Microsoft Fabric でカスタム Spark プールを作成する方法
このドキュメントでは、分析ワークロード用に Microsoft Fabric でカスタム Apache Spark プールを作成する方法について説明します。 Apache Spark プールを使用すると、ユーザーは特定の要件に基づいて調整されたコンピューティング環境を作成し、最適なパフォーマンスとリソース使用率を確保できます。
自動スケールの最小ノードと最大ノードを指定します。 これらの値に基づいて、システムはジョブのコンピューティング要件の変化に応じてノードを動的に取得および廃止し、効率的なスケーリングとパフォーマンスの向上を実現します。 Spark プールでの Executor の動的割り当てにより、手動の Executor 構成の必要性も軽減されます。 代わりに、データ ボリュームとジョブ レベルのコンピューティングニーズに応じて、Executor の数が調整されます。 このプロセスにより、パフォーマンスの最適化とリソース管理を気にすることなく、ワークロードに集中できます。
手記
カスタム Spark プールを作成するには、ワークスペースへの管理者アクセス権が必要です。 容量管理者は、容量管理者設定の Spark コンピューティング セクションで、カスタマイズされたワークスペースプール オプションを有効にする必要があります。 詳細については、「ファブリック容量に対する Spark コンピュート設定 」をで確認してください。
カスタム Spark プールを作成する
ワークスペースに関連付けられている Spark プールを作成または管理するには:
ワークスペースに移動し、[ワークスペースの設定]
選択します。 データ エンジニアリング/サイエンス オプションを選択してメニューを展開し、Spark 設定を選択します。
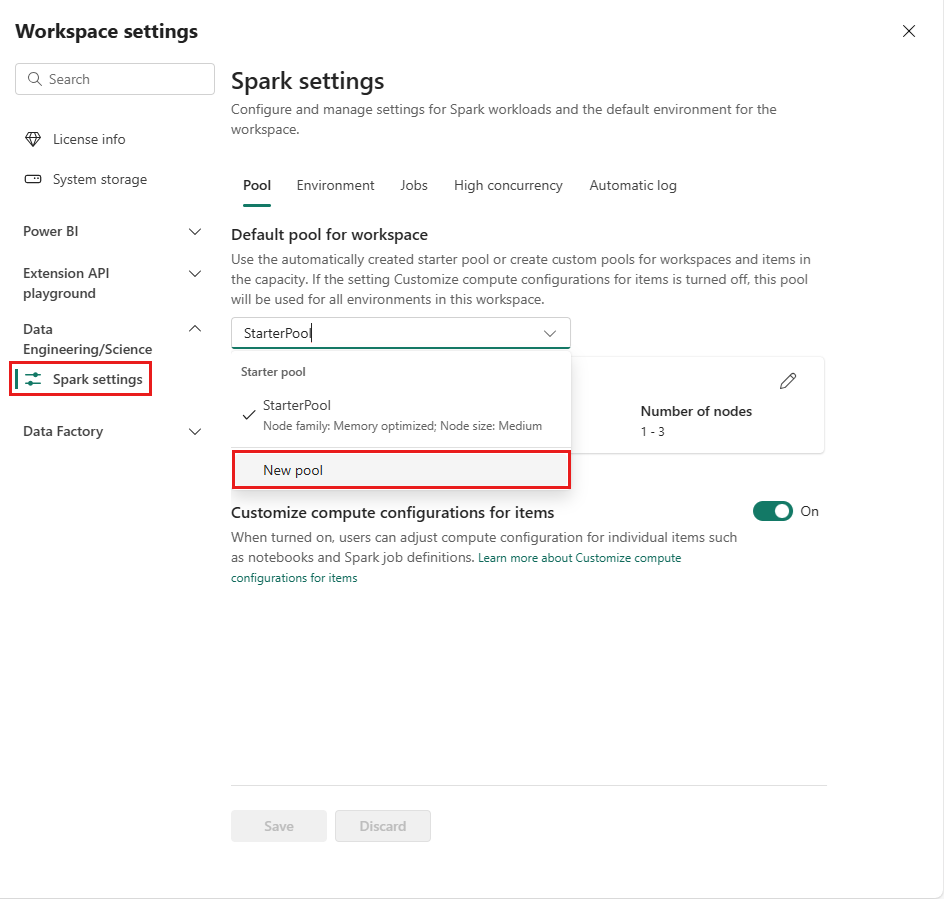
新しいプール オプションを選択します。 作成プール 画面で、Spark プールに名前を付けます。 また、ノード ファミリを選択し、ワークロードのコンピューティング要件に基づいて、使用可能なサイズ (Small、Medium、Large、X-Large、XX-Large) から ノード サイズ を選択します。
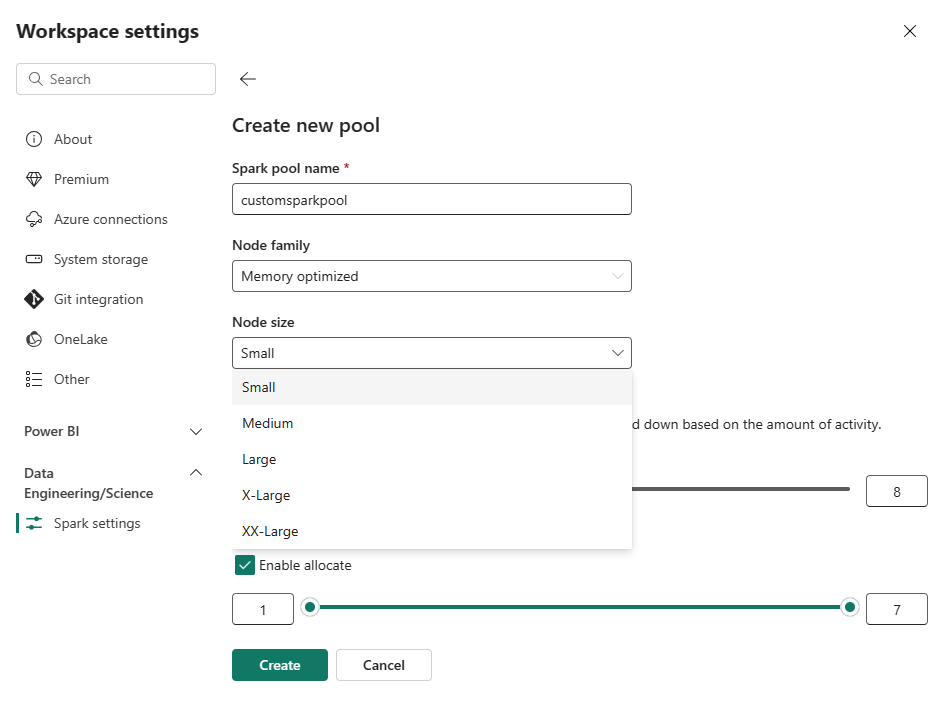
カスタム プールの最小ノード構成を 1に設定できます。 Fabric Spark は 1 つのノードを持つクラスターに復元可能な可用性を提供するため、ジョブの失敗、障害時のセッションの損失、または小規模な Spark ジョブのコンピューティング料金の超過について心配する必要はありません。
カスタム Spark プールの自動スケールを有効または無効にすることができます。 自動スケールが有効になっている場合、プールは、ユーザーが指定した最大ノード制限まで新しいノードを動的に取得し、ジョブの実行後に削除します。 この機能は、ジョブの要件に基づいてリソースを調整することで、パフォーマンスを向上させます。 Fabric 容量 SKU の一部として購入した容量ユニット内に収まるノードのサイズを設定できます。

Spark プールに対して動的実行プログラムの割り当てを有効にすることもできます。これによって、ユーザー指定の最大バインド内の Executor の最適な数が自動的に決定されます。 この機能により、データ ボリュームに基づいて Executor の数が調整され、パフォーマンスとリソース使用率が向上します。

これらのカスタム プールの既定の自動一時停止期間は 2 分です。 自動一時停止期間に達すると、セッションは期限切れになり、クラスターは割り当て解除されます。 ノードの数と、カスタム Spark プールが使用される期間に基づいて課金されます。
関連コンテンツ
- 詳細については、Apache Spark パブリック ドキュメントを参照してください。
- Microsoft Fabricの
Spark ワークスペース管理設定の使用を始めましょう。