Mozaïek AI Vector Search
Dit artikel bevat een overzicht van de vectordatabaseoplossing van Databricks, Mozaïek AI Vector Search, inclusief wat het is en hoe het werkt.
Wat is Mozaïek AI Vector Search?
Mozaïek AI Vector Search is een vectordatabase die is ingebouwd in het Databricks Data Intelligence Platform en geïntegreerd met de governance- en productiviteitsprogramma's. Een vectordatabase is een database die is geoptimaliseerd voor het opslaan en ophalen van insluitingen. Insluitingen zijn wiskundige weergaven van de semantische inhoud van gegevens, meestal tekst- of afbeeldingsgegevens. Insluitingen worden gegenereerd door een groot taalmodel en vormen een belangrijk onderdeel van veel generatieve AI-toepassingen die afhankelijk zijn van het vinden van documenten of afbeeldingen die vergelijkbaar zijn met elkaar. Voorbeelden zijn RAG-systemen, aanbevelingssystemen en beeld- en videoherkenning.
Met Mozaïek AI Vector Search maakt u een vectorzoekindex van een Delta-tabel. De index bevat ingesloten gegevens met metagegevens. Vervolgens kunt u een query uitvoeren op de index met behulp van een REST API om de meest vergelijkbare vectoren te identificeren en de bijbehorende documenten te retourneren. U kunt de index zo structuren dat deze automatisch wordt gesynchroniseerd wanneer de onderliggende Delta-tabel wordt bijgewerkt.
Mozaïek AI Vector Search ondersteunt het volgende:
- Hybride trefwoord-overeenkomsten zoeken.
- Filteren.
- Toegangsbeheerlijsten (ACL's) voor het beheren van eindpunten voor vectorzoekopdrachten.
- alleen geselecteerde kolommen synchroniseren.
- gegenereerde insluitingen opslaan en synchroniseren.
Hoe werkt Mosaic AI Vector Search?
Mozaïek AI Vector Search maakt gebruik van het HNSW-algoritme (Hierarchical Navigable Small World) voor zijn benaderde dichtstbijzijnde burenzoekopdrachten en de L2-afstandsmetriek om de embedding vector-gelijkenis te meten. Als u cosinus-overeenkomsten wilt gebruiken, moet u de insluitingen van uw gegevenspunten normaliseren voordat u ze invoert in vectorzoekopdrachten. Wanneer de gegevenspunten worden genormaliseerd, is de rangorde die wordt geproduceerd door L2-afstand hetzelfde als de rangschikking veroorzaakt door cosinus-gelijkenis.
Mozaïek AI Vector Search biedt ook ondersteuning voor hybride zoekopdrachten op trefwoorden, waarbij vectorgebaseerde insluitingszoekopdrachten worden gecombineerd met traditionele zoektechnieken op basis van trefwoorden. Deze benadering komt overeen met exacte woorden in de query, terwijl ook een op vector gebaseerde vergelijkingsmethode wordt gebruikt om de semantische relaties en context van de query vast te leggen.
Door deze twee technieken te integreren, haalt hybride trefwoord-overeenkomsten zoeken documenten op die niet alleen de exacte trefwoorden bevatten, maar ook documenten die conceptueel vergelijkbaar zijn, waardoor uitgebreidere en relevante zoekresultaten worden geboden. Deze methode is met name nuttig in RAG-toepassingen waarbij brongegevens unieke trefwoorden hebben, zoals SKU's of id's die niet geschikt zijn voor pure overeenkomsten zoeken.
Zie de Python SDK-verwijzing en een vectorzoekeindpunt opvragen voor meer informatie over de API.
Berekening van overeenkomsten zoeken
In de berekening voor overeenkomsten zoeken wordt de volgende formule gebruikt:
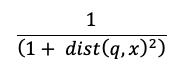
waarbij dist de Euclidische afstand tussen de query q en de indexvermelding is x:
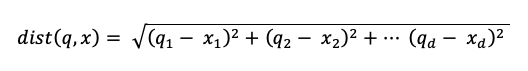
Zoekalgoritmen voor trefwoorden
Relevantiescores worden berekend met Okapi BM25. Alle tekst- of tekenreekskolommen, inclusief de embedding van de brontekst en metadatakolommen in tekst- of tekenreeksindeling, worden doorzocht. De tokenisatiefunctie splitst op woordgrenzen, verwijdert interpunctie en converteert alle tekst naar kleine letters.
Hoe overeenkomsten zoeken en zoeken op trefwoorden worden gecombineerd
De zoekresultaten voor overeenkomsten en trefwoorden worden gecombineerd met behulp van de functie Wederzijdse Rank Fusion (RRF).
RRF herscoret elk document van elke methode met behulp van de score:
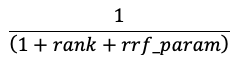
In de bovenstaande vergelijking begint rang bij 0, worden de scores voor elk document opgeteld en worden de hoogste scoredocumenten geretourneerd.
rrf_param bepaalt het relatieve belang van documenten met een hogere rang en een lagere rangschikking. Op basis van de literatuur is rrf_param ingesteld op 60.
Scores worden genormaliseerd zodat de hoogste score 1 is en de laagste score 0 is met behulp van de volgende vergelijking:
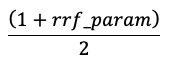
Opties voor het bieden van vector-insluitingen
Als u een vectordatabase wilt maken in Databricks, moet u eerst beslissen hoe vector-insluitingen moeten worden geboden. Databricks ondersteunt drie opties:
optie 1: Delta Sync-index met insluitingen die zijn berekend door Databricks U geeft een delta-brontabel op die gegevens in tekstindeling bevat. Databricks berekent de insluitingen met behulp van een model dat u opgeeft en slaat de insluitingen desgewenst op in een tabel in Unity Catalog. Wanneer de Delta-tabel wordt bijgewerkt, blijft de index gesynchroniseerd met de Delta-tabel.
In het volgende diagram ziet u het proces:
- Query-insluitingen berekenen. Query kan metagegevensfilters bevatten.
- Zoek naar overeenkomsten om de meest relevante documenten te identificeren.
- Retourneer de meest relevante documenten en voeg ze toe aan de query.
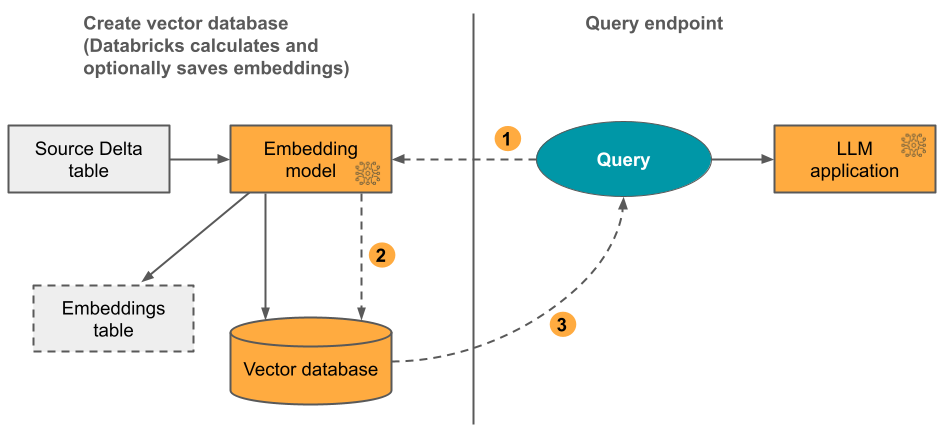
optie 2: Delta Sync-index met zelfbeheerde insluitingen U geeft een delta-brontabel op die vooraf berekende insluitingen bevat. Wanneer de Delta-tabel wordt bijgewerkt, blijft de index gesynchroniseerd met de Delta-tabel.
In het volgende diagram ziet u het proces:
- Query bestaat uit insluitingen en kan metagegevensfilters bevatten.
- Zoek naar overeenkomsten om de meest relevante documenten te identificeren. Retourneer de meest relevante documenten en voeg ze toe aan de query.
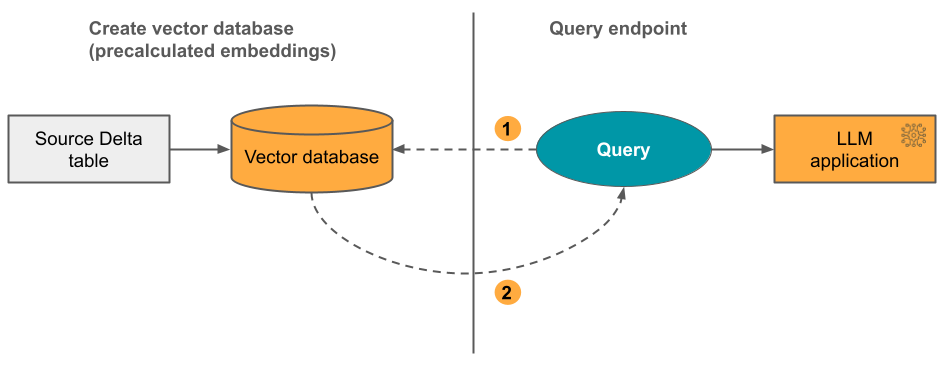
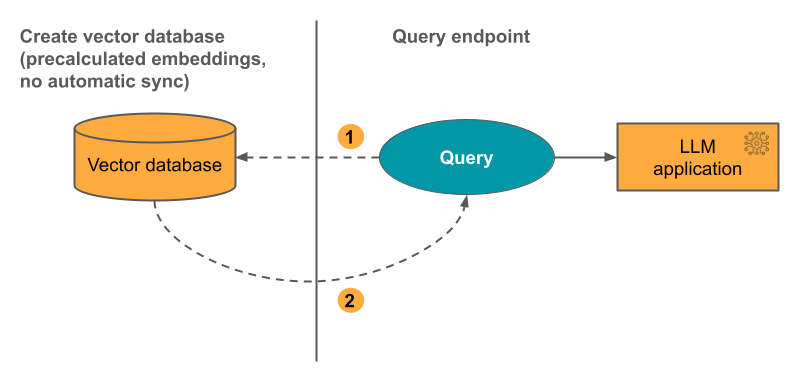
optie 3: Direct Vector Access Index U moet de index handmatig bijwerken met behulp van de REST API wanneer de insluitingstabel wordt gewijzigd.
In het volgende diagram ziet u het proces:
Hoe Mosaic AI Vector Search te configureren
Als u Mozaïek AI Vector Search wilt gebruiken, moet u het volgende maken:
Een vectorzoekeindpunt. Dit eindpunt dient voor de vectorzoekindex. U kunt het eindpunt opvragen en bijwerken met behulp van de REST API of de SDK. Zie Een vectorzoekeindpunt maken voor instructies.
Eindpunten worden automatisch opgeschaald om de grootte van de index of het aantal gelijktijdige aanvragen te ondersteunen. Eindpunten worden niet automatisch omlaag geschaald.
Een vectorzoekindex. De vectorzoekindex wordt gemaakt op basis van een Delta-tabel en is geoptimaliseerd voor real-time zoekopdrachten naar benaderde dichtstbijzijnde buren. Het doel van de zoekopdracht is om documenten te identificeren die vergelijkbaar zijn met de query. Vectorzoekindexen worden weergegeven en worden beheerd door Unity Catalog. Zie Een vectorzoekindex maken voor instructies.
Als u ervoor kiest om databricks de insluitingen te laten berekenen, kunt u bovendien een vooraf geconfigureerd Foundation Model-API-eindpunt gebruiken of een model voor eindpunten maken om het insluitmodel van uw keuze te leveren. Zie Foundation Model API's op basis van betaling per token of Serve-eindpunten voor basismodellen creëren voor instructies.
Als u een query wilt uitvoeren op het eindpunt van het model, gebruikt u de REST API of de Python SDK. Uw query kan filters definiëren op basis van elke kolom in de Delta-tabel. Zie Filters gebruiken voor query's, de API-verwijzing of de Python SDK-verwijzing voor meer informatie.
Vereisten
- Een werkruimte waarbij Unity Catalog is ingeschakeld.
- Serverloze rekenkracht ingeschakeld. Zie Verbinding maken met serverloze berekeningen voor instructies.
- Voor de brontabel moet de Wijzigingsgegevensfeed zijn ingeschakeld. Zie Delta Lake-wijzigingenfeed gebruiken in Azure Databricks voor instructies.
- Als u een vectorzoekindex wilt maken, moet u CREATE TABLE bevoegdheden hebben voor het catalogusschema waarin de index wordt gemaakt.
De machtiging voor het maken en beheren van vectorzoekeindpunten wordt geconfigureerd met behulp van toegangsbeheerlijsten. Zie ACL's voor vectorzoekeindpunten.
gegevensbescherming en -verificatie
Databricks implementeert de volgende beveiligingsmechanismen om uw gegevens te beveiligen:
- Elke klantaanvraag bij Mosaic AI Vector Search is logisch geïsoleerd, geverifieerd en geautoriseerd.
- Mozaïek AI Vector Search versleutelt alle gegevens in rust (AES-256) en tijdens transport (TLS 1.2+).
Mozaïek AI Vector Search ondersteunt twee verificatiemodi:
Token voor service-principal. Een beheerder kan een service-principal-token genereren en doorgeven aan de SDK of API. Zie service-principals gebruiken. Voor productiegebruiksscenario's raadt Databricks aan om een service-principal-token te gebruiken.
# Pass in a service principal vsc = VectorSearchClient(workspace_url="...", service_principal_client_id="...", service_principal_client_secret="..." )Persoonlijk toegangstoken. U kunt een persoonlijk toegangstoken gebruiken om te verifiëren met Mosaic AI Vector Search. Zie het verificatietoken voor persoonlijke toegang. Als u de SDK in een notebookomgeving gebruikt, genereert de SDK automatisch een PAT-token voor verificatie.
# Pass in the PAT token client = VectorSearchClient(workspace_url="...", personal_access_token="...")
Cmk (Door klant beheerde sleutels) worden ondersteund op eindpunten die zijn gemaakt op of na 8 mei 2024.
Gebruik en kosten controleren
Met de factureerbare gebruikssysteemtabel kunt u het gebruik en de kosten bewaken die zijn gekoppeld aan vectorzoekindexen en eindpunten. Hier volgt een voorbeeld van een query:
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL THEN 'ingest'
WHEN usage_type = "STORAGE_SPACE" THEN 'storage'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
CASE WHEN workload_type = 'serving' THEN SUM(usage_quantity)
WHEN workload_type = 'ingest' THEN SUM(usage_quantity)
ELSE null
END as dbus,
CASE WHEN workload_type = 'storage' THEN SUM(usage_quantity)
ELSE null
END as dsus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
Zie voor meer informatie over de inhoud van de gebruikstabel voor facturering Factureerbare gebruikssysteemtabelreferentie. Aanvullende query's bevinden zich in het volgende voorbeeldnotebook.
Notitieboek voor vectorzoeksysteem-query's naar tabellen
Limieten voor resource- en gegevensgrootte
De volgende tabel bevat een overzicht van resource- en gegevensgroottelimieten voor vectorzoekeindpunten en -indexen:
| Bron | Granulariteit | Grens |
|---|---|---|
| Eindpunten voor vectorzoekopdrachten | Per werkruimte | 100 |
| Insluitingen | Per eindpunt | 320 000 000 |
| Dimensie voor insluiten | Per index | 4096 |
| Indexen | Per eindpunt | 50 |
| Kolommen | Per index | 50 |
| Kolommen | Ondersteunde typen: Bytes, short, integer, long, float, double, boolean, string, timestamp, datum | |
| Metagegevensvelden | Per index | 50 |
| Naam van de index | Per index | 128 tekens |
De volgende limieten zijn van toepassing op het maken en bijwerken van vectorzoekindexen:
| Bron | Granulariteit | Grens |
|---|---|---|
| Rijgrootte voor Delta Sync-index | Per index | 100 KB |
| Grootte van bronkolommen opnemen in de Delta Sync-index | Per Index | 32764 bytes |
| Limiet voor bulk upsert-aanvraaggrootte voor Direct Vector-index | Per indexpunt | 10 MB |
| Limiet voor aanvraaggrootte bulksgewijs verwijderen voor Direct Vector-index | Per Index | 10 MB |
De volgende limieten zijn van toepassing op de query-API.
| Bron | Granulariteit | Grens |
|---|---|---|
| Lengte van querytekst | Per aanvraag | 32764 bytes |
| Maximum aantal geretourneerde resultaten | Per aanvraag | 10.000 |
Beperking
Machtigingen op rij- en kolomniveau worden niet ondersteund. U kunt echter uw eigen ACL's op toepassingsniveau implementeren met behulp van de filter-API.
Aanvullende bronnen
- Implementeer uw LLM-chatbot met het ophalen van Augmented Generation (RAG), Foundation Models en Vector Search.
- Een vectorzoekindex maken en er query's op uitvoeren.
- Voorbeeldnotebooks