RAG-keten voor deductie
In dit artikel wordt het proces beschreven dat optreedt wanneer de gebruiker een aanvraag indient bij de RAG-toepassing in een online-instelling. Zodra de gegevens zijn verwerkt door de gegevenspijplijn, is deze geschikt voor gebruik in de RAG-toepassing. De reeks of keten van stappen die tijdens deductietijd worden aangeroepen, wordt meestal de RAG-keten genoemd.
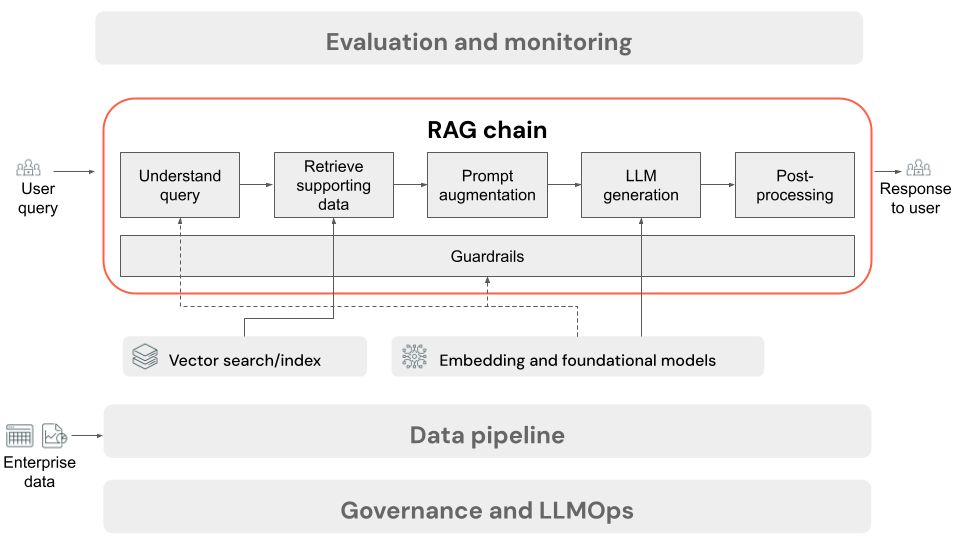
- (Optioneel) Voorverwerking van gebruikersquery's: in sommige gevallen wordt de query van de gebruiker vooraf verwerkt om deze geschikter te maken voor het uitvoeren van query's op de vectordatabase. Dit kan betrekking hebben op het opmaken van de query in een sjabloon, het gebruik van een ander model om de aanvraag te herschrijven of om trefwoorden te extraheren om het ophalen te helpen. De uitvoer van deze stap is een ophaalquery die wordt gebruikt in de volgende stap voor het ophalen.
- Ophalen: Voor het ophalen van ondersteunende informatie uit de vectordatabase wordt de ophaalquery omgezet in een insluiting met hetzelfde insluitingsmodel dat is gebruikt om de documentsegmenten in te sluiten tijdens het voorbereiden van de gegevens. Met deze insluitingen kunt u de semantische gelijkenis tussen de ophaalquery en de ongestructureerde tekstsegmenten vergelijken met behulp van metingen zoals cosinus-gelijkenis. Vervolgens worden segmenten opgehaald uit de vectordatabase en gerangschikt op basis van hoe vergelijkbaar ze zijn met de ingesloten aanvraag. De bovenste (meest vergelijkbare) resultaten worden geretourneerd.
- Promptvergroting: de prompt die naar de LLM wordt verzonden, wordt gevormd door de query van de gebruiker te uitbreiden met de opgehaalde context, in een sjabloon die het model instrueert hoe elk onderdeel moet worden gebruikt, vaak met aanvullende instructies voor het beheren van de antwoordindeling. Het proces voor het herhalen van de juiste promptsjabloon die moet worden gebruikt, wordt prompt-engineering genoemd.
- LLM Generation: De LLM neemt de augmented prompt, die de query van de gebruiker bevat en ondersteunende gegevens heeft opgehaald, als invoer. Vervolgens wordt een antwoord gegenereerd dat is gebaseerd op de aanvullende context.
- (Optioneel) Naverwerking: het antwoord van de LLM kan verder worden verwerkt om aanvullende bedrijfslogica toe te passen, bronvermeldingen toe te voegen of de gegenereerde tekst op een andere manier te verfijnen op basis van vooraf gedefinieerde regels of beperkingen.
Net als bij de RAG-toepassingsgegevenspijplijn zijn er veel gevolgkundige beslissingen die van invloed kunnen zijn op de kwaliteit van de RAG-keten. Als u bijvoorbeeld bepaalt hoeveel segmenten u wilt ophalen in stap 2 en hoe u deze kunt combineren met de query van de gebruiker in stap 3, kan dit van grote invloed zijn op het vermogen van het model om antwoorden van kwaliteit te generate.
In de hele keten kunnen verschillende kaders worden toegepast om te zorgen voor naleving van het ondernemingsbeleid. Dit kan betrekking hebben op het filteren van de juiste aanvragen, het controleren van gebruikersmachtigingen voordat u toegang verleent tot gegevensbronnen en het toepassen van con tentmodus rationtechnieken op de gegenereerde antwoorden.