Sweep e selezione dei modelli per la previsione in AutoML
Questo articolo descrive come Machine Learning automatizzato (AutoML) in Azure Machine Learning cerca e seleziona i modelli di previsione. Per altre informazioni sulla metodologia di previsione in AutoML, vedere Panoramica dei metodi di previsione in AutoML. Per esplorare gli esempi di training per la previsione dei modelli in AutoML, vedere Configurare AutoML per eseguire il training di un modello di previsione di serie temporali con l'SDK e l'interfaccia della riga di comando.
Sweep del modello in AutoML
L'attività centrale di AutoML consiste nell'eseguire il training e valutare diversi modelli e scegliere quello migliore rispetto alla metrica primaria fornita. La parola "model" in questo caso si riferisce sia alla classe del modello, ad esempio ARIMA che alla foresta casuale, e alle impostazioni specifiche di iper parametri che distinguono i modelli all'interno di una classe. Ad esempio, ARIMA si riferisce a una classe di modelli che condividono un modello matematico e un set di presupposti statistici. Il training o l'adattamento di un modello ARIMA richiede un elenco di numeri interi positivi che specificano la forma matematica precisa del modello. Questi valori sono gli iper parametri. I modelli ARIMA(1, 0, 1) e ARIMA(2, 1, 2) hanno la stessa classe, ma iper parametri diversi. Queste definizioni possono essere adattate separatamente ai dati di training e valutate l'una rispetto all'altra. AutoML esegue ricerche, o sweep, su classi di modello diverse e all'interno di classi variando gli iperparaparatori.
Metodi di sweep di iperparaparazione
La tabella seguente illustra i diversi metodi di sweep di iperparametri usati da AutoML per classi di modelli diverse:
| Gruppo di classi di modelli | Tipo di modello | Metodo di sweep di iperparametri |
|---|---|---|
| Naive, Seasonal Naive, Average, Seasonal Average | Serie temporale | Nessuno sweep all'interno della classe a causa della semplicità del modello |
| Exponential Smoothing, ARIMA(X) | Serie temporale | Ricerca a griglia per lo sweep all'interno della classe |
| Prophet | Regressione | Nessuno sweep all'interno della classe |
| Linear SGD, LARS LASSO, Elastic Net, K Nearest Neighbors, Decision Tree, Random Forest, Extremely Randomized Trees, Gradient Boosted Trees, LightGBM, XGBoost | Regressione | Il servizio di raccomandazione dei modelli di AutoML esplora in modo dinamico gli spazi degli iperparametri |
| ForecastTCN | Regressione | Elenco statico di modelli seguiti da una ricerca casuale sulle dimensioni della rete, il rapporto di rilascio e la frequenza di apprendimento |
Per una descrizione dei diversi tipi di modello, vedere la sezione Modelli di previsione in AutoML dell'articolo Panoramica dei metodi di previsione.
La quantità di sweep da AutoML dipende dalla configurazione del processo di previsione. È possibile specificare i criteri di arresto come limite di tempo o un limite per il numero di versioni di valutazione o il numero equivalente di modelli. La logica di terminazione anticipata può essere usata in entrambi i casi per interrompere lo sweep se la metrica primaria non migliora.
Selezione del modello in AutoML
AutoML segue un processo in tre fasi per cercare e selezionare i modelli di previsione:
Fase 1: eseguire lo sweep sui modelli di serie temporali e selezionare il modello migliore da ogni classe usando i metodi di stima della massima probabilità.
Fase 2: eseguire lo sweep sui modelli di regressione e classificarli, insieme ai modelli di serie temporali migliori della fase 1, in base ai valori delle metriche principali dei set di convalida.
Fase 3: creare un modello di insieme dai modelli classificati più in alto, calcolare la metrica di convalida e classificarla con gli altri modelli.
Il modello con il valore della metrica meglio classificato alla fine della fase 3 viene designato come modello migliore.
Importante
Nella fase 3, AutoML calcola sempre le metriche sui dati out-of-sample che non vengono usati per adattarsi ai modelli. Questo approccio consente di proteggersi dall'overfitting.
Configurazioni di convalida
AutoML ha due configurazioni di convalida: convalida incrociata e dati di convalida espliciti.
Nel caso della convalida incrociata, AutoML usa la configurazione di input per creare suddivisioni dei dati in riduzioni di training e convalida. L'ordine di tempo deve essere mantenuto in queste divisioni. AutoML usa la cosiddetta convalida incrociata dell'origine mobile, che divide la serie in dati di training e convalida usando un punto temporale di origine. Scorrere l'origine nel tempo comporta la generazione di riduzioni della convalida incrociata. Ogni riduzione di convalida contiene l'orizzonte di osservazioni immediatamente successivo alla posizione dell'origine per la riduzione specificata. Questa strategia mantiene l'integrità dei dati delle serie temporali e riduce il rischio di perdita di informazioni.
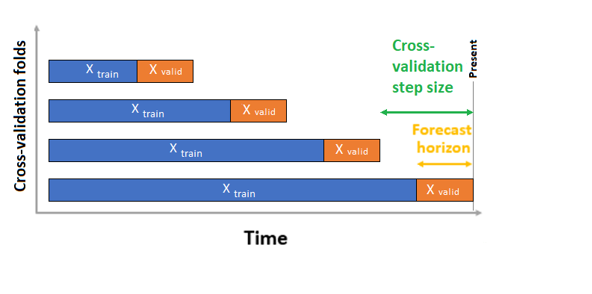
AutoML segue la normale procedura di convalida incrociata, eseguendo il training di un modello separato su ogni riduzione e calcolando la media delle metriche di convalida di tutte le riduzioni.
La convalida incrociata per i processi di previsione viene configurata impostando il numero di riduzioni di convalida incrociata e, facoltativamente, il numero di periodi di tempo tra due riduzioni di convalida incrociata consecutive. Per altre informazioni e un esempio di configurazione della convalida incrociata per la previsione, vedere Impostazioni di convalida incrociata personalizzate.
È anche possibile usare i propri dati di convalida. Per altre informazioni, vedere Configurare dati di training, convalida, convalida incrociata e test in AutoML (SDK v1).For more information, see Configure training, validation, cross-validation, and test data in AutoML (SDK v1).