Beschrijving en verwerkingsstappen van RAG-gegevenspijplijn
In dit artikel leert u hoe u ongestructureerde gegevens voorbereidt voor gebruik in RAG-toepassingen. Ongestructureerde gegevens verwijzen naar gegevens zonder een specifieke structuur of organisatie, zoals PDF-documenten met tekst en afbeeldingen, of multimedia-inhoud zoals audio of video's.
Ongestructureerde gegevens ontbreken een vooraf gedefinieerd gegevensmodel of schema, waardoor het onmogelijk is om alleen op basis van structuur en metagegevens query's uit te voeren. Als gevolg hiervan zijn ongestructureerde gegevens technieken vereist die semantische betekenis kunnen begrijpen en extraheren uit onbewerkte tekst, afbeeldingen, audio of andere inhoud.
Tijdens het voorbereiden van gegevens worden onbewerkte ongestructureerde gegevens door de RAG-toepassingsgegevenspijplijn omgezet in afzonderlijke segmenten die kunnen worden opgevraagd op basis van hun relevantie voor de query van een gebruiker. De belangrijkste stappen in het voorverwerken van gegevens worden hieronder beschreven. Elke stap heeft een verscheidenheid aan knoppen die kunnen worden afgestemd - voor een diepere bespreking van deze knoppen raadpleegt u de kwaliteit van de RAG-toepassing verbeteren.
Ongestructureerde gegevens voorbereiden voor ophalen
In de rest van deze sectie beschrijven we het proces voor het voorbereiden van ongestructureerde gegevens voor het ophalen met behulp van semantische zoekopdrachten. Semantische zoekopdrachten begrijpen de contextuele betekenis en intentie van een gebruikersquery om relevantere zoekresultaten te bieden.
Semantisch zoeken is een van de verschillende benaderingen die kunnen worden gebruikt bij het implementeren van het ophaalonderdeel van een RAG-toepassing over ongestructureerde gegevens. Deze documenten hebben betrekking op alternatieve ophaalstrategieën in de sectie voor het ophalen van knoppen.
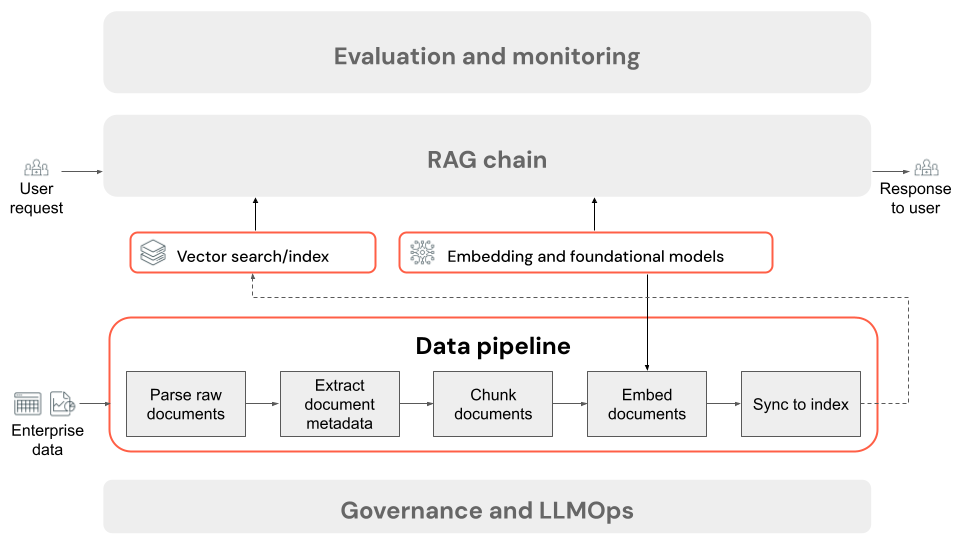
Stappen van een RAG-toepassingsgegevenspijplijn
Hier volgen de typische stappen van een gegevenspijplijn in een RAG-toepassing met behulp van ongestructureerde gegevens:
- De onbewerkte documenten parseren: de eerste stap omvat het transformeren van onbewerkte gegevens in een bruikbare indeling. Dit kan bestaan uit het extraheren van tekst, tablesen afbeeldingen uit een verzameling PDF-bestanden of het gebruik van OCR-technieken (Optical Character Recognition) om tekst uit afbeeldingen te extraheren.
- Documentmetagegevens extraheren (optioneel): in sommige gevallen kunnen documentmetagegevens worden geëxtraheerd en gebruikt, zoals documenttitels, paginanummers, URL's of andere informatie, zodat de juiste gegevens nauwkeuriger kunnen worden opgehaald.
- segmentdocumenten: om ervoor te zorgen dat de geparseerde documenten in het insluitmodel en de context windowvan de LLM passen, splitsen we de geparseerde documenten op in kleinere, discrete segmenten. Het ophalen van deze gerichte segmenten, in plaats van volledige documenten, geeft de LLM meer gerichte context waaruit de antwoorden moeten worden generate.
- Segmenten insluiten: In een RAG-toepassing die gebruikmaakt van semantische zoekopdrachten, transformeert een speciaal type taalmodel dat een insluitmodel wordt genoemd, elk van de segmenten uit de vorige stap in numerieke vectoren of lijsten met getallen, die de betekenis van elk deel van de inhoud inkapselen. Cruciaal is dat deze vectoren de semantische betekenis van de tekst vertegenwoordigen, niet alleen trefwoorden op oppervlakniveau. Hiermee kunt u zoeken op basis van betekenis in plaats van letterlijke tekstovereenkomsten.
- Indexsegmenten in een vectordatabase: de laatste stap is het laden van de vectorweergaven van de segmenten, samen met de tekst van het segment, in een vectordatabase. Een vectordatabase is een gespecialiseerd type database dat is ontworpen om vectorgegevens, zoals insluitingen, efficiënt op te slaan en te zoeken. Om de prestaties met een groot aantal segmenten te behouden, bevatten vectordatabases meestal een vectorindex die gebruikmaakt van verschillende algoritmen om de vector-insluitingen op een manier te organiseren en toe te wijzen op een manier die de zoekefficiëntie optimaliseert. Tijdens de query wordt de aanvraag van een gebruiker ingesloten in een vector en maakt de database gebruik van de vectorindex om de meest vergelijkbare segmentvectoren te vinden, die de bijbehorende oorspronkelijke tekstsegmenten retourneren.
Het rekenproces van overeenkomsten kan rekenkundig duur zijn. Vectorindexen, zoals Databricks Vector Search, versnellen dit proces door een mechanisme te bieden voor het efficiënt ordenen en navigeren van insluitingen, vaak via geavanceerde methoden voor benadering. Hierdoor kunnen de meest relevante resultaten snel worden gerangschikt zonder dat elke insluiting afzonderlijk wordt vergeleken met de query van de gebruiker.
Elke stap in de gegevenspijplijn omvat technische beslissingen die van invloed zijn op de kwaliteit van de RAG-toepassing. Als u bijvoorbeeld de juiste segmentgrootte in stap 3 kiest, zorgt u ervoor dat de LLM specifieke maar contextuele informatie ontvangt, terwijl het selecteren van een geschikt insluitingsmodel in stap 4 de nauwkeurigheid bepaalt van de segmenten die worden geretourneerd tijdens het ophalen.
Dit proces voor gegevensvoorbereiding wordt offlinegegevensvoorbereiding genoemd, zoals het gebeurt voordat de systeemquery's beantwoordt, in tegenstelling tot de onlinestappen die worden geactiveerd wanneer een gebruiker een query indient.