Azure Synapse Analytics에서 Fabric으로 Hive Metastore 메타데이터 마이그레이션
HMS(Hive Metastore) 마이그레이션의 초기 단계에는 전송하려는 데이터베이스, 테이블 및 파티션을 결정하는 작업이 포함됩니다. 모든 항목을 마이그레이션할 필요는 없습니다. 특정 데이터베이스를 선택할 수 있습니다. 마이그레이션할 데이터베이스를 식별할 때 관리되는 Spark 테이블 또는 외부 Spark 테이블이 있는지 확인해야 합니다.
HMS 고려 사항은 Azure Synapse Spark와 Fabric 간의 차이점을 참조 하세요.
참고 항목
또는 ADLS Gen2에 델타 테이블이 포함된 경우 ADLS Gen2에서 델타 테이블에 대한 OneLake 바로 가기를 생성할 수 있니다.
필수 조건
- 아직 없는 경우 테넌트에 Fabric 작업 영역을 만듭니다.
- 아직 없는 경우 작업 영역에 Fabric Lakehouse를 만듭니다.
옵션 1: Lakehosue 메타스토어로 HMS 내보내기 및 가져오기
마이그레이션을 위해 다음 주요 단계를 수행합니다.
- 1단계: 원본 HMS에서 메타데이터 내보내기
- 2단계: Fabric Lakehouse로 메타데이터 가져오기
- 마이그레이션 후 단계: 콘텐츠 유효성 검사
참고 항목
스크립트는 Spark 카탈로그 개체만 Fabric Lakehouse에 복사합니다. 데이터가 이미 복사(예: Warehouse 위치에서 ADLS Gen2로)되거나 관리 및 외부 테이블(예: 바로 가기를 통해 기본 설정)에서 Fabric Lakehouse로 사용할 수 있다고 가정합니다.
1단계: 원본 HMS에서 메타데이터 내보내기
1단계의 초점은 원본 HMS에서 Fabric Lakehouse의 Files 섹션으로 메타데이터를 내보내는 것입니다. 프로세스는 다음과 같습니다.
1.1) HMS 메타데이터 내보내기 Notebook 가가져오기를 Azure Synapse 작업 영역으로 합니다. 이 Notebook은 데이터베이스, 테이블 및 파티션의 HMS 메타데이터를 쿼리하고 OneLake의 중간 디렉터리로 내보냅니다(함수는 아직 포함되지 않음). Spark 내부 카탈로그 API는 이 스크립트에서 카탈로그 개체를 읽는 데 사용됩니다.
1.2) 매개 변수 구성을 첫 번째 명령에서 하여 메타데이터 정보를 중간 스토리지(OneLake)로 내보냅니다. 다음 코드 조각은 원본 및 대상 매개 변수를 구성하는 데 사용됩니다. 고유의 값으로 바꾸어야 합니다.
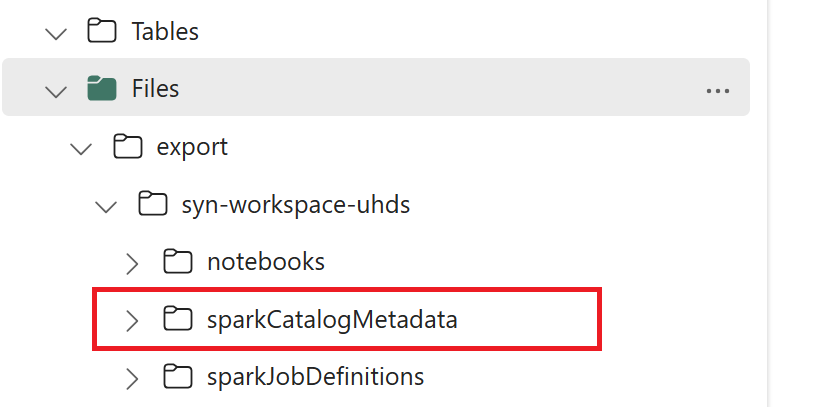
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) 모든 Notebook 명령을 실행하여 카탈로그 개체를 OneLake로 내보냅니다. 셀이 완료되면 중간 출력 디렉터리 아래에 이 폴더 구조가 만들어집니다.
2단계: Fabric Lakehouse로 메타데이터 가져오기
2단계는 실제 메타데이터를 중간 스토리지에서 Fabric Lakehouse로 가져오는 경우입니다. 이 단계의 출력은 모든 HMS 메타데이터(데이터베이스, 테이블 및 파티션)를 마이그레이션하는 것입니다. 프로세스는 다음과 같습니다.
2.1) "파일" 섹션 내에 바로 가기를 생성하기를 Lakehouse에 대해서 합니다. 이 바로 가기는 원본 Spark Warehouse 디렉터리를 가리킬 필요가 있으며 나중에 Spark 관리 테이블을 대체하는 데 사용됩니다. Spark Warehouse 디렉터리를 가리키는 바로 가기 예제를 참조하세요.
- Azure Synapse Spark Warehouse 디렉터리에 대한 바로 가기 경로:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Azure Databricks Warehouse 디렉터리의 바로 가기 경로:
dbfs:/mnt/<warehouse_dir> - HDInsight Spark Warehouse 디렉터리의 바로 가기 경로:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Azure Synapse Spark Warehouse 디렉터리에 대한 바로 가기 경로:
2.2) HMS 메타데이터 가져오기 노트북 가져오오기를 Fabric 작업 영역으로 합니다. 중간 스토리지에서 데이터베이스, 테이블 및 파티션 개체를 가져오려면 이 Notebook을 가져옵니다. Spark 내부 카탈로그 API는 이 스크립트에서 Fabric에서 카탈로그 개체를 만드는 데 사용됩니다.
2.3) 첫 번째 명령에서 매개 변수 를 구성합니다. Apache Spark에서 관리되는 테이블을 만들 때 해당 테이블의 데이터는 일반적으로 Spark의 Warehouse 디렉터리 내에서 Spark 자체에서 관리하는 위치에 저장됩니다. 정확한 위치는 Spark에 의해 결정됩니다. 이는 위치를 지정하고 기본 데이터를 관리하는 외부 테이블과 대조됩니다. 실제 데이터를 이동하지 않고 관리되는 테이블의 메타데이터를 마이그레이션하는 경우 메타데이터에는 이전 Spark Warehouse 디렉터리를 가리키는 원래 위치 정보가 계속 포함됩니다. 따라서 관리되는 테이블의 경우 2.1단계에서 만든 바로 가기를 사용하여
WarehouseMappings를 사용하여 교체를 수행합니다. 모든 원본 관리 테이블은 이 스크립트를 사용하여 외부 테이블로 변환됩니다.LakehouseId는 바로 가기를 포함하는 2.1단계에서 만든 Lakehouse를 나타냅니다.// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) 모든 Notebook 명령 실행을 하여 중간 경로에서 카탈로그 개체를 가져옵니다.
참고 항목
여러 데이터베이스를 가져올 때 (i) 데이터베이스당 하나의 Lakehouse를 만들거나(여기서 사용되는 접근 방식) (ii) 모든 테이블을 다른 데이터베이스에서 단일 Lakehouse로 이동할 수 있습니다. 후자의 경우 마이그레이션된 모든 테이블이 <lakehouse>.<db_name>_<table_name>이 될 수 있으며, 이에 따라 가져오기 Notebook을 조정해야 합니다.
3단계: 콘텐츠 유효성 검사
3단계는 메타데이터가 성공적으로 마이그레이션되었는지 확인하는 위치입니다. 다른 예제를 참조하세요.
다음을 실행하여 가져온 데이터베이스를 볼 수 있습니다.
%%sql
SHOW DATABASES
다음을 실행하여 Lakehouse(데이터베이스)의 모든 테이블을 확인할 수 있습니다.
%%sql
SHOW TABLES IN <lakehouse_name>
다음을 실행하여 특정 테이블의 세부 정보를 볼 수 있습니다.
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
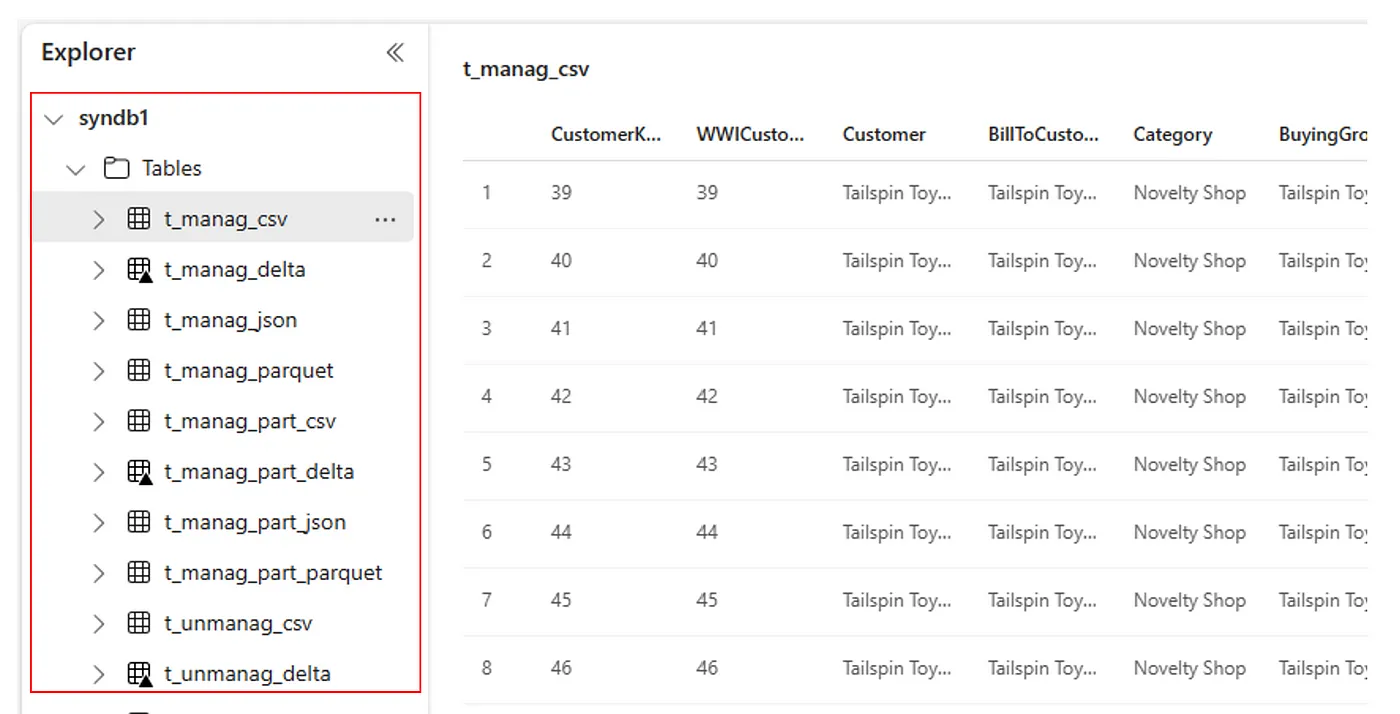
또는 가져온 모든 테이블이 각 Lakehouse에 대한 Lakehouse 탐색기 UI 테이블 섹션 내에 표시됩니다.
기타 고려 사항
- 확장성: 여기서 솔루션은 내부 Spark 카탈로그 API를 사용하여 가져오기/내보내기를 수행하지만 카탈로그 개체를 가져오기 위해 HMS에 직접 연결되지 않으므로 카탈로그가 큰 경우 솔루션의 크기를 잘 조정할 수 없습니다. HMS DB를 사용하여 내보내기 논리를 변경해야 합니다.
- 데이터 정확도: 격리 보장은 없습니다. 즉, 마이그레이션 Notebook이 실행되는 동안 Spark 컴퓨팅 엔진이 metastore를 동시에 수정하는 경우 Fabric Lakehouse에서 일관되지 않은 데이터를 도입할 수 있습니다.
관련 콘텐츠
- Fabric과 Azure Synapse Spark 비교
- Spark 풀, 구성, 라이브러리리, Notebook 및 Spark 작업 정의에 대한 마이그레이션 옵션에 대해서도 자세히 알아봅니다.