache Spark Structured Streaming gebruikt om gegevens te lezen en te schrijven met Apache Kafka in Azure HDInsight.
Spark Structured Streaming is een streamverwerkingsengine gebaseerd op Spark SQL. Hiermee kunt u streamingberekeningen op dezelfde manier weergeven als batchberekeningen van statische gegevens.
In deze zelfstudie leert u het volgende:
- Een Azure Resource Manager-sjabloon gebruiken om clusters te maken
- Spark Structured Streaming met Kafka gebruiken
Nadat u de stappen in dit document hebt doorlopen, moet u niet vergeten de clusters te verwijderen om overtollige kosten te voorkomen.
Vereisten
jq, een opdrachtregel-JSON-processor. Zie https://stedolan.github.io/jq/.
Weten hoe u Jupyter Notebooks gebruikt met Apache Spark on HDInsight. Zie het document Zelfstudie: Gegevens laden en query's uitvoeren in een Apache Spark-cluster in Azure HDInsight voor meer informatie.
Bekend met de programmeertaal Scala. De code die wordt gebruikt in deze zelfstudie, is geschreven in Scala.
Kennis van Kafka-onderwerpen. Zie het document Quickstart: Een Apache Kafka-cluster maken in HDInsight voor meer informatie.
Belangrijk
Voor de stappen in dit document is een Azure-resourcegroep nodig die zowel een Spark in HDInsight- als een Kafka in HDInsight-cluster bevat. Deze clusters bevinden zich beide binnen een Azure Virtual Network, waardoor het Spark-cluster rechtstreeks kan communiceren met het Kafka-cluster.
Voor uw gemak is dit document gekoppeld aan een sjabloon waarmee u alle vereiste Azure-resources kunt maken.
Zie het document Plan een virtueel netwerk voor HDInsight voor meer informatie over het gebruik van HDInsight in een virtueel netwerk.
Gestructureerd streamen met Apache Kafka
Spark Structured Streaming is een streamverwerkingsengine gebaseerd op de Spark SQL-engine. Wanneer u Structured Streaming gebruikt, kunt u streamingquery's schrijven op de manier waarop u ook batchquery's schrijft.
De volgende codefragmenten laten zien hoe u gegevens kunt lezen uit Kafka om deze daarna op te slaan in een bestand. Het eerste fragment betreft een batchbewerking, terwijl het tweede een streamingbewerking is:
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
In beide codefragmenten worden gegevens gelezen uit Kafka en weggeschreven naar een bestand. Dit zijn de verschillende tussen de voorbeelden:
| Batch | Streaming |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
De streamingbewerking gebruikt ook awaitTermination(30000), waarmee de stream na 30.000 ms wordt gestopt.
Als u Structured Streaming wilt gebruiken met Kafka, moet het project afhankelijk zijn van het pakket org.apache.spark : spark-sql-kafka-0-10_2.11. De versie van dit pakket moet overeenkomen met de versie van Spark in HDInsight. Voor Spark 2.4 (beschikbaar in HDInsight 4.0) vindt u de afhankelijkheidsinformatie voor verschillende projecttypen op https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar.
Voor het Jupyter-notebook dat wordt gebruikt met deze zelfstudie zorgt de code in de volgende cel ervoor dat deze pakketafhankelijkheid wordt geladen:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
De clusters maken
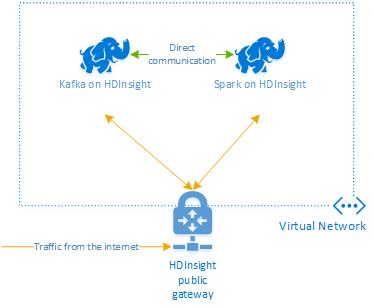
Apache Kafka in HDInsight biedt geen toegang tot de Kafka-brokers via het openbare internet. Alles wat gebruikmaakt van Kafka moet zich in hetzelfde Azure Virtual Network bevinden. In deze zelfstudie bevinden de Kafka- en Spark-clusters zich in hetzelfde Azure Virtual Network.
Het volgende diagram laat zien hoe de communicatie tussen Spark en Kafka verloopt:
Notitie
De Kafka-service blijft beperkt tot communicatie binnen het virtuele netwerk. Andere services in het cluster, zoals SSH en Ambari, zijn toegankelijk via internet. Zie Poorten en URI's die worden gebruikt door HDInsight voor meer informatie over de openbare poorten die beschikbaar zijn voor HDInsight.
Gebruik de volgende stappen om eerst een virtueel Azure-netwerk te maken en vervolgens de Kafka- en Spark-clusters:
Gebruik de volgende knop om u aan te melden bij Azure en de sjabloon in de Azure Portal te openen.

De Azure Resource Manager-sjabloon bevindt zich op https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json.
Met deze sjabloon maakt u de volgende bronnen:
Een Kafka-cluster in HDInsight 4.0 of 5.0.
Een Spark 2.4- of 3.1-cluster in HDInsight 4.0 of 5.0.
Een Azure Virtual Network dat de HDInsight-clusters bevat.
Belangrijk
Voor het gestructureerde streaming-notebook dat in deze zelfstudie wordt gebruikt, is Spark 2.4 of 3.1 in HDInsight 4.0 of 5.0 vereist. Als u een eerdere versie van Spark in HDInsight gebruikt, worden er fouten gegenereerd bij gebruik van de notebook.
Gebruik de volgende informatie voor het vullen van de vermeldingen in de sectie Aangepaste sjabloon:
Instelling Weergegeven als Abonnement Uw Azure-abonnement Resourcegroep De resourcegroep die de resources bevat. Locatie De Azure-regio waarin de bronnen worden gemaakt. Naam Spark-cluster De naam van het Spark-cluster. De eerste zes tekens moeten verschillen van de naam van het Kafka-cluster. Naam Kafka-cluster De naam van het Kafka-cluster. De eerste zes tekens moeten verschillen van de naam van het Spark-cluster. Gebruikersnaam voor clusteraanmelding De beheerdersnaam voor de clusters. Wachtwoord voor clusteraanmelding Het beheerderswachtwoord voor de clusters. SSH-gebruikersnaam De SSH-gebruiker die voor de clusters wordt gemaakt. SSH-wachtwoord Het wachtwoord voor de SSH-gebruiker. 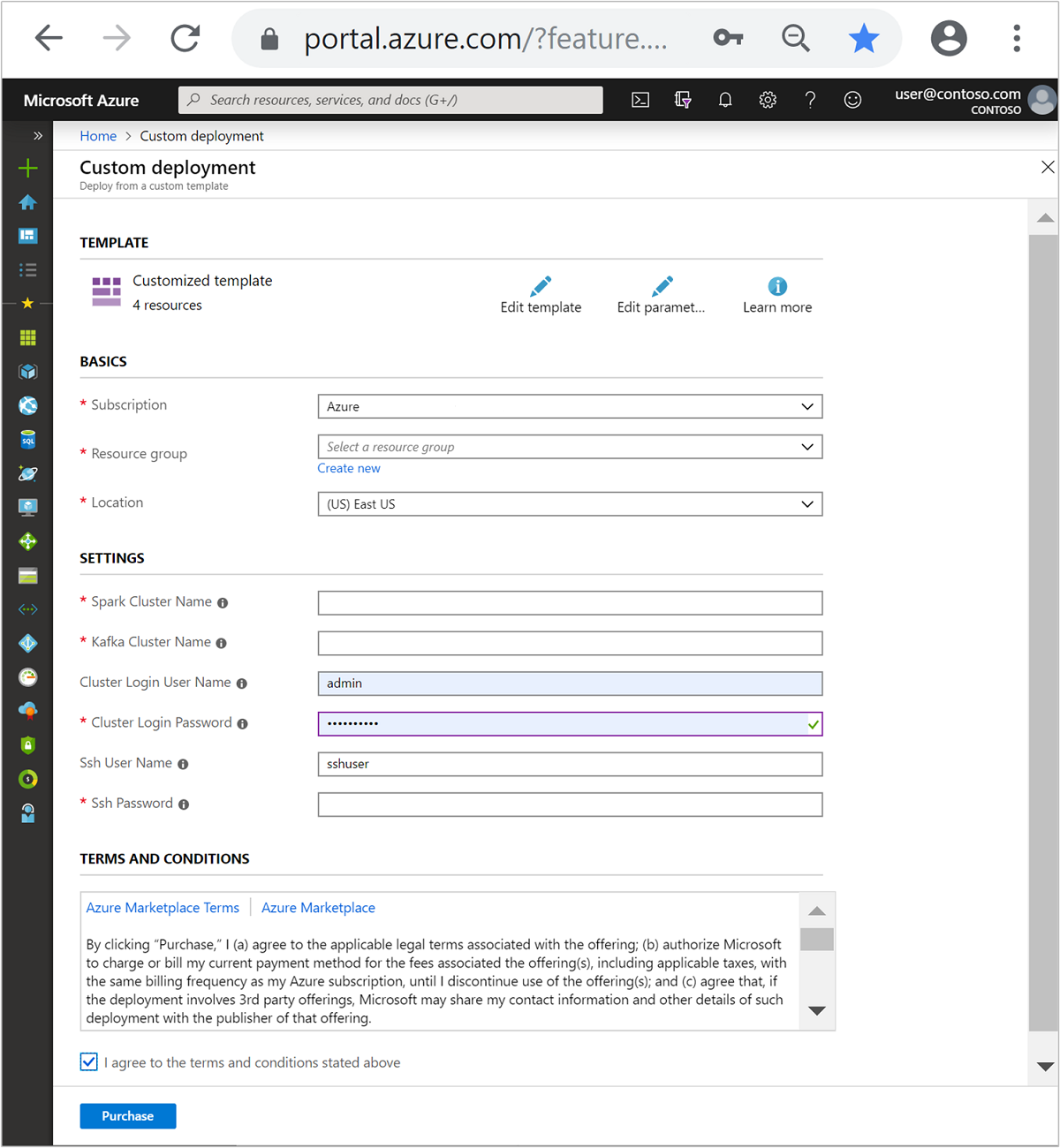
Lees de voorwaarden en schakel vervolgens het selectievakje Ik ga akkoord met de bovenstaande voorwaarden in.
Selecteer Aankoop.
Notitie
Het kan 20 minuten duren voordat het cluster is gemaakt.
Spark Structured Streaming gebruiken
In dit voorbeeld wordt aangegeven hoe u Spark Structured Streaming kunt gebruiken met Kafka in HDInsight. Hierin worden gegevens van taxiritten in New York gebruikt. De gegevensset die door dit notebook wordt gebruikt, betreft de ritgegevens uit 2016 van Green Taxi.
Verzamel informatie over de host. Gebruik de onderstaande curl- en jq-opdrachten om uw Kafka ZooKeeper- en Kafka-brokerhostgegevens op te halen. De opdrachten zijn ontworpen voor een Windows-opdrachtprompt. Voor andere omgevingen zijn iets andere opdrachten nodig. Vervang
KafkaClusterdoor de naam van uw Kafka-cluster, en vervangKafkaPassworddoor het wachtwoord voor aanmelding bij het cluster. Vervang ookC:\HDI\jq-win64.exedoor het werkelijke pad naar uw jq-installatie. Voer de opdrachten in een Windows-opdrachtprompt in en sla de uitvoer op voor gebruik in latere stappen.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"Navigeer in een webbrowser naar
https://CLUSTERNAME.azurehdinsight.net/jupyter, waarbijCLUSTERNAMEde naam van uw cluster is. Typ desgevraagd de cluster-aanmelding (beheerder) en het cluster-wachtwoord die u hebt gebruikt bij het maken van het cluster.Selecteer Nieuwe > Spark om een notebook te maken.
Spark streaming maakt gebruik van microbatchverwerking, wat betekent dat gegevens worden aangeleverd in batches en executers worden uitgevoerd op de batches met gegevens. Als de time-out wegens inactiviteit van de executor korter is dan de tijd die nodig is om de batch te verwerken, wordt de executor voortdurend toegevoegd en verwijderd. Als de time-out wegens inactiviteit van de executor groter is dan de batchduur, wordt de executor nooit verwijderd. Daarom wordt aanbevolen om dynamische toewijzing uit te schakelen door spark.dynamicAllocation.enabled in te stellen op false tijdens het uitvoeren van streaming-toepassingen.
Laad pakketten die door het Notebook worden gebruikt door de volgende informatie in te voeren in een Notebook-cel. Voer de opdracht uit met Ctrl+Enter.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Maak het Kafka-onderwerp. Bewerk de onderstaande opdracht door
YOUR_ZOOKEEPER_HOSTSte vervangen door de Zookeeper-hostgegevens die in de eerste stap zijn geëxtraheerd. Voer de bewerkte opdracht in uw Jupyter Notebook in om het onderwerptripdatate maken.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersHaal de gegevens over de taxiritten op. Voer de opdracht in de volgende cel in om de gegevens over taxiritten in New York te laden. De gegevens worden in een gegevensframe geladen en vervolgens wordt de gegevensframe weergegeven als de uitvoer van de cel.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Stel de Kafka-brokerhostgegevens in. Vervang
YOUR_KAFKA_BROKER_HOSTSdoor de brokerhostgegevens die u in stap 1 hebt geëxtraheerd. Voer de bewerkte opdracht in de volgende Jupyter Notebook-cel in.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")Verzend de gegevens naar Kafka. In de volgende opdracht wordt het veld
vendoridgebruikt als de sleutelwaarde voor het Kafka-bericht. De sleutel wordt door Kafka gebruikt bij het partitioneren van gegevens. Alle velden worden opgeslagen in het Kafka-bericht als een JSON-tekenreekswaarde. Voer de volgende opdracht in Jupyter in om de gegevens op te slaan in Kafka met behulp van een batchquery.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")Declareer een schema. De volgende opdracht laat zien hoe u een schema kunt gebruiken bij het lezen van JSON-gegevens uit Kafka. Voer de opdracht in de volgende Jupyter-cel in.
// Import bits used for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")Selecteer gegevens en start de stroom. De volgende opdracht laat zien hoe u gegevens ophaalt uit Kafka met behulp van een batchquery. Schrijf de resultaten vervolgens naar HDFS op het Spark-cluster. In dit voorbeeld wordt het bericht (waardeveld) met
selectuit Kafka opgehaald en wordt het schema erop toegepast. De gegevens worden vervolgens naar HDFS (WASB of ADL) geschreven in Parquet-indeling. Voer de opdracht in de volgende Jupyter-cel in.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")U kunt controleren of de bestanden zijn gemaakt door de opdracht in uw volgende Jupyter-cel in te voeren. Hiermee worden de bestanden in de map
/example/batchtripdataweergegeven.%%bash hdfs dfs -ls /example/batchtripdataIn het vorige voorbeeld is een batchquery gebruikt, maar de volgende opdracht laat zien hoe u hetzelfde kunt doen met behulp van een streamingquery. Voer de opdracht in de volgende Jupyter-cel in.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")Voer de volgende cel uit om te controleren of de bestanden zijn geschreven door de streamingquery.
%%bash hdfs dfs -ls /example/streamingtripdata
Resources opschonen
Als u de in deze zelfstudie gemaakte resources wilt opschonen, kunt u de resourcegroep verwijderen. Als u de resourcegroep verwijdert, wordt ook het bijbehorende HDInsight-cluster verwijderd. Ook alle overige resources die aan de resourcegroep zijn gekoppeld, worden verwijderd.
Ga als volgt te werk om de resourcegroep te verwijderen in Azure Portal:
- Vouw het menu aan de linkerkant in Azure Portal uit om het menu met services te openen en kies Resourcegroepen om de lijst met resourcegroepen weer te geven.
- Zoek de resourcegroep die u wilt verwijderen en klik met de rechtermuisknop op de knop Meer (... ) aan de rechterkant van de vermelding.
- Selecteer Resourcegroep verwijderen en bevestig dit.
Waarschuwing
De facturering voor het gebruik van HDInsight-clusters begint zodra er een cluster is gemaakt en stopt als een cluster wordt verwijderd. De facturering wordt pro-rato per minuut berekend, dus u moet altijd uw cluster verwijderen wanneer het niet meer wordt gebruikt.
Door een Kafka in HDInsight-cluster te verwijderen, worden alle gegevens verwijderd die zijn opgeslagen in Kafka.