Rag-toepassingskwaliteit verbeteren
Dit artikel bevat een overzicht van hoe u elk onderdeel kunt verfijnen om de kwaliteit van uw rag-toepassing (Augmented Generation) te verhogen.
Er zijn talloze 'knoppen' om op elk punt in zowel de offline gegevenspijplijn als de online RAG-keten af te stemmen. Hoewel er talloze andere zijn, richt het artikel zich op de belangrijkste knoppen die de grootste impact hebben op de kwaliteit van uw RAG-toepassing. Databricks raadt aan om te beginnen met deze knoppen.
Twee soorten kwaliteitsoverwegingen
Vanuit een conceptueel oogpunt is het handig om RAG-kwaliteitsknoppen te bekijken via de lens van de twee belangrijke kwaliteitsproblemen:
Kwaliteit ophalen: zoekt u de meest relevante informatie voor een bepaalde ophaalquery?
Het is moeilijk om rag-uitvoer van hoge kwaliteit te genereren als er belangrijke informatie ontbreekt in de context die aan de LLM wordt verstrekt of overbodige informatie bevat.
Generatiekwaliteit: Gezien de opgehaalde informatie en de oorspronkelijke gebruikersquery, genereert de LLM de meest nauwkeurige, coherente en nuttige reactie mogelijk?
Problemen hier kunnen zich voordoen als halluinaties, inconsistente uitvoer of het rechtstreeks oplossen van de gebruikersquery.
RAG-apps hebben twee onderdelen die kunnen worden ge curseerd om kwaliteitsuitdagingen aan te pakken: gegevenspijplijn en de keten. Het is verleidelijk om uit te gaan van een schone verdeling tussen het ophalen van problemen (werk de gegevenspijplijn bij) en generatieproblemen (werk de RAG-keten bij). De realiteit is echter genuanceerder. De kwaliteit van het ophalen kan worden beïnvloed door zowel de gegevenspijplijn (bijvoorbeeld strategie voor parseren/segmenteren, metagegevensstrategie, insluitmodel) als de RAG-keten (bijvoorbeeld transformatie van gebruikersquery's, aantal opgehaalde segmenten, opnieuw rangschikken). Op dezelfde manier wordt de generatiekwaliteit altijd beïnvloed door slecht ophalen (bijvoorbeeld irrelevante of ontbrekende informatie die van invloed is op de modeluitvoer).
Deze overlap onderstreept de noodzaak van een holistische benadering van RAG-kwaliteitsverbetering. Door te begrijpen welke onderdelen moeten worden gewijzigd in zowel de gegevenspijplijn als de RAG-keten en hoe deze wijzigingen van invloed zijn op de algehele oplossing, kunt u gerichte updates aanbrengen om de rag-uitvoerkwaliteit te verbeteren.
Overwegingen voor de kwaliteit van gegevenspijplijnen
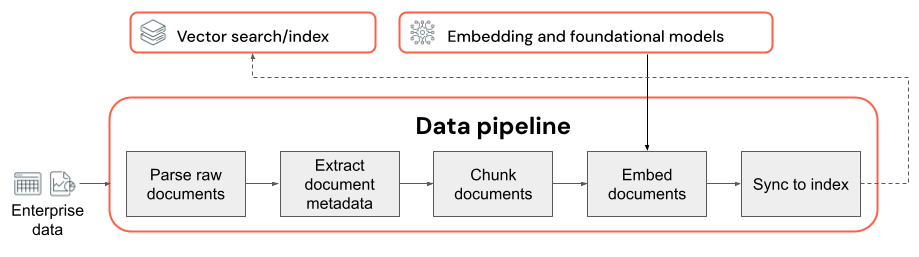
Belangrijke overwegingen over de gegevenspijplijn:
- De samenstelling van het invoergegevenslichaam.
- Hoe onbewerkte gegevens worden geëxtraheerd en getransformeerd in een bruikbare indeling (bijvoorbeeld het parseren van een PDF-document).
- Hoe documenten worden gesplitst in kleinere segmenten en hoe deze segmenten zijn opgemaakt (bijvoorbeeld segmenteringsstrategie en segmentgrootte).
- De metagegevens (zoals sectietitel of documenttitel) die zijn geëxtraheerd over elk document en/of segment. Hoe deze metagegevens worden opgenomen (of niet opgenomen) in elk segment.
- Het insluitmodel dat wordt gebruikt om tekst te converteren naar vectorweergaven voor zoekopdrachten naar overeenkomsten.
RAG-keten
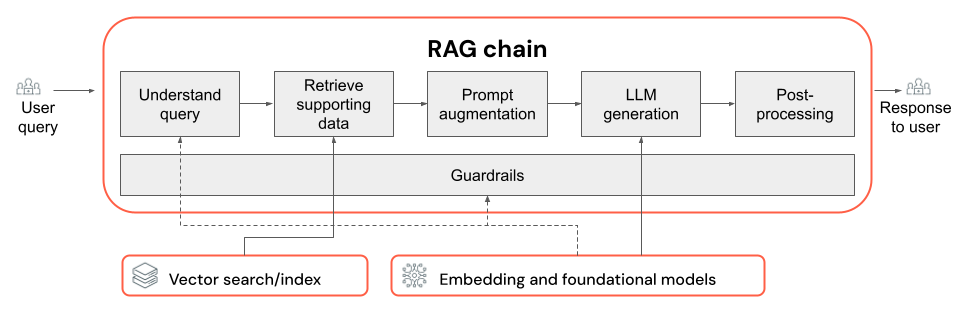
- De keuze van LLM en de bijbehorende parameters (bijvoorbeeld temperatuur- en maximumtokens).
- De parameters voor het ophalen (bijvoorbeeld het aantal segmenten of documenten dat is opgehaald).
- De ophaalbenadering (bijvoorbeeld trefwoord versus hybride versus semantische zoekopdrachten, herschrijven van de query van de gebruiker, het transformeren van de query van een gebruiker in filters of het opnieuw rangschikken).
- De prompt opmaken met de opgehaalde context om de LLM naar kwaliteitsuitvoer te leiden.