Fabric 容量のデータ エンジニアリングとデータ サイエンスの設定を構成および管理する
適用対象:✅ Microsoft Fabric でのデータ エンジニアリングとデータ サイエンス
Azure portal から Microsoft Fabric を作成すると、容量の作成に使用されるサブスクリプションに関連付けられている Fabric テナントに自動的に追加されます。 Microsoft Fabric の簡略化されたセットアップでは、容量を Fabric テナントにリンクする必要ありません。 新しく作成された容量が管理設定ウィンドウに一覧表示されるためです。 この構成により、管理者は企業分析チーム用の容量の設定をより迅速に開始できます。
容量のデータ エンジニアリング/サイエンスの設定を変更するには、その容量の管理者ロールが必要です。 容量でユーザーに割り当てることができるロールについて詳しくは、容量のロールに関する記事を参照してください。
Microsoft Fabric 容量のデータ エンジニアリング/サイエンスの設定を管理するには、次の手順を使用します。
[設定] オプションを選択して、Fabric アカウントの設定ウィンドウを開きます。 [Governance and insights] (ガバナンスと分析情報) セクションで [Admin portal] (管理ポータル) を選択します
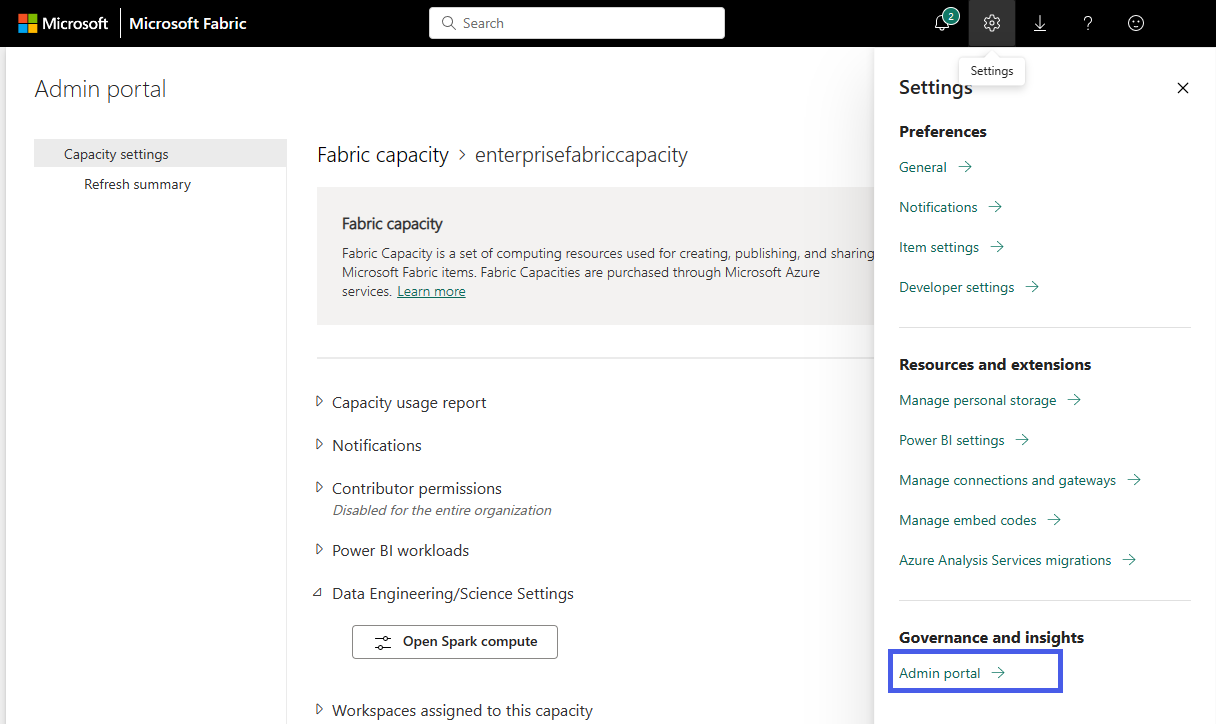
[容量の設定] オプションを選択してメニューを展開し、[Fabric capacity] (Fabric の容量) タブを選択します。ここには、テナントで作成した容量が表示されます。 構成する容量を選択します。
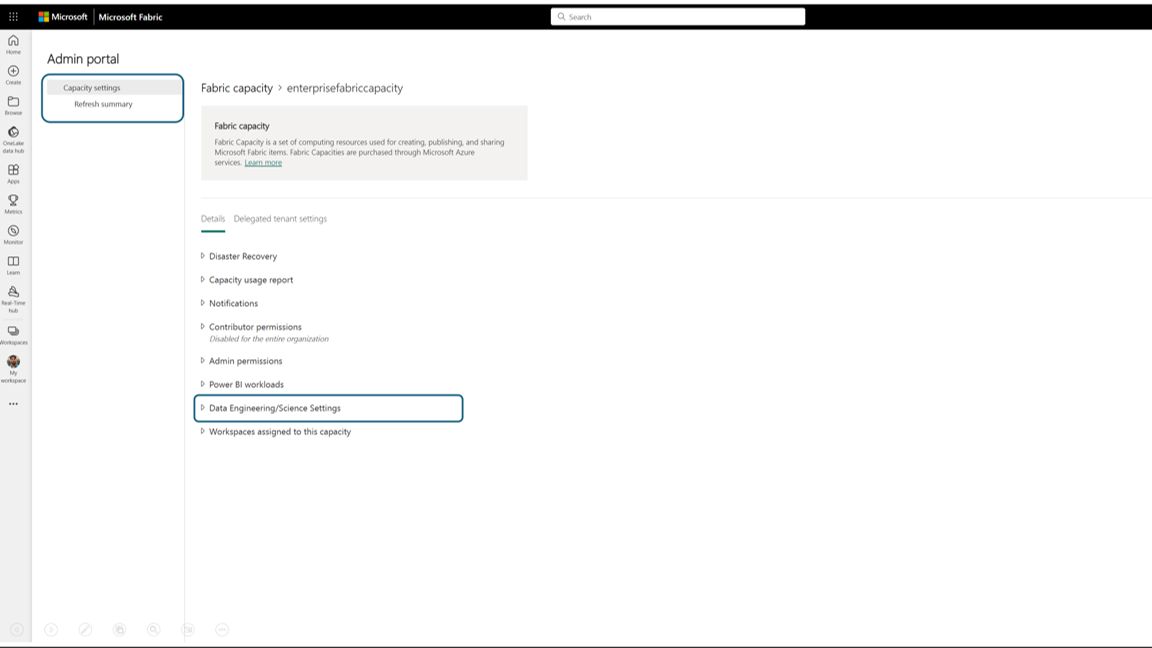
容量の詳細ウィンドウに移動すると、容量の使用状況やその他の管理コントロールを表示できます。 [Data Engineering/Science Settings] (データ エンジニアリング/サイエンスの設定) セクションに移動し、[Open Spark Compute] (Spark コンピューティングを開く) を選択します。 次のパラメーターを構成します。
Note
ファブリック容量管理ポータルからデータ エンジニアリング/サイエンス設定を調べるには、少なくとも 1 つのワークスペースをファブリック容量にアタッチする必要があります。
- [Customized workspace pools] (カスタマイズされたワークスペース プール): このオプションを有効または無効にすることで、コンピューティングのカスタマイズをワークスペース管理者に制限または民主化できます。 このオプションを有効にすると、ワークスペース管理者は、ワークスペース レベルのカスタム Spark プールを作成、更新、または削除できます。 さらに、コンピューティング要件に基づいて、容量の最大コア数制限内でそれらのサイズを変更できます。
Microsoft Fabric での Data Engineering と Data Science 用の容量プール (パブリック プレビュー)
Spark 設定の [プール リスト] セクションで、[追加] オプションをクリックして、Fabric 容量用のカスタム プールを作成できます。
![管理ポータルの設定の [プールの一覧] セクションを示すスクリーンショット。](media/capacity-settings-management/capacity-settings-pool-list.png)
[プールの作成] セクションに移動します。ここで、プール名、ノード ファミリを指定し、ノード サイズを選択し、カスタム プールの最小ノードと最大ノードの設定、自動スケーリングの有効化/無効化、Executor の動的割り当てを行います。
![[管理ポータル] の設定の [プールの作成] セクションを示すスクリーンショット。](media/capacity-settings-management/capacity-pools-creation.png)
[作成] を選択し、設定を保存します。
![[管理ポータル] の設定に保存された容量プールを示すスクリーンショット。](media/capacity-settings-management/capacity-settings-pool-creation.png)
![管理ポータルの設定の [プールの一覧] セクションを示すスクリーンショット。](media/capacity-settings-management/capacity-settings-pool-list.png#lightbox)
Note
容量設定で作成されたカスタム プールは、スターター プール経由で提供されるセッションとは異なり、オンデマンド セッションであり、セッション開始待機時間は 2 分から 3 分です。
これで、新しく作成された容量プールが、この Fabric 容量に接続されているすべてのワークスペースの [プールの選択] メニューでコンピューティング オプションとして使用できるようになりました。
![[ワークスペース設定] のプール リストに一覧表示されている容量プールを示すスクリーンショット。](media/capacity-settings-management/capacity-pools-workspace-pool-options.png)
ワークスペースの環境項目で、作成した容量プールをコンピューティング オプションとして表示することもできます。
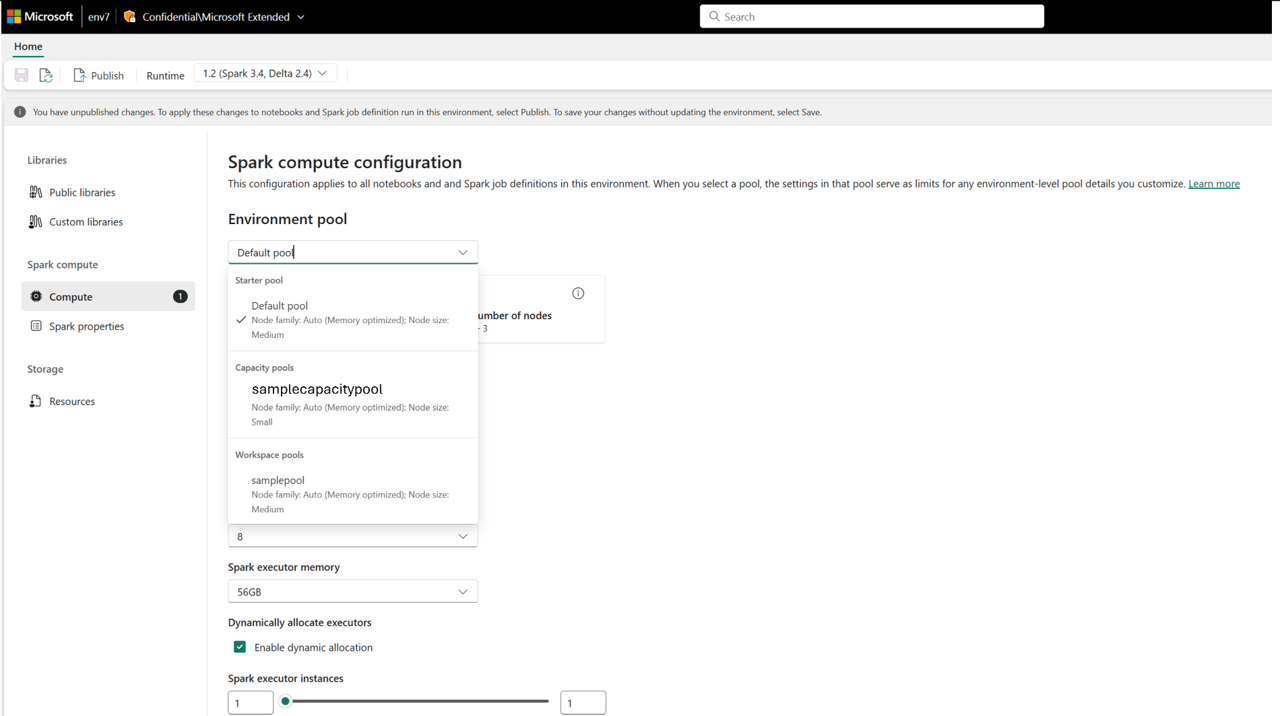
これにより、Microsoft Fabric で Spark コンピューティングのコンピューティング ガバナンスを管理するための他の管理制御が提供されます。 容量管理者は、ワークスペースのプールを作成し、ワークスペース レベルのカスタマイズを無効化できます。これにより、ワークスペース管理者はカスタム プールを作成できなくなります。