Résoudre les problèmes liés aux requêtes lentes dans SQL Server
Version du produit d’origine : SQL Server
Numéro de base de connaissances d’origine : 243589
Introduction
Cet article explique comment gérer un problème de performances que les applications de base de données peuvent rencontrer lors de l’utilisation de SQL Server : performances lentes d’une requête ou d’un groupe de requêtes spécifique. La méthodologie suivante vous aidera à limiter la cause du problème de requêtes lentes et à vous diriger vers la résolution.
Rechercher des requêtes lentes
Pour établir que vous rencontrez des problèmes de performances de requête sur votre instance SQL Server, commencez par examiner les requêtes par leur temps d’exécution (temps écoulé). Vérifiez si le temps dépasse un seuil défini (en millisecondes) en fonction d’une base de référence de performances établie. Par exemple, dans un environnement de test de contrainte, vous avez peut-être établi un seuil pour que votre charge de travail ne soit plus de 300 ms, et vous pouvez utiliser ce seuil. Ensuite, vous pouvez identifier toutes les requêtes qui dépassent ce seuil, en se concentrant sur chaque requête individuelle et sa durée de base de référence des performances prédéfinie. En fin de compte, les utilisateurs professionnels se soucient de la durée globale des requêtes de base de données ; par conséquent, le principal focus est sur la durée d’exécution. D’autres métriques telles que le temps processeur et les lectures logiques sont collectées pour vous aider à affiner l’investigation.
Pour les instructions en cours d’exécution, vérifiez les colonnes total_elapsed_time et cpu_time dans sys.dm_exec_requests. Exécutez la requête suivante pour obtenir les données :
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;Pour les exécutions passées de la requête, vérifiez les colonnes last_elapsed_time et last_worker_time dans sys.dm_exec_query_stats. Exécutez la requête suivante pour obtenir les données :
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCNote
Si
avg_wait_timeelle affiche une valeur négative, il s’agit d’une requête parallèle.Si vous pouvez exécuter la requête à la demande dans SQL Server Management Studio (SSMS) ou Azure Data Studio, exécutez-la avec SET STATISTICS TIME
ONet SET STATISTICS IOON.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFFEnsuite, à partir de Messages, vous verrez le temps processeur, le temps écoulé et les lectures logiques comme suit :
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.Si vous pouvez collecter un plan de requête, vérifiez les données des propriétés du plan d’exécution.
Exécutez la requête avec inclure le plan d’exécution réel activé.
Sélectionnez l’opérateur le plus à gauche dans le plan d’exécution.
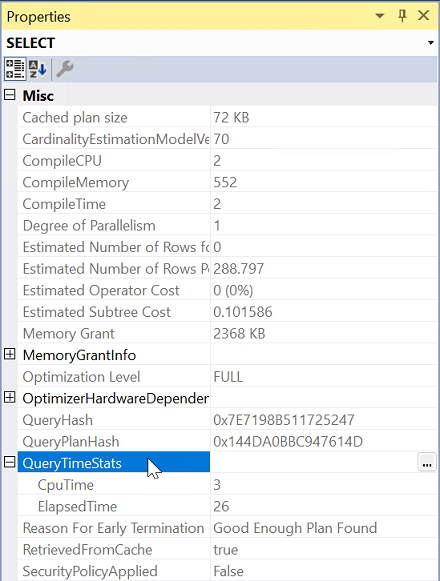
À partir des propriétés, développez la propriété QueryTimeStats .
Vérifiez l’heure écoulée et cpuTime.
Exécution et attente : pourquoi les requêtes sont-elles lentes ?
Si vous trouvez des requêtes qui dépassent votre seuil prédéfini, examinez pourquoi elles pourraient être lentes. La cause des problèmes de performances peut être regroupée en deux catégories, en cours d’exécution ou en attente :
EN ATTENTE : Les requêtes peuvent être lentes, car elles attendent un goulot d’étranglement pendant longtemps. Consultez la liste détaillée des goulots d’étranglement dans les types d’attente.
EXÉCUTION : Les requêtes peuvent être lentes, car elles s’exécutent (en cours d’exécution) pendant une longue période. En d’autres termes, ces requêtes utilisent activement des ressources processeur.
Une requête peut être en cours d’exécution pendant un certain temps et en attente pendant un certain temps au cours de sa durée de vie. Toutefois, votre objectif est de déterminer quelle est la catégorie dominante qui contribue à son temps écoulé long. Ainsi, la première tâche consiste à établir la catégorie à laquelle appartiennent les requêtes. C’est simple : si une requête n’est pas en cours d’exécution, elle attend. Idéalement, une requête passe la plupart de son temps écoulé dans un état d’exécution et très peu de temps en attente de ressources. En outre, dans le meilleur cas, une requête s’exécute au sein ou en dessous d’une base de référence prédéterminée. Comparez le temps écoulé et le temps processeur de la requête pour déterminer le type de problème.
Type 1 : lié au processeur (exécuteur)
Si le temps processeur est proche, égal ou supérieur au temps écoulé, vous pouvez le traiter comme une requête liée au processeur. Par exemple, si le temps écoulé est de 3 000 millisecondes (ms) et que le temps processeur est de 2900 ms, cela signifie que la plupart du temps écoulé est consacré au processeur. Nous pouvons ensuite dis-le’s une requête liée au processeur.
Exemples de requêtes en cours d’exécution (liées au processeur) :
| Temps écoulé (ms) | Temps processeur (ms) | Lectures (logiques) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1 000 | 20 |
Les lectures logiques - lecture de pages de données/d’index dans le cache - sont les pilotes de l’utilisation du processeur dans SQL Server. Il peut y avoir des scénarios où l’utilisation du processeur provient d’autres sources : une boucle while (dans T-SQL ou d’autres codes tels que XProcs ou sql CRL). Le deuxième exemple du tableau illustre un tel scénario, où la majorité de l’UC ne provient pas de lectures.
Note
Si le temps processeur est supérieur à la durée, cela indique qu’une requête parallèle est exécutée ; plusieurs threads utilisent le processeur en même temps. Pour plus d’informations, consultez Requêtes parallèles - Exécuteur ou serveur.
Type 2 : Attente sur un goulot d’étranglement (serveur)
Une requête attend un goulot d’étranglement si le temps écoulé est nettement supérieur au temps processeur. Le temps écoulé inclut le temps d’exécution de la requête sur le processeur (temps processeur) et le temps d’attente d’une ressource à libérer (temps d’attente). Par exemple, si le temps écoulé est de 2000 ms et que le temps processeur est de 300 ms, le temps d’attente est de 1700 ms (2000 - 300 = 1700). Pour plus d’informations, consultez Types d’attente.
Exemples de requêtes en attente :
| Temps écoulé (ms) | Temps processeur (ms) | Lectures (logiques) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
Requêtes parallèles - Exécuteur ou serveur
Les requêtes parallèles peuvent utiliser plus de temps processeur que la durée globale. L’objectif du parallélisme est de permettre à plusieurs threads d’exécuter simultanément des parties d’une requête. Dans une seconde de temps d’horloge, une requête peut utiliser huit secondes de temps processeur en exécutant huit threads parallèles. Par conséquent, il devient difficile de déterminer une requête liée au processeur ou en attente en fonction du temps écoulé et de la différence de temps processeur. Toutefois, en règle générale, suivez les principes répertoriés dans les deux sections ci-dessus. Le résumé est le suivant :
- Si le temps écoulé est beaucoup plus élevé que le temps processeur, considérez-le comme un serveur.
- Si le temps processeur est beaucoup plus élevé que le temps écoulé, considérez-le comme un exécuteur.
Exemples de requêtes parallèles :
| Temps écoulé (ms) | Temps processeur (ms) | Lectures (logiques) |
|---|---|---|
| 1 200 | 8100 | 850 000 |
| 3080 | 12300 | 1500000 |
Représentation visuelle générale de la méthodologie

Diagnostiquer et résoudre des requêtes en attente
Si vous avez établi que vos requêtes d’intérêt sont des serveurs d’attente, l’étape suivante consiste à vous concentrer sur la résolution des problèmes de goulot d’étranglement. Sinon, accédez à l’étape 4 : Diagnostiquer et résoudre les requêtes en cours d’exécution.
Pour optimiser une requête qui attend des goulots d’étranglement, identifiez la durée d’attente et l’emplacement du goulot d’étranglement (type d’attente). Une fois le type d’attente confirmé, réduisez le temps d’attente ou éliminez complètement l’attente.
Pour calculer le temps d’attente approximatif, soustrayez le temps processeur (temps de travail) du temps écoulé d’une requête. En règle générale, le temps processeur est le temps d’exécution réel et la partie restante de la durée de vie de la requête est en attente.
Exemples de calcul de la durée d’attente approximative :
| Temps écoulé (ms) | Temps processeur (ms) | Temps d’attente (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1 000 | 6080 |
Identifier le goulot d’étranglement ou attendre
Pour identifier les requêtes d’attente longue historiques (par exemple, >20 % du temps d’attente total écoulé) exécutent la requête suivante. Cette requête utilise des statistiques de performances pour les plans de requête mis en cache depuis le début de SQL Server.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCPour identifier les requêtes en cours d’exécution avec des attentes supérieures à 500 ms, exécutez la requête suivante :
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Si vous pouvez collecter un plan de requête, vérifiez WaitStats à partir des propriétés du plan d’exécution dans SSMS :
- Exécutez la requête avec inclure le plan d’exécution réel activé.
- Cliquez avec le bouton droit sur l’opérateur le plus à gauche dans l’onglet Plan d’exécution
- Sélectionnez Propriétés , puis propriété WaitStats .
- Vérifiez les waitTimeMs et WaitType.
Si vous connaissez les scénarios PSSDiag/SQLdiag ou SQL LogScout LightPerf/GeneralPerf, envisagez d’utiliser l’un d’eux pour collecter des statistiques de performances et identifier les requêtes en attente sur votre instance SQL Server. Vous pouvez importer les fichiers de données collectés et analyser les données de performances avec SQL Nexus.
Références pour éliminer ou réduire les attentes
Les causes et les résolutions de chaque type d’attente varient. Il n’existe aucune méthode générale pour résoudre tous les types d’attente. Voici des articles pour résoudre et résoudre les problèmes courants liés au type d’attente :
- Comprendre et résoudre les problèmes de blocage (LCK_M_*)
- Comprendre et résoudre les problèmes de blocage d’Azure SQL Database
- Résoudre les problèmes de performances lentes de SQL Server causés par des problèmes d’E/S (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- Résoudre l’insertion de la dernière page PAGELATCH_EX contention dans SQL Server
- Mémoire accorde des explications et des solutions (RESOURCE_SEMAPHORE)
- Résoudre les problèmes de requêtes lentes résultant de ASYNC_NETWORK_IO type d’attente
- Résolution des problèmes liés au type d’attente haute HADR_SYNC_COMMIT avec les groupes de disponibilité Always On
- Fonctionnement : CMEMTHREAD et débogage
- Rendre les attentes parallélisme exploitables (CXPACKET et CXCONSUMER)
- Attente THREADPOOL
Pour obtenir des descriptions de nombreux types d’attente et de ce qu’ils indiquent, consultez le tableau dans Types d’attente.
Diagnostiquer et résoudre des requêtes en cours d’exécution
Si le temps processeur (worker) est très proche de la durée totale écoulée, la requête passe la majeure partie de sa durée de vie en cours d’exécution. En règle générale, lorsque le moteur SQL Server pilote une utilisation élevée du processeur, l’utilisation élevée de l’UC provient de requêtes qui pilotent un grand nombre de lectures logiques (la raison la plus courante).
Pour identifier les requêtes qui sollicitent fortement l’UC, exécutez l’instruction suivante :
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
Si les requêtes ne sollicitent pas l’UC pour l’instant, vous pouvez exécuter l’instruction suivante pour identifier les requêtes d’historique utilisant le processeur de manière intensive :
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
Méthodes courantes pour résoudre les requêtes longues et consommatrices de ressources processeur
- Examiner le plan de requête de la requête
- Mettre à jour les statistiques
- Identifiez et appliquez les index manquants. Pour plus d’informations sur l’identification des index manquants, consultez Régler les index non cluster avec des suggestions d’index manquantes
- Reconcevoir ou réécrire les requêtes
- Identifier et résoudre les plans sensibles aux paramètres
- Identifier et résoudre les problèmes de capacité SARG
- Identifiez et résolvez les problèmes d’objectif de ligne où des boucles imbriquées longues peuvent être provoquées par TOP, EXISTS, IN, FAST, SET ROWCOUNT, OPTION (FAST N). Pour plus d’informations, consultez Améliorations apportées aux objectifs de ligne non autorisés et showplan - Row Goal EstimateRowsWithoutRowGoal
- Évaluer et résoudre les problèmes d’estimation de cardinalité. Pour plus d’informations, consultez Réduction des performances des requêtes après la mise à niveau de SQL Server 2012 ou version antérieure vers 2014 ou version ultérieure
- Identifier et résoudre les carrières qui ne semblent jamais terminées, voir Résoudre les problèmes de requêtes qui semblent ne jamais se terminer dans SQL Server
- Identifier et résoudre les requêtes lentes affectées par le délai d’expiration de l’optimiseur
- Identifiez les problèmes élevés de performances du processeur. Pour plus d’informations, consultez Résoudre les problèmes d’utilisation élevée du processeur dans SQL Server
- Résoudre les problèmes d’une requête qui montre une différence de performances significative entre deux serveurs
- Augmenter les ressources de calcul sur le système (processeurs)
- Résoudre les problèmes de performances UPDATE avec des plans étroits et larges
Ressources recommandées
- Types détectables de goulots d’étranglement des performances de requêtes dans SQL Server et Azure SQL Managed Instance
- Outils de surveillance et de réglage des performances
- Options de réglage automatique dans SQL Server
- Conseils pour la conception et l’architecture des index
- Résoudre les erreurs d’expiration de la requête
- Résoudre les problèmes d’utilisation élevée du processeur dans SQL Server
- Diminution des performances des requêtes après la mise à niveau de SQL Server 2012 ou antérieur vers 2014 ou ultérieur