Esercitazione: Pulizia dei dati con dipendenze funzionali
In questa esercitazione si usano dipendenze funzionali per la pulizia dei dati. Esiste una dipendenza funzionale quando una colonna in un modello semantico (un set di dati di Power BI) è una funzione di un'altra colonna. Ad esempio, una colonna codice postale potrebbe determinare i valori in una colonna città. Una dipendenza funzionale si manifesta come una relazione uno-a-molti tra i valori in due o più colonne all'interno di un dataframe. Questa esercitazione usa il set di dati Synthea per illustrare in che modo le relazioni funzionali possono aiutare a rilevare i problemi di qualità dei dati.
In questa esercitazione si apprenderà come:
- Applicare le conoscenze di dominio per formulare ipotesi sulle dipendenze funzionali in un modello semantico.
- Acquisire familiarità con i componenti della libreria Python del collegamento semantico (SemPy) che consentono di automatizzare l'analisi della qualità dei dati. Questi componenti includono:
- FabricDataFrame: struttura simile a pandas migliorata con informazioni semantiche aggiuntive.
- Funzioni utili che automatizzano la valutazione delle ipotesi sulle dipendenze funzionali e che identificano le violazioni delle relazioni nei modelli semantici.
Prerequisiti
Ottieni una sottoscrizione Microsoft Fabric . In alternativa, iscriviti per una prova gratuita di Microsoft Fabric.
Accedi a Microsoft Fabric.
Usare l'interruttore dell'esperienza in basso a sinistra della home page per passare a Fabric.

- Selezionare aree di lavoro nel pannello di navigazione a sinistra per trovare e selezionare l'area di lavoro. Questa area di lavoro diventa l'area di lavoro corrente.
Seguire la procedura nel notebook
Il notebook intitolato data_cleaning_functional_dependencies_tutorial.ipynb accompagna questa esercitazione.
Per aprire il notebook di accompagnamento per questa esercitazione, seguire le istruzioni riportate in Preparare il sistema per le esercitazioni di data science per importare il notebook nell'area di lavoro.
Se preferisci copiare e incollare il codice da questa pagina, puoi creare un nuovo notebook.
Assicurati di collegare una lakehouse al notebook prima di iniziare l'esecuzione del codice.
Configurare il notebook
In questa sezione viene configurato un ambiente notebook con i moduli e i dati necessari.
- Per Spark 3.4 e versioni successive, il collegamento semantico è disponibile nel runtime predefinito quando si usa Fabric e non è necessario installarlo. Se si usa Spark 3.3 o versione successiva o se si vuole eseguire l'aggiornamento alla versione più recente di Semantic Link, è possibile eseguire il comando :
python %pip install -U semantic-link
Eseguire le importazioni necessarie di moduli necessari in un secondo momento:
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_syntheaEstrarre i dati di esempio. Per questa esercitazione si userà il set di dati Synthea di record medici sintetici (versione ridotta per semplicità):
download_synthea(which='small')
Esplora i dati
Inizializzare un
FabricDataFramecon il contenuto del file providers.csv:providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Verificare la presenza di problemi di qualità dei dati con la funzione
find_dependenciesdi SemPy tracciando un grafico delle dipendenze funzionali rilevate automaticamente:deps = providers.find_dependencies() plot_dependency_metadata(deps)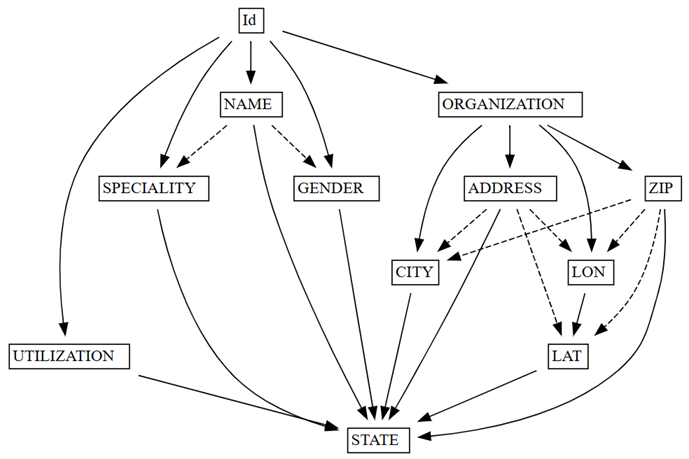
Il grafico delle dipendenze funzionali mostra che
IddeterminaNAMEeORGANIZATION(indicati dalle frecce a tinta unita), che è previsto, poichéIdè univoco:Verificare che
Idsia univoco:providers.Id.is_uniqueIl codice restituisce
Trueper verificare cheIdsia univoco.

Analizzare in profondità le dipendenze funzionali
Il grafico delle dipendenze funzionali mostra anche che ORGANIZATION determina ADDRESS e ZIP, come previsto. Tuttavia, ma è possibile che ZIP determini anche CITY, la freccia tratteggiata indica che la dipendenza è solo approssimativa, evidenziando un problema di qualità dei dati.
Ci sono altre peculiarità nel grafico. Ad esempio, NAME non determina GENDER, Id, SPECIALITYo ORGANIZATION. Ognuna di queste peculiarità potrebbe essere utile indagare.
Esaminare in modo più approfondito la relazione approssimativa tra
ZIPeCITY, usando la funzionelist_dependency_violationsdi SemPy per visualizzare un elenco tabulare di violazioni:providers.list_dependency_violations('ZIP', 'CITY')Disegnare un grafico con la funzione di visualizzazione
plot_dependency_violationsdi SemPy. Questo grafico è utile se il numero di violazioni è ridotto:providers.plot_dependency_violations('ZIP', 'CITY')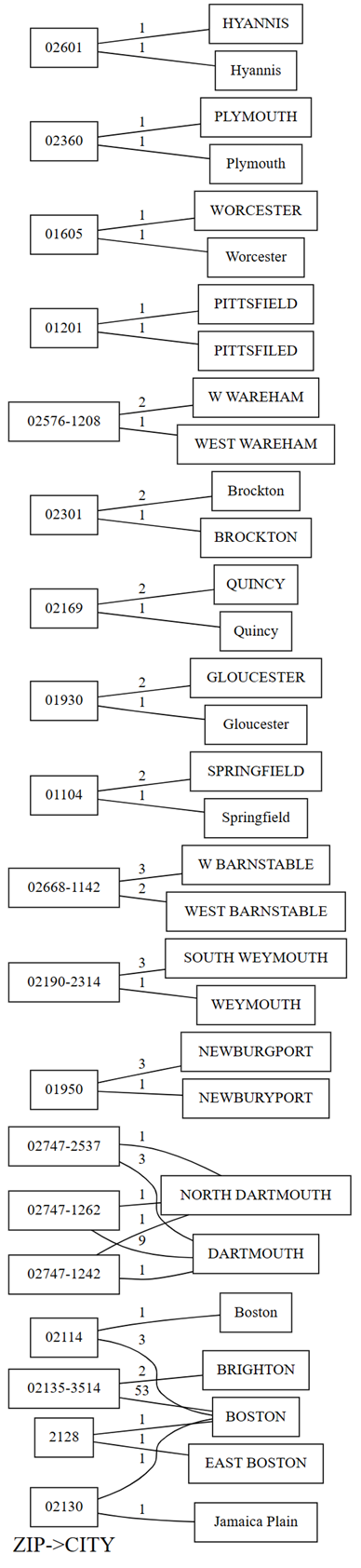
Il grafico delle violazioni delle dipendenze mostra i valori per
ZIPsul lato sinistro e i valori perCITYsul lato destro. Un bordo collega un codice postale sul lato sinistro del tracciato con una città sul lato destro se è presente una riga che contiene questi due valori. I bordi vengono annotati con il conteggio di tali righe. Ad esempio, sono presenti due righe con codice postale 02747-1242, una riga con città "NORTH DARTHMOUTH" e l'altra con città "DARTHMOUTH", come illustrato nel tracciato precedente e nel codice seguente:Verificare le osservazioni precedenti effettuate con il tracciato delle violazioni delle dipendenze eseguendo il codice seguente:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()Il tracciato mostra anche che tra le righe che hanno
CITYcome "DARTHMOUTH", nove righe hanno unZIPdi 02747-1262; una riga ha unZIPdi 02747-1242; e una riga ha unZIPdi 02747-2537. Conferma queste osservazioni con il codice seguente:providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()Esistono altri codici postali associati a "DARTMOUTH", ma questi codici postali non vengono visualizzati nel grafico delle violazioni delle dipendenze, perché non indicano problemi di qualità dei dati. Ad esempio, il codice postale "02747-4302" è associato in modo univoco a "DARTMOUTH" e non viene visualizzato nel grafico delle violazioni delle dipendenze. Verificare eseguendo il codice seguente:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Riepilogare i problemi di qualità dei dati rilevati con SemPy
Tornando al grafico delle violazioni delle dipendenze, è possibile notare che esistono diversi problemi di qualità dei dati interessanti presenti in questo modello semantico:
- Alcuni nomi di città sono tutti maiuscoli. Questo problema è facile da risolvere usando i metodi stringa.
- Alcuni nomi di città hanno qualificatori (o prefissi), ad esempio "North" e "East". Ad esempio, il codice postale "2128" esegue il mapping a "EAST BOSTON" una volta e a "BOSTON" una volta. Si verifica un problema simile tra "NORTH DARTHMOUTH" e "DARTHMOUTH". È possibile provare a eliminare questi qualificatori o mappare i codici postali alla città con l'occorrenza più comune.
- Ci sono errori di digitazioni in alcune città, ad esempio "PITTSFIELD" e "PITTSFILED" e "NEWBURGPORT vs. "NEWBURYPORT". Per "NEWBURGPORT" questo errore di digitatura potrebbe essere corretto utilizzando l'occorrenza più comune. Per "PITTSFIELD", la presenza di una sola occorrenza rende molto più difficile la disambiguazione automatica senza conoscenza esterna o l'uso di un modello linguistico.
- In alcuni casi, i prefissi come "West" sono abbreviati in una singola lettera "W". Questo problema potrebbe essere risolto con una semplice sostituzione, se tutte le occorrenze di "W" stessero per "West".
- Il codice postale "02130" è mappato a "BOSTON" una volta e "Giamaica Plain" una volta. Questo problema non è facile da risolvere, ma se sono presenti più dati, il mapping all'occorrenza più comune potrebbe essere una potenziale soluzione.
Pulire i dati
Risolvere i problemi di maiuscole e minuscole modificando tutte le maiuscole in maiuscole e minuscole:
providers['CITY'] = providers.CITY.str.title()Eseguire di nuovo il rilevamento delle violazioni per verificare che alcune delle ambiguità siano scomparse (il numero di violazioni è minore):
providers.list_dependency_violations('ZIP', 'CITY')A questo punto, è possibile perfezionare i dati più manualmente, ma una potenziale attività di pulizia dei dati consiste nell'eliminare righe che violano vincoli funzionali tra colonne nei dati, usando la funzione
drop_dependency_violationsdi SemPy.Per ogni valore della variabile determinante,
drop_dependency_violationsfunziona selezionando il valore più comune della variabile dipendente ed eliminando tutte le righe con altri valori. È consigliabile applicare questa operazione solo se si è certi che questa euristica statistica provocherebbe i risultati corretti per i dati. In caso contrario, è necessario scrivere codice personalizzato per gestire le violazioni rilevate in base alle esigenze.Eseguire la funzione
drop_dependency_violationsnelle colonneZIPeCITY:providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')Elencare eventuali violazioni delle dipendenze tra
ZIPeCITY:providers_clean.list_dependency_violations('ZIP', 'CITY')Il codice restituisce un elenco vuoto per indicare che non sono presenti altre violazioni del vincolo funzionale CITY -> ZIP.
Contenuto correlato
Vedere altre esercitazioni per il collegamento semantico/SemPy:
- Esercitazione: Analizzare le dipendenze funzionali in un modello semantico di esempio
- esercitazione : Estrarre e calcolare le misure di Power BI da un notebook di Jupyter
- Esercitazione: Individuare le relazioni in un modello semantico usando il collegamento semantico
- Esercitazione: Scoprire le relazioni nel dataset Synthea utilizzando il collegamento semantico
- Esercitazione: Convalidare i dati usando SemPy e Great Expectations (GX)