Azure Synapse에서 Fabric으로 Spark 작업 정의 마이그레이션
Azure Synapse에서 Fabric으로 Spark SJD(작업 정의)를 이동하려면 두 가지 옵션이 있습니다.
- 옵션 1: Fabric에서 Spark 작업 정의를 수동으로 만듭니다.
- 옵션 2: 스크립트를 사용하여 Azure Synapse에서 Spark 작업 정의를 내보내고 API를 사용하여 Fabric에서 가져올 수 있습니다.
Spark 작업 정의 고려 사항은 Azure Synapse Spark와 Fabric 간의 차이점을 참조 하세요.
필수 조건
아직 없는 경우 테넌트에 Fabric 작업 영역을 만듭니다.
옵션 1: Spark 작업 정의를 수동으로 만듭니다.
Azure Synapse에서 Spark 작업 정의를 내보내려면 다음을 수행합니다.
- Synapse Studio 열기: Azure에 로그인합니다. Azure Synapse 작업 영역으로 이동하여 Synapse Studio를 엽니다.
- Python/Scala/R Spark 작업을 찾기: 마이그레이션하려는 Python/Scala/R Spark 작업 정의를 찾아서 식별합니다.
-
작업 정의 구성 내보내기:
- Synapse Studio에서 Spark 작업 정의를 엽니다.
- 스크립트 파일 위치, 종속성, 매개 변수 및 기타 관련 세부 정보를 포함하여 구성 설정을 내보내거나 기록해 둡니다.
Fabric에서 내보낸 SJD 정보를 기반으로 새 SJD(Spark 작업 정의)를 만들려면 다음을 수행합니다.
- Fabric 작업 영역에 액세스: Fabric에 로그인하고 작업 영역에 액세스합니다.
-
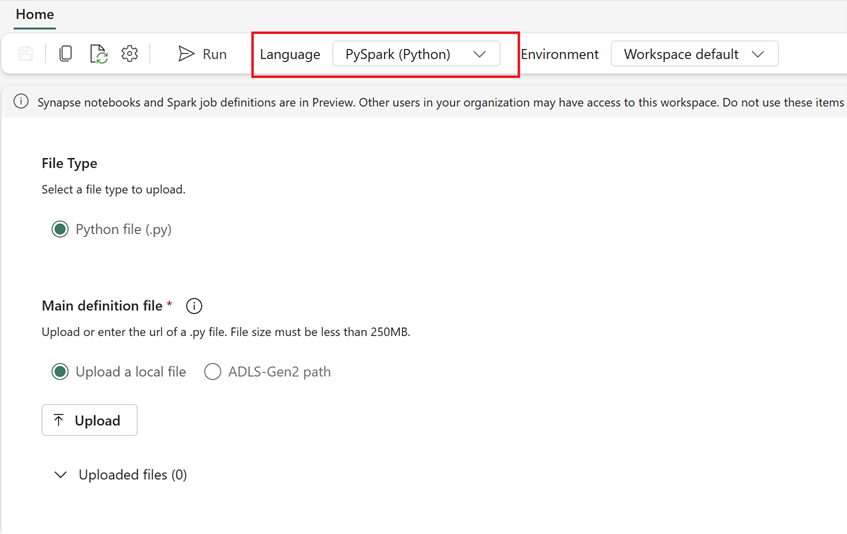
Fabric에서 새 Spark 작업 정의 만들기.
- Fabric에서 데이터 엔지니어 홈페이지로 이동합니다.
- Spark 작업 정의 선택하기.
- 스크립트 위치, 종속성, 매개 변수 및 클러스터 설정을 포함하여 Synapse에서 내보낸 정보를 사용하여 작업을 구성합니다.
- 적응 및 테스트: Fabric 환경에 맞게 스크립트 또는 구성에 필요한 모든 적응을 수행합니다. Fabric에서 작업을 테스트하여 올바르게 실행되는지 확인합니다.
Spark 작업 정의가 만들어지면 종속성 유효성을 검사합니다.
- 동일한 Spark 버전을 사용하는지 확인합니다.
- 기본 정의 파일이 있는지 확인합니다.
- 참조된 파일, 종속성 및 리소스가 있는지 확인합니다.
- 연결된 서비스, 데이터 원본 연결 및 탑재 지점.
Fabric에서 Apache Spark 작업 정의를 생성하는 방법에 대해 자세히 알아보세요.
옵션 2: Fabric API 사용
마이그레이션을 위해 다음 주요 단계를 수행합니다.
- 필수 구성 요소.
- 1단계: Azure Synapse에서 OneLake(.json)로 Spark 작업 정의를 내보냅니다.
- 2단계: Fabric API를 사용하여 Spark 작업 정의를 Fabric으로 자동으로 가져옵니다.
필수 조건
필수 구성 요소에는 Fabric으로 Spark 작업 정의 마이그레이션을 시작하기 전에 고려해야 하는 작업이 포함됩니다.
- Fabric 작업 영역입니다.
- 아직 없는 경우 작업 영역에 Fabric Lakehouse를 만듭니다.
1단계: Azure Synapse 작업 영역에서 Spark 작업 정의 내보내기
1단계의 초점은 Spark 작업 정의를 Azure Synapse 작업 영역에서 json 형식의 OneLake로 내보내는 것입니다. 프로세스는 다음과 같습니다.
- 1.1) SJD 마이그레이션 Notebook을 Fabric 작업 영역으로 가져옵니다. 이 Notebook 은 지정된 Azure Synapse 작업 영역에서 OneLake의 중간 디렉터리로 모든 Spark 작업 정의를 내보냅니다. Synapse API는 SJD를 내보내는 데 사용됩니다.
- 1.2) 매개 변수 구성을 첫 번째 명령에서 하여 Spark 작업 정의를 중간 스토리지(OneLake)로 내보냅니다. json 메타데이터 파일만 내보냅니다. 다음 코드 조각은 원본 및 대상 매개 변수를 구성하는 데 사용됩니다. 고유의 값으로 바꾸어야 합니다.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
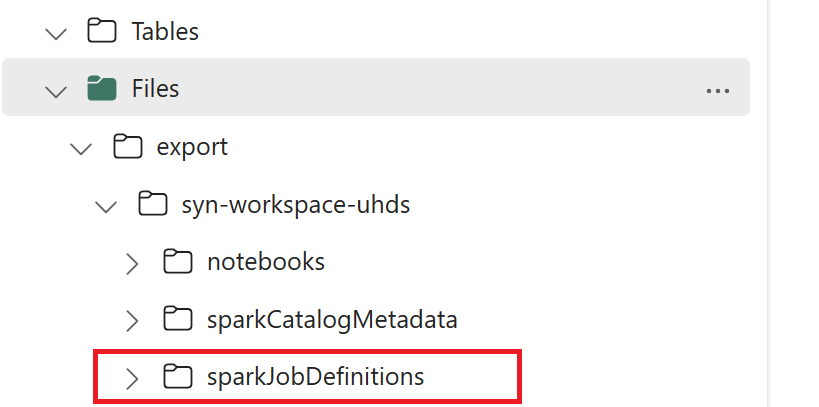
- 1.3) 처음 두 셀이 있는 내보내기/가져오기 Notebook에서 실행하여 Spark 작업 정의 메타데이터를 OneLake로 내보냅니다. 셀이 완료되면 중간 출력 디렉터리 아래에 이 폴더 구조가 만들어집니다.
2단계: Spark 작업 정의를 Fabric으로 가져오기
2단계는 Spark 작업 정의를 중간 스토리지에서 Fabric 작업 영역으로 가져오는 경우입니다. 프로세스는 다음과 같습니다.
- 2.1) 구성의 유효성이 있는 1.2에서 검사하여 Spark 작업 정의를 가져오도록 올바른 작업 영역과 접두사를 표시합니다.
- 2.2) 세 번째 셀이 있는 내보내기/가져오기 Notebook을 실행하여 중간 위치에서 모든 Spark 작업 정의를 가져옵니다.
참고 항목
내보내기 옵션은 json 메타데이터 파일을 출력합니다. Fabric에서 Spark 작업 정의 실행 파일, 참조 파일 및 인수에 액세스할 수 있는지 확인합니다.