Azure Data Factory と Azure Synapse Analytics での ORC 形式
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新たに試用を開始する方法については、こちらをご覧ください。
ORC ファイルを解析する場合や、ORC 形式にデータを書き込む場合は、この記事に従ってください。
ORC 形式は、Amazon S3、Amazon S3 Compatible Storage、Azure Blob、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2、Azure Files、ファイル システム、FTP、Google Cloud Storage、HDFS、HTTP、Oracle Cloud Storage、SFTP の各コネクタでサポートされます。
データセットのプロパティ
データセットを定義するために使用できるセクションとプロパティの完全な一覧については、データセットに関する記事をご覧ください。 このセクションでは、ORC データセットでサポートされるプロパティの一覧を示します。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセットの type プロパティは、Orc に設定する必要があります。 | はい |
| location | ファイルの場所の設定。 ファイル ベースの各コネクタには、固有の場所の種類と location でサポートされるプロパティがあります。 詳細については、コネクタの記事でデータセットのプロパティに関するセクションを参照してください。> |
はい |
| compressionCodec | ORC ファイルへの書き込み時に使用する圧縮コーデック。 データ ファクトリーでは、ORC ファイルから読み取るときに、ファイルのメタデータに基づいて圧縮コーデックが自動的に決定されます。 サポートされている種類は、なし、zlib、snappy (既定)、および lzo です。 ORC ファイルの読み取り/書き込みの場合、コピー アクティビティでは現在、LZO がサポートされていないことに注意してください。 |
いいえ |
Azure Blob Storage 上の ORC データセットの例を次に示します。
{
"name": "OrcDataset",
"properties": {
"type": "Orc",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
}
}
}
}
以下の点に注意してください。
- 複合データ型 (MAP、LIST、STRUCT など) は、現在、コピー アクティビティではなくデータ フローでのみサポートされています。 データ フローで複合型を使用するには、データセットにファイル スキーマをインポートしないで、データセット内のスキーマを空白のままにしておきます。 次に、ソース変換で、プロジェクションをインポートします。
- 列名では、空白はサポートされません。
コピー アクティビティのプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関する記事を参照してください。 このセクションでは、ORC のソースとシンクでサポートされるプロパティの一覧を示します。
ソースとしての ORC
Copy アクティビティの *source* セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティは OrcSource に設定する必要があります。 | はい |
| storeSettings | データ ストアからデータを読み取る方法を指定するプロパティのグループ。 ファイル ベースの各コネクタには、storeSettings に、固有のサポートされる読み取り設定があります。 詳細については、コネクタの記事で Copy アクティビティのプロパティに関するセクションを参照してください。> |
いいえ |
シンクとしての ORC
Copy アクティビティの *sink* セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのシンクの type プロパティには OrcSink を設定する必要があります。 | はい |
| formatSettings | プロパティのグループ。 後の ORC の書き込み設定に関する表を参照してください。 | いいえ |
| storeSettings | データ ストアにデータを書き込む方法を指定するプロパティのグループ。 ファイル ベースの各コネクタには、storeSettings に、固有のサポートされる書き込み設定があります。 詳細については、コネクタの記事で Copy アクティビティのプロパティに関するセクションを参照してください。> |
いいえ |
formatSettings でサポートされている ORC の書き込み設定:
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | formatSettings の種類は OrcWriteSettings に設定する必要があります。 | Yes |
| maxRowsPerFile | データをフォルダーに書き込むとき、複数のファイルに書き込み、ファイルあたりの最大行を指定することを選択できます。 | No |
| fileNamePrefix | maxRowsPerFile が構成されている場合に使用されます。データを複数のファイルに書き込むとき、ファイル名のプレフィックスを指定します。結果的に <fileNamePrefix>_00000.<fileExtension> のパターンになります。 指定されていない場合、ファイル名プレフィックスは自動生成されます。 このプロパティは、ソースがファイルベース ストアかパーティション オプション対応データ ストアの場合、適用されません。 |
いいえ |
Mapping Data Flow のプロパティ
マッピング データ フローでは、次のデータ ストアで ORC 形式での読み取りと書き込みを実行できます。Azure Blob Storage、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2、SFTP。また、Amazon S3 で ORC 形式を読み取ることができます。
ORC ファイルは、ORC データセットまたはインライン データセットを使用して参照できます。
ソースのプロパティ
次の表に、ORC ソースでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [ソース オプション] タブで編集できます。
インライン データセットを使用する場合、「データセットのプロパティ」セクションで説明したプロパティと同じ追加のファイル設定が表示されます。
| Name | 説明 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| Format | 形式は orc である必要があります |
はい | orc |
format |
| Wild card paths (ワイルドカード パス) | ワイルドカードのパスに一致するすべてのファイルが処理されます。 データセットで設定されているフォルダーとファイル パスはオーバーライドされます。 | no | String[] | wildcardPaths |
| パーティションのルート パス | パーティション分割されたファイル データについては、パーティション フォルダーを列として読み取るためにパーティションのルート パスを入力できます | no | String | partitionRootPath |
| ファイルの一覧 | 処理するファイルを一覧表示しているテキスト ファイルをソースが指しているかどうか | no | true または false |
fileList |
| ファイル名を格納する列 | ソース ファイル名とパスを使用して新しい列を作成します | no | String | rowUrlColumn |
| 完了後 | 処理後にファイルを削除または移動します。 ファイル パスはコンテナー ルートから始まります | no | 削除: true または false 移動: [<from>, <to>] |
purgeFiles moveFiles |
| 最終更新日時でフィルター処理 | 最後に変更された日時に基づいてファイルをフィルター処理する場合に選択 | no | Timestamp | modifiedAfter modifiedBefore |
| [Allow no files found](ファイルの未検出を許可) | true の場合、ファイルが見つからない場合でもエラーはスローされない | no | true または false |
ignoreNoFilesFound |
ソースの例
ORC ソース構成に関連付けられているデータ フロー スクリプトは次のとおりです。
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'orc') ~> OrcSource
シンクのプロパティ
次の表に、ORC シンクでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [設定] タブで編集できます。
インライン データセットを使用する場合、「データセットのプロパティ」セクションで説明したプロパティと同じ追加のファイル設定が表示されます。
| Name | 説明 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| Format | 形式は orc である必要があります |
はい | orc |
format |
| Clear the folder (フォルダーのクリア) | 書き込みの前に宛先フォルダーがクリアされるかどうか | no | true または false |
truncate |
| ファイル名のオプション | 書き込まれたデータの名前付け形式です。 既定では、part-#####-tid-<guid> という形式で、パーティションごとに 1 ファイルです |
いいえ | パターン: String パーティションあたり: String[] 列内のデータとして: String 1 つのファイルに出力する: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
シンクの例
ORC シンク構成に関連付けられているデータ フロー スクリプトは次のとおりです。
OrcSource sink(
format: 'orc',
filePattern:'output[n].orc',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> OrcSink
セルフホステッド統合ランタイムの使用
重要
オンプレミスとクラウドのデータ ストアの間など、セルフホステッド統合ランタイムを利用したコピーでは、ORC ファイルを そのまま コピーしない場合は、64-bit JRE 8 (Java Runtime Environment) または OpenJDK と Microsoft Visual C++ 2010 再頒布可能パッケージ を IR マシンにインストールする必要があります。 詳細については、次の段落をご確認ください。
ORC ファイルのシリアル化または逆シリアル化を使用してセルフホステッド IR 上で実行されるコピーの場合、サービスによる Java ランタイムの検索は、JRE のレジストリ (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) の確認から始まり、見つからない場合は、OpenJDK のシステム変数 JAVA_HOME が確認されます。
- JRE を使用する場合:64 ビット IR には 64 ビット JRE が必要です。 こちらから入手できます。
- OpenJDK の使用方法:IR バージョン 3.13 以降でサポートされています。 jvm.dll を他のすべての必要な OpenJDK のアセンブリと共にセルフホステッド IR マシンにパッケージ化し、それに応じてシステム環境変数 JAVA_HOME を設定します。
- Microsoft Visual C++ 2010 再頒布可能パッケージのインストール方法:Visual C++ 2010 再頒布可能パッケージは、セルフホステッド IR インストールではインストールされません。 こちらから入手できます。
ヒント
セルフホステッド統合ランタイムを使用して、ORC 形式をコピー元またはコピー先にしてデータをコピーしたときに、"An error occurred when invoking java, message: java.lang.OutOfMemoryError:Java heap space" (java の呼び出し中にエラーが発生しました。メッセージ: java.lang.OutOfMemoryError:Java heap space) というエラーが発生する場合は、まず、セルフホステッド IR のホストであるマシン内に環境変数 _JAVA_OPTIONS を追加してください。次に、JVM の最小/最大ヒープ サイズを調整し、コピーを行えるようにしてから、パイプラインを再実行してください。
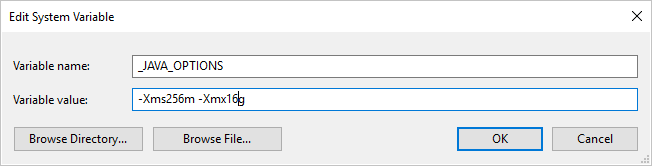
例: 変数 _JAVA_OPTIONS を設定して、値 -Xms256m -Xmx16g を指定します。 フラグ Xms では、Java 仮想マシン (JVM) の初期メモリ割り当てプールを指定します。Xmx では、最大メモリ割り当てプールを指定します。 これは、JVM 起動時のメモリ量が Xms、使用可能なメモリ量が最大で Xmx であることを意味します。 既定では、サービスにより最小で 64MB、最大で 1G が使用されます。