Eseguire la migrazione di pool di Spark da Azure Synapse Analytics a Fabric
Mentre Azure Synapse fornisce pool di Spark, Fabric offre pool di avvio e pool personalizzati. Il pool di avvio può essere una scelta ottimale se esiste un singolo pool senza configurazioni o librerie personalizzate in Azure Synapse, e se le dimensioni medie del nodo soddisfano i requisiti. Tuttavia, se si cerca una maggiore flessibilità con le configurazioni dei pool di Spark, è consigliabile usare pool personalizzati. Sono disponibili due opzioni:
- Opzione 1: spostare il pool di Spark nel pool predefinito di un'area di lavoro.
- Opzione 2: spostare il pool di Spark in un ambiente personalizzato in Fabric.
Se esistono più pool di Spark e si prevede di spostarli nella stessa area di lavoro di Fabric, è consigliabile usare l'opzione 2, creando più pool e ambienti personalizzati.
Per considerazioni sul pool di Spark, vedere le differenze tra Azure Synapse Spark e Fabric.
Prerequisiti
Se non esiste ancora, creare un'area di lavoro di Fabric nel tenant.
Opzione 1: dal pool di Spark al pool predefinito dell'area di lavoro
È possibile creare un pool di Spark personalizzato dall'area di lavoro di Fabrice usarlo come pool predefinito nell'area di lavoro. Il pool predefinito viene usato da tutti i notebook e dalle definizioni processo Spark nella stessa area di lavoro.
Per passare da un pool di Spark esistente da Azure Synapse a un pool predefinito dell'area di lavoro:
- Accedere all'area di lavoro di Azure Synapse: accedere ad Azure. Spostarsi nell'area di lavoro di Azure Synapse, passare a Pool di analisi e selezionare Pool di Apache Spark.
- Individuare il pool di Spark: da Pool di Apache Spark, individuare il pool di Spark da spostare in Fabric e controllare le Proprietà del pool.
- Ottenere le proprietà: ottenere le proprietà del pool di Spark, ad esempio la versione di Apache Spark, la famiglia di dimensioni dei nodi, le dimensioni del nodo o la scalabilità automatica. Per visualizzare eventuali differenze, vedere Considerazioni sui pool di Spark.
-
Creare un pool di Spark personalizzato in Fabric:
- Passare all'area di lavoro di Fabric e selezionare Impostazioni area di lavoro.
- Passare a Ingegneria dei dati / Data science e selezionare Impostazioni di Spark.
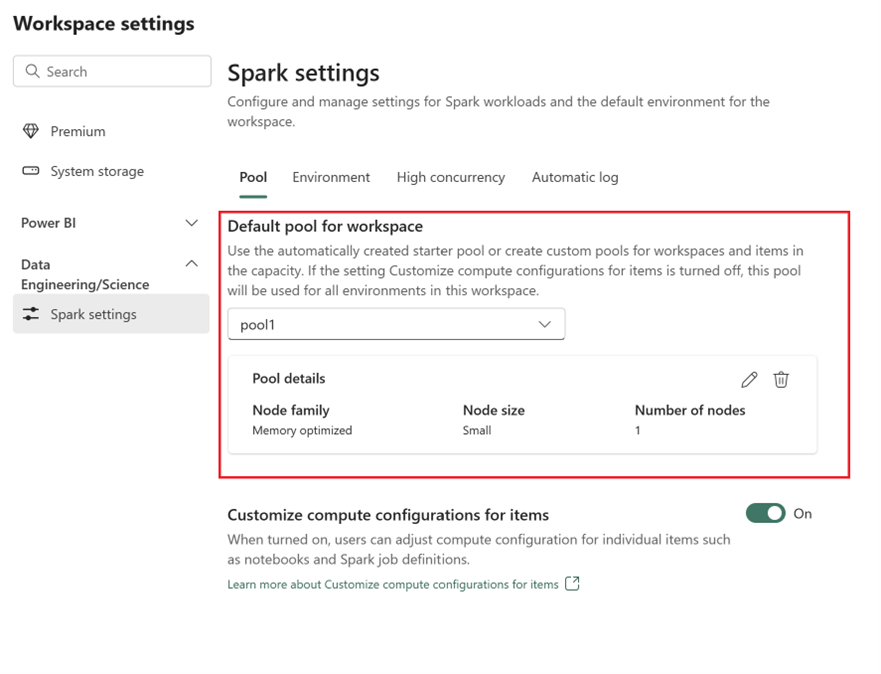
- Nella scheda Pool e nella sezione Pool predefinito per l'area di lavoro, espandere il menu a discesa e selezionare Crea nuovo pool.
- Creare un pool personalizzato con i valori di destinazione corrispondenti. Immettere il nome, la famiglia di nodi, le dimensioni del nodo, la scalabilità automatica e le opzioni di allocazione dell'executor dinamico.
-
Selezionare una versione del runtime:
- Passare alla scheda Ambiente e selezionare la Versione del runtime richiesta. Vedere i runtime disponibili qui.
- Disabilitare l'opzione Imposta ambiente predefinito.
Nota
In questa opzione, le librerie o le configurazioni a livello di pool non sono supportate. Tuttavia, è possibile modificare la configurazione di calcolo per singoli elementi, ad esempio notebook e definizioni processo Spark, e aggiungere librerie inline. Se è necessario aggiungere librerie e configurazioni personalizzate a un ambiente, considerare un ambiente personalizzato.
Opzione 2: dal pool di Spark a un ambiente personalizzato
Con ambienti personalizzati è possibile configurare proprietà e librerie di Spark personalizzate. Per creare un ambiente personalizzato:
- Accedere all'area di lavoro di Azure Synapse: accedere ad Azure. Spostarsi nell'area di lavoro di Azure Synapse, passare a Pool di analisi e selezionare Pool di Apache Spark.
- Individuare il pool di Spark: da Pool di Apache Spark, individuare il pool di Spark da spostare in Fabric e controllare le Proprietà del pool.
- Ottenere le proprietà: ottenere le proprietà del pool di Spark, ad esempio la versione di Apache Spark, la famiglia di dimensioni dei nodi, le dimensioni del nodo o la scalabilità automatica. Per visualizzare eventuali differenze, vedere Considerazioni sui pool di Spark.
-
Creare un pool di Spark personalizato:
- Passare all'area di lavoro di Fabric e selezionare Impostazioni area di lavoro.
- Passare a Ingegneria dei dati / Data science e selezionare Impostazioni di Spark.
- Nella scheda Pool e nella sezione Pool predefinito per l'area di lavoro, espandere il menu a discesa e selezionare Crea nuovo pool.
- Creare un pool personalizzato con i valori di destinazione corrispondenti. Immettere il nome, la famiglia di nodi, le dimensioni del nodo, la scalabilità automatica e le opzioni di allocazione dell'executor dinamico.
- Creare un elemento ambiente, se non ne è disponibile uno.
-
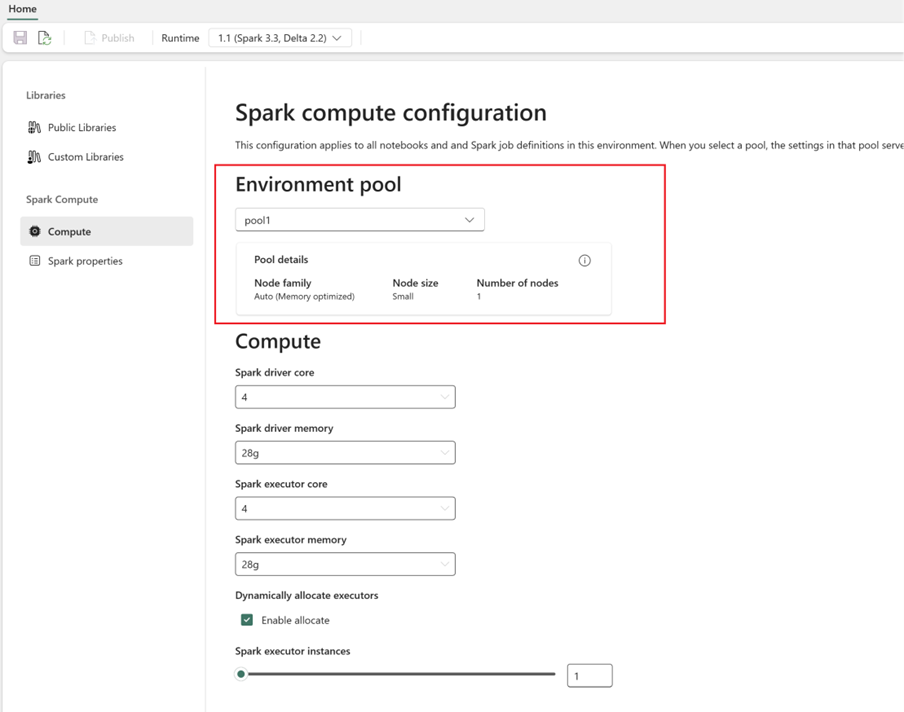
Configurare l'ambiente di calcolo Spark:
- All'interno dell'ambiente, passare ad Ambiente di calcolo Spark>Ambiente di calcolo.
- Selezionare il pool appena creato per il nuovo ambiente.
- È possibile configurare core executor, driver e memoria.
- Selezionare una versione del runtime per l'ambiente. Vedere i runtime disponibili qui.
- Fare clic su Salva e scegliere Pubblica per le modifiche.
Altre informazioni sulla creazione e sull’uso di un ambiente.