Azure Data Factory または Azure Synapse Analytics を使用して Microsoft Fabric Lakehouse でデータをコピーおよび変換する
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
Microsoft Fabric レイクハウスは、構造化データと非構造化データを 1 つの場所で保存、管理、分析するためのデータ アーキテクチャ プラットフォームです。 Microsoft Fabric のすべてのコンピューティング エンジン間でシームレスにデータにアクセスできるようにする方法について詳しくは、Lakehouse と Delta テーブルに関する記事をご覧ください。 既定では、データは V オーダーで Lakehouse テーブルに書き込まれます。詳細については、Delta Lake テーブルの最適化と V オーダーに関する記事を参照してください。
この記事では、Copy アクティビティを使って Microsoft Fabric Lakehouse との間でデータをコピーする方法と、Data Flow を使って Microsoft Fabric Lakehouse でデータを変換する方法の概要を説明します。 詳細については、Azure Data Factory または Azure Synapse Analytics の概要記事を参照してください。
サポートされる機能
この Microsoft Fabric Lakehouse コネクタは、次の機能のためにサポートされています。
| サポートされる機能 | IR |
|---|---|
| Copy アクティビティ (ソース/シンク) | ① ② |
| マッピング データ フロー (ソース/シンク) | ① |
| Lookup アクティビティ | ① ② |
| GetMetadata アクティビティ | ① ② |
| アクティビティを削除する | ① ② |
① Azure 統合ランタイム ② セルフホステッド統合ランタイム
はじめに
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用します。
UI を使って Microsoft Fabric Lakehouse のリンク サービスを作成する
次の手順を使って、Azure portal UI で Microsoft Fabric Lakehouse のリンク サービスを作成します。
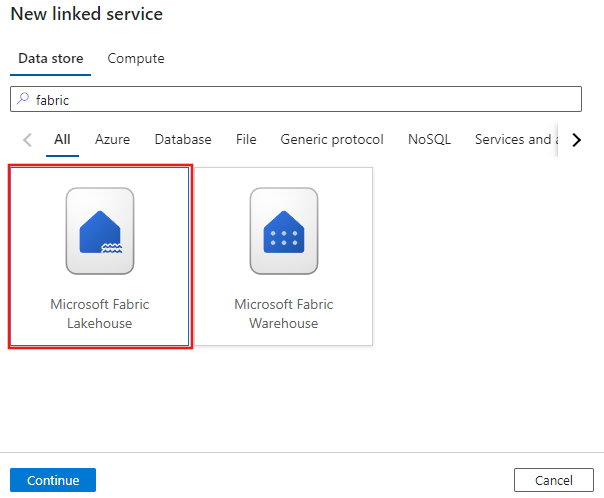
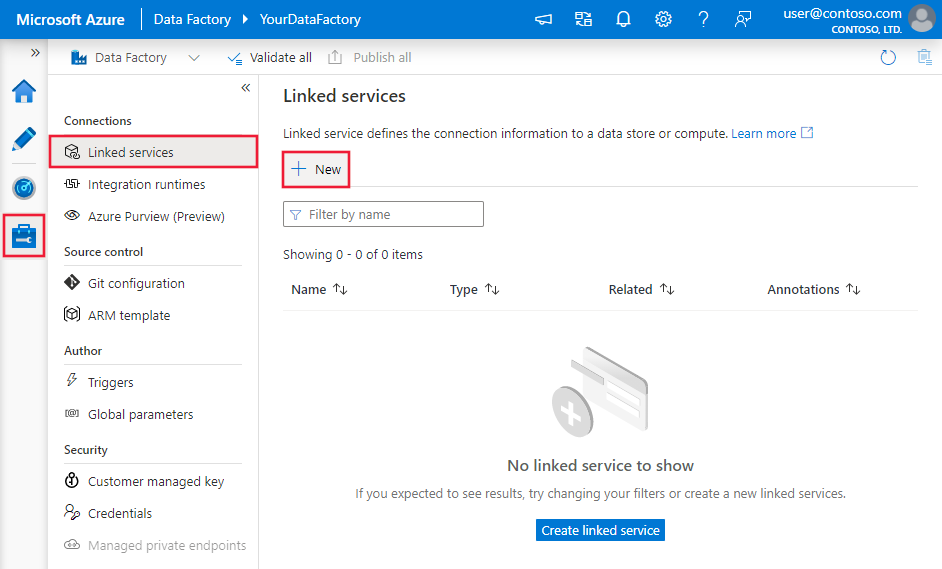
Azure Data Factory または Synapse ワークスペースの [管理] タブに移動し、[リンク サービス] を選択して、[新規] を選択します。
Microsoft Fabric Lakehouse を検索し、コネクタを選びます。
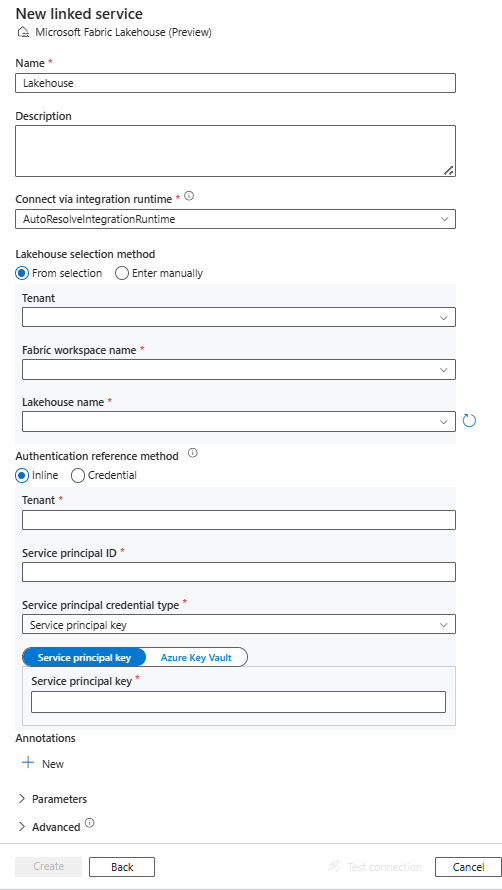
サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
コネクタの構成の詳細
次のセクションでは、Microsoft Fabric Lakehouse に固有の Data Factory エンティティを定義するために使われるプロパティについて詳しく説明します。
リンクされたサービス プロパティ
Microsoft Fabric Lakehouse コネクタでは、次の認証の種類がサポートされています。 詳細については、対応するセクションをご覧ください。
サービス プリンシパルの認証
サービス プリンシパル認証を使用するには、次の手順に従います。
Microsoft ID プラットフォームにアプリケーションを登録し、クライアント シークレットを追加します。 その後、これらの値を記録しておきます。リンクされたサービスを定義するときに使います。
- アプリケーション (クライアント) ID。リンク サービスのサービス プリンシパル ID です。
- クライアント シークレット値。リンク サービスのサービス プリンシパル キーです。
- テナント ID
Microsoft Fabric ワークスペースで、サービス プリンシパルに少なくとも共同作成者ロールを付与します。 次の手順のようにします。
自分の Microsoft Fabric ワークスペースに移動し、上部のバーにある [アクセスの管理] を選びます。 次に、[ユーザーまたはグループの追加] を選びます。
![Fabric ワークスペースの [アクセスの管理] の選択を示すスクリーンショット。](media/connector-microsoft-fabric-lakehouse/fabric-workspace-manage-access.png)
![Fabric ワークスペースの [アクセスの管理] ウィンドウを示すスクリーンショット。](media/connector-microsoft-fabric-lakehouse/manage-access-pane.png)
[ユーザーの追加] ペインで、ご利用のサービス プリンシパル名を入力し、ドロップダウン リストから、該当するサービス プリンシパルを選びます。
Note
Power BI テナント設定で Fabric API へのサービス プリンシパルのアクセスが有効になっていない限り、サービス プリンシパルは [ユーザーの追加] の一覧には表示されません。
ロールとして共同作成者以上 (管理者、メンバー) を指定してから、[追加] を選びます。
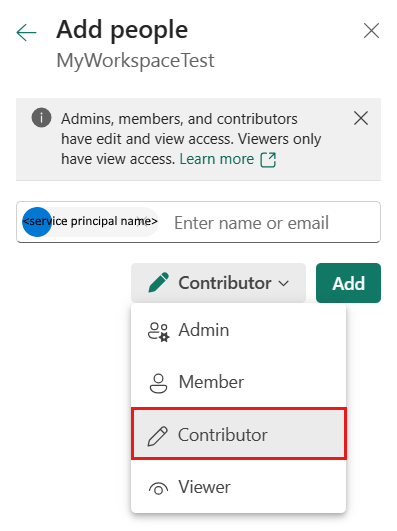
[アクセスの管理] ペイン上にサービス プリンシパルが表示されます。
リンクされたサービスでは、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは、Lakehouse に設定する必要があります。 | はい |
| workspaceId | Microsoft Fabric ワークスペース ID。 | はい |
| artifactId | Microsoft Fabric Lakehouse オブジェクト ID。 | はい |
| tenant | アプリケーションが存在するテナントの情報 (ドメイン名またはテナント ID) を指定します。 これは、Azure portal の右上隅をマウスでポイントすることで取得できます。 | はい |
| servicePrincipalId | アプリケーションのクライアント ID を取得します。 | はい |
| servicePrincipalCredentialType | サービス プリンシパル認証に使用する資格情報の種類。 使用できる値は ServicePrincipalKey と ServicePrincipalCert です。 | Yes |
| servicePrincipalCredential | サービス プリンシパルの資格情報。 資格情報の種類として ServicePrincipalKey を使用する場合は、アプリケーションのクライアント シークレット値を指定します。 このフィールドを SecureString とマークして安全に保存するか、Azure Key Vault に保存されているシークレットを参照します。 資格情報として ServicePrincipalCert を使用する場合は、Azure Key Vault 内の証明書を参照し、証明書のコンテンツ タイプが PKCS #12 であることを確認します。 |
はい |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 データ ストアがプライベート ネットワーク内にある場合、Azure Integration Runtime またはセルフホステッド統合ランタイムを使用できます。 指定されていない場合は、既定の Azure Integration Runtime が使用されます。 | いいえ |
例: サービス プリンシパル キー認証の使用
サービス プリンシパル キーを Azure Key Vault に格納することもできます。
{
"name": "MicrosoftFabricLakehouseLinkedService",
"properties": {
"type": "Lakehouse",
"typeProperties": {
"workspaceId": "<Microsoft Fabric workspace ID>",
"artifactId": "<Microsoft Fabric Lakehouse object ID>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
データセットのプロパティ
Microsoft Fabric Lakehouse コネクタでは、Microsoft Fabric Lakehouse Files データセットと Microsoft Fabric Lakehouse Table データセットの 2 種類のデータセットがサポートされています。 詳細については、対応するセクションをご覧ください。
データセットの定義に使用できるセクションとプロパティの一覧については、データセットに関する記事をご覧ください。
Microsoft Fabric Lakehouse Files データセット
Microsoft Fabric Lakehouse コネクタでは、次のファイル形式がサポートされています。 形式ベースの設定については、各記事を参照してください。
形式ベースの Microsoft Fabric Lakehouse Files データセットの location 設定では、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセット内で location の下にある type プロパティは、LakehouseLocation に設定する必要があります。 |
はい |
| folderPath | フォルダーのパス。 ワイルドカードを使用してフォルダーをフィルター処理する場合は、この設定をスキップし、アクティビティのソース設定で指定します。 | いいえ |
| fileName | 特定の folderPath の下のファイル名。 ワイルドカードを使用してファイルをフィルター処理する場合は、この設定をスキップし、アクティビティのソース設定で指定します。 | いいえ |
例:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"location": {
"type": "LakehouseLocation",
"fileName": "<file name>",
"folderPath": "<folder name>"
},
"columnDelimiter": ",",
"compressionCodec": "gzip",
"escapeChar": "\\",
"firstRowAsHeader": true,
"quoteChar": "\""
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ]
}
}
Microsoft Fabric Lakehouse Table データセット
Microsoft Fabric Lakehouse Table データセットでは、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセットの type プロパティは LakehouseTable に設定する必要があります。 | はい |
| schema | スキーマの名前。 指定しない場合は、既定値の dbo が使用されます。 |
いいえ |
| テーブル | テーブルの名前。 テーブル名は、1 文字以上の長さであり、'/' または '\' を含まず、末尾にドットがなく、先頭または末尾にスペースがないものにする必要があります。 | はい |
例:
{
"name": "LakehouseTableDataset",
"properties": {
"type": "LakehouseTable",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"schema": [< physical schema, optional, retrievable during authoring >]
}
}
コピー アクティビティのプロパティ
Copy アクティビティのプロパティは、Microsoft Fabric Lakehouse Files データセットと Microsoft Fabric Lakehouse Table データセットでは異なります。 詳細については、対応するセクションをご覧ください。
アクティビティの定義に使用できるセクションとプロパティの一覧については、コピー アクティビティの構成およびパイプラインとアクティビティに関する記事をご覧ください。
Copy アクティビティでの Microsoft Fabric Lakehouse Files
Copy アクティビティのソースまたはシンクとして Microsoft Fabric Lakehouse Files データセットの種類を使うための詳細な構成については、次のセクションをご覧ください。
ソースの種類としての Microsoft Fabric Lakehouse Files
Microsoft Fabric Lakehouse コネクタでは、次のファイル形式がサポートされています。 形式ベースの設定については、各記事を参照してください。
Microsoft Fabric Lakehouse Files データセットを使って Microsoft Fabric Lakehouse からデータをコピーするには、いくつかのオプションがあります。
- データセットに指定されている特定のパスからコピーします。
- フォルダー パスまたはファイル名に対するワイルドカード フィルターについては、
wildcardFolderPathおよびwildcardFileNameを確認してください。 - 特定のテキスト ファイルで定義されているファイルをファイル セットとしてコピーします。
fileListPathを確認してください。
Microsoft Fabric Lakehouse Files データセットを使うとき、形式ベースのコピー ソースの storeSettings 設定には、次のプロパティがあります。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type |
storeSettings の下の type プロパティは、LakehouseReadSettings に設定する必要があります。 |
はい |
| コピーするファイルを特定する: | ||
| オプション 1: 静的パス |
データセットで指定されているフォルダーまたはファイル パスからコピーします。 フォルダーからすべてのファイルをコピーする場合は、さらに * として wildcardFileName を指定します。 |
|
| オプション 2: ワイルドカード - wildcardFolderPath |
ソース フォルダーをフィルター処理するための、ワイルドカード文字を含むフォルダー パス。 使用できるワイルドカーは、 * (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。実際のフォルダー名にワイルドカードまたはこのエスケープ文字が含まれている場合は、^ を使用してエスケープします。 「フォルダーとファイル フィルターの例」の他の例をご覧ください。 |
いいえ |
| オプション 2: ワイルドカード - wildcardFileName |
ソース ファイルをフィルター処理するための、特定の folderPath/wildcardFolderPath の下のワイルドカード文字を含むファイル名。 使用できるワイルドカーは、 * (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。実際のファイル名にワイルドカードまたはこのエスケープ文字が含まれている場合は、^ を使用してエスケープします。 「フォルダーとファイル フィルターの例」の他の例をご覧ください。 |
はい |
| オプション 3: ファイルの一覧 - fileListPath |
指定されたファイル セットをコピーすることを示します。 コピーするファイルの一覧を含むテキスト ファイルをポイントします。データセットで構成されているパスへの相対パスであるファイルを 1 行につき 1 つずつ指定します。 このオプションを使用する場合は、データセットにファイル名を指定しないでください。 その他の例については、ファイル リストの例を参照してください。 |
いいえ |
| 追加の設定: | ||
| recursive | データをサブフォルダーから再帰的に読み取るか、指定したフォルダーからのみ読み取るかを指定します。 recursive が true に設定されていて、シンクがファイル ベースのストアである場合、空のフォルダーまたはサブフォルダーはシンクでコピーも作成もされません。 使用可能な値: true (既定値) および false。 fileListPath を構成する場合、このプロパティは適用されません。 |
いいえ |
| deleteFilesAfterCompletion | 宛先ストアに正常に移動した後、バイナリ ファイルをソース ストアから削除するかどうかを示します。 ファイルの削除はファイルごとに行われるので、Copy アクティビティが失敗した場合、一部のファイルは既にコピー先にコピーされてコピー元から削除されているのに、他のファイルはまだコピー元ストアに残っていることがわかります。 このプロパティは、バイナリ ファイルのコピー シナリオでのみ有効です。 既定値: false。 |
いいえ |
| modifiedDatetimeStart | ファイルはフィルター処理され、元になる属性は最終更新時刻です。 ファイルは、最終変更日時が modifiedDatetimeStart と同じかそれよりも後であり、modifiedDatetimeEnd よりも前である場合に選択されます。 時刻は "2018-12-01T05:00:00Z" の形式で UTC タイム ゾーンに適用されます。 各プロパティには NULL を指定できます。これは、ファイル属性フィルターをデータセットに適用しないことを意味します。 modifiedDatetimeStart に datetime 値を設定し、modifiedDatetimeEnd を NULL にした場合は、最終更新時刻属性が datetime 値以上であるファイルが選択されることを意味します。
modifiedDatetimeEnd に datetime 値を設定し、modifiedDatetimeStart を NULL にした場合は、最終更新時刻属性が datetime 値以下であるファイルが選択されることを意味します。fileListPath を構成する場合、このプロパティは適用されません。 |
いいえ |
| modifiedDatetimeEnd | 上記と同じです。 | いいえ |
| enablePartitionDiscovery | パーティション分割されているファイルの場合は、ファイル パスのパーティションを解析してそれを別のソース列として追加するかどうかを指定します。 指定できる値は false (既定値) と true です。 |
いいえ |
| partitionRootPath | パーティション検出が有効になっている場合は、パーティション分割されたフォルダーをデータ列として読み取るための絶対ルート パスを指定します。 指定しない場合の既定は、以下のようになります。 - ソース上のデータセットまたはファイルの一覧内のファイル パスを使用する場合、パーティションのルート パスはそのデータセットで構成されているパスです。 - ワイルドカード フォルダー フィルターを使用する場合、パーティションのルート パスは最初のワイルドカードの前のサブパスです。 たとえば、データセット内のパスを "root/folder/year=2020/month=08/day=27" として構成するとします。 - パーティションのルート パスを "root/folder/year=2020" として指定した場合は、コピー アクティビティによって、ファイル内の列とは別に、それぞれ "08" と "27" の値を持つ month と day という 2 つの追加の列が生成されます。- パーティションのルート パスを指定しない場合、追加の列は生成されません。 |
いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されたコンカレント接続数の上限。 コンカレント接続を制限する場合にのみ、値を指定します。 | いいえ |
例:
"activities": [
{
"name": "CopyFromLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "LakehouseReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
シンクの種類としての Microsoft Fabric Lakehouse Files
Microsoft Fabric Lakehouse コネクタでは、次のファイル形式がサポートされています。 形式ベースの設定については、各記事を参照してください。
Microsoft Fabric Lakehouse Files データセットを使うとき、形式ベースのコピー シンクの storeSettings 設定には、次のプロパティがあります。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type |
storeSettings の下の type プロパティは、LakehouseWriteSettings に設定する必要があります。 |
はい |
| copyBehavior | ソースがファイル ベースのデータ ストアのファイルの場合は、コピー動作を定義します。 使用できる値は、以下のとおりです。 - PreserveHierarchy (既定値):ターゲット フォルダー内でファイル階層を保持します。 ソース フォルダーへのソース ファイルの相対パスはターゲット フォルダーへのターゲット ファイルの相対パスと同じになります。 - FlattenHierarchy:ソース フォルダーのすべてのファイルをターゲット フォルダーの第一レベルに配置します。 ターゲット ファイルは、自動生成された名前になります。 - MergeFiles:ソース フォルダーのすべてのファイルを 1 つのファイルにマージします。 ファイル名を指定した場合、マージされたファイル名は指定した名前になります。 それ以外は自動生成されたファイル名になります。 |
いいえ |
| blockSizeInMB | Microsoft Fabric Lakehouse へのデータの書き込みに使うブロック サイズを MB 単位で指定します。 詳細は、ブロック BLOB に関するページを参照してください。 指定できる値は、4 MB から 100 MB です。 既定では、ソース ストアの種類とデータに基づいて、ADF によってブロック サイズが自動的に決定されます。 Microsoft Fabric Lakehouse への非バイナリ コピーの場合、最大約 4.75 TB のデータに収まるように、既定のブロック サイズは 100 MB になります。 データが大きくない場合、特に、低パフォーマンスのネットワークでセルフホステッド統合ランタイムを使用し、操作のタイムアウトやパフォーマンスの問題が発生する場合は、最適ではない可能性があります。 ブロック サイズは明示的に指定できますが、blockSizeInMB*50000 が確実にデータを格納するのに十分な大きさであるようにします。そうしないと、Copy アクティビティの実行は失敗します。 |
いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されたコンカレント接続数の上限。 コンカレント接続を制限する場合にのみ、値を指定します。 | いいえ |
| metadata | シンクにコピーするときにカスタム メタデータを設定します。
metadata 配列の各オブジェクトは追加列を表します。
name ではメタデータ キー名を定義し、value では、そのキーのデータ値を指定します。
属性の保持機能が使用されている場合は、ソース ファイルのメタデータを使用して、指定されたメタデータの和集合の作成や上書きが行われます。使用できるデータ値: - $$LASTMODIFIED: 予約済みの変数によって、ソース ファイルの最終更新時刻を格納することを指定します。 バイナリ形式のファイルベースのソースにのみ適用されます。- 式 - 静的な値 |
いいえ |
例:
"activities": [
{
"name": "CopyToLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings": {
"type": "LakehouseWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
}
]
},
"formatSettings": {
"type": "ParquetWriteSettings"
}
}
}
}
]
フォルダーとファイル フィルターの例
このセクションでは、ワイルドカード フィルターを使用した結果のフォルダーのパスとファイル名の動作について説明します。
| folderPath | fileName | recursive | ソースのフォルダー構造とフィルターの結果 (太字のファイルが取得されます) |
|---|---|---|---|
Folder* |
(空、既定値を使用) | false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(空、既定値を使用) | true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
ファイル リストの例
このセクションでは、コピー アクティビティのソースでファイル リスト パスを使用した結果の動作について説明します。
次のソース フォルダー構造があり、太字のファイルをコピーするとします。
| サンプルのソース構造 | FileListToCopy.txt のコンテンツ | ADF 構成 |
|---|---|---|
| filesystem FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv メタデータ FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
データセット内: - フォルダー パス: FolderAコピー アクティビティ ソース内: - ファイル リストのパス: Metadata/FileListToCopy.txt ファイル リストのパスは、コピーするファイルの一覧を含む同じデータ ストア内のテキスト ファイルをポイントします。データセットで構成されているパスへの相対パスで 1 行につき 1 つのファイルを指定します。 |
recursive と copyBehavior の例
このセクションでは、recursive 値と copyBehavior 値のさまざまな組み合わせでのコピー操作の動作について説明します。
| recursive | copyBehavior | ソースのフォルダー構造 | ターゲットの結果 |
|---|---|---|---|
| true | preserveHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲット Folder1 は、ソースと同じ構造で作成されます。 Folder1 File1 File2 Subfolder1 File3 File4 File5 |
| true | flattenHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲットの Folder1 は、次の構造で作成されます。 Folder1 File1 の自動生成された名前 File2 の自動生成された名前 File3 の自動生成された名前 File4 の自動生成された名前 File5 の自動生成された名前 |
| true | mergeFiles | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲットの Folder1 は、次の構造で作成されます。 Folder1 File1、File2、File3、File4、File5 の内容は 1 つのファイルにマージされて、自動生成されたファイル名が付けられます。 |
| false | preserveHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲットの Folder1 は、次の構造で作成されます。 Folder1 File1 File2 File3、File4、File5 を含む Subfolder1 は取得されません。 |
| false | flattenHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲットの Folder1 は、次の構造で作成されます。 Folder1 File1 の自動生成された名前 File2 の自動生成された名前 File3、File4、File5 を含む Subfolder1 は取得されません。 |
| false | mergeFiles | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲットの Folder1 は、次の構造で作成されます。 Folder1 File1、File2 の内容は 1 つのファイルにマージされ、自動生成されたファイル名が付けられます。 File1 の自動生成された名前 File3、File4、File5 を含む Subfolder1 は取得されません。 |
Copy アクティビティでの Microsoft Fabric Lakehouse Table
Copy アクティビティのソースまたはシンク データセットとして Microsoft Fabric Lakehouse Table データセットを使うための詳細な構成については、次のセクションをご覧ください。
ソースの種類としての Microsoft Fabric Lakehouse Table
Microsoft Fabric Lakehouse Table データセットを使って Microsoft Fabric Lakehouse からデータをコピーするには、Copy アクティビティのソースの type プロパティを LakehouseTableSource に設定します。 Copy アクティビティの source セクションでは、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティを LakehouseTableSource に設定する必要があります。 | はい |
| timestampAsOf | 古いスナップショットに対してクエリを実行するタイムスタンプ。 | いいえ |
| versionAsOf | 古いスナップショットに対してクエリを実行するバージョン。 | いいえ |
例:
"activities":[
{
"name": "CopyFromLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "LakehouseTableSource",
"timestampAsOf": "2023-09-23T00:00:00.000Z",
"versionAsOf": 2
},
"sink": {
"type": "<sink type>"
}
}
}
]
シンクの種類としての Microsoft Fabric Lakehouse Table
Microsoft Fabric Lakehouse Table データセットを使って Microsoft Fabric Lakehouse にデータをコピーするには、Copy アクティビティのシンクの type プロパティを LakehouseTableSink に設定します。 コピー アクティビティの sink セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティを LakehouseTableSink に設定する必要があります。 | はい |
Note
既定では、データは V オーダーで Lakehouse テーブルに書き込まれます。 詳細については、Delta Lake テーブルの最適化と V オーダーに関する記事を参照してください。
例:
"activities":[
{
"name": "CopyToLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "LakehouseTableSink",
"tableActionOption ": "Append"
}
}
}
]
Mapping Data Flow のプロパティ
マッピング データ フローでデータを変換するときは、Microsoft Fabric Lakehouse のファイルまたはテーブルの読み取りと書き込みを行うことができます。 詳細については、対応するセクションをご覧ください。
詳細については、マッピング データ フローのソース変換とシンク変換に関する記事をご覧ください。
マッピング データ フローでの Microsoft Fabric Lakehouse Files
マッピング データ フローのソースまたはシンク データセットとして Microsoft Fabric Lakehouse Files データセットを使うための詳細な構成については、次のセクションをご覧ください。
ソースまたはシンクの種類としての Microsoft Fabric Lakehouse Files
Microsoft Fabric Lakehouse コネクタでは、次のファイル形式がサポートされています。 形式ベースの設定については、各記事を参照してください。
インライン データセット型の Fabric Lakehouse ファイル ベース コネクタを使用するには、データに適したインライン データセットの種類を選択する必要があります。 データ形式に応じて、DelimitedText、Avro、JSON、ORC、または Parquet を使用できます。
マッピング データ フローでの Microsoft Fabric Lakehouse Table
マッピング データ フローのソースまたはシンク データセットとして Microsoft Fabric Lakehouse Table データセットを使うための詳細な構成については、次のセクションをご覧ください。
ソースの種類としての Microsoft Fabric Lakehouse Table
ソース オプションには、構成可能なプロパティはありません。
Note
現在、Lakehouse テーブル ソースの CDC サポートは利用できません。
シンクの種類としての Microsoft Fabric Lakehouse Table
次のプロパティは、マッピング データ フローの sink セクションでサポートされています。
| 名前 | 説明 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| 更新方法 | [Allow insert](挿入の許可) を単独で選択するか、新しいデルタ テーブルに書き込むときに、ターゲットは行ポリシー セットに関係なくすべての受信行を受け取ります。 データに他の行ポリシーの行が含まれている場合は、前述のフィルター変換を使用して除外する必要があります。 すべての更新メソッドを選択すると、マージが実行され、前述の行の変更変換を使用して設定された行ポリシーに従って行が挿入/削除/アップサート/更新されます。 |
はい |
true または false |
insertable deletable upsertable updateable |
| 最適化された書き込み | Spark Executor の内部シャッフルを最適化することで、書き込み操作のスループットを向上させることができます。 結果として、大きいサイズのパーティションやファイルの数が減ることに気付くかもしれません | いいえ |
true または false |
optimizedWrite: true |
| 自動圧縮 | 書き込み操作が完了すると、Spark によって自動的に OPTIMIZE コマンドが実行されてデータが再編成されます。これにより、必要に応じてより多くのパーティションが作成され、将来の読み取りパフォーマンスが向上します |
いいえ |
true または false |
autoCompact: true |
| マージ スキーマ | マージ スキーマ オプションを使うと、スキーマの進化が可能になります。つまり、現在の着信ストリームには存在し、ターゲットの Delta テーブルには存在していない列が、そのスキーマに自動的に追加されます。 このオプションは、すべての更新方法でサポートされます。 | いいえ |
true または false |
mergeSchema: true |
例: Microsoft Fabric Lakehouse Table シンク
sink(allowSchemaDrift: true,
validateSchema: false,
input(
CustomerID as string,
NameStyle as string,
Title as string,
FirstName as string,
MiddleName as string,
LastName as string,
Suffix as string,
CompanyName as string,
SalesPerson as string,
EmailAddress as string,
Phone as string,
PasswordHash as string,
PasswordSalt as string,
rowguid as string,
ModifiedDate as string
),
deletable:false,
insertable:true,
updateable:false,
upsertable:false,
optimizedWrite: true,
mergeSchema: true,
autoCompact: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CustomerTable
インライン データセット型の Fabric Lakehouse テーブルベース コネクタの場合は、データセットの種類として Delta を使用するだけでかまいません。 これにより、Fabric Lakehouse テーブルからデータの読み取りと書き込みを行うことができます。
Lookup アクティビティのプロパティ
プロパティの詳細については、Lookup アクティビティに関するページを参照してください。
GetMetadata アクティビティのプロパティ
プロパティの詳細については、GetMetadata アクティビティに関するページを参照してください。
Delete アクティビティのプロパティ
プロパティの詳細については、Delete アクティビティに関するページを参照してください。
関連するコンテンツ
コピー アクティビティによってソース、シンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するセクションを参照してください。