Opplæring: Valider data ved hjelp av SemPy og store forventninger (GX)
I denne opplæringen lærer du hvordan du bruker SemPy sammen med Store forventninger (GX) til å utføre datavalidering på semantiske modeller i Power BI.
Denne opplæringen viser deg hvordan du:
- Valider begrensninger på et datasett i Fabric-arbeidsområdet med Fabric Data Source (bygget på semantisk kobling).
- Konfigurer en GX-datakontekst, dataressurser og forventninger.
- Vis valideringsresultater med et GX-kontrollpunkt.
- Bruk semantisk kobling til å analysere rådata.
Forutsetninger
Få et Microsoft Fabric-abonnement. Eller registrer deg for en gratis Prøveversjon av Microsoft Fabric.
Logg på Microsoft Fabric.
Bruk opplevelsesbryteren nederst til venstre på hjemmesiden for å bytte til Fabric.

- Velg arbeidsområder fra venstre navigasjonsrute for å finne og velge arbeidsområdet. Dette arbeidsområdet blir ditt gjeldende arbeidsområde.
- Last ned PBIX.pbix- eksempelfilen for detaljhandelanalyse.
- Velg Importer>rapport eller paginert rapport>Fra denne datamaskinen du laster opp PBIX.pbix- eksempelfilen for detaljhandelanalyse til arbeidsområdet.
Følg med i notatblokken
great_expectations_tutorial.ipynb er notatblokken som følger med denne opplæringen.
Hvis du vil åpne den medfølgende notatblokken for denne opplæringen, følger du instruksjonene i Klargjøre systemet for opplæringer om datavitenskap importere notatblokken til arbeidsområdet.
Hvis du heller vil kopiere og lime inn koden fra denne siden, kan du opprette en ny notatblokk.
Pass på å feste et lakehouse til notatblokken før du begynner å kjøre kode.
Konfigurere notatblokken
I denne delen konfigurerer du et notatblokkmiljø med de nødvendige modulene og dataene.
- Installer
SemPyog de relevanteGreat Expectationsbibliotekene fra PyPI ved hjelp av%pipinnebygd installasjonsfunksjonalitet i notatblokken.
# install libraries
%pip install semantic-link 'great-expectations<1.0' great_expectations_experimental great_expectations_zipcode_expectations
# load %%dax cell magic
%load_ext sempy
- Utfør nødvendig import av moduler som du trenger senere:
import great_expectations as gx
from great_expectations.expectations.expectation import ExpectationConfiguration
from great_expectations_zipcode_expectations.expectations import expect_column_values_to_be_valid_zip5
Konfigurere GX-datakontekst og datakilde
For å komme i gang med store forventninger må du først konfigurere en GX-datakontekst. Konteksten fungerer som et inngangspunkt for GX-operasjoner og inneholder alle relevante konfigurasjoner.
context = gx.get_context()
Du kan nå legge til Fabric-datasettet i denne konteksten som en datakilde for å begynne å samhandle med dataene. Denne opplæringen bruker en semantisk standard PBIX-fil for eksempel på detaljhandelanalyse.
ds = context.sources.add_fabric_powerbi("Retail Analysis Data Source", dataset="Retail Analysis Sample PBIX")
Angi dataressurser
Definer dataressurser for å angi delsettet med data du vil arbeide med. Aktivumet kan være så enkelt som fullstendige tabeller, eller være så komplisert som en egendefinert DAX-spørring (Data Analysis Expressions).
Her legger du til flere aktiva:
- Power BI-tabell
- Power BI-mål
- Egendefinert DAX-spørring
- spørring for dynamisk behandlingsvisning (DMV)
Power BI-tabell
Legg til en Power BI-tabell som et dataaktiva.
ds.add_powerbi_table_asset("Store Asset", table="Store")
Power BI-mål
Hvis datasettet inneholder forhåndskonfigurerte mål, legger du til målene som aktiva etter en lignende API i SemPys evaluate_measure.
ds.add_powerbi_measure_asset(
"Total Units Asset",
measure="TotalUnits",
groupby_columns=["Time[FiscalYear]", "Time[FiscalMonth]"]
)
DAX
Hvis du vil definere dine egne mål eller ha mer kontroll over bestemte rader, kan du legge til et DAX-aktivum med en egendefinert DAX-spørring. Her definerer vi et Total Units Ratio mål ved å dele to eksisterende mål.
ds.add_powerbi_dax_asset(
"Total Units YoY Asset",
dax_string=
"""
EVALUATE SUMMARIZECOLUMNS(
'Time'[FiscalYear],
'Time'[FiscalMonth],
"Total Units Ratio", DIVIDE([Total Units This Year], [Total Units Last Year])
)
"""
)
DMV-spørring
I noen tilfeller kan det være nyttig å bruke DMV-beregninger (Dynamic Management View) som en del av datavalideringsprosessen. Du kan for eksempel holde oversikt over antall brudd på referanseintegritet i datasettet. Hvis du vil ha mer informasjon, kan du se Fjern data = raskere rapporter.
ds.add_powerbi_dax_asset(
"Referential Integrity Violation",
dax_string=
"""
SELECT
[Database_name],
[Dimension_Name],
[RIVIOLATION_COUNT]
FROM $SYSTEM.DISCOVER_STORAGE_TABLES
"""
)
Forventninger
Hvis du vil legge til bestemte begrensninger for ressursene, må du først konfigurere Expectation Suites. Når du har lagt til individuelle Forventninger i hver serie, kan du deretter oppdatere datakonteksten som er konfigurert i begynnelsen med den nye serien. Hvis du vil ha en fullstendig liste over tilgjengelige forventninger, kan du se GX Expectation Gallery.
Start med å legge til en «Retail Store Suite» med to forventninger:
- et gyldig postnummer
- en tabell med radantall mellom 80 og 200
suite_store = context.add_expectation_suite("Retail Store Suite")
suite_store.add_expectation(ExpectationConfiguration("expect_column_values_to_be_valid_zip5", { "column": "PostalCode" }))
suite_store.add_expectation(ExpectationConfiguration("expect_table_row_count_to_be_between", { "min_value": 80, "max_value": 200 }))
context.add_or_update_expectation_suite(expectation_suite=suite_store)
TotalUnits mål
Legg til en "Retail Measure Suite" med én forventning:
- Kolonneverdier må være større enn 50 000
suite_measure = context.add_expectation_suite("Retail Measure Suite")
suite_measure.add_expectation(ExpectationConfiguration(
"expect_column_values_to_be_between",
{
"column": "TotalUnits",
"min_value": 50000
}
))
context.add_or_update_expectation_suite(expectation_suite=suite_measure)
Total Units Ratio DAX
Legg til en "Retail DAX Suite" med én forventning:
- Kolonneverdier for totalt antall enheter-forholdet skal være mellom 0,8 og 1,5
suite_dax = context.add_expectation_suite("Retail DAX Suite")
suite_dax.add_expectation(ExpectationConfiguration(
"expect_column_values_to_be_between",
{
"column": "[Total Units Ratio]",
"min_value": 0.8,
"max_value": 1.5
}
))
context.add_or_update_expectation_suite(expectation_suite=suite_dax)
Brudd på referanseintegritet (DMV)
Legg til en "Retail DMV Suite" med én forventning:
- RIVIOLATION_COUNT skal være 0
suite_dmv = context.add_expectation_suite("Retail DMV Suite")
# There should be no RI violations
suite_dmv.add_expectation(ExpectationConfiguration(
"expect_column_values_to_be_in_set",
{
"column": "RIVIOLATION_COUNT",
"value_set": [0]
}
))
context.add_or_update_expectation_suite(expectation_suite=suite_dmv)
Validering
Hvis du faktisk vil kjøre de angitte forventningene mot dataene, må du først opprette en kontrollpunkt og legge den til i konteksten. Hvis du vil ha mer informasjon om kontrollpunktkonfigurasjon, kan du se arbeidsflyt for datavalidering.
checkpoint_config = {
"name": f"Retail Analysis Checkpoint",
"validations": [
{
"expectation_suite_name": "Retail Store Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Store Asset",
},
},
{
"expectation_suite_name": "Retail Measure Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Total Units Asset",
},
},
{
"expectation_suite_name": "Retail DAX Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Total Units YoY Asset",
},
},
{
"expectation_suite_name": "Retail DMV Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Referential Integrity Violation",
},
},
],
}
checkpoint = context.add_checkpoint(
**checkpoint_config
)
Kjør kontrollpunktet og trekk ut resultatene som en pandas DataFrame for enkel formatering.
result = checkpoint.run()
Behandle og skrive ut resultatene.
import pandas as pd
data = []
for run_result in result.run_results:
for validation_result in result.run_results[run_result]["validation_result"]["results"]:
row = {
"Batch ID": run_result.batch_identifier,
"type": validation_result.expectation_config.expectation_type,
"success": validation_result.success
}
row.update(dict(validation_result.result))
data.append(row)
result_df = pd.DataFrame.from_records(data)
result_df[["Batch ID", "type", "success", "element_count", "unexpected_count", "partial_unexpected_list"]]

Fra disse resultatene kan du se at alle forventningene dine passerte valideringen, bortsett fra «Totalt antall enheter YoY-aktiva» som du definerte gjennom en egendefinert DAX-spørring.
Diagnostikk
Ved hjelp av semantisk kobling kan du hente kildedataene for å forstå hvilke eksakte år som er utenfor området. Semantisk kobling gir en innebygd magi for kjøring av DAX-spørringer. Bruk semantisk kobling til å kjøre den samme spørringen du sendte til GX-dataaktivaet, og visualiser de resulterende verdiene.
%%dax "Retail Analysis Sample PBIX"
EVALUATE SUMMARIZECOLUMNS(
'Time'[FiscalYear],
'Time'[FiscalMonth],
"Total Units Ratio", DIVIDE([Total Units This Year], [Total Units Last Year])
)
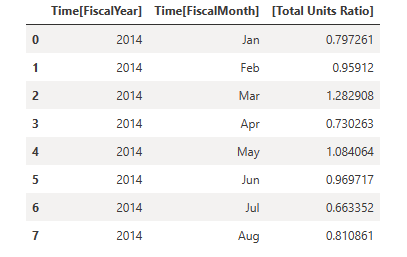
Lagre disse resultatene i en DataFrame.
df = _
Tegn inn resultatene.
import matplotlib.pyplot as plt
df["Total Units % Change YoY"] = (df["[Total Units Ratio]"] - 1)
df.set_index(["Time[FiscalYear]", "Time[FiscalMonth]"]).plot.bar(y="Total Units % Change YoY")
plt.axhline(0)
plt.axhline(-0.2, color="red", linestyle="dotted")
plt.axhline( 0.5, color="red", linestyle="dotted")
None
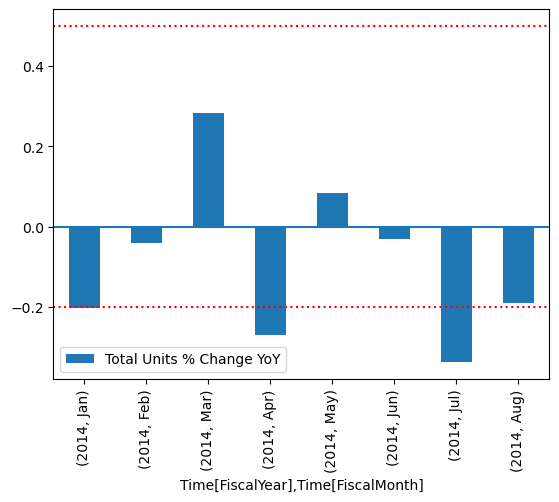
Fra plottet kan du se at april og juli var litt utenfor rekkevidde og kan deretter ta ytterligere skritt for å undersøke.
LagreR GX-konfigurasjon
Etter hvert som dataene i datasettet endres over tid, kan det hende du vil kjøre GX-valideringene du nettopp utførte på nytt. For øyeblikket lever datakonteksten (som inneholder de tilkoblede dataressursene, forventningsseriene og kontrollpunkt) flyktig, men den kan konverteres til en filkontekst for fremtidig bruk. Alternativt kan du starte en filkontekst (se starte en datakontekst).
context = context.convert_to_file_context()
Nå som du lagret konteksten, kopierer du gx katalogen til lakehouse.
Viktig
Denne cellen forutsetter at du lagt til et lakehouse- i notatblokken. Hvis det ikke er noen lakehouse festet, vil du ikke se en feil, men du vil heller ikke senere kunne få konteksten. Hvis du legger til et lakehouse nå, starter kjernen på nytt, så du må kjøre hele notatblokken på nytt for å komme tilbake til dette punktet.
# copy GX directory to attached lakehouse
!cp -r gx/ /lakehouse/default/Files/gx
Nå kan fremtidige kontekster opprettes med context = gx.get_context(project_root_dir="<your path here>") for å bruke alle konfigurasjonene fra denne opplæringen.
Legg for eksempel ved samme lakehouse i en ny notatblokk, og bruk context = gx.get_context(project_root_dir="/lakehouse/default/Files/gx") til å hente konteksten.
Relatert innhold
Sjekk ut andre opplæringer for semantisk kobling / SemPy:
- opplæring: Rengjøre data med funksjonelle avhengigheter
- opplæring: Analysere funksjonelle avhengigheter i en semantisk eksempelmodell
- opplæring: Trekke ut og beregne Power BI-mål fra en Jupyter-notatblokk
- opplæring: Oppdag relasjoner i en semantisk modell ved hjelp av semantisk kobling
- opplæring: Oppdag relasjoner i Synthea-datasettet ved hjelp av semantisk kobling