Esercitazione: analizzare le dipendenze funzionali in un modello semantico
In questa esercitazione ci si basa sul lavoro svolto in precedenza da un analista di Power BI e archiviato sotto forma di modelli semantici (set di dati di Power BI). Usando SemPy (anteprima) nell'esperienza di Synapse Data Science all'interno di Microsoft Fabric, si analizzano le dipendenze funzionali presenti nelle colonne di un DataFrame. Questa analisi consente di individuare problemi di qualità dei dati non intermedi per ottenere informazioni più accurate.
In questa esercitazione apprenderai a:
- Applicare le conoscenze del dominio per formulare ipotesi sulle dipendenze funzionali in un modello semantico.
- Familiarizzare con i componenti del collegamento semantico della libreria Python (SemPy) che supportano l'integrazione con Power BI e consentono di automatizzare l'analisi della qualità dei dati. Questi componenti includono:
- FabricDataFrame: una struttura simile a pandas migliorata con informazioni semantiche aggiuntive.
- Funzioni utili per il pull di modelli semantici da un'area di lavoro Fabric nel tuo notebook.
- Funzioni utili che automatizzano la valutazione delle ipotesi sulle dipendenze funzionali e che identificano le violazioni delle relazioni nei modelli semantici.
Prerequisiti
Ottenere una sottoscrizione di Microsoft Fabric. In alternativa, iscriversi per ottenere una versione di valutazione di Microsoft Fabric gratuita.
Accedere a Microsoft Fabric.
Usa il commutatore dell'esperienza in basso a sinistra della tua home page per passare a Fabric.

Selezionare Aree di lavoro nel riquadro di spostamento sinistro per trovare e selezionare l'area di lavoro. Questa area di lavoro diventa l'area di lavoro corrente.
Scaricare il modello semantico Customer Profitability Sample.pbix dal repository GitHub fabric-samples.
Nella tua area di lavoro, seleziona Importa>Report o Report impaginato>da questo computer per caricare il file Customer Profitability Sample.pbix nell'area di lavoro.
Seguire la procedura nel notebook
Il notebook powerbi_dependencies_tutorial.ipynb accompagna questa esercitazione.
Per aprire il notebook di accompagnamento per questa esercitazione, seguire le istruzioni riportate in Preparare il sistema per le esercitazioni di data science per importare il notebook nell'area di lavoro.
Se si preferisce copiare e incollare il codice da questa pagina, è possibile creare un nuovo notebook.
Assicurarsi di collegare un lakehouse al notebook prima di iniziare a eseguire il codice.
Configurare il notebook
In questa sezione viene configurato un ambiente notebook con i moduli e i dati necessari.
Installare
SemPyda PyPI usando la funzionalità di installazione in linea%pipall'interno del notebook:%pip install semantic-linkEseguire le importazioni necessarie di moduli che serviranno in un secondo momento:
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
Caricare e pre-elaborare i dati
Questa esercitazione usa un modello semantico di esempio standard Customer Profitability Sample.pbix. Per una descrizione del modello semantico, vedere Esempio di redditività dei clienti per Power BI.
Caricare i dati di Power BI in FabricDataFrames usando la funzione
read_tabledi SemPy:dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()Caricare la tabella
Statein un FabricDataFrame:state = fabric.read_table(dataset, "State") state.head()Mentre l'output di questo codice è simile a un DataFrame pandas, è stata effettivamente inizializzata una struttura di dati denominata
FabricDataFrameche supporta alcune operazioni utili oltre a pandas.Verificare il tipo di dati di
customer:type(customer)L'output conferma che
customerè di tiposempy.fabric._dataframe._fabric_dataframe.FabricDataFrame.`Unire i DataFrame
customerestate:customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
Identificare le dipendenze funzionali
Una dipendenza funzionale si manifesta come una relazione uno-a-molti tra i valori in due o più colonne all'interno di un DataFrame. Queste relazioni possono essere usate per rilevare automaticamente i problemi di qualità dei dati.
Eseguire la funzione
find_dependenciesdi SemPy nel DataFrame unito per identificare eventuali dipendenze funzionali esistenti tra i valori nelle colonne:dependencies = customer_state_df.find_dependencies() dependenciesVisualizzare le dipendenze identificate usando la funzione
plot_dependency_metadatadi SemPy:plot_dependency_metadata(dependencies)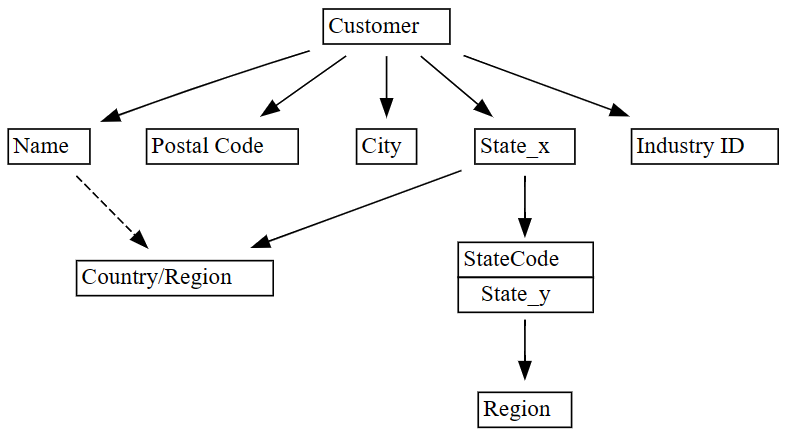
Come previsto, il grafico delle dipendenze funzionali mostra che la colonna
Customerdetermina alcune colonne comeCity,Postal CodeeName.Sorprendentemente, il grafico non mostra una dipendenza funzionale tra
CityePostal Code, probabilmente perché esistono molte violazioni nelle relazioni tra le colonne. È possibile usare la funzioneplot_dependency_violationsdi SemPy per visualizzare le violazioni delle dipendenze tra colonne specifiche.

Esplorare i dati per i problemi di qualità
Disegnare un grafico con la funzione di visualizzazione
plot_dependency_violationsdi SemPy.customer_state_df.plot_dependency_violations('Postal Code', 'City')
Il tracciato delle violazioni delle dipendenze mostra i valori per
Postal Codesul lato sinistro e i valori perCitysul lato destro. Una linea collega unPostal Codesul lato sinistro del tracciato a unaCitysul lato destro dello stesso, se esiste almeno una riga che contiene entrambi i valori. Le linee vengono annotate con il conteggio delle righe corrispondenti. Ad esempio, ci sono due righe con codice postale 20004, una con città "North Tower" e l'altra con città "Washington".Inoltre, il tracciato mostra alcune violazioni e molti valori vuoti.
Confermare il numero di valori vuoti per
Postal Code:customer_state_df['Postal Code'].isna().sum()50 righe hanno NA per il codice postale.
Eliminare righe con valori vuoti. Trovare quindi le dipendenze usando la funzione
find_dependencies. Si noti il parametro aggiuntivoverbose=1che offre un'occhiata ai lavori interni di SemPy:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)L'entropia condizionale per
Postal CodeeCityè 0,049. Questo valore indica che sono presenti violazioni delle dipendenze funzionali. Prima di correggere le violazioni, aumentare la soglia sull'entropia condizionale dal valore predefinito di0.01a0.05, solo per visualizzare le dipendenze. Le soglie inferiori comportano un minor numero di dipendenze (o una selettività superiore).Aumentare la soglia per l'entropia condizionale dal valore predefinito di
0.01a0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))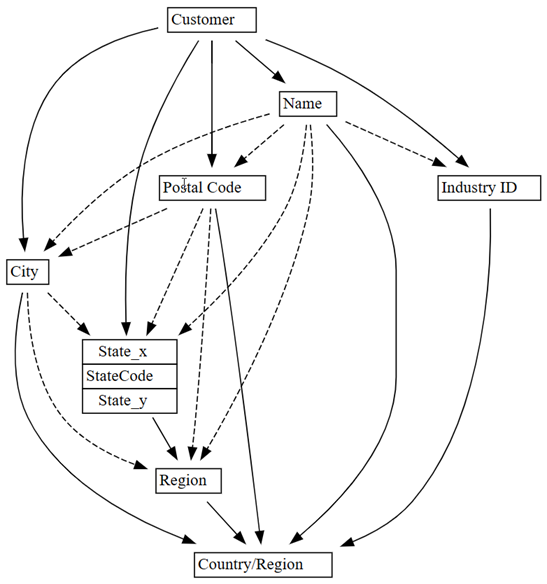
Se si applica la conoscenza del dominio di quale entità determina i valori di altre entità, questo grafico delle dipendenze sembra accurato.
Esplorare altri problemi di qualità dei dati rilevati. Ad esempio, una freccia tratteggiata unisce
CityeRegion, il che indica che la dipendenza è solo approssimativa. Questa relazione approssimativa potrebbe implicare che esiste una dipendenza funzionale parziale.customer_state_df.list_dependency_violations('City', 'Region')Esaminare in modo più approfondito ognuno dei casi in cui un valore nonempty
Regioncausa una violazione:customer_state_df[customer_state_df.City=='Downers Grove']Il risultato mostra la città di Downers Grove presente in Illinois e Nebraska. Tuttavia, Downer's Grove è una città dell'Illinois, non del Nebraska.
Dai un'occhiata alla città di Fremont:
customer_state_df[customer_state_df.City=='Fremont']C'è una città chiamata Fremont in California. Tuttavia, per il Texas, il motore di ricerca restituisce Premont, non Fremont.
È anche sospetto vedere le violazioni della dipendenza tra
NameeCountry/Region, come indicato dalla linea punteggiata nel grafico originale delle violazioni delle dipendenze (prima di eliminare le righe con valori vuoti).customer_state_df.list_dependency_violations('Name', 'Country/Region')Sembra che un cliente, SDI Design sia presente in due aree, Stati Uniti e Canada. Questa occorrenza può non essere una violazione semantica, ma può essere semplicemente un caso non comune. Comunque, vale la pena dare un'occhiata:
Esaminare più in dettaglio al cliente SDI Design:
customer_state_df[customer_state_df.Name=='SDI Design']Un'ulteriore ispezione mostra che sono in realtà due clienti diversi (da settori diversi) con lo stesso nome.

L'analisi esplorativa dei dati è un processo interessante e lo è anche la pulizia dei dati. C'è sempre qualcosa che i dati nascondono, a seconda di come si esaminano, cosa si vuole chiedere e così via. Il collegamento semantico offre nuovi strumenti che è possibile usare per ottenere di più con i dati.
Contenuto correlato
Vedere altre esercitazioni per il collegamento semantico/SemPy:
- Esercitazione: Pulire i dati con dipendenze funzionali
- Esercitazione: Estrarre e calcolare le misure di Power BI da un Jupyter Notebook
- Esercitazione: Individuare le relazioni in un modello semantico usando il collegamento semantico
- Esercitazione: Individuare le relazioni nel set di dati Synthea usando il collegamento semantico
- Esercitazione: Validare i dati utilizzando SemPy e Great Expectations (GX)