Inferenza e valutazione dei modelli di previsione
Questo articolo presenta i concetti relativi all'inferenza del modello e alla valutazione nelle attività di previsione. Per istruzioni ed esempi per il training dei modelli di previsione in AutoML, vedere Configurare AutoML per eseguire il training di un modello di previsione di serie temporali con SDK e interfaccia della riga di comando.
Dopo aver usato AutoML per eseguire il training e selezionare un modello migliore, il passaggio successivo consiste nel generare previsioni. Quindi, se possibile, valutarne l'accuratezza in un set di test derivato dai dati di training. Per informazioni su come configurare ed eseguire la valutazione del modello di previsione in Machine Learning automatizzato, vedere Orchestrazione di training, inferenza e valutazione.
Scenari di inferenza
Nell'apprendimento automatico l'inferenza è il processo di generazione di stime del modello per i nuovi dati non usati nel training. Esistono diversi modi per generare stime nella previsione a causa della dipendenza temporale dei dati. Lo scenario più semplice è quando il periodo di inferenza segue immediatamente il periodo di training e vengono generate stime all'orizzonte di previsione. Il diagramma seguente illustra questo scenario:
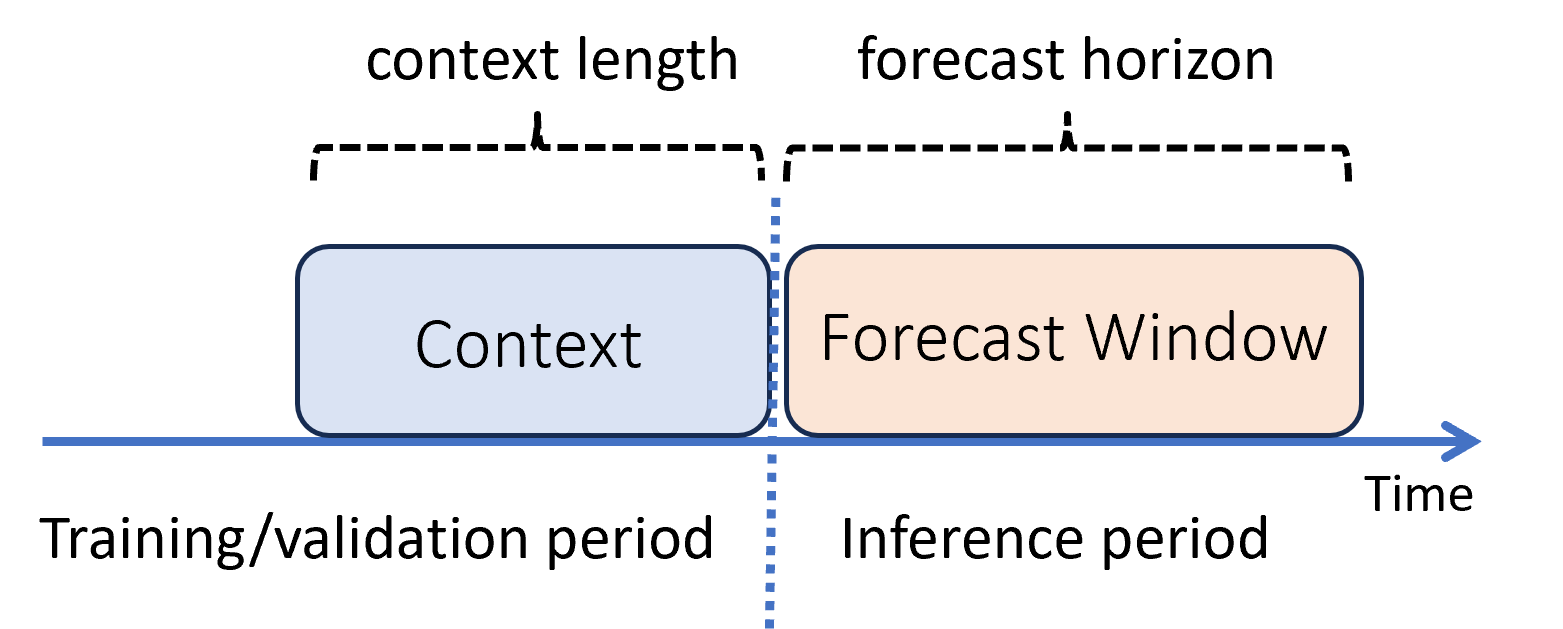
Il diagramma mostra due parametri di inferenza importanti:
- La lunghezza del contesto è la quantità di cronologia richiesta dal modello per effettuare una previsione.
- L'orizzonte di previsione indica quanto avanti nel tempo viene eseguito il training del responsabile della previsione per la stima.
I modelli di previsione usano in genere alcune informazioni cronologiche, il contesto, per creare stime in anticipo fino all'orizzonte di previsione. Quando il contesto fa parte dei dati di training, AutoML salva gli elementi necessari per effettuare previsioni. Non è necessario specificarlo in modo esplicito.
Esistono due altri scenari di inferenza più complessi:
- Generazione di stime più lontano nel futuro rispetto all'orizzonte di previsione
- Ottenere stime quando si verifica un divario tra i periodi di training e inferenza
Le sottosezioni seguenti esaminano questi casi.
Stima oltre l'orizzonte di previsione: previsione ricorsiva
Quando sono necessarie previsioni oltre l'orizzonte, AutoML applica il modello in modo ricorsivo nel periodo di inferenza. Le stime del modello vengono restituite come input per generare stime per le successive finestre di previsione. Il diagramma seguente mostra un semplice esempio:
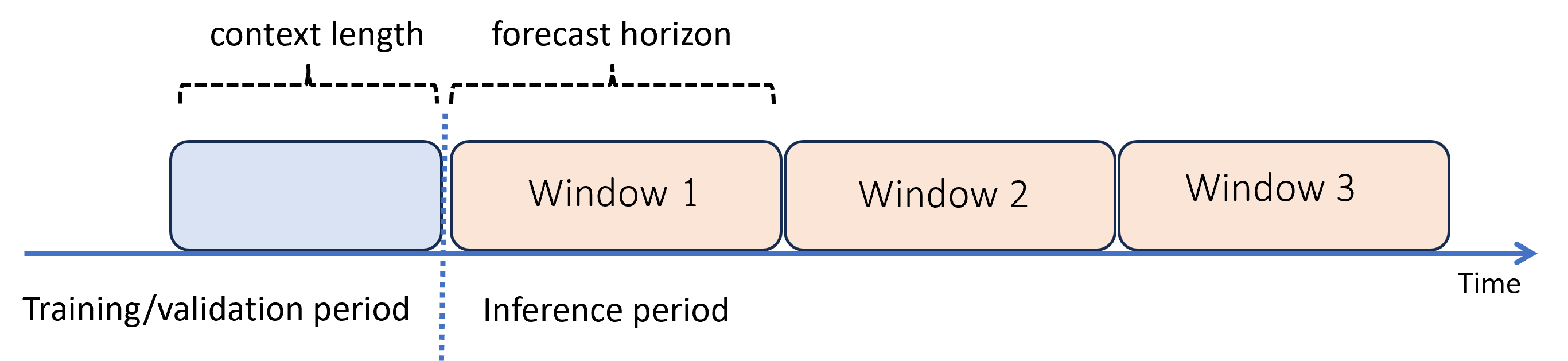
In questo caso l'apprendimento automatico genera previsioni su un periodo pari a tre volte la lunghezza dell'orizzonte. Usa stime da una finestra come contesto per la finestra successiva.
Avviso
La previsione ricorsiva può accumulare errori di modellazione. Le stime diventano meno accurate più lontane sono dall'orizzonte di previsione originale. È possibile trovare un modello più accurato eseguendo nuovamente il training con un orizzonte più lungo.
Stima con un divario tra periodi di training e inferenza
Si supponga che, dopo aver eseguito il training di un modello, lo si voglia usare per eseguire stime da nuove osservazioni non ancora disponibili durante il training. In questo caso, esiste un divario di tempo tra i periodi di training e inferenza:
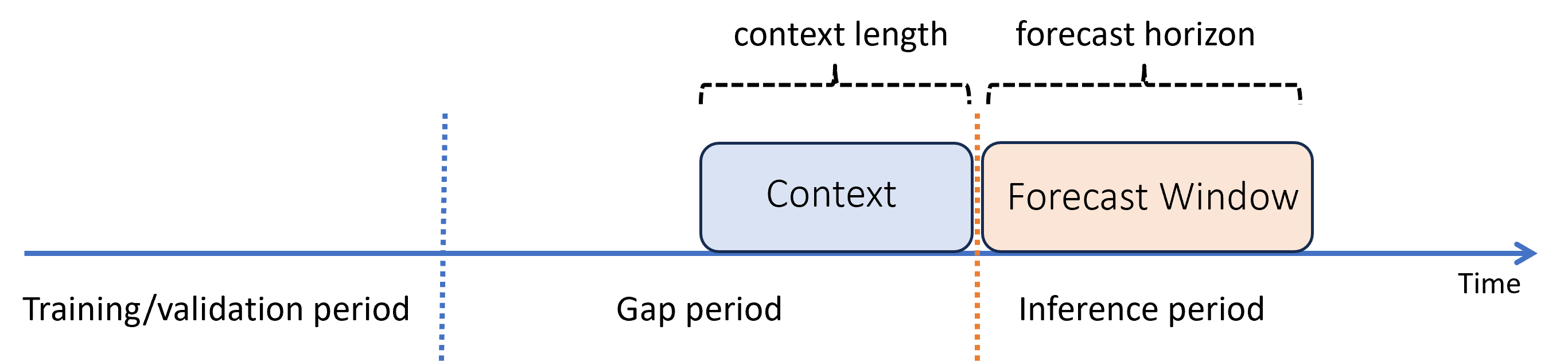
AutoML supporta questo scenario di inferenza, ma è necessario fornire i dati di contesto nel periodo di gap, come illustrato nel diagramma. I dati di stima passati al componente di inferenza hanno bisogno di valori per le funzionalità e i valori di destinazione osservati nel gap e valori mancanti o NaN per la destinazione nel periodo di inferenza. La tabella seguente mostra un esempio di questo criterio:
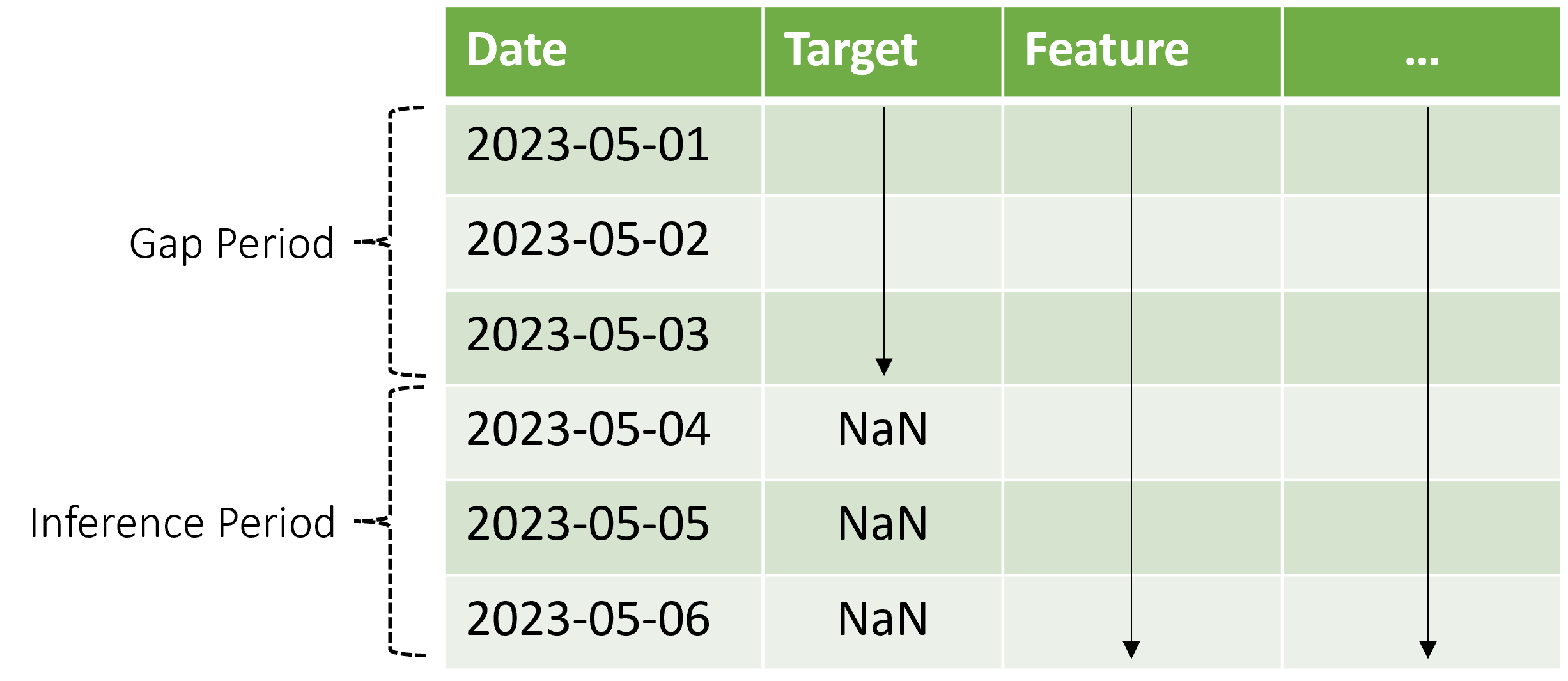
I valori noti della destinazione e delle funzionalità vengono forniti dal 2023-05-01 fino al 2023-05-03. I valori di destinazione mancanti a partire dal 2023-05-04 indicano che il periodo di inferenza inizia da tale data.
AutoML usa i nuovi dati di contesto per aggiornare il ritardo e altre funzionalità di lookback e anche per aggiornare modelli come ARIMA che mantengono uno stato interno. Questa operazione non aggiorna o adatta i parametri del modello.
Valutazione del modello
La valutazione è il processo di generazione di stime su un set di test derivato dai dati di training e dalle metriche di calcolo da queste stime che guidano le decisioni di distribuzione del modello. Di conseguenza, è disponibile una modalità di inferenza adatta alla valutazione del modello, ovvero una previsione in sequenza.
Una procedura consigliata per la valutazione di un modello di previsione consiste nell’eseguire il rollforward del responsabile della previsione sottoposto a training nel tempo nel set di test, calcolando la media delle metriche degli errori in diverse finestre di stima. Questa procedura viene talvolta definita backtest. Idealmente, il set di test per la valutazione è lungo rispetto all'orizzonte di previsione del modello. Le stime dell'errore di previsione potrebbero altrimenti essere statisticamente poco significative e, pertanto, meno affidabili.
Il diagramma seguente mostra un semplice esempio con tre finestre di previsione:
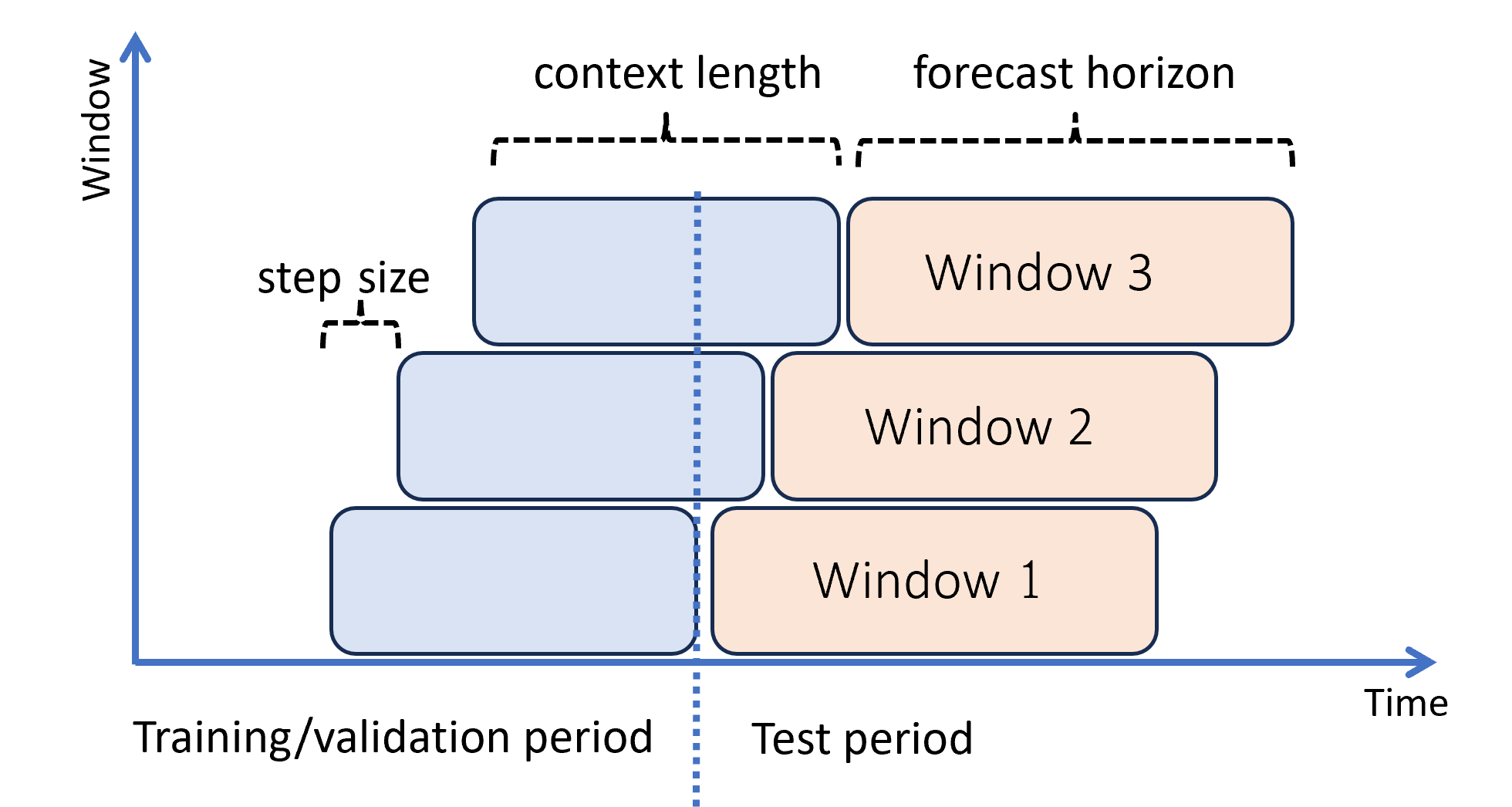
Il diagramma illustra tre parametri di valutazione in sequenza:
- La lunghezza del contesto è la quantità di cronologia richiesta dal modello per effettuare una previsione.
- L'orizzonte di previsione indica quanto avanti nel tempo viene eseguito il training del responsabile della previsione per la stima.
- La dimensione passaggio rappresenta l'anticipo con cui la finestra mobile avanza a ogni iterazione sull'insieme di test.
Il contesto avanza insieme alla finestra di previsione. I valori effettivi del set di test vengono usati per effettuare previsioni quando rientrano nella finestra di contesto corrente. La data più recente dei valori effettivi utilizzati per una determinata finestra di previsione viene chiamata ora di origine della finestra. La tabella seguente mostra un output di esempio della previsione in sequenza a tre finestre con un orizzonte di tre giorni e una dimensione del passaggio di un giorno:
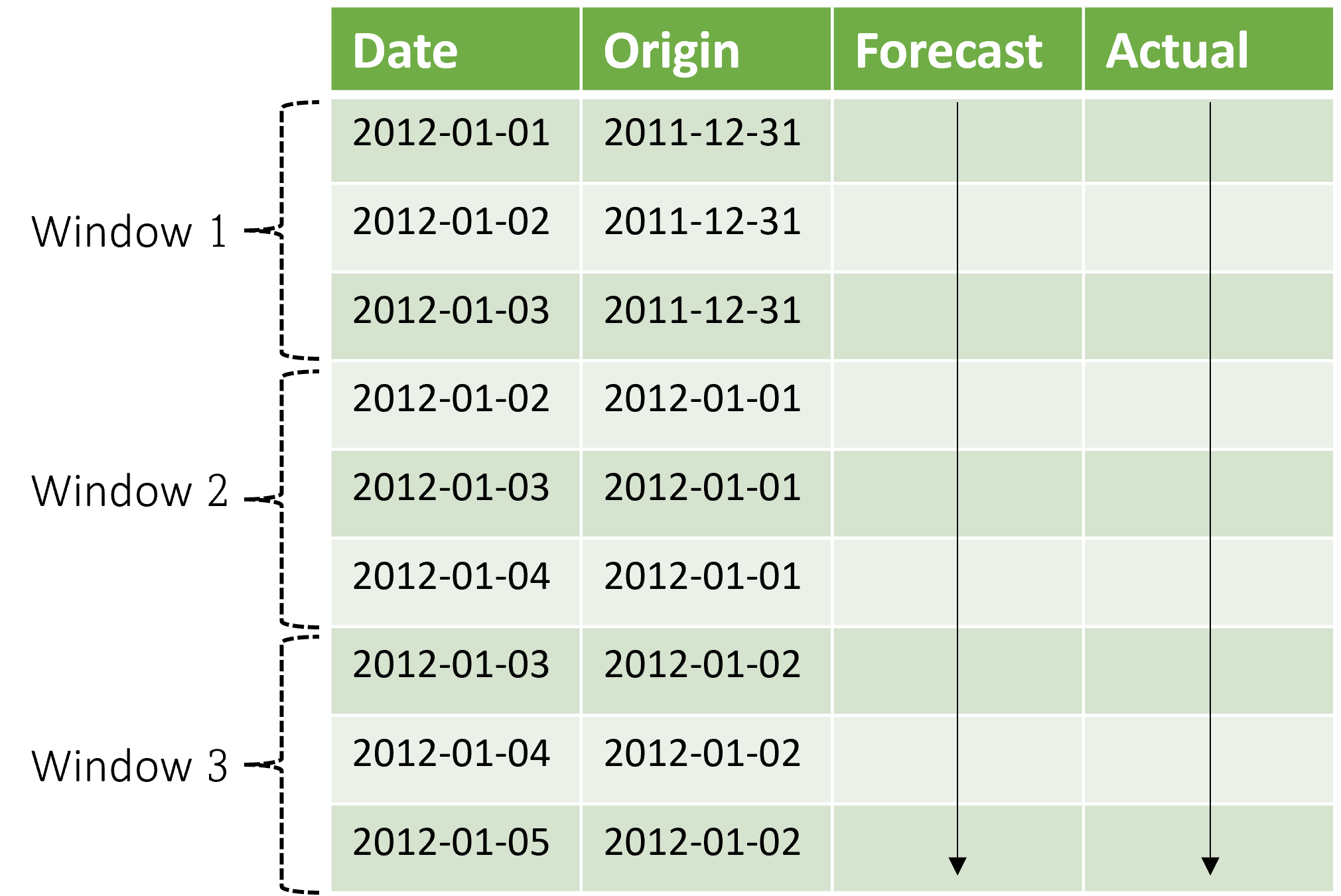
Con una tabella simile a questa, è possibile visualizzare le previsioni rispetto ai valori effettivi e calcolare le metriche di valutazione desiderate. Le pipeline AutoML possono generare previsioni in sequenza in un set di test con un componente di inferenza.
Nota
Quando il periodo di prova è la stessa lunghezza dell'orizzonte di previsione, una previsione mobile offre una singola finestra delle previsioni fino all'orizzonte.
Metriche di valutazione
Lo scenario aziendale specifico determina in genere la scelta del riepilogo o della metrica di valutazione. Alcune scelte comuni includono gli esempi seguenti:
- Tracciati dei valori di destinazione osservati rispetto ai valori previsti per verificare che determinate dinamiche dei dati vengano acquisite dal modello
- Errore assoluto medio percentuale (MAPE) tra valori effettivi e previsti
- Radice errore quadratico medio (RMSE), possibilmente con una normalizzazione, tra valori effettivi e previsti
- Errore assoluto medio (MAE), possibilmente con una normalizzazione, tra valori effettivi e previsti
Esistono molte altre possibilità, a seconda dello scenario aziendale. Potrebbe essere necessario creare utilità di post-elaborazione personalizzate per calcolare le metriche di valutazione da risultati di inferenza o previsioni in sequenza. Per altre informazioni sulle metriche, vedere Metriche di regressione/previsione.
Contenuto correlato
- Altre informazioni su come configurare AutoML per eseguire il training di un modello di previsione di serie temporali.
- Informazioni su come AutoML usa l'apprendimento automatico per creare modelli di previsione.
- Leggere le risposte alle domande frequenti sulle previsioni di AutoML.