Rag-ketenkwaliteit verbeteren
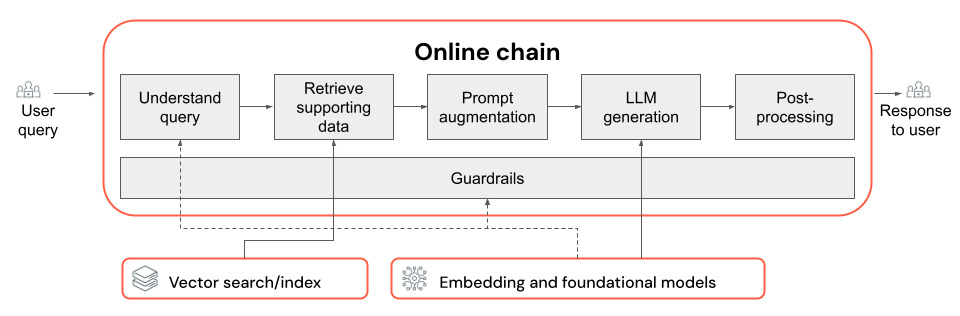
In dit artikel wordt beschreven hoe u de kwaliteit van de RAG-app kunt verbeteren met behulp van onderdelen van de RAG-keten.
De RAG-keten neemt een gebruikersquery op als invoer, haalt relevante informatie op die query is opgegeven en genereert een geschikt antwoord dat is gebaseerd op de opgehaalde gegevens. Hoewel de exacte stappen binnen een RAG-keten sterk kunnen variëren, afhankelijk van de use-case en vereisten, zijn het volgende de belangrijkste onderdelen die u moet overwegen bij het bouwen van uw RAG-keten:
- Inzicht in query's: gebruikersquery's analyseren en transformeren om de intentie beter weer te geven en relevante informatie, zoals filters of trefwoorden, te extraheren om het ophaalproces te verbeteren.
- Ophalen: de meest relevante segmenten van informatie vinden op basis van een ophaalquery. In het geval van ongestructureerde gegevens is dit meestal een of een combinatie van semantische of op trefwoorden gebaseerde zoekopdrachten.
- Prompt-uitbreiding: een gebruikersquery combineren met opgehaalde informatie en instructies om de LLM te begeleiden bij het genereren van antwoorden van hoge kwaliteit.
- LLM: Het selecteren van het meest geschikte model (en modelparameters) voor uw toepassing om de prestaties, latentie en kosten te optimaliseren/te verdelen.
- Naverwerking en kaders: Aanvullende verwerkingsstappen en veiligheidsmaatregelen toepassen om ervoor te zorgen dat de door LLM gegenereerde reacties on-topic, feitelijk consistent zijn en voldoen aan specifieke richtlijnen of beperkingen.
Iteratief implementeren en kwaliteitscorrecties evalueren laat zien hoe u de onderdelen van een keten kunt herhalen.
Inzicht in query's
Het rechtstreeks gebruiken van de gebruikersquery als een ophaalquery kan voor sommige query's werken. Het is echter over het algemeen nuttig om de query opnieuw te formatteren vóór de stap voor het ophalen. Querybegrip bestaat uit een stap (of reeks stappen) aan het begin van een keten om gebruikersquery's te analyseren en transformeren om de intentie beter weer te geven, relevante informatie te extraheren en uiteindelijk het volgende proces te helpen ophalen. Benaderingen voor het transformeren van een gebruikersquery om het ophalen te verbeteren zijn:
Query herschrijven: bij het herschrijven van query's wordt een gebruikersquery omgezet in een of meer query's die de oorspronkelijke intentie beter vertegenwoordigen. Het doel is om de query opnieuw te formatteren op een manier die de kans vergroot dat de stap voor het ophalen van de meest relevante documenten wordt gevonden. Dit kan met name handig zijn bij het verwerken van complexe of dubbelzinnige query's die mogelijk niet rechtstreeks overeenkomen met de terminologie die wordt gebruikt in de ophaaldocumenten.
Voorbeelden:
- Gespreksgeschiedenis parafraseren in een chat met meerdere paden
- Spelfouten corrigeren in de query van de gebruiker
- Woorden of woordgroepen in de gebruikersquery vervangen door synoniemen om een breder scala aan relevante documenten vast te leggen
Belangrijk
Het herschrijven van query's moet worden uitgevoerd in combinatie met wijzigingen in het ophaalonderdeel
Filterextractie: in sommige gevallen kunnen gebruikersquery's specifieke filters of criteria bevatten die kunnen worden gebruikt om de zoekresultaten te verfijnen. Filterextractie omvat het identificeren en extraheren van deze filters uit de query en het doorgeven ervan aan de stap voor ophalen als aanvullende parameters. Dit kan helpen de relevantie van de opgehaalde documenten te verbeteren door te focussen op specifieke subsets van de beschikbare gegevens.
Voorbeelden:
- Specifieke tijdsperioden extraheren die in de query worden vermeld, zoals 'artikelen uit de afgelopen 6 maanden' of 'rapporten uit 2023'.
- Vermeldingen van specifieke producten, services of categorieën in de query identificeren, zoals 'Databricks Professional Services' of 'laptops'.
- Geografische entiteiten extraheren uit de query, zoals plaatsnamen of landcodes.
Notitie
Filterextractie moet worden uitgevoerd in combinatie met wijzigingen in zowel de pijplijn voor metagegevensextractie als de onderdelen van de retriever-keten. De stap voor het extraheren van metagegevens moet ervoor zorgen dat de relevante metagegevensvelden beschikbaar zijn voor elk document/segment en dat de ophaalstap moet worden geïmplementeerd om geëxtraheerde filters te accepteren en toe te passen.
Naast het herschrijven en filteren van query's, is een andere belangrijke overweging bij het begrijpen van query's of het gebruik van één LLM-aanroep of meerdere aanroepen. Hoewel het gebruik van één aanroep met een zorgvuldig samengestelde prompt efficiënt kan zijn, kunnen er gevallen zijn waarin het proces voor het begrijpen van query's in meerdere LLM-aanroepen tot betere resultaten kan leiden. Dit is trouwens een algemeen toepasselijke vuistregel wanneer u een aantal complexe logische stappen in één prompt probeert te implementeren.
U kunt bijvoorbeeld één LLM-aanroep gebruiken om de queryintentie te classificeren, een andere om relevante entiteiten te extraheren en een derde om de query opnieuw te schrijven op basis van de geëxtraheerde informatie. Hoewel deze benadering enige latentie kan toevoegen aan het algehele proces, kan dit een nauwkeuriger beheer mogelijk maken en de kwaliteit van de opgehaalde documenten mogelijk verbeteren.
Kennis van query's met meerdere taken voor een ondersteuningsbot
Hier ziet u hoe een querybegriponderdeel met meerdere stappen kan zoeken naar een klantondersteuningsbot:
- Intentieclassificatie: gebruik een LLM om de query van de gebruiker te classificeren in vooraf gedefinieerde categorieën, zoals 'productgegevens', 'probleemoplossing' of 'accountbeheer'.
- Entiteitextractie: gebruik op basis van de geïdentificeerde intentie een andere LLM-aanroep om relevante entiteiten uit de query te extraheren, zoals productnamen, gerapporteerde fouten of accountnummers.
- Query's herschrijven: Gebruik de geëxtraheerde intentie en entiteiten om de oorspronkelijke query opnieuw te schrijven in een specifiekere en gerichte indeling, bijvoorbeeld :'Mijn RAG-keten kan niet worden geïmplementeerd in Model Serving, ik zie de volgende fout...'.
Ophalen
Het ophaalonderdeel van de RAG-keten is verantwoordelijk voor het vinden van de meest relevante gegevenssegmenten op basis van een ophaalquery. In de context van ongestructureerde gegevens omvat het ophalen meestal een of een combinatie van semantische zoekopdrachten, zoekopdrachten op basis van trefwoorden en het filteren van metagegevens. De keuze voor het ophalen van een strategie is afhankelijk van de specifieke vereisten van uw toepassing, de aard van de gegevens en de typen query's die u verwacht te verwerken. Laten we deze opties vergelijken:
- Semantische zoekopdracht: Semantisch zoeken maakt gebruik van een insluitmodel om elk stuk tekst te converteren naar een vectorweergave die de semantische betekenis vastlegt. Door de vectorweergave van de ophaalquery te vergelijken met de vectorweergaven van de segmenten, kan semantische zoekopdracht conceptueel vergelijkbare documenten ophalen, zelfs als ze niet de exacte trefwoorden uit de query bevatten.
- Zoekopdracht op basis van trefwoorden: Zoekopdracht op basis van trefwoorden bepaalt de relevantie van documenten door de frequentie en verdeling van gedeelde woorden tussen de ophaalquery en de geïndexeerde documenten te analyseren. Hoe vaker dezelfde woorden worden weergegeven in zowel de query als een document, hoe hoger de relevantiescore die aan dat document is toegewezen.
- Hybride zoeken: Hybride zoeken combineert de sterke punten van zowel semantische als op trefwoorden gebaseerde zoekopdrachten door gebruik te maken van een proces voor het ophalen in twee stappen. Eerst voert het een semantische zoekopdracht uit om een set conceptuele relevante documenten op te halen. Vervolgens wordt zoekopdracht op basis van trefwoorden toegepast op deze gereduceerde set om de resultaten verder te verfijnen op basis van exacte trefwoordovereenkomsten. Ten slotte worden de scores uit beide stappen gecombineerd om de documenten te rangschikken.
Strategieën voor ophalen vergelijken
De volgende tabel contrasteert elk van deze strategieën voor ophalen tegen elkaar:
| Semantische zoekopdrachten | Zoeken op trefwoord | Hybride zoekopdracht | |
|---|---|---|---|
| Eenvoudige uitleg | Als dezelfde concepten worden weergegeven in de query en een mogelijk document, zijn ze relevant. | Als dezelfde woorden in de query en een mogelijk document worden weergegeven, zijn ze relevant. Hoe meer woorden uit de query in het document, hoe relevanter dat document is. | Voert zowel een semantische zoekopdracht als trefwoordzoekopdracht uit en combineert vervolgens de resultaten. |
| Voorbeeld van use case | Klantondersteuning waarbij gebruikersquery's verschillen van de woorden in de producthandleidingen. Voorbeeld: 'Hoe schakel ik mijn telefoon in?' en de handmatige sectie heet "schakelen tussen de macht". | Klantondersteuning waarbij query's specifieke, niet beschrijvende technische termen bevatten. Voorbeeld: "Wat doet model HD7-8D?" | Klantenondersteuningsquery's die zowel semantische als technische termen hebben gecombineerd. Voorbeeld: "Hoe schakel ik mijn HD7-8D in?" |
| Technische benaderingen | Maakt gebruik van insluitingen om tekst in een continue vectorruimte weer te geven, waardoor semantische zoekopdrachten mogelijk zijn. | Is afhankelijk van discrete op tokens gebaseerde methoden zoals bag-of-words, TF-IDF, BM25 voor trefwoordkoppeling. | Gebruik een herclassificatiebenadering om de resultaten te combineren, zoals wederzijdse rangschikkingsfusie of een herclassificatiemodel. |
| Sterktes | Het ophalen van contextuele vergelijkbare informatie als een query, zelfs als de exacte woorden niet worden gebruikt. | Scenario's waarvoor nauwkeurige trefwoordovereenkomsten zijn vereist, ideaal voor specifieke query's met een term, zoals productnamen. | Combineert het beste van beide benaderingen. |
Manieren om het ophaalproces te verbeteren
Naast deze kernstrategieën voor het ophalen zijn er verschillende technieken die u kunt toepassen om het ophaalproces verder te verbeteren:
- Queryuitbreiding: Queryuitbreiding kan helpen bij het vastleggen van een breder scala aan relevante documenten met behulp van meerdere variaties van de ophaalquery. Dit kan worden bereikt door afzonderlijke zoekopdrachten uit te voeren voor elke uitgebreide query of door een samenvoeging te gebruiken van alle uitgebreide zoekquery's in één ophaaltquery.
Notitie
Query-uitbreiding moet worden uitgevoerd in combinatie met wijzigingen in het onderdeel Query Understanding (RAG-keten). In deze stap worden doorgaans meerdere variaties van een ophaalquery gegenereerd.
- Opnieuw rangschikken: pas na het ophalen van een eerste set segmenten aanvullende classificatiecriteria toe (bijvoorbeeld sorteren op tijd) of een rerankermodel om de resultaten opnieuw te ordenen. Opnieuw rangschikken kan helpen bij het prioriteren van de meest relevante segmenten op basis van een specifieke ophaalquery. Rerankering met cross-encoder modellen zoals mxbai-rerank en ColBERTv2 kan een uplift opleveren bij het ophalen van prestaties.
- Metagegevens filteren: gebruik metagegevensfilters die zijn geëxtraheerd uit de stap voor het begrijpen van query's om de zoekruimte te verfijnen op basis van specifieke criteria. Metagegevensfilters kunnen kenmerken bevatten, zoals documenttype, aanmaakdatum, auteur of domeinspecifieke tags. Door metagegevensfilters te combineren met semantische of op trefwoorden gebaseerde zoekopdrachten, kunt u gerichtere en efficiëntere ophaalbewerkingen maken.
Notitie
Het filteren van metagegevens moet worden uitgevoerd in combinatie met wijzigingen in de onderdelen van de query understanding (RAG-keten) en metagegevensextractie (gegevenspijplijn).
Prompt-uitbreiding
Prompt-uitbreiding is de stap waarbij de gebruikersquery wordt gecombineerd met de opgehaalde informatie en instructies in een promptsjabloon om het taalmodel te begeleiden bij het genereren van antwoorden van hoge kwaliteit. Herhalen op deze sjabloon om de prompt die aan de LLM (AKA prompt engineering) wordt gegeven, te optimaliseren, is vereist om ervoor te zorgen dat het model wordt begeleid bij het produceren van nauwkeurige, geaarde en coherente reacties.
Er zijn volledige handleidingen voor het vragen van engineering, maar hier volgen enkele overwegingen waarmee u rekening moet houden wanneer u de promptsjabloon doorgeeft:
- Voorbeelden opgeven
- Voorbeelden van goed gevormde query's en de bijbehorende ideale antwoorden in de promptsjabloon zelf (weinig-shot learning). Dit helpt het model inzicht te krijgen in de gewenste indeling, stijl en inhoud van de antwoorden.
- Een handige manier om goede voorbeelden te krijgen, is het identificeren van typen query's waarmee uw keten worstelt. Maak standaardantwoorden voor deze query's en neem ze op als voorbeelden in de prompt.
- Zorg ervoor dat de voorbeelden die u opgeeft, representatief zijn voor gebruikersquery's die u verwacht tijdens deductietijd. Doel is om een breed scala aan verwachte query's te behandelen om het model beter te generaliseren.
- De promptsjabloon parameteriseren
- Ontwerp uw promptsjabloon om flexibel te zijn door deze te parameteriseren om aanvullende informatie op te nemen buiten de opgehaalde gegevens en gebruikersquery. Dit kunnen variabelen zijn, zoals huidige datum, gebruikerscontext of andere relevante metagegevens.
- Het injecteren van deze variabelen in de prompt tijdens deductietijd kan meer persoonlijke of contextbewuste antwoorden inschakelen.
- Houd rekening met ketting-van-gedachte-prompting
- Voor complexe query's waarbij directe antwoorden niet direct duidelijk zijn, kunt u coT-vragen (Chain-of-Thought) overwegen. Met deze prompt engineeringstrategie worden ingewikkelde vragen onderverdeeld in eenvoudigere, opeenvolgende stappen, waarbij de LLM wordt geleid door een logisch redeneringsproces.
- Door het model te vragen om stapsgewijs na te denken over het probleem, moedigt u het aan om gedetailleerdere en goed onderbouwde antwoorden te bieden, die met name effectief kunnen zijn voor het verwerken van query's met meerdere stappen of open-einden.
- Prompts worden mogelijk niet overgedragen tussen modellen
- Herkennen dat prompts vaak niet naadloos worden overgedragen over verschillende taalmodellen. Elk model heeft zijn eigen unieke kenmerken, waarbij een prompt die goed werkt voor één model mogelijk niet zo effectief is voor een ander model.
- Experimenteer met verschillende promptindelingen en lengten, raadpleeg onlinegidsen (zoals OpenAI Cookbook of Lantropisch kookboek) en wees voorbereid om uw prompts aan te passen en te verfijnen bij het schakelen tussen modellen.
LLM
Het generatieonderdeel van de RAG-keten neemt de uitgebreide promptsjabloon uit de vorige stap en geeft deze door aan een LLM. Wanneer u een LLM selecteert en optimaliseert voor het generatieonderdeel van een RAG-keten, moet u rekening houden met de volgende factoren, die evenzeer van toepassing zijn op andere stappen die betrekking hebben op LLM-aanroepen:
- Experimenteer met verschillende off-the-shelf modellen.
- Elk model heeft zijn eigen unieke eigenschappen, sterke punten en zwakke punten. Sommige modellen hebben mogelijk een beter inzicht in bepaalde domeinen of werken beter voor specifieke taken.
- Zoals eerder vermeld, moet u er rekening mee houden dat de keuze van het model ook van invloed kan zijn op het prompt engineeringproces, omdat verschillende modellen anders kunnen reageren op dezelfde prompts.
- Als er meerdere stappen in uw keten zijn die een LLM vereisen, zoals aanroepen voor het begrijpen van query's naast de generatiestap, kunt u overwegen om verschillende modellen te gebruiken voor verschillende stappen. Duurdere, algemene modellen kunnen overkill zijn voor taken, zoals het bepalen van de intentie van een gebruikersquery.
- Begin zo nodig klein en schaal omhoog.
- Hoewel het verleidelijk kan zijn om onmiddellijk te bereiken voor de krachtigste en geschikte modellen die beschikbaar zijn (bijvoorbeeld GPT-4, Claude), is het vaak efficiënter om te beginnen met kleinere, lichtgewicht modellen.
- In veel gevallen kunnen kleinere opensource-alternatieven, zoals Llama 3 of DBRX, bevredigende resultaten opleveren tegen lagere kosten en met snellere deductietijden. Deze modellen kunnen bijzonder effectief zijn voor taken waarvoor geen zeer complexe redenering of uitgebreide wereldkennis nodig is.
- Wanneer u uw RAG-keten ontwikkelt en verfijnt, beoordeelt u continu de prestaties en beperkingen van het gekozen model. Als u merkt dat het model worstelt met bepaalde typen query's of onvoldoende gedetailleerde of nauwkeurige antwoorden kan bieden, kunt u overwegen om omhoog te schalen naar een geschikter model.
- Bewaak de impact van het wijzigen van modellen op belangrijke metrische gegevens, zoals responskwaliteit, latentie en kosten om ervoor te zorgen dat u het juiste evenwicht vindt voor de vereisten van uw specifieke use-case.
- Modelparameters optimaliseren
- Experimenteer met verschillende parameterinstellingen om de optimale balans te vinden tussen responskwaliteit, diversiteit en samenhang. Het aanpassen van de temperatuur kan bijvoorbeeld de willekeurigheid van de gegenereerde tekst regelen, terwijl max_tokens de antwoordlengte kan beperken.
- Houd er rekening mee dat de optimale parameterinstellingen kunnen variëren, afhankelijk van de specifieke taak, prompt en gewenste uitvoerstijl. Test deze instellingen iteratief en verfijn deze op basis van de evaluatie van de gegenereerde antwoorden.
- Taakspecifieke afstemming
- Wanneer u de prestaties verfijnt, kunt u kleinere modellen verfijnen voor specifieke subtaken binnen uw RAG-keten, zoals het begrijpen van query's.
- Door gespecialiseerde modellen te trainen voor afzonderlijke taken met de RAG-keten, kunt u de algehele prestaties verbeteren, latentie verminderen en lagere deductiekosten in vergelijking met het gebruik van één groot model voor alle taken.
- Vervolgtraining
- Als uw RAG-toepassing werkt met een gespecialiseerd domein of kennis vereist die niet goed wordt weergegeven in de vooraf getrainde LLM, kunt u overwegen om voortgezette pretraining (CPT) uit te voeren op domeinspecifieke gegevens.
- Verdere training kan het begrip van specifieke terminologie of concepten die uniek zijn voor uw domein verbeteren door een model te verbeteren. Op zijn beurt kan dit de behoefte aan uitgebreide prompt engineering of weinig-shot voorbeelden verminderen.
Naverwerking en kaders
Nadat de LLM een antwoord heeft gegenereerd, is het vaak nodig om naverwerkingstechnieken of kaders toe te passen om ervoor te zorgen dat de uitvoer voldoet aan de gewenste indeling, stijl en inhoudsvereisten. Deze laatste stap (of meerdere stappen) in de keten kan helpen consistentie en kwaliteit te behouden voor de gegenereerde antwoorden. Als u naverwerking en kaders implementeert, kunt u een aantal van de volgende zaken overwegen:
- Uitvoerindeling afdwingen
- Afhankelijk van uw gebruiksscenario moet u mogelijk de gegenereerde antwoorden vereisen om te voldoen aan een specifieke indeling, zoals een gestructureerde sjabloon of een bepaald bestandstype (zoals JSON, HTML, Markdown, enzovoort).
- Als gestructureerde uitvoer vereist is, bieden bibliotheken zoals Docenten of Overzichten goede uitgangspunten om dit type validatiestap te implementeren.
- Neem bij het ontwikkelen tijd om ervoor te zorgen dat de naverwerkingsstap flexibel genoeg is om variaties in de gegenereerde antwoorden af te handelen terwijl de vereiste indeling behouden blijft.
- Stijlconsistentie behouden
- Als uw RAG-toepassing specifieke stijlrichtlijnen of toonvereisten heeft (bijvoorbeeld formele versus informele, beknopte versus gedetailleerde), kan een naverwerkingsstap deze stijlkenmerken controleren en afdwingen voor gegenereerde antwoorden.
- Inhoudsfilters en veiligheidsbescherming
- Afhankelijk van de aard van uw RAG-toepassing en de mogelijke risico's die verband houden met gegenereerde inhoud, kan het belangrijk zijn om inhoudsfilters of veiligheidsbescherming te implementeren om de uitvoer van ongepaste, aanstootgevende of schadelijke informatie te voorkomen.
- Overweeg het gebruik van modellen zoals Llama Guard of API's die speciaal zijn ontworpen voor con tentmodus ration en veiligheid, zoals de beheer-API van OpenAI, om veiligheidsrails te implementeren.
- Halluïnaties verwerken
- Het verdedigen tegen halluinaties kan ook worden geïmplementeerd als een naverwerkingsstap. Dit kan betrekking hebben op kruisverwijzingen naar de gegenereerde uitvoer met opgehaalde documenten of het gebruik van extra LLM's om de feitelijke nauwkeurigheid van het antwoord te valideren.
- Ontwikkel terugvalmechanismen voor het afhandelen van gevallen waarin het gegenereerde antwoord niet voldoet aan de feitelijke nauwkeurigheidsvereisten, zoals het genereren van alternatieve antwoorden of het verstrekken van disclaimers aan de gebruiker.
- Foutafhandeling
- Met eventuele naverwerkingsstappen implementeert u mechanismen om probleemloos af te handelen in gevallen waarin de stap een probleem tegenkomt of een bevredigend antwoord niet kan genereren. Dit kan betrekking hebben op het genereren van een standaardreactie of het escaleren van het probleem naar een menselijke operator voor handmatige controle.