Esercitazione: Individuare le relazioni in un modello semantico usando il collegamento semantico
Questa esercitazione illustra come interagire con Power BI da un Jupyter Notebook e rilevare le relazioni tra tabelle con l'aiuto della libreria SemPy.
In questa esercitazione apprenderai a:
- Individuare le relazioni in un modello semantico (set di dati di Power BI), usando la libreria Python (SemPy) del collegamento semantico.
- Usare i componenti di SemPy che supportano l'integrazione con Power BI e consentono di automatizzare l'analisi della qualità dei dati. Questi componenti includono:
- FabricDataFrame: una struttura simile a pandas migliorata con informazioni semantiche aggiuntive.
- Funzioni per il pull di modelli semantici da un'area di lavoro Fabric nel tuo notebook.
- Funzioni che automatizzano la valutazione delle ipotesi sulle dipendenze funzionali e che identificano le violazioni delle relazioni nei modelli semantici.
Prerequisiti
Ottenere una sottoscrizione di Microsoft Fabric. In alternativa, iscriversi per ottenere una versione di valutazione di Microsoft Fabric gratuita.
Accedere a Microsoft Fabric.
Usa il selettore di esperienza in basso a sinistra nella tua home page per passare a Fabric.

Selezionare Aree di lavoro nel riquadro di spostamento sinistro per trovare e selezionare l'area di lavoro. Questa area di lavoro diventa l'area di lavoro corrente.
Scaricare i modelli semantici Customer Profitability Sample.pbix e Customer Profitability Sample (auto).pbix dal repository di modelli fabric GitHub e caricarli nell'area di lavoro.
Seguire la procedura nel notebook
Il notebook powerbi_relationships_tutorial.ipynb accompagna questa esercitazione.
Per aprire il notebook di accompagnamento per questa esercitazione, seguire le istruzioni riportate in Preparare il sistema per le esercitazioni di data science per importare il notebook nell'area di lavoro.
Se si preferisce copiare e incollare il codice da questa pagina, è possibile creare un nuovo notebook.
Assicurarsi di collegare un lakehouse al notebook prima di iniziare a eseguire il codice.
Configurare il notebook
In questa sezione viene configurato un ambiente notebook con i moduli e i dati necessari.
Installare
SemPyda PyPI usando la funzionalità di installazione in linea%pipall'interno del notebook:%pip install semantic-linkEseguire le importazioni necessarie dei moduli di SemPy che serviranno in un secondo momento:
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsImportare i pandas per applicare un'opzione di configurazione utile per la formattazione dell'output:
import pandas as pd pd.set_option('display.max_colwidth', None)
Esplorare i modelli semantici
Questa esercitazione usa un modello semantico di esempio standard Customer Profitability Sample.pbix. Per una descrizione del modello semantico, vedere Esempio di redditività dei clienti per Power BI.
Usare la funzione
list_datasetsdi SemPy per esplorare i modelli semantici nell'area di lavoro corrente:fabric.list_datasets()
Per il resto di questo notebook si usano due versioni del modello semantico Customer Profitability Sample:
- Customer Profitability Sample: modello semantico ottenuto da esempi di Power BI con relazioni di tabella predefinite
- Customer Profitability Sample (auto): gli stessi dati, ma le relazioni sono limitate a quelle che Power BI avrebbe individuato automaticamente.
Estrarre un modello semantico di esempio con il modello semantico predefinito
Caricare le relazioni predefinite e archiviate all'interno del modello semantico Customer Profitability Sample , usando la funzione
list_relationshipsdi SemPy. Questa funzione elenca dal modello a oggetti tabulare:dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsVisualizzare il
relationshipsDataFrame come grafico usando la funzioneplot_relationship_metadatadi SemPy:plot_relationship_metadata(relationships)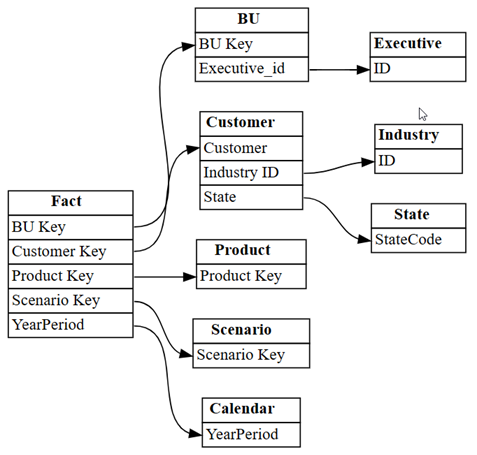

Questo grafico mostra la "verità di base" per le relazioni tra tabelle in questo modello semantico, come riflette il modo in cui sono state definite in Power BI da un esperto di dominio.
Integrare l'individuazione delle relazioni
Se si è iniziato con le relazioni rilevate automaticamente da Power BI, si avrà un set più piccolo.
Visualizzare le relazioni rilevate automaticamente da Power BI nel modello semantico:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)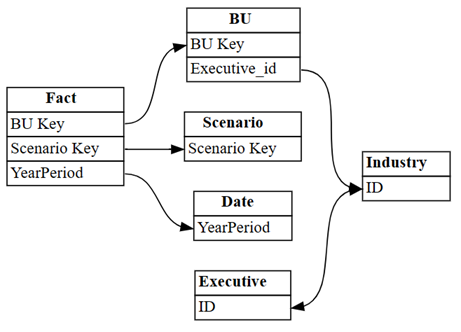
L'autodetezione di Power BI ha perso molte relazioni. Inoltre, due delle relazioni rilevate automaticamente non sono semanticamente corrette:
-
Executive[ID]->Industry[ID] -
BU[Executive_id]->Industry[ID]
-
Stampare le relazioni come tabella:
autodetectedLe relazioni non corrette per la tabella
Industryvengono visualizzate nelle righe con indice 3 e 4. Usare queste informazioni per rimuovere queste righe.Eliminare le relazioni identificate in modo non corretto.
autodetected.drop(index=[3,4], inplace=True) autodetectedOra si dispone di relazioni corrette, ma incomplete.
Visualizzare queste relazioni incomplete usando
plot_relationship_metadata:plot_relationship_metadata(autodetected)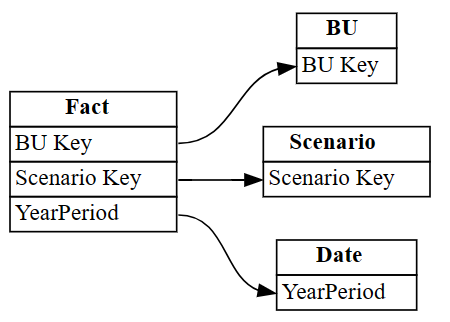
Caricare tutte le tabelle dal modello semantico usando le funzioni
list_tableseread_tabledi SemPy:tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Trovare relazioni tra tabelle, usando
find_relationshipsed esaminare l'output del log per ottenere informazioni dettagliate sul funzionamento di questa funzione:suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )Visualizzare le relazioni appena individuate:
plot_relationship_metadata(suggested_relationships_all)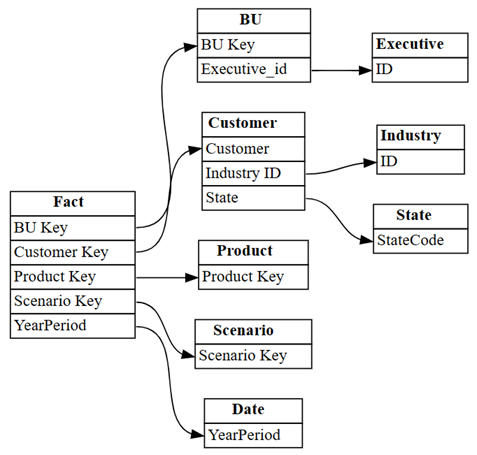
SemPy è stato in grado di rilevare tutte le relazioni.
Usare il parametro
excludeper limitare la ricerca alle relazioni aggiuntive non identificate in precedenza:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



Convalidare le relazioni
Prima di tutto, caricare i dati dal modello semantico Customer Profitability Sample:
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Verificare la sovrapposizione dei valori di chiave primaria ed esterna usando la funzione
list_relationship_violations. Fornire l'output della funzionelist_relationshipscome input alist_relationship_violations:list_relationship_violations(tables, fabric.list_relationships(dataset))Le violazioni delle relazioni forniscono alcune informazioni interessanti. Ad esempio, uno su sette valori in
Fact[Product Key]non è presente inProduct[Product Key]e questa chiave mancante è50.
L'analisi esplorativa dei dati è un processo interessante e lo è anche la pulizia dei dati. C'è sempre qualcosa che i dati nascondono, a seconda di come si esaminano, cosa si vuole chiedere e così via. Il collegamento semantico offre nuovi strumenti che è possibile usare per ottenere di più con i dati.
Contenuto correlato
Vedere altre esercitazioni per il collegamento semantico/SemPy:
- Esercitazione: Pulire i dati con dipendenze funzionali
- Esercitazione: Analizzare le dipendenze funzionali in un modello semantico di esempio
- Esercitazione: Estrarre e calcolare le misure di Power BI da un Jupyter Notebook
- Esercitazione: Individuare le relazioni nel set di dati Synthea usando il collegamento semantico
- Esercitazione: Convalidare i dati usando SemPy e Great Expectations (GX)