Opplæring: Analysere funksjonelle avhengigheter i en semantisk modell
I denne opplæringen bygger du på tidligere arbeid utført av en Power BI-analytiker og lagret i form av semantiske modeller (Power BI-datasett). Ved å bruke SemPy (forhåndsvisning) i Synapse Data Science-opplevelsen i Microsoft Fabric analyserer du funksjonelle avhengigheter som finnes i kolonner i en DataFrame. Denne analysen bidrar til å oppdage problemer med ikke-trivial datakvalitet for å få mer nøyaktig innsikt.
I denne opplæringen lærer du hvordan du:
- Bruk domenekunnskap på å formulere hypoteser om funksjonelle avhengigheter i en semantisk modell.
- Bli kjent med komponenter i Python-biblioteket for semantiske koblinger (SemPy) som støtter integrering med Power BI og bidrar til å automatisere analyse av datakvalitet. Disse komponentene omfatter:
- FabricDataFrame - en pandas-lignende struktur forbedret med ekstra semantisk informasjon.
- Nyttige funksjoner for å trekke semantiske modeller fra et Fabric-arbeidsområde inn i notatblokken.
- Nyttige funksjoner som automatiserer evalueringen av hypoteser om funksjonelle avhengigheter og som identifiserer brudd på relasjoner i semantiske modeller.
Forutsetninger
Få et Microsoft Fabric-abonnement. Eller registrer deg for en gratis Prøveversjon av Microsoft Fabric.
Logg på Microsoft Fabric.
Bruk opplevelsesbryteren nederst til venstre på hjemmesiden for å bytte til Fabric.

Velg arbeidsområder fra venstre navigasjonsrute for å finne og velge arbeidsområdet. Dette arbeidsområdet blir ditt gjeldende arbeidsområde.
Last ned Eksempel på kundelønnsomhet.pbix semantisk modell fra gitHub-repositorium for stoffeksempler.
Velg Importer>rapport eller paginert rapport>Fra denne datamaskinen du laster opp eksempel på kundelønnsomhet.pbix til arbeidsområdet.
Følg med i notatblokken
Notatblokken powerbi_dependencies_tutorial.ipynb følger med denne opplæringen.
Hvis du vil åpne den medfølgende notatblokken for denne opplæringen, følger du instruksjonene i Klargjøre systemet for opplæringer om datavitenskap importere notatblokken til arbeidsområdet.
Hvis du heller vil kopiere og lime inn koden fra denne siden, kan du opprette en ny notatblokk.
Pass på å feste et lakehouse til notatblokken før du begynner å kjøre kode.
Konfigurere notatblokken
I denne delen konfigurerer du et notatblokkmiljø med de nødvendige modulene og dataene.
Installer
SemPyfra PyPI ved hjelp av%pipinnebygd installasjonsfunksjonalitet i notatblokken:%pip install semantic-linkUtfør nødvendig import av moduler som du trenger senere:
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
Laste inn og forhåndsbearbeide dataene
Denne opplæringen bruker en standard semantisk eksempelmodell Eksempel på kundelønnsomhet.pbix. Hvis du vil ha en beskrivelse av den semantiske modellen, kan du se eksempel på kundelønnsomhet for Power BI-.
Last inn Power BI-dataene i FabricDataFrames ved hjelp av SemPys
read_table-funksjon:dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()Last inn
Statetabellen i en FabricDataFrame:state = fabric.read_table(dataset, "State") state.head()Selv om utdataene for denne koden ser ut som en pandas DataFrame, har du faktisk initialisert en datastruktur kalt en
FabricDataFramesom støtter noen nyttige operasjoner på toppen av pandaer.Kontroller datatypen for
customer:type(customer)Utdataene bekrefter at
customerer av typensempy.fabric._dataframe._fabric_dataframe.FabricDataFrame.'Bli med i
customerogstateDataFrames:customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
Identifiser funksjonelle avhengigheter
En funksjonell avhengighet manifesterer seg som en én-til-mange-relasjon mellom verdiene i to (eller flere) kolonner i en DataFrame. Disse relasjonene kan brukes til automatisk å oppdage problemer med datakvalitet.
Kjør SemPys
find_dependencies-funksjon på den flettede DataFrame for å identifisere eventuelle eksisterende funksjonelle avhengigheter mellom verdier i kolonnene:dependencies = customer_state_df.find_dependencies() dependenciesVisualiser de identifiserte avhengighetene ved hjelp av SemPys
plot_dependency_metadata-funksjon:plot_dependency_metadata(dependencies)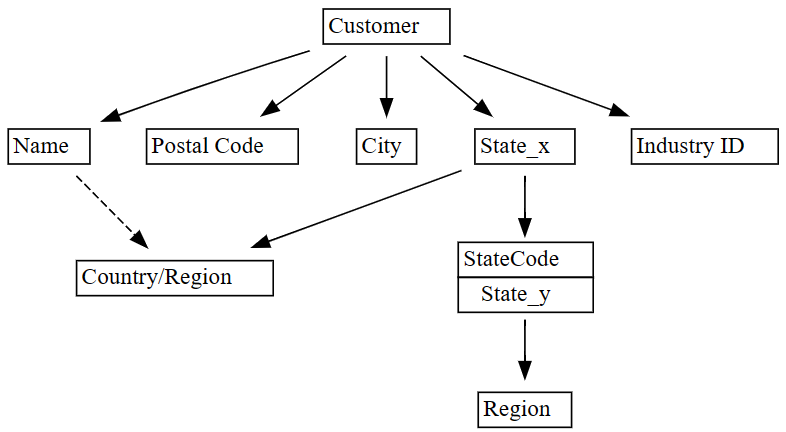
Som forventet viser grafen for funksjonelle avhengigheter at
Customer-kolonnen bestemmer noen kolonner somCity,Postal CodeogName.Overraskende nok viser ikke grafen en funksjonell avhengighet mellom
CityogPostal Code, sannsynligvis fordi det er mange brudd i relasjonene mellom kolonnene. Du kan bruke SemPysplot_dependency_violations-funksjon til å visualisere brudd på avhengigheter mellom bestemte kolonner.

Utforsk dataene for kvalitetsproblemer
Tegn en graf med SemPys
plot_dependency_violationsvisualiseringsfunksjon.customer_state_df.plot_dependency_violations('Postal Code', 'City')
Handlingen for avhengighetsbrudd viser verdier for
Postal Codepå venstre side, og verdier forCitypå høyre side. En kant kobler enPostal Codetil venstre med enCitypå høyre side hvis det er en rad som inneholder disse to verdiene. Kantene er kommentert med antallet slike rader. Det finnes for eksempel to rader med postnummer 20004, én med byen «North Tower» og den andre med byen «Washington».Videre viser plottet noen brudd og mange tomme verdier.
Bekreft antall tomme verdier for
Postal Code:customer_state_df['Postal Code'].isna().sum()50 rader har NA for postnummer.
Slipp rader med tomme verdier. Finn deretter avhengigheter ved hjelp av
find_dependencies-funksjonen. Legg merke til den ekstra parameterenverbose=1som gir et glimt inn i semPys interne arbeid:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)Den betingede entropien for
Postal CodeogCityer 0,049. Denne verdien angir at det finnes funksjonelle avhengighetsbrudd. Før du løser bruddene, må du heve terskelen for betinget entropy fra standardverdien for0.01til0.05, bare for å se avhengighetene. Lavere terskler resulterer i færre avhengigheter (eller høyere selektivitet).Øk terskelen for betinget entropy fra standardverdien for
0.01til0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))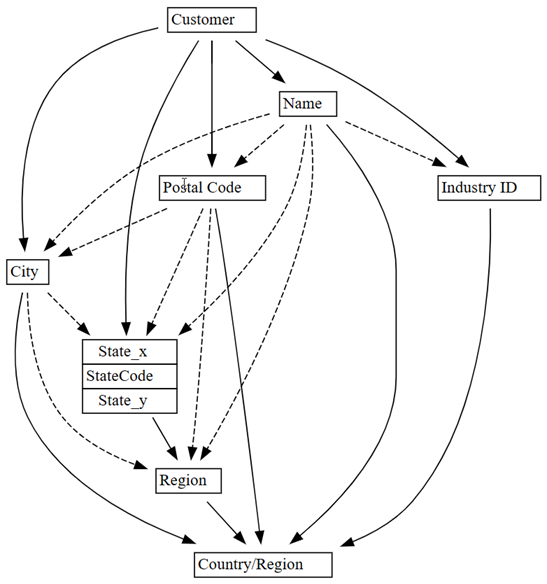
Hvis du bruker domenekunnskap om hvilken enhet som bestemmer verdier for andre enheter, virker denne avhengighetsgrafen nøyaktig.
Utforsk flere problemer med datakvalitet som ble oppdaget. En stiplet pil føyer for eksempel sammen
CityogRegion, som angir at avhengigheten bare er omtrentlig. Denne omtrentlige relasjonen kan antyde at det er en delvis funksjonell avhengighet.customer_state_df.list_dependency_violations('City', 'Region')Ta en nærmere titt på hvert av tilfellene der en ikke-mpty
Regionverdi forårsaker brudd:customer_state_df[customer_state_df.City=='Downers Grove']Resultatet viser Downers Grove byen forekommer i Illinois og Nebraska. Downer's Grove er imidlertid en by i Illinois, ikke Nebraska.
Ta en titt på byen Fremont:
customer_state_df[customer_state_df.City=='Fremont']Det er en by som heter Fremont i California. Men for Texas returnerer søkemotoren Premont, ikke Fremont.
Det er også mistenkelig å se brudd på avhengigheten mellom
NameogCountry/Region, som betegnet av den prikkede linjen i den opprinnelige grafen over avhengighetsbrudd (før rader med tomme verdier slippes).customer_state_df.list_dependency_violations('Name', 'Country/Region')Det ser ut til at én kunde, SDI Design finnes i to regioner – USA og Canada. Denne forekomsten kan ikke være et semantisk brudd, men kan bare være et uvanlig tilfelle. Likevel er det verdt å ta en nærmere titt:
Ta en nærmere titt på SDI Design:
customer_state_df[customer_state_df.Name=='SDI Design']Videre inspeksjon viser at det faktisk er to forskjellige kunder (fra forskjellige bransjer) med samme navn.

Utforskende dataanalyse er en spennende prosess, og det samme er datarengjøring. Det er alltid noe dataene skjuler, avhengig av hvordan du ser på dem, hva du vil spørre om og så videre. Semantisk kobling gir deg nye verktøy som du kan bruke til å oppnå mer med dataene.
Relatert innhold
Sjekk ut andre opplæringer for semantisk kobling / SemPy:
- opplæring: Rengjøre data med funksjonelle avhengigheter
- opplæring: Trekke ut og beregne Power BI-mål fra en Jupyter-notatblokk
- opplæring: Oppdag relasjoner i en semantisk modell ved hjelp av semantisk kobling
- opplæring: Oppdag relasjoner i Synthea-datasettet ved hjelp av semantisk kobling
- opplæring: Valider data ved hjelp av SemPy og store forventninger (GX)