Eseguire la migrazione dei metadati metastore Hive da Azure Synapse Analytics a Fabric
Il passaggio iniziale della migrazione del metastore Hive (HMS) comporta la determinazione dei database, delle tabelle e delle partizioni da trasferire. Non è necessario eseguire la migrazione di tutto; è possibile selezionare database specifici. Quando si identificano i database per la migrazione, assicurarsi di verificare se esistono tabelle Spark gestite o esterne.
Per considerazioni su HMS, vedere le differenze tra Azure Synapse Spark e Fabric.
Nota
In alternativa, se ADLS Gen2 contiene tabelle Delta, è possibile creare un collegamento OneLake a una tabella Delta in ADLS Gen2.
Prerequisiti
- Se non esiste ancora, creare un'area di lavoro di Fabric nel tenant.
- Se non esiste ancora, creare un lakehouse Fabric nell'area di lavoro.
Opzione 1: esportare e importare HMS nel metastore lakehouse
Seguire questi passaggi chiave per la migrazione:
- Passaggio 1: esportare i metadati da HMS di origine
- Passaggio 2: importare metadati in un lakehouse Fabric
- Passaggi dopo la migrazione: convalidare il contenuto
Nota
Gli script copiano solo oggetti del catalogo Spark nel lakehouse Fabric. Si supponga che i dati siano già stati copiati, ad esempio, dalla posizione del warehouse ad ADLS Gen2, o che siano disponibili per tabelle gestite ed esterne, ad esempio, tramite collegamenti, nel lakehouse Fabric.
Passaggio 1: esportare i metadati da HMS di origine
Il passaggio 1 è incentrato sull'esportazione dei metadati da HMS di origine nella sezione File del lakehouse Fabric. Questo processo avviene come indicato di seguito:
1.1) Importare il notebook di esportazione metadati HMS nell'area di lavoro di Azure Synapse. Questo notebook esegue query ed esporta metadati HMS di database, tabelle e partizioni in una directory intermedia in OneLake (funzioni non ancora incluse). L'API del catalogo interno di Spark viene usata in questo script per leggere gli oggetti del catalogo.
1.2) Configurare i parametri nel primo comando per esportare le informazioni sui metadati in un archivio intermedio (OneLake). Il frammento di codice seguente viene usato per configurare i parametri di origine e destinazione. Assicurarsi di sostituirli con i propri valori.
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) Eseguire tutti i comandi del notebook per esportare oggetti del catalogo in OneLake. Una volta completate le celle, viene creata questa struttura di cartelle nella directory di output intermedia.
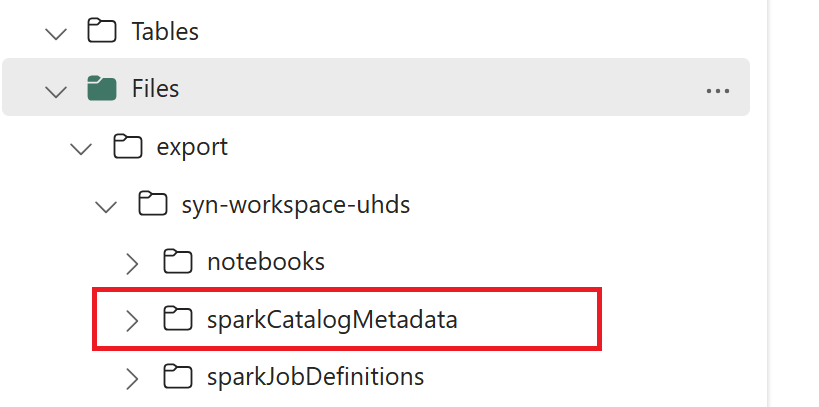
Passaggio 2: importare metadati in un lakehouse Fabric
Il passaggio 2 avviene quando i metadati effettivi vengono importati dall’archiviazione intermedia nel lakehouse di Fabric. L'output di questo passaggio implica la migrazione di tutti i metadati HMS (database, tabelle e partizioni). Questo processo avviene come indicato di seguito:
2.1) Creare un collegamento all'interno della sezione "File" del lakehouse. Questo collegamento deve puntare alla directory del warehouse Spark di origine e viene usato in un secondo momento per sostituire le tabelle gestite di Spark. Vedere esempi di collegamento che puntano alla directory del warehouse Spark:
- Percorso di collegamento alla directory del warehouse di Azure Synapse Spark:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Percorso del collegamento alla directory warehouse di Azure Databricks:
dbfs:/mnt/<warehouse_dir> - Percorso del collegamento alla directory warehouse di Spark HDInsight:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Percorso di collegamento alla directory del warehouse di Azure Synapse Spark:
2.2) Importare il notebook di importazione dei metadati HMS nell'area di lavoro di Fabric. Importare questo notebook per importare oggetti di database, tabelle e partizioni da un’archiviazione intermedia. L'API del catalogo interno di Spark viene usata in questo script per creare oggetti del catalogo in Fabric.
2.3) Configurare i parametri nel primo comando. In Apache Spark, quando si crea una tabella gestita, i dati per tale tabella vengono archiviati in una posizione gestita da Spark, generalmente all'interno della directory warehouse di Spark. La posizione esatta è determinata da Spark. Ciò contrasta con le tabelle esterne in cui si specifica la posizione e si gestiscono i dati sottostanti. Quando si esegue la migrazione dei metadati di una tabella gestita (senza spostare i dati effettivi), i metadati contengono ancora le informazioni sulla posizione originale che puntano alla vecchia directory warehouse di Spark. Di conseguenza, per le tabelle gestite, viene usato
WarehouseMappingsper eseguire la sostituzione usando il collegamento creato nel passaggio 2.1. Tutte le tabelle gestite dall’origine vengono convertite come tabelle esterne usando questo script.LakehouseIdfa riferimento al lakehouse creato nel passaggio 2.1 contenente i collegamenti.// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) Eseguire tutti i comandi del notebook per importare oggetti del catalogo dal percorso intermedio.
Nota
Quando si importano più database, è possibile: 1) creare un lakehouse per ogni database (l'approccio usato qui) o 2) spostare tutte le tabelle da database diversi in un singolo lakehouse. In quest’ultimo caso, tutte le tabelle di cui è stata eseguita la migrazione potrebbero essere <lakehouse>.<db_name>_<table_name> e sarà necessario modificare adeguatamente il notebook di importazione.
Passaggio 3: convalidare il contenuto
Il passaggio 3 avviene quando ci si assicura che la migrazione dei metadati sia stata eseguita correttamente. Vedere diversi esempi.
È possibile visualizzare i database importati eseguendo:
%%sql
SHOW DATABASES
È possibile controllare tutte le tabelle in un lakehouse (database) eseguendo:
%%sql
SHOW TABLES IN <lakehouse_name>
È possibile visualizzare i dettagli di una tabella particolare eseguendo:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
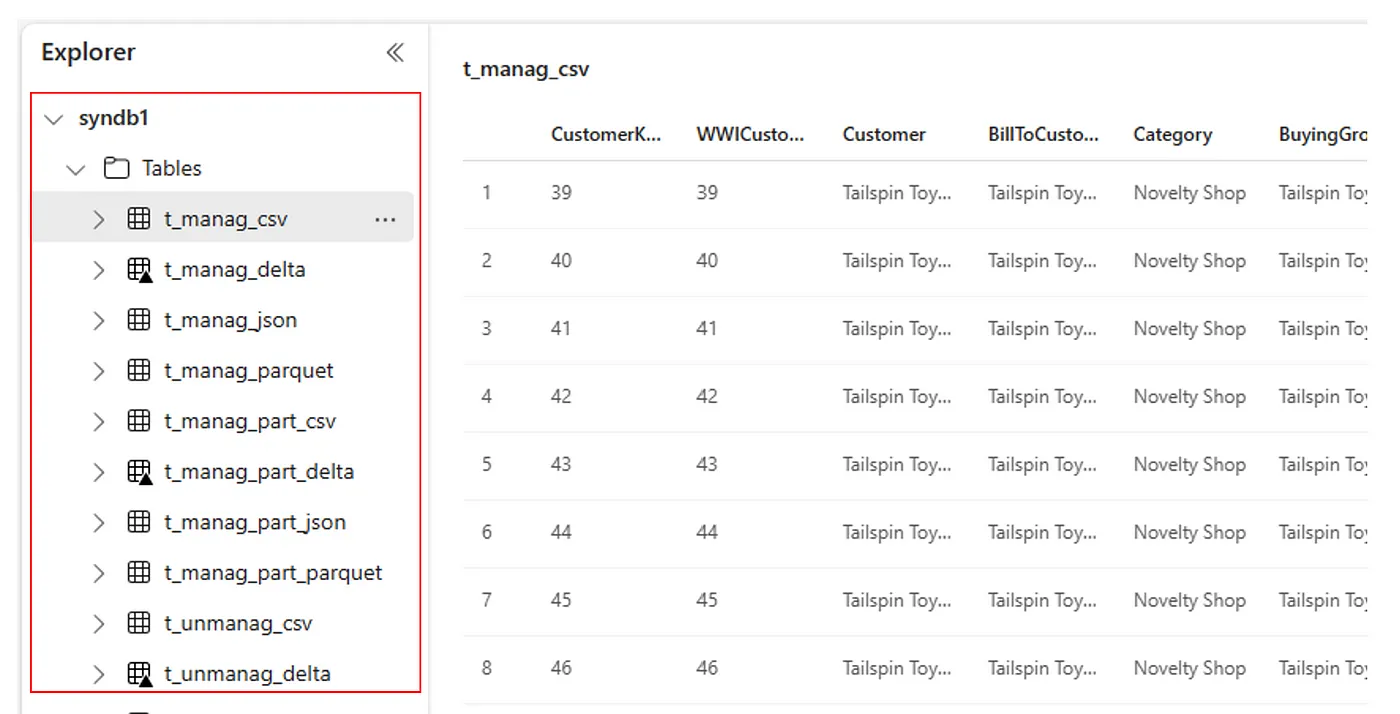
In alternativa, tutte le tabelle importate sono visibili all'interno della sezione Tabelle dell'interfaccia utente di Esplora lakehouse per ogni lakehouse.
Altre considerazioni
- Scalabilità: la soluzione seguente usa l'API del catalogo Spark interna per eseguire l'importazione/esportazione, ma non si connette direttamente a HMS per ottenere oggetti del catalogo, quindi la soluzione non è riuscita a ridimensionare correttamente se il catalogo è di grandi dimensioni. È necessario modificare la logica di esportazione usando il database HMS.
- Accuratezza dei dati: non esiste alcuna garanzia di isolamento, per cui se il motore di calcolo di Spark sta eseguendo modifiche simultanee al metastore mentre il notebook di migrazione è in esecuzione, nel lakehouse Fabric potrebbero essere introdotti dati incoerenti.
Contenuto correlato
- Confronto tra Fabric e Azure Synapse Spark
- Altre informazioni sulle opzioni di migrazione per pool di Spark, configurazioni, librerie, notebook e definizione processo Spark