Apache Spark の使用に向けて準備を行う
Apache Spark は、Microsoft Fabric で "Spark プール" として知られるクラスター内の複数の処理ノード間で作業を調整することで大規模なデータ分析を可能にする分散データ処理フレームワークです。 もっと簡単に言えば、Spark では、複数のコンピューターに作業を分散することで、大量のデータをすばやく処理するための "分割統治" アプローチが使用されます。 タスクの分散と結果の照合のプロセスは、Spark によって自動的に処理されます。
Spark では、Java、Scala (Java ベースのスクリプト言語)、Spark R、Spark SQL、PySpark (Python の Spark 固有のバリアント) など、さまざまな言語で記述されたコードを実行できます。 実際には、ほとんどの Data Engineering と分析ワークロードは、PySpark と Spark SQL の組み合わせを使用して実現されます。
Spark プール
Spark プールは、データ処理タスクを分散するコンピューティング "ノード" で構成されます。 一般的なアーキテクチャを次の図に示します。
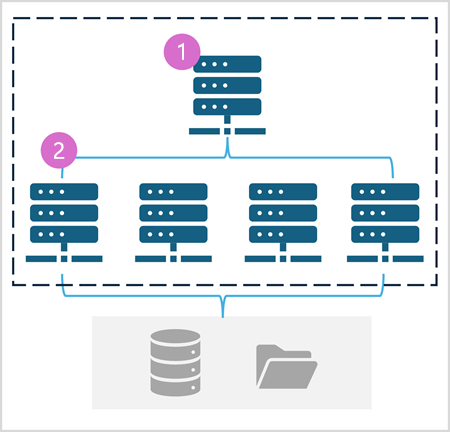
この図に示すように、Spark プールには次の 2 種類のノードが含まれます。
- Spark プール内の "ヘッド" ノードは、"ドライバー" プログラムを介して分散プロセスを調整します。
- プールには、Executor プロセスが実際のデータ処理タスクを実行する複数の worker ノードが含まれています。
Spark プールでは、この分散コンピューティング アーキテクチャを使用して、互換性のあるデータ ストア (OneLake ベースの Data Lakehouse など) のデータにアクセスして処理します。
Microsoft Fabric の Spark プール
Microsoft Fabric は、各ワークスペースに "スターター プール" を提供し、最小限のセットアップと構成で Spark ジョブをすばやく開始して実行できるようにします。 特定のワークロードのニーズまたはコストの制約に従って、スターター プールに含まれるノードを最適化するように構成できます。
さらに、特定のデータ処理ニーズをサポートする特定のノード構成を使用して、カスタム Spark プールを作成できます。
Note
Spark プールの設定をカスタマイズする機能は、Fabric 容量レベルで Fabric 管理者が無効にできます。 詳細については、Fabric ドキュメントでData Engineering とデータ サイエンスのキャパシティ管理設定に関する説明を参照してください。
スターター プールの設定を管理し、ワークスペース設定の [Data Engineering/科学] セクションで新しい Spark プールを作成できます。
Spark プールの具体的な構成設定は次のとおりです。
- ノード ファミリ: Spark クラスター ノードに使用される仮想マシンの種類。 ほとんどの場合、メモリ最適化ノードで最適なパフォーマンスが提供されます。
- 自動スケーリング:必要に応じてノードを自動的にプロビジョニングするかどうか、その場合はプールに割り当てるノードの初期数と最大数。
- 動的割り当て:データ ボリュームに基づいて worker ノードに Executor プロセスを動的に割り当てるかどうか。
ワークスペースに 1 つ以上のカスタム Spark プールを作成する場合は、特定の Spark ジョブに対して特定のプールが指定されていない場合に使用する既定のプールとして、そのうちの 1 つ (またはスターター プール) を設定できます。
ヒント
Microsoft Fabric での Spark プールの管理の詳細については、Microsoft Fabric のドキュメントで Microsoft Fabric でのスターター プールの構成と Microsoft Fabric でカスタム Spark プールを作成する方法を参照してください。
ランタイムと環境
Spark オープン ソース エコシステムには、複数のバージョンの Spark "ランタイム" が含まれています。これは、インストールされている Apache Spark、Delta Lake、Python、その他のコア ソフトウェア コンポーネントのバージョンを決定します。 さらに、ランタイム内で、一般的な (および場合によっては非常に特殊な) タスク用に、さまざまなコード ライブラリをインストールして使用できます。 多くの Spark 処理は PySpark を使用して実行されるため、広範囲の Python ライブラリにより、実行する必要があるタスクに関係なく、おそらく役立つライブラリが確実に存在するようになります。
場合によっては、組織はさまざまなデータ処理タスクをサポートするために "複数の" 環境を定義する必要がある場合があります。 各環境では、特定のランタイム バージョンと、特定の操作を実行するためにインストールする必要があるライブラリを定義します。 その後、データ エンジニアとデータ サイエンティストは、特定のタスクに Spark プールで使用する環境を選択できます。
Microsoft Fabric の Spark ランタイム
Microsoft Fabric では複数の Spark ランタイムがサポートされており、リリースされた新しいランタイムのサポートは引き続き追加されます。 ワークスペース設定インターフェイスを使用して、Spark プールの起動時に既定の環境で使用される Spark ランタイムを指定できます。
ヒント
Microsoft Fabric の Spark ランタイムの詳細については、Microsoft Fabric のドキュメントで Fabric での Apache Spark ランタイム関する説明を参照してください。
Microsoft Fabric の環境
Fabric ワークスペースにカスタム環境を作成して、さまざまなデータ処理操作に特定の Spark ランタイム、ライブラリ、構成設定を使用できます。
![Microsoft Fabric の [環境] ページのスクリーンショット。](../../wwl/use-apache-spark-work-files-lakehouse/media/spark-environment.png)
環境を作成するときに、次のことができます。
- 使用する Spark ランタイムを指定します。
- すべての環境にインストールされている組み込みライブラリを表示します。
- Python パッケージ インデックス (PyPI) から特定のパブリック ライブラリをインストールします。
- パッケージ ファイルをアップロードしてカスタム ライブラリをインストールします。
- 環境で使用する Spark プールを指定します。
- 既定の動作をオーバーライドする Spark 構成プロパティを指定します。
- 環境内で使用できる必要があるリソース ファイルをアップロードします。
少なくとも 1 つのカスタム環境を作成した後、ワークスペース設定で既定の環境として指定できます。
ヒント
Microsoft Fabric でのカスタム環境の使用の詳細については、Microsoft Fabric のドキュメントで Microsoft Fabric での環境の作成、構成、使用に関する説明を参照してください。
その他の Spark 構成オプション
Spark プールと環境の管理は、Fabric ワークスペースで Spark 処理を管理するための主な方法です。 ただし、さらに最適化を行うために使用できる追加のオプションがいくつかあります。
ネイティブ実行エンジン
Microsoft Fabric の "ネイティブ実行エンジン" は、Lakehouse インフラストラクチャで Spark 操作を直接実行するベクター化された処理エンジンです。 ネイティブ実行エンジンを使用すると、Parquet または Delta ファイル形式で大規模なデータ セットを操作するときのクエリのパフォーマンスを大幅に向上させることができます。
ネイティブ実行エンジンを使用するには、環境レベルまたは個々のノートブック内で有効にすることができます。 環境レベルでネイティブ実行エンジンを有効にするには、環境構成で次の Spark プロパティを設定します。
- spark.native.enabled: true
- spark.shuffle.manager: org.apache.spark.shuffle.sort.ColumnarShuffleManager
特定のスクリプトまたはノートブックに対してネイティブ実行エンジンを有効にするには、次のように、コードの先頭でこれらの構成プロパティを設定できます。
%%configure
{
"conf": {
"spark.native.enabled": "true",
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
}
}
ヒント
ネイティブ実行エンジンの詳細については、Microsoft Fabric のドキュメントで Fabric Spark のネイティブ実行エンジンに関する説明を参照してください。
高コンカレンシー モード
Microsoft Fabric で Spark コードを実行すると、Spark セッションが開始されます。 "高コンカレンシー モード" を使用して複数の同時実行ユーザーまたはプロセス間で Spark セッションを共有することで、Spark リソースの使用効率を最適化できます。 ノートブックに対して高コンカレンシー モードが有効になっている場合、複数のユーザーは、同じ Spark セッションを使用するノートブックでコードを実行できます。その際に、あるノートブックの変数が別のノートブックのコードの影響を受けないように、コードの分離が保証されます。 Spark ジョブに対して高コンカレンシー モードを有効にして、非対話型の Spark スクリプトの同時実行に対して同様の効率を実現することもできます。
高コンカレンシー モードを有効にするには、ワークスペース設定インターフェイスの [Data Engineering/科学] セクションを使用します。
ヒント
高コンカレンシー モードの詳細については、Microsoft Fabric のドキュメントで Apache Spark for Fabric の高コンカレンシー モードに関する説明を参照してください。
MLflow の自動ログ記録
MLflow は、機械学習のトレーニングとモデル デプロイを管理するためにデータ サイエンス ワークロードで使用されるオープン ソース ライブラリです。 MLflow の主な機能は、モデルのトレーニングと管理の操作をログに記録する機能です。 既定では、Microsoft Fabric は MLflow を使用して機械学習の実験アクティビティを暗黙的にログに記録します。データ サイエンティストが、これを実行するためのコードを明示的に含める必要はありません。 この機能は、ワークスペースの設定で無効にすることができます。
Fabric 容量のための Spark 管理
管理者は、Fabric 容量レベルで Spark 設定を管理し、組織内のワークスペースの Spark 設定を制限およびオーバーライドできます。
ヒント
Fabric 容量レベルでの Spark 構成の管理の詳細については、Microsoft Fabric のドキュメントで Fabric 容量の Data Engineering とデータ サイエンスの設定の構成と管理に関する説明を参照してください。