Previsione su larga scala: molti modelli e training distribuito
Questo articolo illustra il training dei modelli di previsione su grandi quantità di dati cronologici. Istruzioni ed esempi per il training dei modelli di previsione in AutoML sono disponibili nell'articolo Configurare AutoML per le previsioni delle serie temporali.
I dati delle serie temporali possono essere di grandi dimensioni a causa del numero di serie nei dati, del numero di osservazioni cronologiche o di entrambi. Molti modelli e serie temporali gerarchiche, o HTS, sono soluzioni di ridimensionamento per lo scenario precedente, in cui i dati sono costituiti da un numero elevato di serie temporali. In questi casi, può essere utile per l'accuratezza e la scalabilità del modello eseguire una partizione dei dati in gruppi ed eseguire il training di un numero elevato di modelli indipendenti in parallelo sui gruppi. Viceversa, esistono scenari in cui è preferibile usare uno o pochi modelli ad alta capacità. Il training DNN distribuito si applica proprio a quest'ultimo caso. Nella parte restante dell'articolo vengono esaminati i concetti relativi a questi scenari.
Molti modelli
I numerosi componenti dei modelli in AutoML consentono di eseguire il training e gestire milioni di modelli in parallelo. Si supponga, ad esempio, di avere dati cronologici relativi alle vendite per un numero elevato di negozi. È possibile usare molti modelli per avviare processi di training AutoML paralleli per ogni archivio, come illustrato nel diagramma seguente:

Il componente di training di molti modelli applica lo sweep e la selezione del modello di AutoML in modo indipendente a ogni archivio in questo esempio. Questa indipendenza del modello facilita la scalabilità e può trarre vantaggio dall'accuratezza del modello, soprattutto quando i negozi hanno dinamiche di vendita divergenti. Tuttavia, un singolo approccio al modello può produrre previsioni più accurate quando sono presenti dinamiche di vendita comuni. Per altri dettagli su questo caso, vedere la sezione sul training di DNN distribuito.
È possibile configurare il partizionamento dei dati, le impostazioni AutoML per i modelli e il grado di parallelismo per molti processi di training dei modelli. Per esempi, vedere la sezione della guida su molti componenti di modelli.
Previsione gerarchica delle serie temporali
È comune che le serie temporali nelle applicazioni aziendali abbiano attributi annidati che formano una gerarchia. Gli attributi di geografia e del catalogo prodotti sono spesso annidati, ad esempio. Si consideri un esempio in cui la gerarchia ha due attributi geografici, l'ID dello stato e l'ID archivio, e due attributi del prodotto, categoria e SKU:

Questa gerarchia è illustrata nel diagramma seguente:

In particolare, le quantità di vendita a livello di nodo foglia (SKU) si aggiungono alle quantità di vendita aggregate a livello di stato e vendite totali. I metodi di previsione gerarchici mantengono queste proprietà di aggregazione durante la previsione della quantità venduta a qualsiasi livello della gerarchia. Le previsioni con questa proprietà sono coerenti rispetto alla gerarchia.
AutoML supporta le funzionalità seguenti per le serie temporali gerarchiche (HTS):
- Training a qualsiasi livello della gerarchia. In alcuni casi, i dati a livello di nodo foglia possono essere disturbati, ma le aggregazioni possono essere più adatte alla previsione.
- Recupero delle previsioni dei punti a qualsiasi livello della gerarchia. Se il livello di previsione è "inferiore" al livello di training, le previsioni del livello di training vengono disaggregate attraverso proporzioni cronologiche medie o proporzioni delle medie cronologiche. Le previsioni a livello di training vengono sommate in base alla struttura di aggregazione quando il livello di previsione è "superiore" al livello di training.
- Recupero di previsioni quantile/probabilistiche per i livelli pari o "inferiori" al livello di training. Le funzionalità di modellazione correnti supportano la disaggregazione delle previsioni probabilistiche.
I componenti HTS in AutoML sono basati su molti modelli, quindi HTS condivide le proprietà scalabili di molti modelli. Per esempi, vedere la sezione della guida sui componenti HTS.
Training di DNN distribuito (anteprima)
Importante
Questa funzionalità è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza contratto di servizio, pertanto se ne sconsiglia l’uso per i carichi di lavoro in ambienti di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate.
Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Gli scenari di dati con grandi quantità di osservazioni cronologiche e/o un numero elevato di serie temporali correlate possono trarre vantaggio da un approccio scalabile e a modello singolo. Di conseguenza, AutoML supporta il training distribuito e la ricerca di modellidi rete temporale convoluzionale (TCN), un tipo di rete neurale profonda (DNN) per i dati delle serie temporali. Per altre informazioni sulla classe del modello TCN di AutoML, vedere l'articolo sulla DNN.
Il training di DNN distribuito consente di ottenere scalabilità usando un algoritmo di partizionamento dei dati che rispetta i limiti delle serie temporali. Il diagramma seguente illustra un semplice esempio con due partizioni:
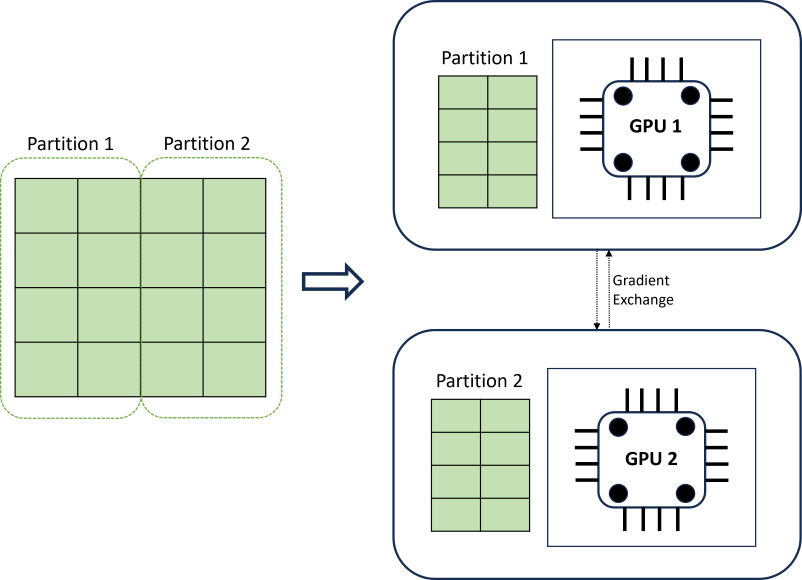
Durante il training, gli strumenti di caricamento dei dati DNN su ogni carico di calcolo devono solo completare un'iterazione di retro-propagazione; l'intero set di dati non viene mai letto nella memoria. Le partizioni vengono ulteriormente distribuite tra più core di calcolo (in genere GPU) in più nodi per accelerare il training. Il coordinamento tra i calcoli viene fornito dal framework Horovod.
Passaggi successivi
- Altre informazioni su come configurare AutoML per eseguire il training di un modello di previsione di serie temporali.
- Informazioni su come AutoML usa l'apprendimento automatico per creare modelli di previsione.
- Informazioni sui modelli di Deep Learning per la previsione in AutoML