Eseguire la migrazione della definizione processo Spark da Azure Synapse a Fabric
Per spostare definizioni processo Spark (SJD) da Azure Synapse a Fabric, sono disponibili due opzioni diverse:
- Opzione 1: creare manualmente la definizione processo Spark in Fabric.
- Opzione 2: è possibile usare uno script per esportare definizioni processo Spark da Azure Synapse e importarle in Fabric usando l'API.
Per considerazioni sulla definizione processo Spark, vedere le differenze tra Azure Synapse Spark e Fabric.
Prerequisiti
Se non esiste ancora, creare un'area di lavoro di Fabric nel tenant.
Opzione 1: Creare manualmente la definizione processo Spark
Per esportare una definizione processo Spark da Azure Synapse:
- Aprire Synapse Studio: accedere ad Azure. Passare all'area di lavoro di Azure Synapse e aprire Synapse Studio.
- Individuare il processo Spark Python/Scala/R: trovare e identificare la definizione processo Spark Python/Scala/R di cui eseguire la migrazione.
-
Esportare la configurazione della definizione processo:
- In Synapse Studio aprire la definizione processo Spark.
- Esportare o annotare le impostazioni di configurazione, inclusi percorso del file di script, dipendenze, parametri e altri dettagli pertinenti.
Per creare una nuova definizione processo Spark (SJD) in base alle informazioni SJD esportate in Fabric:
- Accedere all'area di lavoro infrastruttura: accedere a Fabric e accedere all'area di lavoro.
-
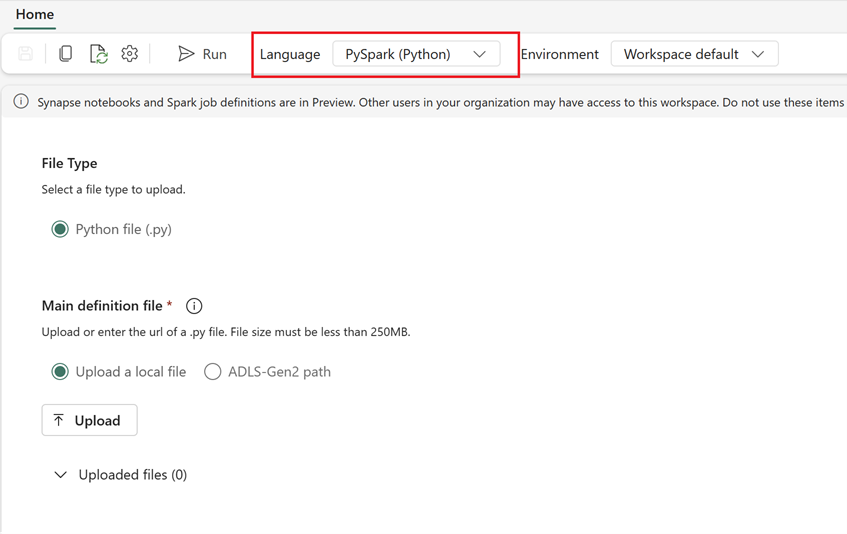
Creare una nuova definizione processo Spark in Fabric:
- In Fabric, passare alla home page Ingegneria dei dati.
- Selezionare Definizione processo Spark.
- Configurare il processo usando le informazioni esportate da Synapse, inclusi percorso script, dipendenze, parametri e impostazioni del cluster.
- Adattare e testare: apportare gli adattamenti necessari allo script o alla configurazione in base all'ambiente Fabric. Testare il processo in Fabric per assicurarsi che venga eseguito correttamente.
Dopo aver creato la definizione processo Spark, convalidare le dipendenze:
- Assicurarsi di usare la stessa versione di Spark.
- Convalidare l'esistenza del file di definizione principale.
- Convalidare l'esistenza dei file, delle dipendenze e delle risorse a cui si fa riferimento.
- Servizi collegati, connessioni all'origine dati e punti di montaggio.
Altre informazioni su come creare una definizione processo Apache Spark in Fabric.
Opzione 2: usare l'API Fabric
Seguire questi passaggi chiave per la migrazione:
- Prerequisiti.
- Passaggio 1: esportare la definizione processo Spark da Azure Synapse a OneLake (.json).
- Passaggio 2: importare la definizione processo Spark automaticamente in Fabric usando l'API Fabric.
Prerequisiti
I prerequisiti includono azioni che è necessario considerare prima di avviare la migrazione della definizione processo Spark in Fabric.
- Un’area di lavoro Fabric.
- Se non esiste ancora, creare un lakehouse Fabric nell'area di lavoro.
Passaggio 1: esportare la definizione processo Spark dall’area di lavoro di Azure Synapse
L'obiettivo del passaggio 1 è l'esportazione della definizione processo Spark dall'area di lavoro di Azure Synapse in OneLake in formato JSON. Questo processo avviene come indicato di seguito:
- 1.1) Importare il notebook di migrazione SJD nell'area lavoro di Fabric. Questo notebook esporta tutte le definizioni processo Spark da una determinata area di lavoro di Azure Synapse in una directory intermedia in OneLake. L'API Synapse viene usata per esportare SJD.
- 1.2) Configurare i parametri nel primo comando per esportare la definizione processo Spark in un’archiviazione intermedia (OneLake). Ciò esporta solo il file di metadati JSON. Il frammento di codice seguente viene usato per configurare i parametri di origine e destinazione. Assicurarsi di sostituirli con i propri valori.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
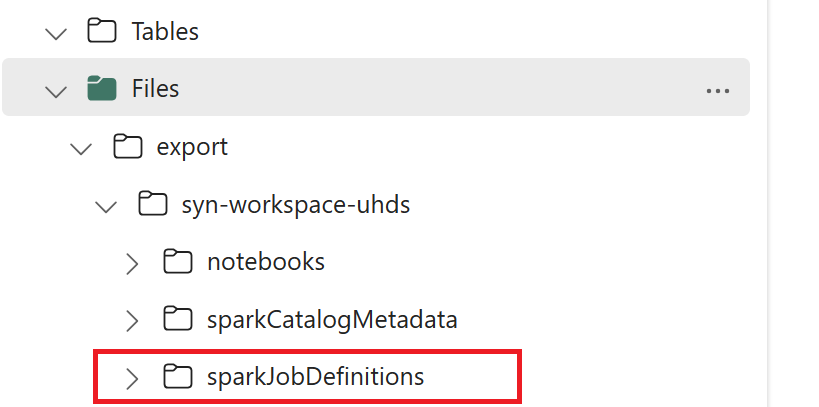
- 1.3) Eseguire le prime due celle del notebook da esportare/importare per esportare i metadati della definizione processo Spark in OneLake. Una volta completate le celle, viene creata questa struttura di cartelle nella directory di output intermedia.
Passaggio 2: importare la definizione processo Spark in Fabric
Il passaggio 2 avviene quando le definizioni processo vengono importate dall'archiviazione intermedia nell'area di lavoro di Fabric. Questo processo avviene come indicato di seguito:
- 2.1) Convalidare le configurazioni nel passaggio 1.2 per assicurarsi che siano indicati il prefisso e l’area di lavoro corretti per importare le definizioni processo.
- 2.2) Eseguire la terza cella del notebook da esportare/importare per importare tutte le definizioni processo Spark dalla posizione intermedia.
Nota
L'opzione di esportazione restituisce un file di metadati JSON. Assicurarsi che i file eseguibili della definizione processo Spark, i file di riferimento e gli argomenti siano accessibili da Fabric.