Deep Learning con previsione di AutoML
Questo articolo è incentrato sui metodi di Deep Learning per la previsione delle serie temporali in AutoML. Istruzioni ed esempi per il training dei modelli di previsione in AutoML sono disponibili nell'articolo Configurare AutoML per le previsioni delle serie temporali.
Il Deep Learning ha numerosi casi d'uso in campi che vanno dalla definizione di modelli linguistici al ripiegamento delle proteine, per citarne che alcuni. La previsione di serie temporali trae vantaggio anche dai recenti progressi nella tecnologia di Deep Learning. Ad esempio, i modelli di rete neurale profonda (DNN) spiccano tra i modelli con prestazioni migliori della quarta e quinta iterazione di previsione Makridakis di alto profilo concorrente.
In questo articolo, sono descritti la struttura e il funzionamento del modello TCNForecaster in AutoML per facilitare l'applicazione del modello al proprio scenario.
Introduzione a TCNForecaster
TCNForecaster è una rete convoluzionale temporale, o TCN, che ha un'architettura DNN progettata per i dati delle serie temporali. Il modello usa i dati cronologici per una quantità di destinazione, insieme alle funzionalità correlate, per effettuare previsioni probabilistiche della destinazione fino a un orizzonte di previsione specificato. L'immagine seguente mostra i componenti principali dell'architettura TCNForecaster:
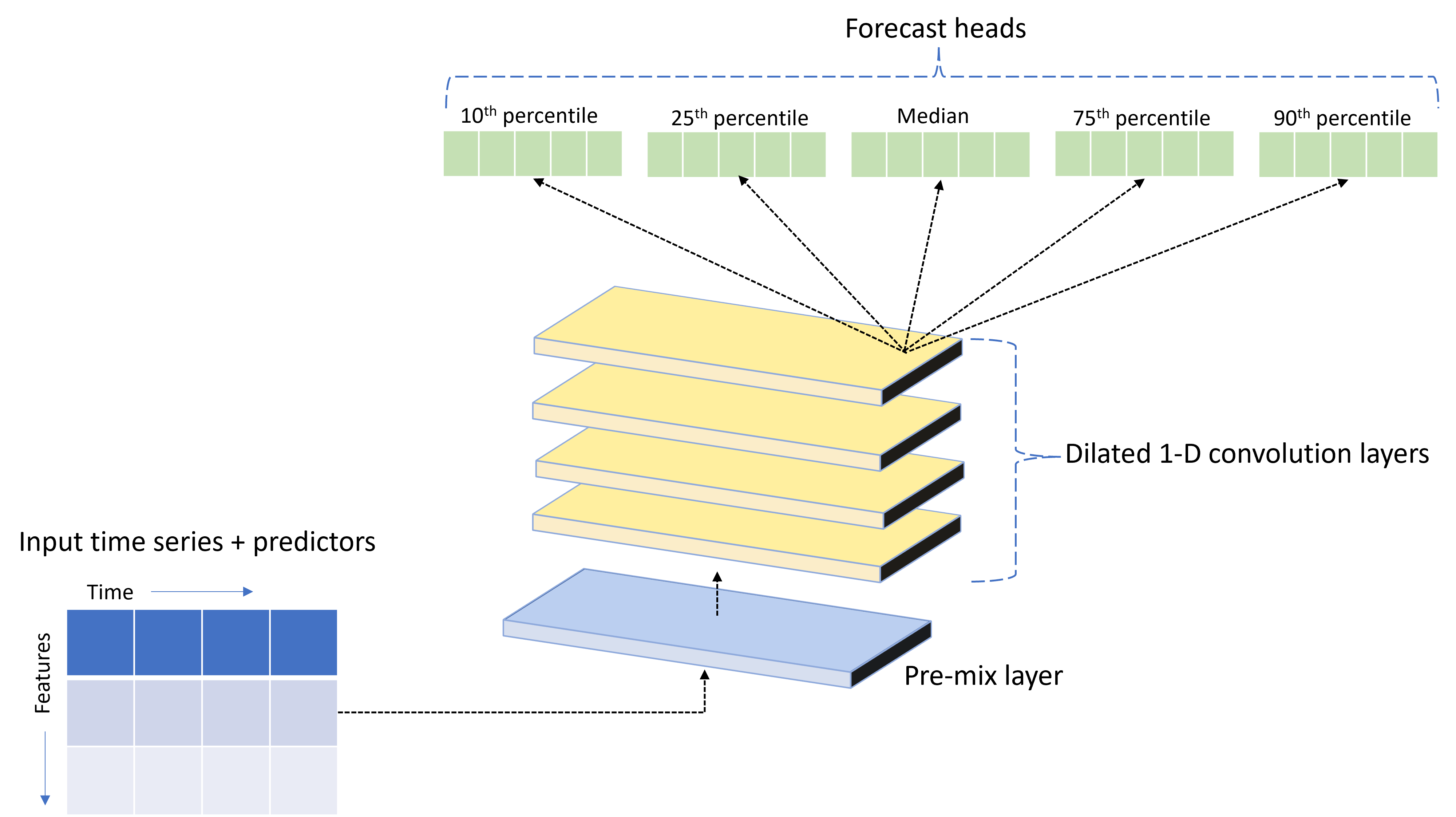
TCNForecaster presenta i componenti principali seguenti:
- Un livello di pre-combinazione che combina le serie temporali di input e i dati delle funzionalità in una array di canali dei segnali che vengono elaborati dallo stack convoluzionale.
- Uno stack di livelli di convoluzione dilatati che elabora l'array di canali in sequenza; ogni livello nello stack elabora l'output del livello precedente per produrre un nuovo array di canali. Ogni canale in questo output contiene una combinazione di segnali filtrati per convoluzione dai canali di input.
- Una raccolta di unità head di previsione che fondono i segnali di output dai livelli di convoluzione e generano previsioni della quantità di destinazione da questa rappresentazione latente. Ogni unità head produce previsioni fino all'orizzonte per un quantile della distribuzione di stima.
Convoluzione causale dilatata
L'operazione centrale di un TCN è una convoluzione causale dilatata lungo la dimensione temporale di un segnale di input. In modo intuitivo, la convoluzione combina i valori dei punti temporali vicini nell'input. Le proporzioni di combinazione sono il kernel, o i pesi, della convoluzione, mentre la separazione tra punti nella combinazione è la dilazione. Il segnale di output viene generato dall'input facendo scorrere il kernel nel tempo lungo l'input e accumulando la composizione in ogni posizione. Una convoluzione causale è una convoluzione in cui il kernel combina solo i valori di input del passato rispetto a ogni punto di output, impedendo all'output di "guardare" il futuro.
La sovrapposizione di convoluzioni correlate offre alla rete TCN la possibilità di modellare le correlazioni per durate prolungate nei segnali di input con pesi del kernel relativamente esigui. Ad esempio, l'immagine seguente mostra tre livelli impilati con un kernel a due pesi in ogni livello e fattori di dilazione dalla crescita esponenziale:
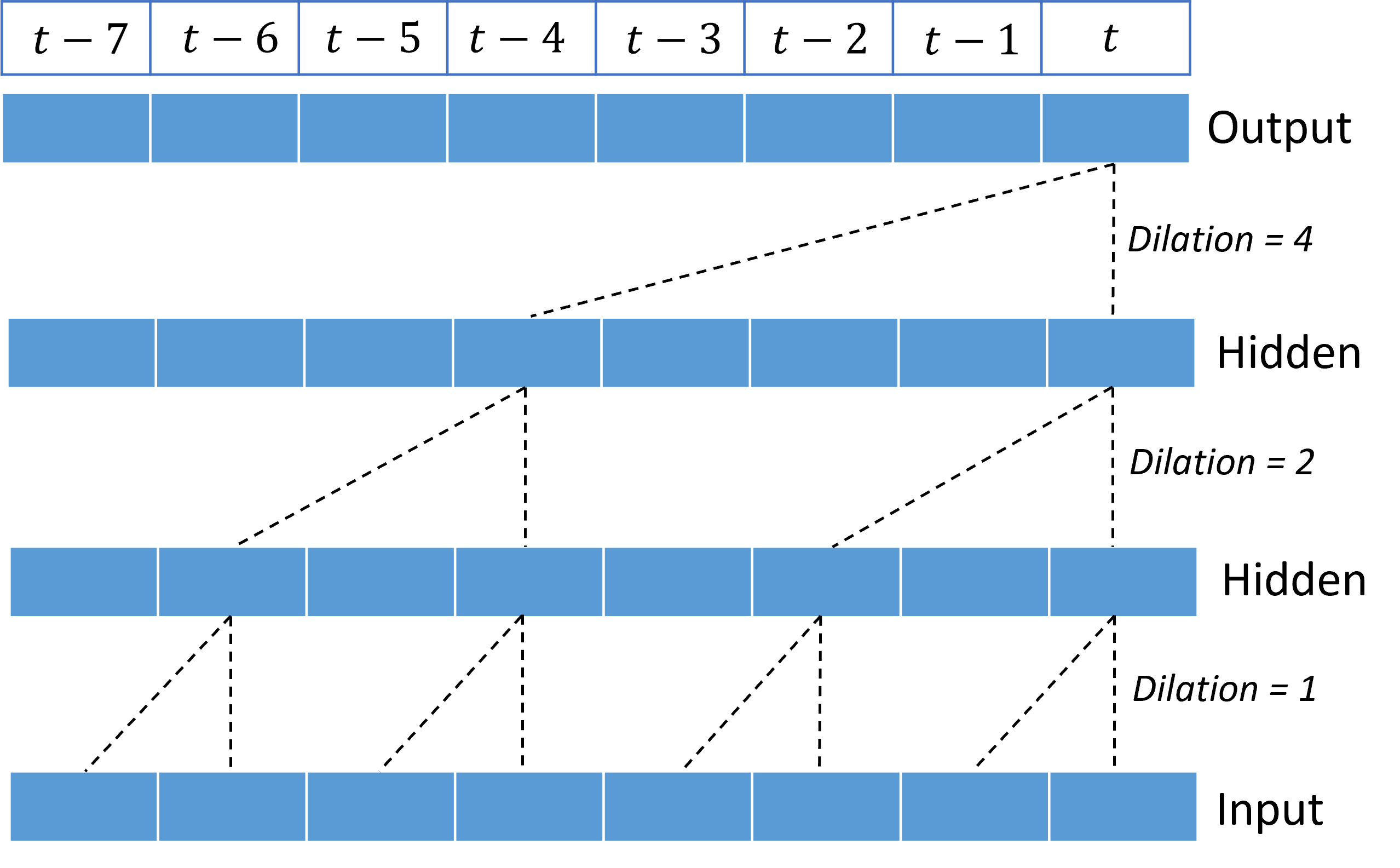
Le linee tratteggiate mostrano i percorsi attraverso la rete che terminano sull'output in una sola volta $t$. Questi percorsi coprono gli ultimi otto punti nell'input, illustrando che ogni punto di output è una funzione degli otto punti più recenti nell'input. La lunghezza della cronologia, o "sguardo indietro", usata da una rete convoluzionale per effettuare stime è detta campo ricettivo ed è determinata completamente dall'architettura TCN.
Architettura di TCNForecaster
Il nucleo dell'architettura TCNForecaster è lo stack di livelli convoluzionali tra la pre-combinazione e gli head di previsione. Lo stack è suddiviso logicamente in unità ripetute denominate blocchi che, a loro volta, sono composti da celle residue. Una cella residua applica le convoluzioni causali alla dilazione di un set insieme alla normalizzazione e all'attivazione non lineare. In particolare, ogni cella residua aggiunge il proprio output all'input usando una cosiddetta connessione residua. Queste connessioni hanno dimostrato di trarre vantaggio dal training DNN, forse perché favoriscono un flusso di informazioni più efficiente attraverso la rete. L'immagine seguente mostra l'architettura dei livelli convoluzionali per una rete di esempio con due blocchi e tre celle residui in ogni blocco:
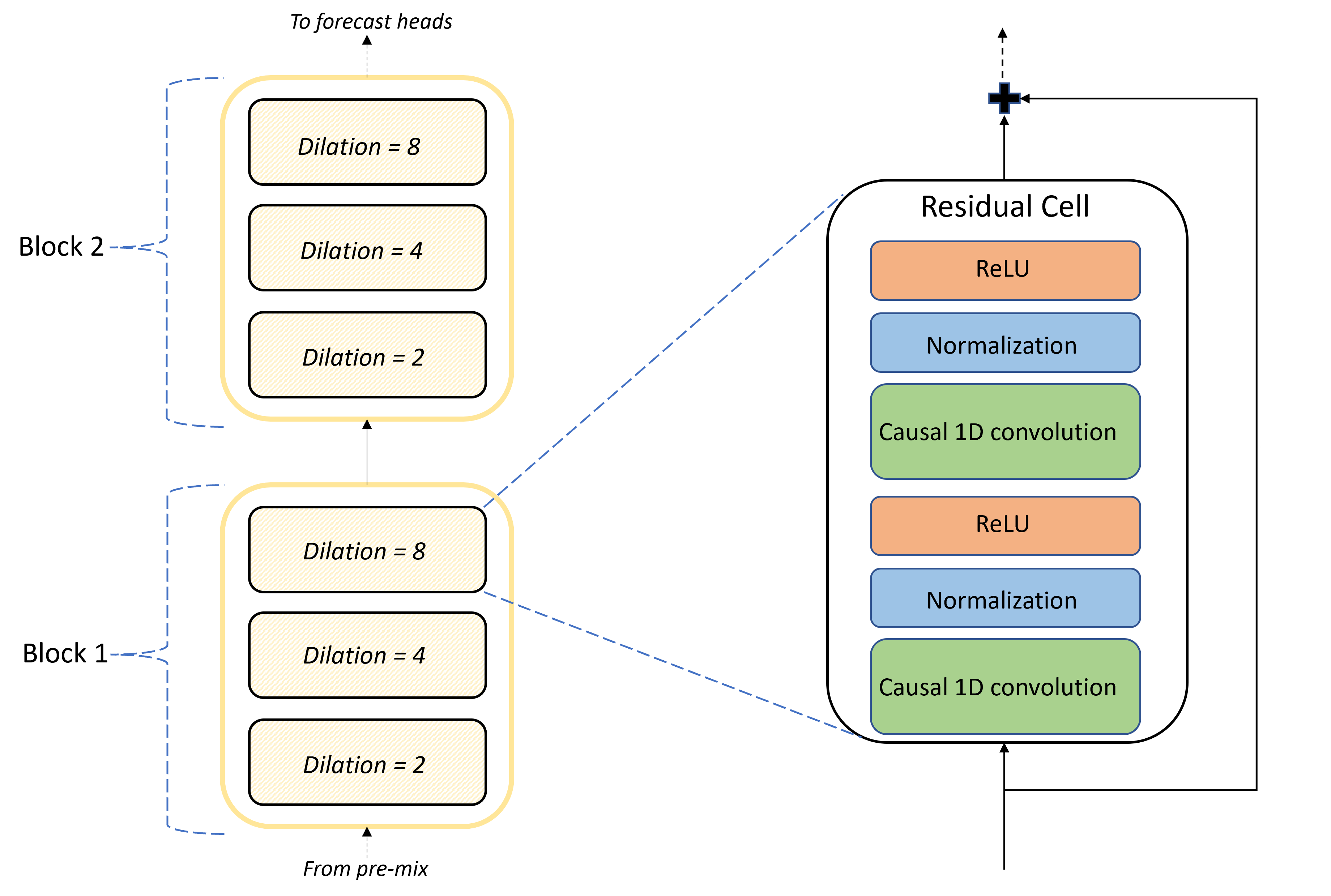
Il numero di blocchi e celle, insieme al numero di canali di segnale in ogni livello, controlla le dimensioni della rete. I parametri dell'architettura di TCNForecaster sono riepilogati nella tabella seguente:
| Parametro | Descrizione |
|---|---|
| $n_{b}$ | Numero di blocchi nella rete; definito anche profondità |
| $n_{c}$ | Numero di celle in ogni blocco |
| $n_{\text{ch}}$ | Numero di canali nei livelli nascosti |
Il campo ricettivo dipende dai parametri di profondità e viene ricavato dalla formula,
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\right) + 1.$
Possiamo dare una definizione più precisa dell'architettura TCNForecaster in termini di formule. Supponiamo che $X$ sia un array di input in cui ogni riga contiene valori delle funzionalità dai dati di input. È possibile dividere $X$ in array di caratteristiche numeriche e categoriche, $X_{\text{num}}$ e $X_{\text{cat}}$. Quindi, TCNForecaster viene ricavato dalle formule,
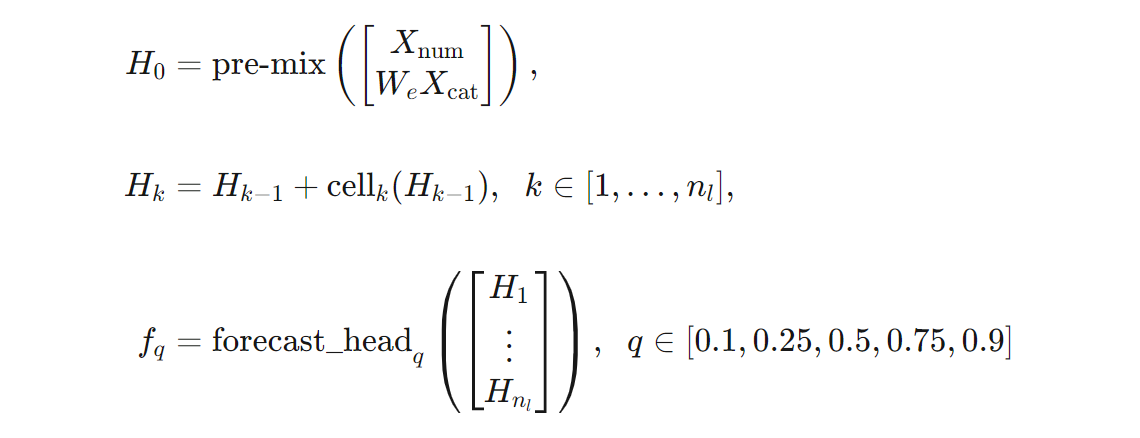
Dove $W_{e}$ è una matrice di incorporamento per le funzionalità categoriche; $n_{l} = n_{b}n_{c}$ è il numero totale di celle residue; $H_{k} indica gli output nascosti del livello e $f_{q}$ indica gli output delle previsioni per i quantili specificati della distribuzione di stima. Per facilitare la comprensione, le dimensioni di queste variabili sono riportate nella tabella seguente:
| Variabile | Descrizione | Dimensioni |
|---|---|---|
| $X$ | Array di input | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | Output del livello nascosto per $i=0,1,\ldots,n_{l}$ | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | Previsione dell'output per quantile $q$ | $h$ |
Nella tabella, $n_{\text{input}} = n_{\text{features}} + 1$, il numero di predittore/variabile funzionalità più la quantità di destinazione. Gli head di previsione generano tutte le previsioni fino all'orizzonte massimo, $h$, in un unico passaggio, quindi TCNForecaster è uno strumento di previsione diretto.
TCNForecaster in AutoML
TCNForecaster è un modello facoltativo in AutoML. Per informazioni su come usarlo, vedere abilitare il Deep Learning.
In questa sezione, viene descritto come AutoML compila modelli TCNForecaster con i dati, con spiegazioni della pre-elaborazione dei dati, il training e la ricerca di modelli.
Passaggi di pre-elaborazione dei dati
AutoML esegue diversi passaggi di pre-elaborazione dei dati per preparare il training del modello. La tabella seguente descrive questi passaggi nell'ordine in cui vengono eseguiti:
| Procedi | Descrizione |
|---|---|
| Compilare i dati mancanti | Attribuire i valori mancanti e le lacune di osservazione e, facoltativamente, riempire o rilasciare serie temporali brevi |
| Creare le funzionalità del calendario | Aumentare i dati di input con le funzionalità derivate dal calendario, ad esempio il giorno della settimana e, facoltativamente, le festività per un paese/area geografica in particolare. |
| Codificare i dati categorici | Le stringhe di codifica delle etichette e altri tipi categorici, incluse tutte le colonne ID delle serie temporali. |
| Trasformazione della destinazione | Facoltativamente, applicare la funzione logaritmo naturale alla destinazione a seconda dei risultati di determinati test statistici. |
| Normalizzazione | Il punteggio Z normalizza tutti i dati numerici; la normalizzazione viene eseguita per gruppo di serie temporali e per funzionalità, come definito dalle colonne ID delle serie temporali. |
Questi passaggi sono inclusi nelle pipeline di trasformazione di AutoML, quindi vengono applicati automaticamente quando necessario in fase di inferenza. In alcuni casi, l'operazione inversa a un passaggio viene inclusa nella pipeline di inferenza. Ad esempio, se AutoML ha applicato una trasformazione $\log$ alla destinazione durante il training, le previsioni non elaborate vengono esponenziate nella pipeline di inferenza.
Formazione
TCNForecaster segue le procedure consigliate di training DNN comuni ad altre applicazioni per immagini e linguaggio. AutoML divide i dati di training pre-elaborati in esempi casuali e raccolti in batch. La rete elabora i batch in sequenza, usando la retro-propagazione e la discesa del gradiente stocastico per ottimizzare i pesi di rete rispetto a una funzione di perdita. Il training può richiedere molti passaggi attraverso i dati di training completi; ogni passaggio viene chiamato epoca.
La tabella seguente elenca e descrive le impostazioni di input e i parametri per il training TCNForecaster:
| Input di training | Descrizione | Valore |
|---|---|---|
| Convalida dei dati | Una parte dei dati che viene tenuta fuori dal training per guidare l'ottimizzazione della rete e attenuare l'overfitting.. | Fornito dall'utente o creato automaticamente dai dati di training, se non specificato. |
| Primary metric (Metrica principale) | Metrica calcolata dalle previsioni medie sui dati di convalida alla fine di ogni epoca di training; utilizzata per l'arresto anticipato e la selezione del modello. | Scelto dall'utente; radice errore quadratico medio normalizzato o errore assoluto medio normalizzato. |
| Epoche di training | Numero massimo di epoche da eseguire per l'ottimizzazione del peso della rete. | 100; la logica di arresto anticipato automatizzato può terminare il training a un numero inferiore di epoche. |
| Pazienza di arresto anticipato | Numero di epoche da attendere per il miglioramento della metrica primaria prima dell'arresto del training. | 20 |
| Funzione di perdita | La funzione obiettivo per l'ottimizzazione del peso della rete. | La perdita di quantile media oltre il 10°, il 25°, il 50°, il 75° e il 90° percentile di previsione. |
| Dimensioni dei batch | Numero di esempi in un batch. Ogni esempio ha dimensioni $n_{\text{input}} \times t_{\text{rf}}$ per input e $h$ per l'output. | Determinato automaticamente dal numero totale di esempi nei dati di training; il valore massimo è 1024. |
| Dimensioni di incorporamento | Dimensioni degli spazi di incorporamento per le funzionalità categoriche. | Impostato automaticamente sulla quarta radice del numero di valori distinti in ogni funzionalità, arrotondato al numero intero più vicino. Le soglie vengono applicate a un valore minimo di 3 e a un valore massimo di 100. |
| Architettura di rete* | Parametri che controllano le dimensioni e la forma della rete: profondità, numero di celle e numero di canali. | Determinato dalla ricerca del modello. |
| Pesi della rete | Parametri che controllano le combinazioni di segnali, incorporamenti categorici, pesi dei kernel di convoluzione e mapping ai valori di previsione. | Inizializzato in modo casuale, quindi ottimizzato in base alla funzione di perdita. |
| Velocità di apprendimento* | Controlla la quantità di peso della rete che può essere regolata in ogni iterazione della discesa del gradiente; ridotta in modo dinamico in prossimità della convergenza. | Determinato dalla ricerca del modello. |
| Rapporto di rilascio* | Controlla il grado di regolarizzazione del rilascio applicato ai pesi della rete. | Determinato dalla ricerca del modello. |
Gli input contrassegnati con un asterisco (*) sono determinati da una ricerca di iper-parametri descritta nella prossima sezione.
Ricerca di modelli
AutoML usa metodi di ricerca dei modelli per trovare i valori per gli iper-parametri seguenti:
- Profondità della rete, o il numero di blocchi convoluzionali,
- Numero di celle per blocco,
- Numero di canali in ogni livello nascosto,
- Rapporto di rilascio per la regolarizzazione della rete,
- Velocità di apprendimento.
I valori ottimali per questi parametri possono variare in modo significativo a seconda dello scenario del problema e dei dati di training; quindi, AutoML esegue il training di diversi modelli all'interno dello spazio dei valori degli iper-parametri e sceglie quello migliore in base al punteggio della metrica principale sui dati di convalida.
La ricerca del modello ha due fasi:
- AutoML esegue una ricerca su 12 modelli di "punto di riferimento". I modelli di punto riferimento sono statici e vengono scelti per estendere ragionevolmente lo spazio degli iper-parametri.
- AutoML continua la ricerca nello spazio degli iper-parametri usando una ricerca casuale.
La ricerca termina quando vengono soddisfatti i criteri di arresto. I criteri di arresto dipendono dalla configurazione del processo di training di previsione, ma alcuni esempi includono limiti di tempo, limiti del numero di prove di ricerca da eseguire e logica di arresto anticipato quando la metrica di convalida non viene migliorata.
Passaggi successivi
- Altre informazioni su come configurare AutoML per eseguire il training di un modello di previsione di serie temporali.
- Informazioni sulla metodologia di previsione in AutoML.
- Consultare le domande frequenti sulla previsione in AutoML.