Opplæring: Oppdag relasjoner i en semantisk modell ved hjelp av semantisk kobling
Denne opplæringen illustrerer hvordan du samhandler med Power BI fra en Jupyter-notatblokk og oppdager relasjoner mellom tabeller ved hjelp av SemPy-biblioteket.
I denne opplæringen lærer du hvordan du:
- Oppdag relasjoner i en semantisk modell (Power BI-datasett), ved hjelp av Python-biblioteket for semantisk kobling (SemPy).
- Bruk komponenter i SemPy som støtter integrering med Power BI, og hjelp til å automatisere analyse av datakvalitet. Disse komponentene omfatter:
- FabricDataFrame - en pandas-lignende struktur forbedret med ekstra semantisk informasjon.
- Funksjoner for å trekke semantiske modeller fra et Fabric-arbeidsområde inn i notatblokken.
- Funksjoner som automatiserer evalueringen av hypoteser om funksjonelle avhengigheter og som identifiserer brudd på relasjoner i semantiske modeller.
Forutsetninger
Få et Microsoft Fabric-abonnement. Eller registrer deg for en gratis Prøveversjon av Microsoft Fabric.
Logg på Microsoft Fabric.
Bruk opplevelsesbryteren nederst til venstre på hjemmesiden for å bytte til Fabric.

Velg arbeidsområder fra venstre navigasjonsrute for å finne og velge arbeidsområdet. Dette arbeidsområdet blir ditt gjeldende arbeidsområde.
Last ned Eksempel på kundelønnsomhet.pbix og Eksempel på kundelønnsomhet (auto).pbix semantiske modeller fra gitHub-repositorium for stoffeksempler og last dem opp til arbeidsområdet.
Følg med i notatblokken
Notatblokken powerbi_relationships_tutorial.ipynb følger med denne opplæringen.
Hvis du vil åpne den medfølgende notatblokken for denne opplæringen, følger du instruksjonene i Klargjøre systemet for opplæringer om datavitenskap importere notatblokken til arbeidsområdet.
Hvis du heller vil kopiere og lime inn koden fra denne siden, kan du opprette en ny notatblokk.
Pass på å feste et lakehouse til notatblokken før du begynner å kjøre kode.
Konfigurere notatblokken
I denne delen konfigurerer du et notatblokkmiljø med de nødvendige modulene og dataene.
Installer
SemPyfra PyPI ved hjelp av%pipinnebygd installasjonsfunksjonalitet i notatblokken:%pip install semantic-linkUtfør nødvendige importer av SemPy-moduler som du trenger senere:
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsImporter pandaer for å fremtvinge et konfigurasjonsalternativ som hjelper med utdataformatering:
import pandas as pd pd.set_option('display.max_colwidth', None)
Utforsk semantiske modeller
Denne opplæringen bruker en standard semantisk eksempelmodell Eksempel på kundelønnsomhet.pbix. Hvis du vil ha en beskrivelse av den semantiske modellen, kan du se eksempel på kundelønnsomhet for Power BI-.
Bruk SemPys
list_datasets-funksjon til å utforske semantiske modeller i det gjeldende arbeidsområdet:fabric.list_datasets()
For resten av denne notatblokken bruker du to versjoner av semantisk modell for eksempel på kundelønnsomhet:
- Eksempel på kundelønnsomhet: den semantiske modellen etter hvert som den kommer fra Power BI-eksempler med forhåndsdefinerte tabellrelasjoner
- eksempel på kundelønnsomhet (automatisk): de samme dataene, men relasjonene er begrenset til de som Power BI automatisk vil oppdage.
Trekke ut en semantisk eksempelmodell med den forhåndsdefinerte semantiske modellen
Last inn relasjoner som er forhåndsdefinerte og lagret i eksempel på kundelønnsomhet semantisk modell, ved hjelp av SemPys
list_relationships-funksjon. Denne funksjonen viser fra tabellobjektmodellen:dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsVisualiser
relationshipsDataFrame som en graf ved hjelp av SemPysplot_relationship_metadata-funksjon:plot_relationship_metadata(relationships)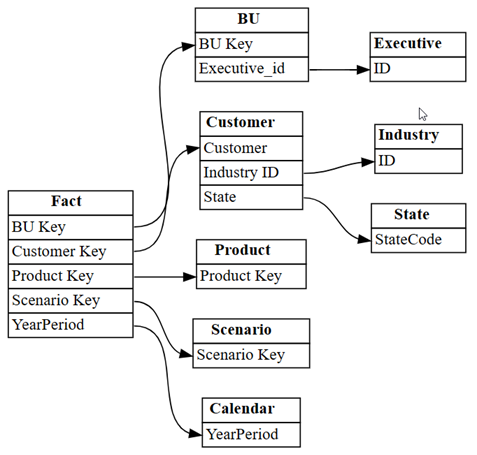

Denne grafen viser "ground truth" for relasjoner mellom tabeller i denne semantiske modellen, da den gjenspeiler hvordan de ble definert i Power BI av en fagekspert.
Komplementer relasjonsoppdagelse
Hvis du startet med relasjoner som Power BI automatisk oppdaget, ville du ha et mindre sett.
Visualiser relasjonene som Power BI automatisk oppdaget i den semantiske modellen:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)
Power BIs automatiske innstilling gikk glipp av mange relasjoner. Dessuten er to av de automatisk gjenkjenningsrelasjonene semantisk feil:
-
Executive[ID]->Industry[ID] -
BU[Executive_id]->Industry[ID]
-
Skriv ut relasjonene som en tabell:
autodetectedFeil relasjoner til
Industrytabellen vises i rader med indeks 3 og 4. Bruk denne informasjonen til å fjerne disse radene.Forkast de feilaktig identifiserte relasjonene.
autodetected.drop(index=[3,4], inplace=True) autodetectedNå har du riktige, men ufullstendige relasjoner.
Visualiser disse ufullstendige relasjonene ved hjelp av
plot_relationship_metadata:plot_relationship_metadata(autodetected)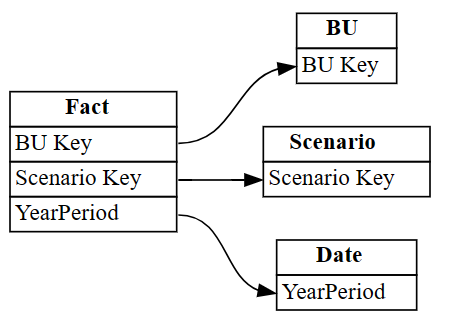
Last inn alle tabellene fra den semantiske modellen ved hjelp av SemPys
list_tables- ogread_table-funksjoner:tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Finn relasjoner mellom tabeller ved hjelp av
find_relationships, og se gjennom loggutdataene for å få innsikt i hvordan denne funksjonen fungerer:suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )Visualiser nylig oppdagede relasjoner:
plot_relationship_metadata(suggested_relationships_all)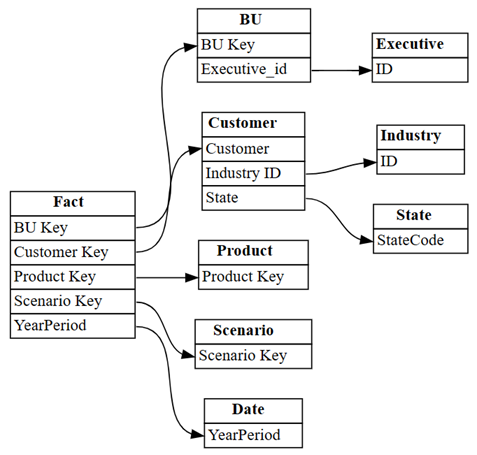
SemPy kunne oppdage alle relasjoner.
Bruk parameteren
excludetil å begrense søket til flere relasjoner som ikke ble identifisert tidligere:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



Validere relasjonene
Først laster du inn dataene fra eksempel på kundelønnsomhet semantisk modell:
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Se etter overlapping av primær- og sekundærnøkkelverdier ved hjelp av
list_relationship_violations-funksjonen. Angi utdataene forlist_relationships-funksjonen som inndata forlist_relationship_violations:list_relationship_violations(tables, fabric.list_relationships(dataset))Relasjonsbruddene gir noen interessante innsikter. Én av sju verdier i
Fact[Product Key]finnes for eksempel ikke iProduct[Product Key], og denne manglende nøkkelen er50.
Utforskende dataanalyse er en spennende prosess, og det samme er datarengjøring. Det er alltid noe dataene skjuler, avhengig av hvordan du ser på dem, hva du vil spørre om og så videre. Semantisk kobling gir deg nye verktøy som du kan bruke til å oppnå mer med dataene.
Relatert innhold
Sjekk ut andre opplæringer for semantisk kobling / SemPy:
- opplæring: Rengjøre data med funksjonelle avhengigheter
- opplæring: Analysere funksjonelle avhengigheter i en semantisk eksempelmodell
- opplæring: Trekke ut og beregne Power BI-mål fra en Jupyter-notatblokk
- opplæring: Oppdag relasjoner i Synthea-datasettet ved hjelp av semantisk kobling
- opplæring: Valider data ved hjelp av SemPy og store forventninger (GX)