Lakehouse 자습서: Lakehouse 만들기, 샘플 데이터 수집 및 보고서 작성
이 자습서에서는 Lakehouse를 빌드하고, 샘플 데이터를 Delta 테이블에 수집하고, 필요한 경우 변환을 적용한 다음, 보고서를 만듭니다. 이 자습서에서는 다음 작업을 수행하는 방법을 알아봅니다.
- Microsoft Fabric에서 레이크하우스 만들기
- 샘플 고객 데이터 다운로드 및 수집
- 의미 체계 모델에 테이블 추가
- 보고서 작성
Microsoft Fabric이 없는 경우, 무료 평가판 용량에 등록하세요.
필수 조건
- Lakehouse를 만들기 전에 먼저 Fabric 작업 공간을 생성해야 합니다.
- CSV 파일을 수집하기 전에 OneDrive를 구성해야 합니다. OneDrive를 구성하지 않은 경우 Microsoft 365 무료 평가판에 등록합니다. 무료 평가판 - 한 달 동안 Microsoft 365를 사용해 보세요.
Lakehouse 만들기
이 섹션에서는 Fabric에서 레이크하우스를 만듭니다.
Fabric에 있는 탐색 표시줄에서 작업 공간을 선택합니다.
작업 영역을 열려면 맨 위에 있는 검색 상자에 해당 이름을 입력하고 검색 결과에서 선택합니다.
작업 영역에서 새 항목을 선택한 다음, Lakehouse를 선택합니다.
새 Lakehouse 대화 상자의 이름 필드에 wwilakehouse를 입력합니다.
만들기를 선택하여 새 Lakehouse를 만들고 엽니다.
샘플 데이터 수집
이 섹션에서는 Lakehouse에 샘플 고객 데이터를 수집합니다.
참고 항목
OneDrive를 구성하지 않은 경우 Microsoft 365 무료 평가판에 등록합니다. 무료 평가판 - 한 달 동안 Microsoft 365를 사용해 보세요.
Fabric 샘플 리포지토리에서 dimension_customer.csv 파일을 다운로드합니다.
홈 탭의 Lakehouse에서 데이터 가져오기 아래에 Lakehouse에 데이터를 로드하는 옵션이 표시됩니다. 새 Dataflow Gen2를 선택합니다.
새 데이터 흐름 화면에서 Text/CSV 파일에서 가져오기를 선택합니다.
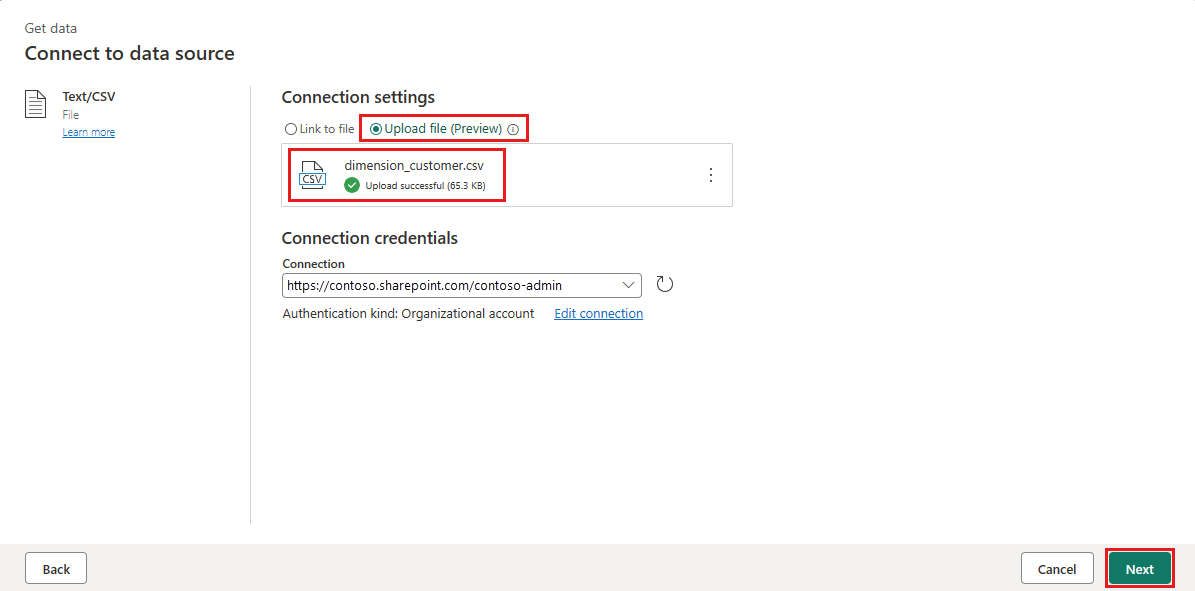
데이터 원본에 연결 화면에서 파일 업로드 라디오 단추를 선택합니다. 1단계에서 다운로드한 dimension_customer.csv 파일을 끌어서 놓습니다. 파일을 업로드한 후 다음을 선택합니다.
파일 데이터 미리 보기 페이지에서 데이터를 미리 확인하고 만들기를 선택하여 계속 진행한 후 데이터 흐름 캔버스로 돌아갑니다.
쿼리 설정 창에서 이름 필드를 dimension_customer 업데이트합니다.
참고 항목
Fabric은 기본적으로 테이블 이름의 끝에 공백과 숫자를 추가합니다. 테이블 이름은 소문자여야 하며 공백을 포함해서는 안 됩니다. 적절하게 이름을 바꾸고 테이블 이름에서 공백을 제거합니다.
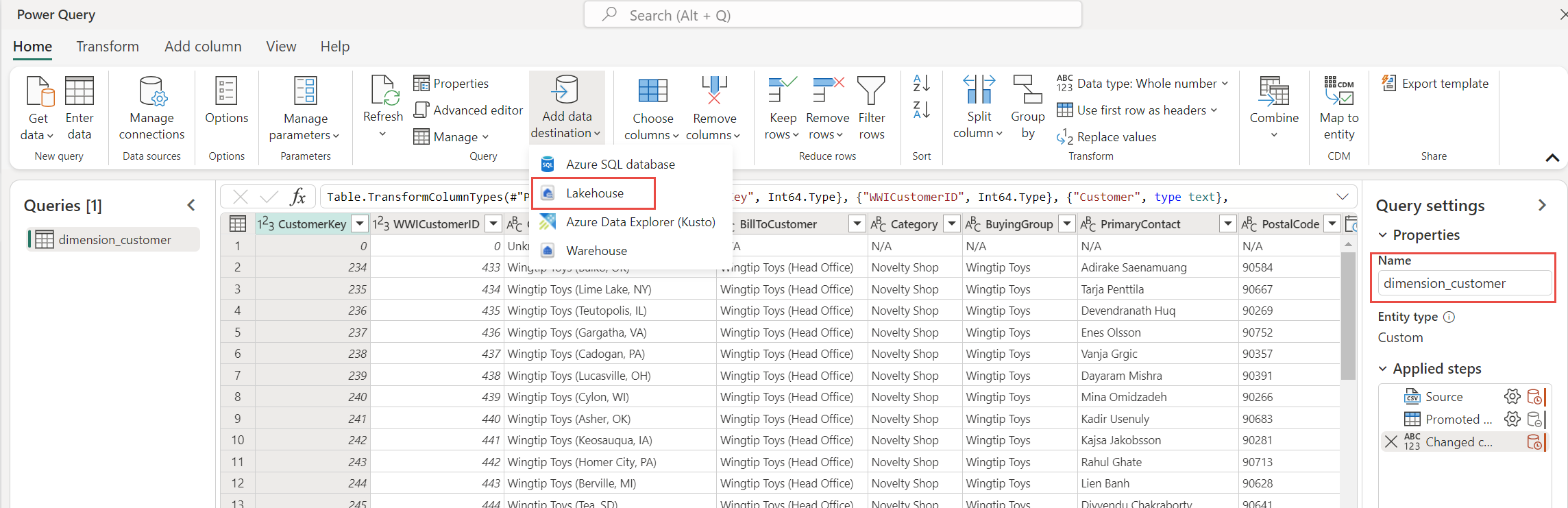
이 자습서에서는 고객 데이터를 Lakehouse와 연결했습니다. Lakehouse와 연결하려는 다른 데이터 항목이 있는 경우 다음을 추가할 수 있습니다.
메뉴 항목에서 데이터 대상 추가를 선택하고 Lakehouse를 선택합니다. 데이터 대상에 연결 화면에서 필요한 경우 계정에 로그인하고 다음을 선택합니다.
작업 영역에서 wwilakehouse로 이동합니다.
dimension_customer 테이블이 없으면 새 테이블 설정을 선택하고 테이블 이름 dimension_customer 입력합니다. 테이블이 이미 있는 경우 기존 테이블 설정을 선택하고 개체 탐색기의 테이블 목록에서 dimension_customer 선택합니다. 다음을 선택합니다.
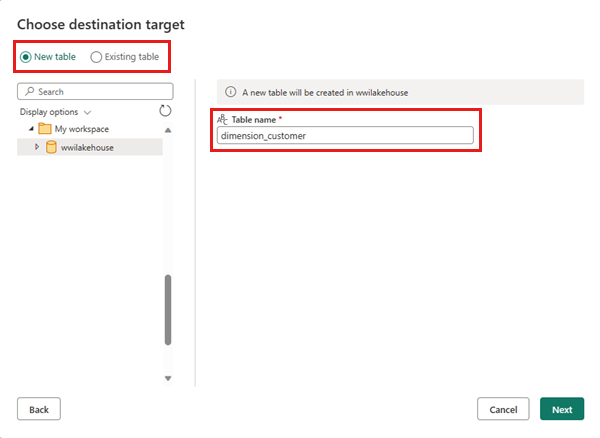
대상 설정 선택 창에서 업데이트 방법으로 바꾸기를 선택합니다. 데이터 흐름 캔버스로 돌아가려면 설정 저장을 선택합니다.
데이터 흐름 캔버스에서 비즈니스 요구 사항에 따라 데이터를 쉽게 변환할 수 있습니다. 편의상, 이 자습서에서는 변경하지 않습니다. 계속하려면 화면 오른쪽 아래에서 게시를 선택합니다.
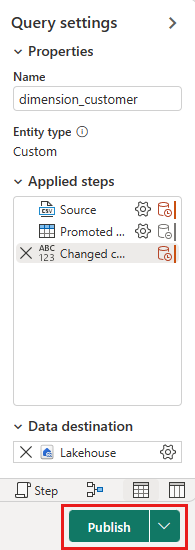
데이터 흐름 이름 옆에 있는 회전하는 원은 항목 보기에서 게시가 진행 중임을 나타냅니다. 게시가 완료되면 ...를 선택하고 속성을 선택합니다. 데이터 흐름의 이름을 Load Lakehouse 테이블로 바꾸고 저장을 선택합니다.
데이터 흐름을 새로 고치려면 데이터 흐름 이름 옆에 있는 지금 새로 고침 옵션을 선택합니다. 이 옵션은 데이터 흐름을 실행하고 원본 파일에서 Lakehouse 테이블로 데이터를 이동합니다. 진행 중인 동안 항목 보기의 새로 고침 열 아래에 회전하는 원이 표시됩니다.
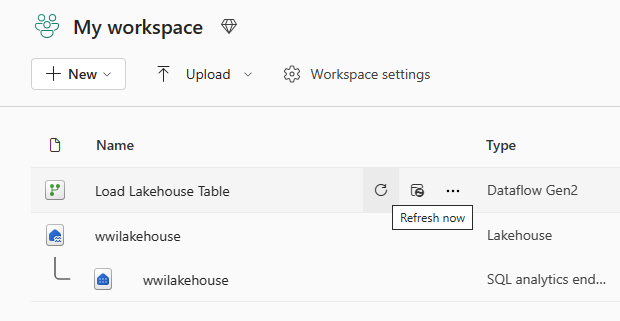
데이터 흐름이 갱신되면 네비게이션 바에서 새로운 레이크하우스를 선택하면 dimension_customer Delta 테이블을 볼 수 있습니다.
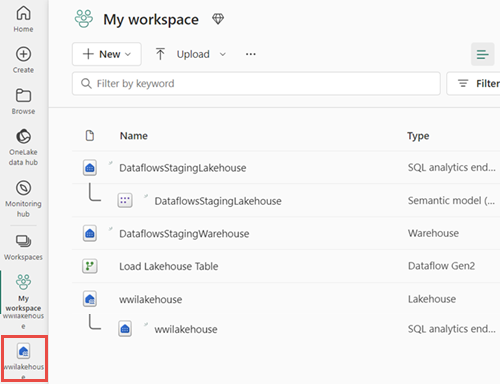
해당 데이터를 미리 보려면 테이블을 선택합니다. Lakehouse의 SQL 분석 엔드포인트를 사용하여 SQL 문을 사용하여 데이터를 쿼리할 수도 있습니다. 화면 오른쪽 위에 있는 Lakehouse 드롭다운 메뉴에서 SQL 분석 엔드포인트 선택합니다.
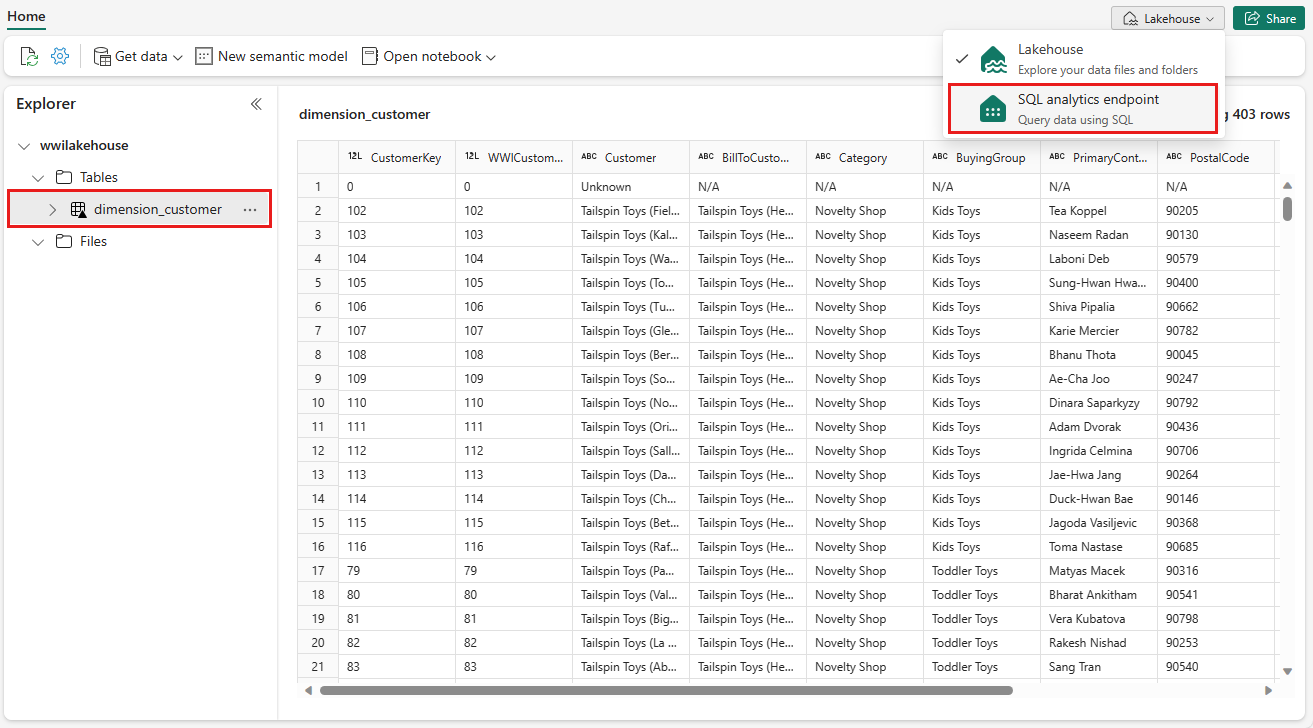
dimension_customer 테이블을 선택하여 데이터를 미리 보거나 새 SQL 쿼리를 선택하여 SQL 문을 작성합니다.
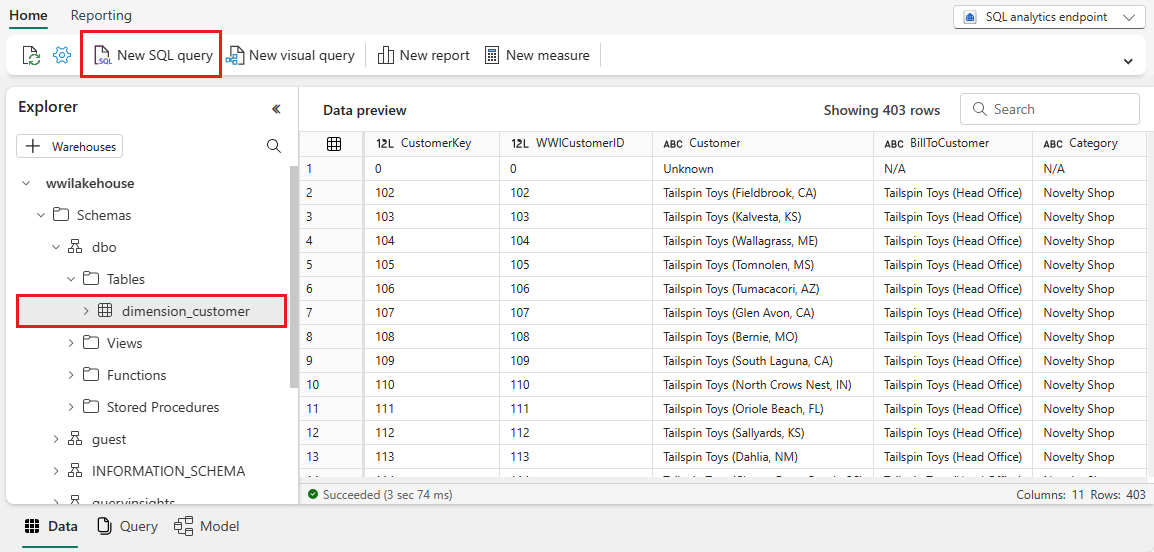
다음 샘플 쿼리는 dimension_customer 테이블의 BuyingGroup 열을 기반으로 행 수를 집계합니다. SQL 쿼리 파일은 이후 참조를 위해 자동으로 저장되며 필요에 따라 이러한 파일의 이름을 바꾸거나 삭제할 수 있습니다.
스크립트를 실행하려면 스크립트 파일의 맨 위에 있는 실행 아이콘을 선택합니다.
SELECT BuyingGroup, Count(*) AS Total FROM dimension_customer GROUP BY BuyingGroup



보고서 작성
이 섹션에서는 수집된 데이터에서 보고서를 빌드합니다.
이전에는 모든 Lakehouse 테이블과 뷰가 의미 체계 모델에 자동으로 추가되었습니다. 최근 업데이트를 통해 새 Lakehouse의 경우 의미 체계 모델에 테이블을 수동으로 추가해야 합니다. Lakehouse를 열고 SQL 분석 엔드포인트 뷰로 전환합니다. 보고 탭에서 기본 의미 체계 모델 관리를 선택하고 의미 체계 모델에 추가할 테이블을 선택합니다. 이 경우 dimension_customer 테이블을 선택합니다.
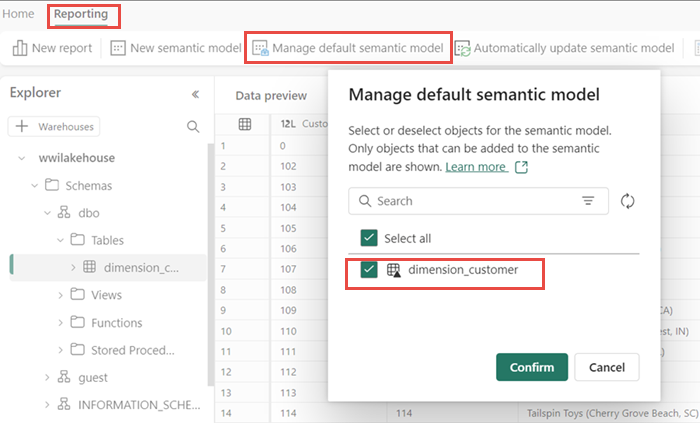
의미 체계 모델의 테이블이 항상 동기화되도록 하려면 SQL 분석 엔드포인트 보기로 전환하고 Lakehouse 설정 창을 엽니다. 기본 Power BI 의미 체계 모델을 선택하고 기본 Power BI 의미 체계 모델 동기화를 켭니다. 자세한 내용은 기본 Power BI 의미 체제 모델을 참조하세요.
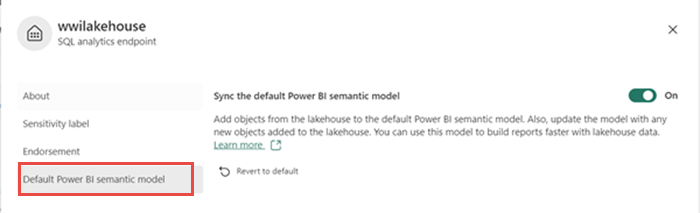
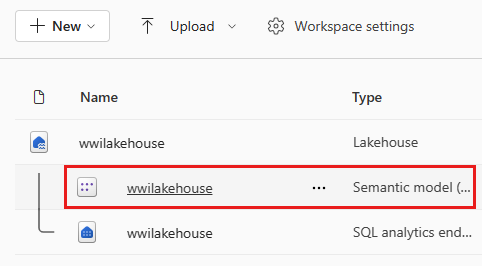
테이블을 추가한 후 Fabric은 Lakehouse와 동일한 이름의 의미 체계 모델을 만듭니다.
의미 체계 모델 창에서 모든 테이블을 볼 수 있습니다. 보고서를 처음부터 만들거나 페이지를 매긴 보고서를 만들거나 Power BI에서 데이터를 기반으로 보고서를 자동으로 만들 수 있습니다. 이 자습서의 경우 이 데이터 탐색에서 보고서 자동 만들기를 선택합니다. 다음 자습서에서는 보고서를 새로 만듭니다.
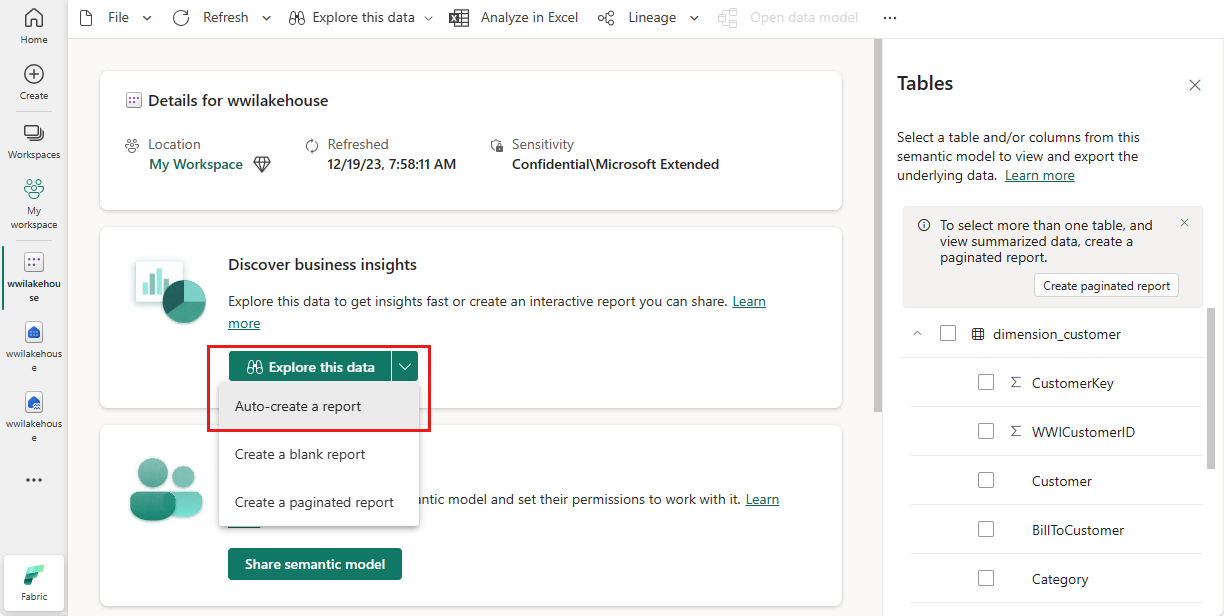
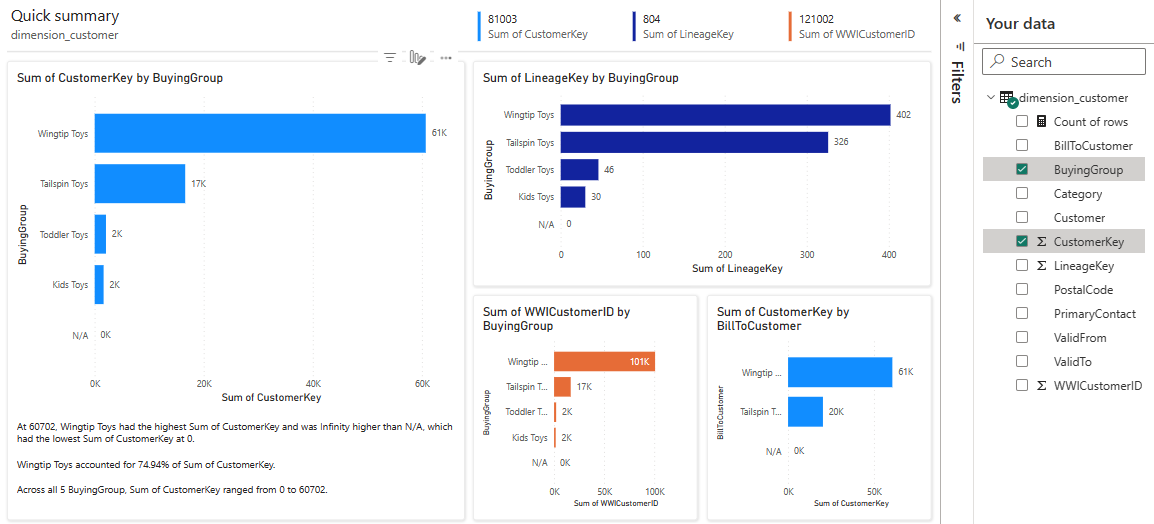
테이블은 차원이고 측정값이 없으므로 Power BI는 행 개수에 대한 측정값을 만들고 여러 열에 걸쳐 집계하고 다음 이미지와 같이 다른 차트를 만듭니다. 위쪽 리본에서 저장을 선택하여 나중에 이 보고서를 저장할 수 있습니다. 다른 테이블이나 열을 포함하거나 제외하여 요구 사항을 충족하기 위해 이 보고서를 추가로 변경할 수 있습니다.