Résoudre les problèmes liés aux requêtes lentes affectées par le délai d’expiration de l’optimiseur de requête
S'applique à : SQL Server
Cet article présente le délai d’expiration de l’optimiseur, la façon dont il peut affecter les performances des requêtes et comment optimiser les performances.
Qu’est-ce que le délai d’expiration de l’optimiseur ?
SQL Server utilise un optimiseur de requête basé sur les coûts (QO). Pour plus d’informations sur la qualité de service, consultez le guide d’architecture de traitement des requêtes. Un optimiseur de requête basé sur les coûts sélectionne un plan d’exécution de requête avec le coût le plus bas une fois qu’il a généré et évalué plusieurs plans de requête. L’un des objectifs de l’optimiseur de requête SQL Server consiste à consacrer un temps raisonnable à l’optimisation des requêtes par rapport à l’exécution des requêtes. L’optimisation d’une requête doit être beaucoup plus rapide que son exécution. Pour accomplir cette cible, qo a un seuil intégré de tâches à prendre en compte avant d’arrêter le processus d’optimisation. Lorsque le seuil est atteint avant que la qualité de service ait pris en compte tous les plans possibles, elle atteint la limite de délai d’expiration de l’optimiseur. Un événement de délai d’expiration de l’optimiseur est signalé dans le plan de requête en tant que délai d’expiration sous Raison de l’arrêt anticipé de l’optimisation des instructions. Il est important de comprendre que ce seuil n’est pas basé sur l’heure de l’horloge, mais sur le nombre de possibilités prises en compte par l’optimiseur. Dans les versions actuelles de la qualité de service SQL Server, plus d’un demi-million de tâches sont prises en compte avant qu’un délai d’expiration soit atteint.
Le délai d’expiration de l’optimiseur est conçu dans SQL Server et, dans de nombreux cas, il n’est pas un facteur affectant les performances des requêtes. Toutefois, dans certains cas, le choix du plan de requête SQL peut être affecté négativement par le délai d’expiration de l’optimiseur et les performances des requêtes plus lentes peuvent entraîner. Lorsque vous rencontrez de tels problèmes, comprendre le mécanisme de délai d’expiration de l’optimiseur et la façon dont les requêtes complexes peuvent être affectées peuvent vous aider à résoudre les problèmes et à améliorer la vitesse de votre requête.
Le résultat de l’atteinte du seuil de délai d’expiration de l’optimiseur est que SQL Server n’a pas considéré l’ensemble des possibilités d’optimisation. Autrement dit, il peut avoir manqué des plans qui pourraient produire des temps d’exécution plus courts. La qualité de service s’arrête au seuil et prend en compte le plan de requête le moins coûteux à ce stade, même s’il peut y avoir de meilleures options non explosées. N’oubliez pas que le plan sélectionné après qu’un délai d’attente d’optimiseur est atteint peut produire une durée d’exécution raisonnable pour la requête. Toutefois, dans certains cas, le plan sélectionné peut entraîner une exécution de requête qui n’est pas optimale.
Comment détecter un délai d’expiration de l’optimiseur ?
Voici les symptômes qui indiquent un délai d’expiration de l’optimiseur :
Requête complexe
Vous avez une requête complexe qui implique un grand nombre de tables jointes (par exemple, huit tables ou plus sont jointes).
Requête lente
La requête peut s’exécuter lentement ou plus lentement qu’elle ne s’exécute sur une autre version ou système SQL Server.
Le plan de requête affiche StatementOptmEarlyAbortReason=Timeout
Le plan de requête s’affiche
StatementOptmEarlyAbortReason="TimeOut"dans le plan de requête XML.<?xml version="1.0" encoding="utf-16"?> <ShowPlanXML xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" Version="1.518" Build="13.0.5201.2" xmlns="http://schemas.microsoft.com/sqlserver/2004/07/showplan"> <BatchSequence> <Batch> <Statements> <StmtSimple ..." StatementOptmLevel="FULL" StatementOptmEarlyAbortReason="TimeOut" ......> ... <Statements> <Batch> <BatchSequence>Vérifiez les propriétés de l’opérateur de plan le plus à gauche dans Microsoft SQL Server Management Studio. Vous pouvez voir la valeur de Reason For Early Termination of Statement Optimization is TimeOut.
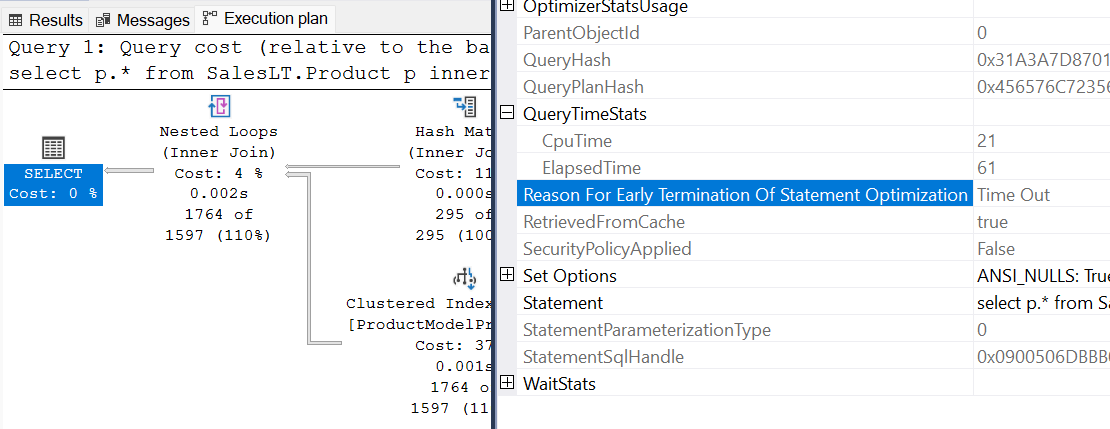
Qu’est-ce qui provoque un délai d’expiration de l’optimiseur ?
Il n’existe aucun moyen simple de déterminer quelles conditions entraîneraient l’atteinte ou le dépassement du seuil de l’optimiseur. Les sections suivantes sont quelques facteurs qui affectent le nombre de plans explorés par qo lorsque vous recherchez le meilleur plan.
Dans quel ordre les tables doivent-elles être jointes ?
Voici un exemple des options d’exécution de jointures à trois tables (
Table1, ,Table2Table3) :- Joindre
Table1avecTable2et le résultat avecTable3 - Joindre
Table1avecTable3et le résultat avecTable2 - Joindre
Table2avecTable3et le résultat avecTable1
Remarque : Plus le nombre de tables est élevé, plus les possibilités sont grandes.
- Joindre
Quelle structure d’accès au tas ou à l’arborescence binaire (HoBT) à utiliser pour récupérer les lignes d’une table ?
- Index cluster
- Index non cluster1
- Index non cluster2
- Tas de tables
Quelle méthode d’accès physique utiliser ?
- Recherche d'index
- Analyse d’index
- Analyse de table
Quel opérateur de jointure physique utiliser ?
- Jointure de boucles imbriquées (NJ)
- Jointure de hachage (HJ)
- Jointure de fusion (MJ)
- Jointure adaptative (à partir de SQL Server 2017 (14.x))
Pour plus d’informations, consultez Jointures.
Exécuter des parties de la requête en parallèle ou en série ?
Pour plus d’informations, consultez Traitement des requêtes parallèles.
Bien que les facteurs suivants réduisent le nombre de méthodes d’accès prises en compte et ainsi les possibilités prises en compte :
- Prédicats de requête (filtres dans la
WHEREclause) - Existences de contraintes
- Combinaisons de statistiques bien conçues et à jour
Remarque : le fait que la qualité de service atteint le seuil ne signifie pas qu’elle finira par une requête plus lente. Dans la plupart des cas, la requête s’exécute correctement, mais dans certains cas, vous pouvez voir une exécution de requête plus lente.
Exemple de la façon dont les facteurs sont considérés
Pour illustrer, prenons un exemple de jointure entre trois tables (t1, t2et t3) et chaque table a un index cluster et un index non cluster.
Tout d’abord, tenez compte des types de jointure physique. Il y a deux jointures ici. Et, étant donné qu’il existe trois possibilités de jointure physique (NJ, HJ et MJ), la requête peut être effectuée de 32 = 9 façons.
- NJ - NJ
- NJ - HJ
- NJ - MJ
- HJ - NJ
- HJ - HJ
- HJ - MJ
- MJ - NJ
- MJ - HJ
- MJ - MJ
Ensuite, considérez l’ordre de jointure, calculé à l’aide de Permutations : P (n, r). L’ordre des deux premières tables n’a pas d’importance, il peut donc y avoir P(3,1) = 3 possibilités :
- Rejoindre
t1avect2, puis avect3 - Rejoindre
t1avect3, puis avect2 - Rejoindre
t2avect3, puis avect1
Ensuite, considérez les index cluster et non cluster qui peuvent être utilisés pour la récupération des données. En outre, pour chaque index, nous avons deux méthodes d’accès, rechercher ou analyser. Cela signifie que, pour chaque table, il existe 22 = 4 choix. Nous avons trois tables, donc il peut y avoir 43 = 64 choix.
Enfin, compte tenu de toutes ces conditions, il peut y avoir 9*3*64 = 1728 plans possibles.
Supposons maintenant qu’il existe n tables jointes à la requête, et chaque table a un index cluster et un index non cluster. Considérons les facteurs suivants :
- Commandes de jointure : P(n,n-2) = n !/2
- Types de jointure : 3n-1
- Différents types d’index avec des méthodes de recherche et d’analyse : 4n
Multipliez toutes ces valeurs ci-dessus, et nous pouvons obtenir le nombre de plans possibles : 2*n !*12n-1. Quand n = 4, le nombre est de 82 944. Quand n = 6, le nombre est de 358 318 080. Par conséquent, avec l’augmentation du nombre de tables impliquées dans une requête, le nombre de plans possibles augmente géométriquement. En outre, si vous incluez la possibilité de parallélisme et d’autres facteurs, vous pouvez imaginer combien de plans possibles seront pris en compte. Par conséquent, une requête avec un grand nombre de jointures est plus susceptible d’atteindre le seuil de délai d’expiration de l’optimiseur qu’une avec moins de jointures.
Notez que les calculs ci-dessus illustrent le pire scénario. Comme nous l’avons souligné, il existe des facteurs qui réduisent le nombre de possibilités, telles que les prédicats de filtre, les statistiques et les contraintes. Par exemple, un prédicat de filtre et des statistiques mises à jour réduit le nombre de méthodes d’accès physique, car il peut être plus efficace d’utiliser une recherche d’index qu’une analyse. Cela entraînera également une sélection plus petite de jointures, et ainsi de suite.
Pourquoi voir un délai d’expiration d’optimiseur avec une requête simple ?
Rien avec l’optimiseur de requête n’est simple. Il existe de nombreux scénarios possibles, et le degré de complexité est si élevé qu’il est difficile de saisir toutes les possibilités. L’optimiseur de requête peut définir dynamiquement le seuil d’expiration en fonction du coût du plan trouvé à une certaine étape. Par exemple, si un plan qui apparaît relativement efficace est trouvé, la limite de tâches pour rechercher un meilleur plan peut être réduite. Par conséquent, l’estimation de cardinalité sous-estimée (CE) peut être un scénario pour atteindre un délai d’expiration de l’optimiseur tôt. Dans ce cas, le focus de l’enquête est CE. Il s’agit d’un cas plus rare que le scénario d’exécution d’une requête complexe décrite dans la section précédente, mais il est possible.
Résolutions
Un délai d’expiration de l’optimiseur apparaissant dans un plan de requête ne signifie pas nécessairement qu’il s’agit de la cause des performances des requêtes médiocres. Dans la plupart des cas, vous n’avez peut-être pas besoin de faire quoi que ce soit à ce sujet. Le plan de requête avec lequel SQL Server se termine peut être raisonnable et la requête que vous exécutez peut fonctionner correctement. Vous ne savez peut-être jamais que vous avez rencontré un délai d’expiration de l’optimiseur.
Essayez les étapes suivantes si vous trouvez la nécessité de régler et d’optimiser.
Étape 1 : Établir une base de référence
Vérifiez si vous pouvez exécuter la même requête avec le même jeu de données sur une autre build de SQL Server, à l’aide d’une configuration CE différente ou sur un autre système (spécifications matérielles). Un principe guidant dans le réglage des performances est « il n’y a aucun problème de performances sans base de référence ». Par conséquent, il serait important d’établir une base de référence pour la même requête.
Étape 2 : Rechercher des conditions « masquées » qui mènent au délai d’expiration de l’optimiseur
Examinez votre requête en détail pour déterminer sa complexité. Lors de l’examen initial, il n’est peut-être pas évident que la requête est complexe et implique de nombreuses jointures. Voici un scénario courant : les vues ou les fonctions table sont impliquées. Par exemple, sur la surface, la requête peut sembler simple, car elle joint deux vues. Toutefois, lorsque vous examinez les requêtes à l’intérieur des vues, vous pouvez constater que chaque vue joint sept tables. Par conséquent, lorsque les deux vues sont jointes, vous finissent par une jointure de 14 tables. Si votre requête utilise les objets suivants, explorez chaque objet pour voir à quoi ressemblent les requêtes sous-jacentes à l’intérieur :
- Vues
- Fonctions table (TFV)
- Sous-requêtes ou tables dérivées
- Expressions de table courantes (CTEs)
- Opérateurs UNION
Pour tous ces scénarios, la résolution la plus courante consiste à réécrire la requête et à la décomposer en plusieurs requêtes. Consultez l’étape 7 : Affiner la requête pour plus d’informations.
Sous-requêtes ou tables dérivées
La requête suivante est un exemple qui joint deux ensembles distincts de requêtes (tables dérivées) avec des jointures de 4 à 5 dans chacune d’elles. Toutefois, après l’analyse par SQL Server, elle sera compilée en une seule requête avec huit tables jointes.
SELECT ...
FROM
( SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
) AS derived_table1
INNER JOIN
( SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
) AS derived_table2
ON derived_table1.Co1 = derived_table2.Co10
AND derived_table1.Co2 = derived_table2.Co20
Expressions de table courantes (CTEs)
L’utilisation de plusieurs expressions de table courantes (CTEs) n’est pas une solution appropriée pour simplifier une requête et éviter le délai d’expiration de l’optimiseur. Plusieurs CTE n’augmenteront que la complexité de la requête. Par conséquent, il est contre-productif d’utiliser des CTE lors de la résolution des délais d’expiration de l’optimiseur. Les CTE ressemblent à interrompre une requête logiquement, mais elles seront combinées en une seule requête et optimisées comme une seule jointure volumineuse de tables.
Voici un exemple d’un CTE qui sera compilé en tant que requête unique avec de nombreuses jointures. Il peut apparaître que la requête sur la my_cte est une jointure simple à deux objets, mais en fait, il existe sept autres tables jointes dans l’objet CTE.
WITH my_cte AS (
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
WHERE ... )
SELECT ...
FROM my_cte
JOIN t8 ON ...
Vues
Vérifiez que vous avez vérifié les définitions d’affichage et obtenu toutes les tables impliquées. Comme pour les tables CTEs et dérivées, les jointures peuvent être masquées à l’intérieur des vues. Par exemple, une jointure entre deux vues peut finalement être une requête unique avec huit tables impliquées :
CREATE VIEW V1 AS
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
GO
CREATE VIEW V2 AS
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
GO
SELECT ...
FROM V1
JOIN V2 ON ...
Fonctions table (TVF)
Certaines jointures peuvent être masquées dans les TFV. L’exemple suivant montre ce qui apparaît comme une jointure entre deux tfv, et une table peut être une jointure à neuf tables.
CREATE FUNCTION tvf1() RETURNS TABLE
AS RETURN
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
GO
CREATE FUNCTION tvf2() RETURNS TABLE
AS RETURN
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
GO
SELECT ...
FROM tvf1()
JOIN tvf2() ON ...
JOIN t9 ON ...
Union
Les opérateurs union combinent les résultats de plusieurs requêtes dans un jeu de résultats unique. Ils combinent également plusieurs requêtes en une seule requête. Vous pouvez ensuite obtenir une requête unique et complexe. L’exemple suivant se termine par un plan de requête unique qui implique 12 tables.
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
UNION ALL
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
UNION ALL
SELECT ...
FROM t9
JOIN t10 ON ...
JOIN t11 ON ...
JOIN t12 ON ...
Étape 3 : Si vous avez une requête de référence qui s’exécute plus rapidement, utilisez son plan de requête
Si vous déterminez qu’un plan de référence particulier que vous obtenez à l’étape 1 est préférable à votre requête via le test, utilisez l’une des options suivantes pour forcer la qualité de service à sélectionner ce plan :
- procédure stockée Magasin des requêtes (QDS)
- Indicateur de requête : OPTION (USE PLAN N’XML_Plan<>')
- Repères de plan
Étape 4 : Réduire les choix de plans
Pour réduire la probabilité d’un délai d’expiration de l’optimiseur, essayez de réduire les possibilités dont la qualité de service a besoin pour choisir un plan. Ce processus implique de tester la requête avec différentes options d’indicateur. Comme pour la plupart des décisions avec qo, les choix ne sont pas toujours déterministes sur la surface, car il existe une grande variété de facteurs à prendre en compte. Par conséquent, il n’existe pas de stratégie garantie unique réussie, et le plan sélectionné peut améliorer ou diminuer les performances de la requête sélectionnée.
Forcer une commande JOIN
Permet OPTION (FORCE ORDER) d’éliminer les permutations d’ordre :
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
OPTION (FORCE ORDER)
Réduire les possibilités JOIN
Si d’autres alternatives n’ont pas aidé, essayez de réduire les combinaisons de plans de requête en limitant les choix d’opérateurs de jointures physiques avec des indicateurs de jointure. Par exemple : OPTION (HASH JOIN, MERGE JOIN), OPTION (HASH JOIN, LOOP JOIN) ou OPTION (MERGE JOIN).
Remarque : Vous devez être prudent lors de l’utilisation de ces indicateurs.
Dans certains cas, la limitation de l’optimiseur avec moins de choix de jointure peut entraîner la meilleure option de jointure non disponible et peut réellement ralentir la requête. En outre, dans certains cas, une jointure spécifique est requise par un optimiseur (par exemple, l’objectif de ligne) et la requête peut échouer à générer un plan si cette jointure n’est pas une option. Par conséquent, après avoir ciblé les indicateurs de jointure pour une requête spécifique, vérifiez si vous trouvez une combinaison qui offre de meilleures performances et élimine le délai d’expiration de l’optimiseur.
Voici deux exemples d’utilisation de ces indicateurs :
Permet
OPTION (HASH JOIN, LOOP JOIN)d’autoriser uniquement les jointures de hachage et de boucle et d’éviter la jointure de fusion dans la requête :SELECT ... FROM t1 JOIN t2 ON ... JOIN t3 ON ... JOIN t4 ON ... JOIN t5 ON ... OPTION (HASH JOIN, LOOP JOIN)Appliquez une jointure spécifique entre deux tables :
SELECT ... FROM t1 INNER MERGE JOIN t2 ON ... JOIN t3 ON ... JOIN t4 ON ... JOIN t5 ON ...
Étape 5 : Modifier la configuration CE
Essayez de modifier la configuration CE en basculant entre la version CE héritée et le nouveau ce. La modification de la configuration CE peut entraîner la sélection d’un chemin différent lorsque SQL Server évalue et crée des plans de requête. Ainsi, même si un problème de délai d’expiration de l’optimiseur se produit, il est possible que vous finissent par un plan qui s’exécute de manière plus optimale que celui sélectionné à l’aide de la configuration CE alternative. Pour plus d’informations, consultez Comment activer le meilleur plan de requête (Estimation de cardinalité).
Étape 6 : Activer les correctifs optimizer
Si vous n’avez pas activé les correctifs de l’optimiseur de requête, envisagez de les activer à l’aide de l’une des deux méthodes suivantes :
- Niveau du serveur : utilisez l’indicateur de trace T4199.
- Niveau de base de données : utilisez
ALTER DATABASE SCOPED CONFIGURATION ..QUERY_OPTIMIZER_HOTFIXES = ONou modifiez les niveaux de compatibilité de base de données pour SQL Server 2016 et versions ultérieures.
Les correctifs qo peuvent entraîner la prise d’un chemin différent dans l’exploration du plan. Par conséquent, il peut choisir un plan de requête plus optimal. Pour plus d’informations, consultez le modèle de maintenance du correctif logiciel de l’optimiseur de requête SQL Server 4199.
Étape 7 : Affiner la requête
Envisagez de diviser la requête à plusieurs tables en plusieurs requêtes distinctes à l’aide de tables temporaires. La séparation de la requête n’est qu’une des façons de simplifier la tâche pour l’optimiseur. Voir l’exemple suivant :
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
Pour optimiser la requête, essayez de décomposer la requête unique en deux requêtes en insérant une partie de la jointure dans une table temporaire :
SELECT ...
INTO #temp1
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
GO
SELECT ...
FROM #temp1
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...