Opplæring: Rengjøre data med funksjonelle avhengigheter
I denne opplæringen bruker du funksjonelle avhengigheter for datarengjøring. Det finnes en funksjonell avhengighet når én kolonne i en semantisk modell (et Power BI-datasett) er en funksjon i en annen kolonne. En postnummer kolonne kan for eksempel bestemme verdiene i en by kolonne. En funksjonell avhengighet manifesterer seg som en én-til-mange-relasjon mellom verdiene i to eller flere kolonner i en DataFrame. Denne opplæringen bruker datasettet Synthea til å vise hvordan funksjonelle relasjoner kan bidra til å oppdage problemer med datakvalitet.
I denne opplæringen lærer du hvordan du:
- Bruk domenekunnskap på å formulere hypoteser om funksjonelle avhengigheter i en semantisk modell.
- Bli kjent med komponenter i Python-biblioteket for semantiske koblinger (SemPy) som bidrar til å automatisere analyse av datakvalitet. Disse komponentene omfatter:
- FabricDataFrame - en pandas-lignende struktur forbedret med ekstra semantisk informasjon.
- Nyttige funksjoner som automatiserer evalueringen av hypoteser om funksjonelle avhengigheter og som identifiserer brudd på relasjoner i semantiske modeller.
Forutsetninger
Få et Microsoft Fabric-abonnement. Eller registrer deg for en gratis Prøveversjon av Microsoft Fabric.
Logg på Microsoft Fabric.
Bruk opplevelsesbryteren nederst til venstre på hjemmesiden for å bytte til Fabric.

- Velg arbeidsområder fra venstre navigasjonsrute for å finne og velge arbeidsområdet. Dette arbeidsområdet blir ditt gjeldende arbeidsområde.
Følg med i notatblokken
Notatblokken data_cleaning_functional_dependencies_tutorial.ipynb følger med denne opplæringen.
Hvis du vil åpne den medfølgende notatblokken for denne opplæringen, følger du instruksjonene i Klargjøre systemet for opplæringer om datavitenskap importere notatblokken til arbeidsområdet.
Hvis du heller vil kopiere og lime inn koden fra denne siden, kan du opprette en ny notatblokk.
Pass på å feste et lakehouse til notatblokken før du begynner å kjøre kode.
Konfigurere notatblokken
I denne delen konfigurerer du et notatblokkmiljø med de nødvendige modulene og dataene.
- For Spark 3.4 og nyere er Semantic-koblingen tilgjengelig i standard kjøretid når du bruker Fabric, og det er ikke nødvendig å installere den. Hvis du bruker Spark 3.3 eller nedenfor, eller hvis du vil oppdatere til den nyeste versjonen av Semantic Link, kan du kjøre kommandoen:
python %pip install -U semantic-link
Utfør nødvendig import av moduler som du trenger senere:
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_syntheaHente eksempeldataene. I denne opplæringen bruker du Synthea datasett med syntetiske medisinske journaler (liten versjon for enkelhetsbruk):
download_synthea(which='small')
Utforsk dataene
Initialiser en
FabricDataFramemed innholdet i providers.csv-filen:providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Se etter datakvalitetsproblemer med SemPys
find_dependencies-funksjon ved å tegne inn en graf over automatiske funksjonelle avhengigheter:deps = providers.find_dependencies() plot_dependency_metadata(deps)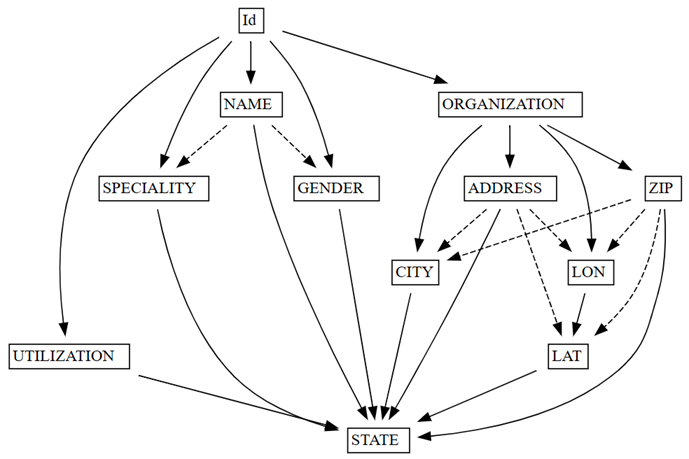
Grafen over funksjonelle avhengigheter viser at
IdbestemmerNAMEogORGANIZATION(angitt av de heldekkende pilene), som forventes, sidenIder unik:Bekreft at
Ider unik:providers.Id.is_uniqueKoden returnerer
Truefor å bekrefte atIder unik.

Analyser funksjonelle avhengigheter i dybden
Grafen for funksjonelle avhengigheter viser også at ORGANIZATION bestemmer ADDRESS og ZIP, som forventet. Du kan imidlertid forvente at ZIP også bestemmer CITY, men den stiplede pilen indikerer at avhengigheten bare er omtrentlig, og peker mot et problem med datakvalitet.
Det finnes andre særegenheter i grafen.
NAME bestemmer for eksempel ikke GENDER, Id, SPECIALITYeller ORGANIZATION. Hver av disse særegenheter kan være verdt å undersøke.
Ta en dypere titt på den omtrentlige relasjonen mellom
ZIPogCITYved hjelp av SemPyslist_dependency_violations-funksjon for å se en tabellliste over brudd:providers.list_dependency_violations('ZIP', 'CITY')Tegn en graf med SemPys
plot_dependency_violationsvisualiseringsfunksjon. Denne grafen er nyttig hvis antall brudd er lite:providers.plot_dependency_violations('ZIP', 'CITY')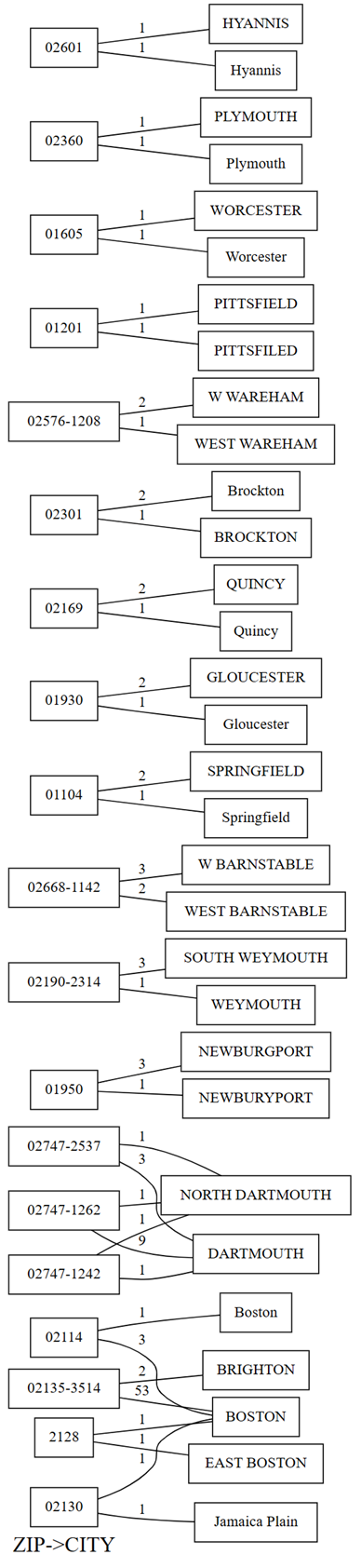
Handlingen for avhengighetsbrudd viser verdier for
ZIPpå venstre side, og verdier forCITYpå høyre side. En kant kobler sammen et postnummer på venstre side av plottet med en by på høyre side hvis det er en rad som inneholder disse to verdiene. Kantene er kommentert med antallet slike rader. Det er for eksempel to rader med postnummer 02747-1242, én rad med by "NORTHSPAMMOUTH" og den andre med by "SPAMMOUTH", som vist i forrige plott og følgende kode:Bekreft de forrige observasjonene du har gjort med tegn på avhengighetsbrudd ved å kjøre følgende kode:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()Handlingen viser også at blant radene som har
CITYsom "SERAMMOUTH", har ni rader enZIPpå 02747-1262; én rad har enZIPav 02747-1242; og én rad har enZIP02747-2537. Bekrefter disse observasjonene med følgende kode:providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()Det finnes andre postnumre som er knyttet til "DARTMOUTH", men disse postnumrene vises ikke i grafen over avhengighetsbrudd, da de ikke antyder problemer med datakvalitet. Postnummeret "02747-4302" er for eksempel unikt knyttet til "RPRS" og vises ikke i grafen over avhengighetsbrudd. Bekreft ved å kjøre følgende kode:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Oppsummer problemer med datakvalitet oppdaget med SemPy
Hvis du går tilbake til grafen over avhengighetsbrudd, kan du se at det finnes flere interessante problemer med datakvalitet i denne semantiske modellen:
- Noen bynavn er store bokstaver. Dette problemet er enkelt å løse ved hjelp av strengmetoder.
- Noen bynavn har kvalifikser (eller prefikser), for eksempel «Nord» og «Øst». Postnummeret «2128» tilordnes for eksempel «EAST BOSTON» én gang og til «BOSTON» én gang. Det oppstår et lignende problem mellom «NORTH- OG KJERFTMOUTH». Du kan prøve å slippe disse kvalifikatorene eller tilordne postnumrene til byen med den vanligste forekomsten.
- Det finnes skrivefeil i enkelte byer, for eksempel "PITTSFIELD" vs. "PITTSFILED" og "NEWBURGPORT vs. "NEWBURYPORT". For "NEWBURGPORT" kan denne skrivefeilen løses ved hjelp av den vanligste forekomsten. For «PITTSFIELD» er det mye vanskeligere å ha bare én forekomst hver for automatisk entydighet uten ekstern kunnskap eller bruk av en språkmodell.
- Noen ganger forkortes prefikser som «Vest» til én enkelt bokstav «W». Dette problemet kan potensielt løses med en enkel erstatning, hvis alle forekomster av «W» står for «Vest».
- Postnummeret "02130" kartlegger til "BOSTON" en gang og "Jamaica Plain" en gang. Dette problemet er ikke enkelt å løse, men hvis det fantes flere data, kan tilordning til den vanligste forekomsten være en potensiell løsning.
Rengjør dataene
Løs store/små bokstaver ved å endre all stor forbokstav til titteltilfelle:
providers['CITY'] = providers.CITY.str.title()Kjør registreringen av brudd på nytt for å se at noen av tvetydighetene er borte (antall brudd er mindre):
providers.list_dependency_violations('ZIP', 'CITY')På dette tidspunktet kan du begrense dataene mer manuelt, men én potensiell dataoppryddingsoppgave er å slippe rader som bryter funksjonelle begrensninger mellom kolonner i dataene, ved hjelp av SemPys
drop_dependency_violations-funksjon.For hver verdi av determinantvariabelen fungerer
drop_dependency_violationsved å velge den vanligste verdien av den avhengige variabelen og slippe alle rader med andre verdier. Du bør bare bruke denne operasjonen hvis du er sikker på at denne statistiske heuristikken vil føre til riktige resultater for dataene. Ellers bør du skrive din egen kode for å håndtere de oppdagede bruddene etter behov.Kjør
drop_dependency_violations-funksjonen på kolonneneZIPogCITY:providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')Vis eventuelle avhengighetsbrudd mellom
ZIPogCITY:providers_clean.list_dependency_violations('ZIP', 'CITY')Koden returnerer en tom liste for å angi at det ikke er flere brudd på den funksjonelle betingelsen BY -> ZIP-.
Relatert innhold
Sjekk ut andre opplæringer for semantisk kobling / SemPy:
- opplæring: Analysere funksjonelle avhengigheter i en semantisk eksempelmodell
- opplæring: Trekke ut og beregne Power BI-mål fra en Jupyter-notatblokk
- opplæring: Oppdag relasjoner i en semantisk modell ved hjelp av semantisk kobling
- opplæring: Oppdag relasjoner i Synthea-datasettet ved hjelp av semantisk kobling
- opplæring: Valider data ved hjelp av SemPy og store forventninger (GX)