Domande frequenti sulle previsioni di AutoML
SI APPLICA A:  Python SDK azure-ai-ml v2 (corrente)
Python SDK azure-ai-ml v2 (corrente)
Questo articolo risponde alle domande comuni sulle previsioni nel machine learning automatizzato (AutoML). Per informazioni generali sulla metodologia di previsione in AutoML, vedere l'articolo Panoramica dei metodi di previsione in AutoML.
Come si inizia a creare modelli di previsione in AutoML?
Per iniziare, leggere l'articolo Configurare AutoML per eseguire il training di un modello di previsione della serie temporale. È anche possibile trovare esempi pratici in diversi Jupyter Notebook:
- Esempio di condivisione di bike
- Previsione tramite deep learning
- Soluzione Molti modelli
- Previsioni di ricette
- Scenari di previsione avanzati
Perché AutoML è lento con i dati?
Ci impegniamo costantemente a rendere AutoML più veloce e scalabile. Per funzionare come piattaforma di previsione generale, AutoML esegue ampie convalide dei dati e definizione delle funzionalità complesse ed esegue ricerche in uno spazio di modelli di grandi dimensioni. Tale complessità può richiedere molto tempo, a seconda dei dati e della configurazione.
Una ragione comune del tempo di esecuzione lento è il training di AutoML con impostazioni predefinite sui dati che contengono numerose serie temporali. Il costo di molti metodi di previsione viene ridimensionato con il numero di serie. Ad esempio, metodi come Smoothing esponenziale e Prophet eseguono il training di un modello per ogni serie temporale nei dati di training.
La funzionalità Molti modelli di AutoML viene ridimensionata in questi scenari distribuendo i processi di training in un cluster di elaborazione. È stata applicata correttamente ai dati con milioni di serie temporali. Per altre informazioni, vedere la sezione dell'articolo su Molti modelli. È anche possibile leggere informazioni sull'esito positivo di Molti modelli in un set di dati di concorrenza di alto profilo.
Come è possibile velocizzare AutoML?
Vedere la risposta a Perché AutoML è lento con i dati? per comprendere il motivo per cui AutoML potrebbe essere lento nelle circostanze in questione.
Prendere in considerazione le seguenti modifiche di configurazione che potrebbero velocizzare il processo:
- Bloccare modelli di serie temporali come ARIMA e Prophet.
- Disattivare le funzionalità di look-back, ad esempio ritardi e finestre in sequenza.
- Ridurre:
- Il numero di versioni di valutazione/iterazioni.
- Il timeout delle versioni di valutazione/iterazione.
- Il timeout degli esperimenti.
- Il numero di riduzioni di convalida incrociata.
- Assicurarsi che la terminazione anticipata sia abilitata.
Quale configurazione di modellazione è consigliabile usare?
La previsione autoML supporta quattro configurazioni di base:
| Impostazione | Scenario | Vantaggi | Svantaggi |
|---|---|---|---|
| AutoML predefinito | Consigliato se il set di dati ha un numero ridotto di serie temporali con un comportamento cronologico approssimativamente simile. | - Semplice da configurare da codice/SDK o da studio di Azure Machine Learning. - AutoML è in grado di apprendere serie temporali differenti, in quanto i modelli di regressione raggruppano tutte le serie nel training. Per altre informazioni, vedere Raggruppamento di modelli. |
- I modelli di regressione potrebbero essere meno accurati se le serie temporali nei dati di training hanno un comportamento divergente. - I modelli di serie temporali potrebbero richiedere molto tempo per eseguire il training, laddove i dati di training hanno un numero elevato di serie. Per altre informazioni, vedere la risposta a Perché AutoML è lento con i dati?. |
| AutoML con deep learning | Consigliato per i set di dati con più di 1.000 osservazioni e, potenzialmente, numerose serie temporali che presentano modelli complessi. Quando è abilitato, AutoML eseguirà lo sweep sui modelli di rete neurale convoluzionale (TCN) temporali durante il training. Per altre informazioni, vedere Abilitare il deep learning. | - Semplice da configurare da codice/SDK o da studio di Azure Machine Learning. - Opportunità di apprendimento incrociato, perché la TCN raggruppa tutte le serie. - Accuratezza potenzialmente superiore a causa della grande capacità dei modelli di rete neurale profonda (DNN). Per altre informazioni, vedere Modelli di previsione in AutoML. |
- Il training può richiedere molto più tempo a causa della complessità dei modelli DNN. - Le serie con piccole quantità di cronologia non trarranno probabilmente vantaggio da questi modelli. |
| Molti modelli | Consigliato se è necessario eseguire il training e gestire un numero elevato di modelli di previsione in modo scalabile. Per altre informazioni, vedere la sezione dell'articolo su Molti modelli. | - Scalabile. - Accuratezza potenzialmente superiore quando le serie temporali hanno un comportamento divergente l'uno dall'altro. |
- Nessun apprendimento tra le serie temporali. - Non è possibile configurare o eseguire processi Molti modelli da studio di Azure Machine Learning Studio. È attualmente disponibile solo l'esperienza di codice/SDK. |
| Serie temporale gerarchica (HTS) | Consigliata se la serie nei dati ha una struttura annidata e gerarchica ed è necessario eseguire il training o effettuare previsioni a livelli aggregati della gerarchia. Per altre informazioni, vedere la sezione dell'articolo relativa alla previsione gerarchica delle serie temporali. | - Il training a livelli aggregati può ridurre il rumore nella serie temporale del nodo foglia e determinare potenzialmente modelli di accuratezza più elevata. - È possibile recuperare le previsioni per qualsiasi livello della gerarchia aggregando o disaggregando le previsioni dal livello di training. |
- È necessario fornire il livello di aggregazione per il training. AutoML non dispone attualmente di un algoritmo per trovare un livello ottimale. |
Nota
È consigliabile usare nodi di calcolo con GPU quando il deep learning è abilitato per sfruttare al meglio la capacità DNN elevata. Il tempo di training può essere molto più veloce rispetto ai nodi contenenti esclusivamente CPU. Per altre informazioni, vedere l'articolo Dimensioni delle macchine virtuali ottimizzate per la GPU.
Nota
HTS è progettato per le attività in cui è necessario eseguire il training o la previsione a livelli aggregati nella gerarchia. Per i dati gerarchici che richiedono solo il training e la previsione dei nodi foglia, usare invece Molti modelli.
Come è possibile prevenire l'overfitting e la perdita di dati?
AutoML usa procedure consigliate di machine learning, come la selezione di modelli con convalida incrociata, che riducono numerosi problemi di overfitting. Esistono tuttavia altre possibili cause di overfitting:
I dati di input contengono colonne di funzionalità che derivano dalla destinazione con una formula semplice. Ad esempio, una funzionalità che è un multiplo esatto della destinazione può comportare un punteggio di training quasi perfetto. Tuttavia, il modello non verrà probabilmente generalizzato per i dati fuori ambito. È consigliabile esplorare i dati prima del training del modello e eliminare le colonne che "perdono" le informazioni di destinazione.
I dati di training usano funzionalità che non sono note in futuro, fino all'orizzonte di previsione. I modelli di regressione di AutoML presuppongono attualmente che tutte le funzionalità siano note all'orizzonte di previsione. È consigliabile esplorare i dati prima del training e rimuovere tutte le colonne di funzionalità note solo storicamente.
Esistono differenze strutturali significative (modifiche al regime) tra le parti di training, convalida o test dei dati. Si consideri, ad esempio, l'effetto della pandemia di COVID-19 sulla domanda di quasi tutti i prodotti durante il 2020 e il 2021. Si tratta di un esempio classico di un cambiamento di regime. L'overfitting dovuto al cambiamento di regime è il problema più complesso da risolvere perché dipende da uno scenario altamente dipendente e può necessitare del deep learning per l'identificazione.
Come prima linea di difesa, provare a riservare dal 10 al 20% della cronologia totale per i dati di convalida o di convalida incrociata. Non è sempre possibile riservare questa quantità di dati di convalida se la cronologia del training è breve; tuttavia, si tratta di una procedura consigliata. Per altre informazioni, vedere Training e convalida dei dati.
Cosa significa se il lavoro di training ottiene punteggi di convalida perfetti?
È possibile visualizzare punteggi perfetti quando si visualizzano le metriche di convalida da un processo di training. Un punteggio perfetto indica che le previsioni e i valori effettivi nel set di convalida sono uguali o quasi uguali. Ad esempio, si ha una radice dell'errore quadratico medio pari a 0,0 o un punteggio R2 pari a 1,0.
Un punteggio di convalida perfetto indica in genere che il modello è soggetto a overfitting elevato, probabilmente a causa della perdita di dati. L'azione migliore consiste nell'esaminare i dati per individuare le perdite e eliminare le colonne che causano le suddette.
Cosa accade se i dati delle serie temporali non hanno osservazioni dalla spaziatura regolare?
I modelli di previsione di AutoML richiedono che i dati di training dispongano di osservazioni dalla spaziatura regolare rispetto al calendario. Tale requisito include casi come osservazioni mensili o annuali in cui il numero di giorni tra le osservazioni può variare. I dati dipendenti dal tempo potrebbero non soddisfare questo requisito in due casi:
I dati hanno una frequenza ben definita, ma le osservazioni mancanti creano lacune nella serie. In questo caso, AutoML tenterà di rilevare la frequenza, compilare nuove osservazioni per le lacune e imputare valori di destinazione e funzionalità mancanti. Facoltativamente, l'utente può configurare i metodi di imputazione tramite le impostazioni dell'SDK o l'interfaccia utente Web. Per altre informazioni, vedere Definizione delle funzionalità personalizzate.
I dati non hanno una frequenza ben definita. Ovvero, la durata tra le osservazioni non ha un criterio riconoscibile. Un esempio è rappresentato dai dati transazionali, come quello di un sistema point-of-sales. In questo caso, è possibile configurare AutoML in modo da aggregare i dati a una frequenza scelta. È possibile scegliere una frequenza regolare più adatta ai dati e agli obiettivi di modellazione. Per altre informazioni, vedere Aggregazione dei dati.
Come si sceglie la metrica primaria?
La metrica primaria è importante perché il suo valore sui dati di convalida determina il modello migliore durante lo sweep e la selezione. La radice dell'errore quadratico medio normalizzato (NRMSE) e l'errore assoluto medio normalizzato (NMAE) sono in genere le scelte migliori per la metrica primaria nelle attività di previsione.
Per scegliere tra di essi, si noti che NRMSE penalizza gli outlier nei dati di training più di NMAE perché usa il quadrato dell'errore. NMAE potrebbe essere una scelta migliore se si desidera che il modello sia meno sensibile agli outlier. Per altre informazioni, vedere Metriche di regressione e previsione.
Nota
Non è consigliabile usare il punteggio R2 o R2come metrica primaria per la previsione.
Nota
AutoML non supporta funzioni personalizzate o fornite dall'utente per la metrica primaria. È necessario scegliere una delle metriche primarie predefinite supportate da AutoML.
Come è possibile migliorare l'accuratezza del modello?
- Assicurarsi di configurare AutoML nel modo migliore per i dati. Per altre informazioni, vedere la risposta alla domanda Quale configurazione di modellazione è consigliabile usare?.
- Vedere il notebook delle ricette di previsione per le guide dettagliate su come compilare e migliorare i modelli di previsione.
- Valutare il modello usando test back in diversi cicli di previsione. Questa procedura fornisce una stima più affidabile dell'errore di previsione e fornisce una baseline per la misurazione dei miglioramenti. Per un esempio, vedere il notebook di back-testing.
- Se i dati sono rumorosi, è consigliabile aggregarli a una frequenza più grossolana per aumentare il rapporto segnale-rumore. Per altre informazioni, vedere Aggregazione di dati di frequenza e destinazione.
- Aggiungere nuove funzionalità che consentono di stimare la destinazione. Le competenze in materia possono risultare molto utili quando si selezionano i dati di training.
- Confrontare i valori delle metriche di convalida e test e determinare se il modello selezionato esegue l'undefitting o overfitting dei dati. Tali informazioni possono essere utili per una configurazione di training migliore. Ad esempio, è possibile determinare che è necessario usare più riduzioni di convalida incrociata in risposta all'overfitting.
AutoML selezionerà sempre lo stesso modello migliore dagli stessi dati di training e dalla stessa configurazione?
Il processo di ricerca del modello di AutoML non è deterministico, per cui non sempre seleziona il medesimo modello dagli stessi dati e dalla stessa configurazione.
Come è possibile correggere un errore di memoria insufficiente?
Esistono due tipi di errori di memoria:
- Memoria insufficiente della RAM
- Memoria insufficiente del disco
Prima di tutto, assicurarsi di configurare AutoML nel modo migliore per i dati. Per altre informazioni, vedere la risposta alla domanda Quale configurazione di modellazione è consigliabile usare?.
Per le impostazioni predefinite di AutoML, è possibile correggere gli errori di memoria insufficiente della RAM usando nodi di calcolo con più RAM. Una regola generale è che la quantità di RAM libera deve essere almeno 10 volte superiore alla dimensione dei dati non elaborati per eseguire AutoML con le impostazioni predefinite.
È possibile risolvere gli errori di memoria insufficiente del disco eliminando il cluster di elaborazione e creando uno nuovo.
Quali scenari di previsione avanzati supporta AutoML?
AutoML supporta i seguenti scenari di previsione avanzata:
- Previsioni di quantili
- Valutazione affidabile dei modelli tramite previsioni in sequenza
- Previsioni oltre l'orizzonte di previsione
- Previsioni quando si verifica un divario nel tempo tra il training e i periodi di previsione
Per esempi e dettagli, vedere il notebook per scenari di previsione avanzata.
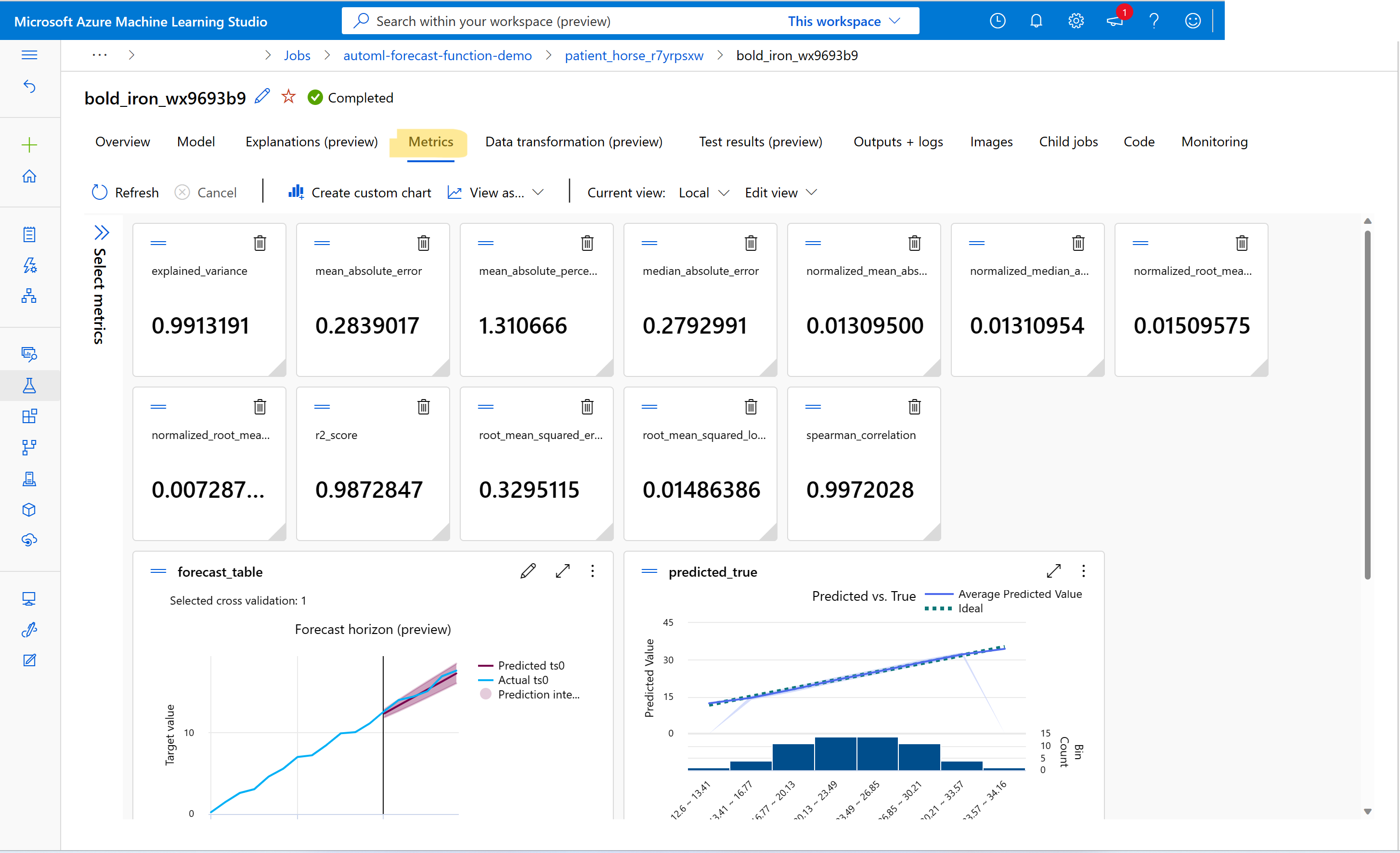
Come si visualizzano le metriche dai processi di training di previsione?
Per trovare i valori delle metriche di training e convalida, vedere Visualizzare le informazioni sui processi o sulle esecuzioni in studio. È possibile visualizzare le metriche per qualsiasi modello di previsione sottoposto a training in AutoML andando a un modello dall'interfaccia utente del processo AutoML in studio e selezionando la scheda Metriche.
Come si esegue il debug degli errori con i processi di training di previsione?
Se il processo di previsione AutoML ha esito negativo, un messaggio di errore visualizzato nell'interfaccia utente di studio consente di diagnosticare e risolvere il problema. La migliore fonte di informazioni sull'errore oltre il messaggio di errore è il log del driver relativo al processo. Per istruzioni su come trovare i log dei driver, vedere Visualizzare le informazioni sui processi/sulle esecuzioni con MLflow.
Nota
Per un processo Molti modelli o HTS, il training è in genere in cluster di elaborazione a più nodi. I log per questi processi sono presenti per ogni indirizzo IP del nodo. In questo caso, è necessario cercare i log degli errori in ogni nodo. I log degli errori, insieme ai log del driver, si trovano nella cartella user_logs per ogni indirizzo IP del nodo.
Come si distribuisce un modello dai processi di training di previsione?
È possibile distribuire un modello dai processi di training di previsione in uno dei seguenti modi:
- Endpoint online: controllare il file di assegnazione dei punteggi usato nella distribuzione o selezionare la scheda Test nella pagina dell'endpoint in studio per comprendere la struttura di input prevista dalla distribuzione. Per un esempio, vedere questo notebook. Per altre informazioni sulla distribuzione online, vedere Distribuire un modello AutoML in un endpoint online.
- Endpoint batch: questo metodo di distribuzione richiede di sviluppare uno script di assegnazione dei punteggi personalizzato. Per un esempio, fare riferimento a questo notebook. Per altre informazioni sulla distribuzione batch, vedere Usare gli endpoint batch per l'assegnazione dei punteggi batch.
Per le distribuzioni dell'interfaccia utente, è consigliabile usare una di queste opzioni:
- Endpoint in tempo reale
- Endpoint batch
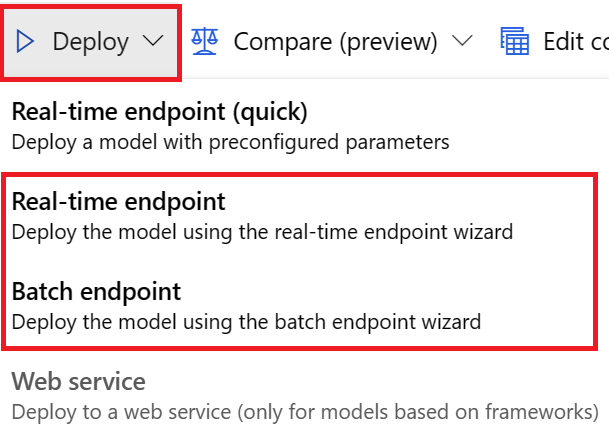
Non usare la prima opzione, Endpoint in tempo reale (rapida).
Nota
Al momento, non è supportata la distribuzione del modello MLflow dai processi di training di previsione tramite SDK, interfaccia della riga di comando o interfaccia utente. Se si prova a eseguire questa operazione, si otterranno errori.
Che cos'è un'area di lavoro, un ambiente, un esperimento, un'istanza di ambiente di calcolo o una destinazione di calcolo?
Se non si ha familiarità con i concetti di Azure Machine Learning, iniziare con gli articoli Che cos'è Azure Machine Learning? e Che cos'è un'area di lavoro di Azure Machine Learning?.
Passaggi successivi
- Altre informazioni su come configurare AutoML per eseguire il training di un modello di previsione di serie temporali.
- Informazioni sulle funzionalità di calendario per la previsione di serie temporali in AutoML.
- Informazioni su come AutoML usa l'apprendimento automatico per creare modelli di previsione.
- Informazioni sulle previsioni autoML per le funzionalità differite.