Résoudre les problèmes d’une requête qui montre une différence de performances significative entre deux serveurs
S'applique à : SQL Server
Cet article fournit des étapes de dépannage pour un problème de performances où une requête s’exécute plus lentement sur un serveur que sur un autre serveur.
Symptômes
Supposons qu’il existe deux serveurs avec SQL Server installé. L’une des instances SQL Server contient une copie d’une base de données dans l’autre instance SQL Server. Lorsque vous exécutez une requête sur les bases de données sur les deux serveurs, la requête s’exécute plus lentement sur un serveur que l’autre.
Les étapes suivantes peuvent vous aider à résoudre ce problème.
Étape 1 : Déterminer s’il s’agit d’un problème courant avec plusieurs requêtes
Utilisez l’une des deux méthodes suivantes pour comparer les performances pour deux requêtes ou plus sur les deux serveurs :
Testez manuellement les requêtes sur les deux serveurs :
- Choisissez plusieurs requêtes pour les tests avec priorité placées sur les requêtes suivantes :
- Beaucoup plus rapide sur un serveur que sur l’autre.
- Important pour l’utilisateur/l’application.
- Fréquemment exécuté ou conçu pour reproduire le problème à la demande.
- Suffisamment longtemps pour capturer des données (par exemple, au lieu d’une requête de 5 millisecondes, choisissez une requête de 10 secondes).
- Exécutez les requêtes sur les deux serveurs.
- Comparez le temps écoulé (durée) sur deux serveurs pour chaque requête.
- Choisissez plusieurs requêtes pour les tests avec priorité placées sur les requêtes suivantes :
Analysez les données de performances avec SQL Nexus.
- Collectez les données PSSDiag/SQLdiag ou SQL LogScout pour les requêtes sur les deux serveurs.
- Importez les fichiers de données collectés avec SQL Nexus et comparez les requêtes des deux serveurs. Pour plus d’informations, consultez Comparaison des performances entre deux collections de journaux (Lente et Rapide, par exemple).
Scénario 1 : une seule requête s’effectue différemment sur les deux serveurs
Si une seule requête s’effectue différemment, le problème est plus susceptible d’être spécifique à la requête individuelle plutôt qu’à l’environnement. Dans ce cas, accédez à l’étape 2 : Collecter des données et déterminer le type de problème de performances.
Scénario 2 : Plusieurs requêtes s’exécutent différemment sur les deux serveurs
Si plusieurs requêtes s’exécutent plus lentement sur un serveur que l’autre, la cause la plus probable est les différences entre le serveur ou l’environnement de données. Accédez à Diagnostiquer les différences d’environnement et vérifiez si la comparaison entre les deux serveurs est valide.
Étape 2 : Collecter des données et déterminer le type de problème de performances
Collecter le temps écoulé, le temps processeur et les lectures logiques
Pour collecter le temps écoulé et le temps processeur de la requête sur les deux serveurs, utilisez l’une des méthodes suivantes qui correspondent le mieux à votre situation :
Pour les instructions en cours d’exécution, vérifiez les colonnes total_elapsed_time et cpu_time dans sys.dm_exec_requests. Exécutez la requête suivante pour obtenir les données :
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;Pour les exécutions passées de la requête, vérifiez les colonnes last_elapsed_time et last_worker_time dans sys.dm_exec_query_stats. Exécutez la requête suivante pour obtenir les données :
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCNote
Si
avg_wait_timeelle affiche une valeur négative, il s’agit d’une requête parallèle.Si vous pouvez exécuter la requête à la demande dans SQL Server Management Studio (SSMS) ou Azure Data Studio, exécutez-la avec SET STATISTICS TIME
ONet SET STATISTICS IOON.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFFEnsuite, à partir de Messages, vous verrez le temps processeur, le temps écoulé et les lectures logiques comme suit :
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.Si vous pouvez collecter un plan de requête, vérifiez les données des propriétés du plan d’exécution.
Exécutez la requête avec inclure le plan d’exécution réel activé.
Sélectionnez l’opérateur le plus à gauche dans le plan d’exécution.
À partir des propriétés, développez la propriété QueryTimeStats .
Vérifiez l’heure écoulée et cpuTime.
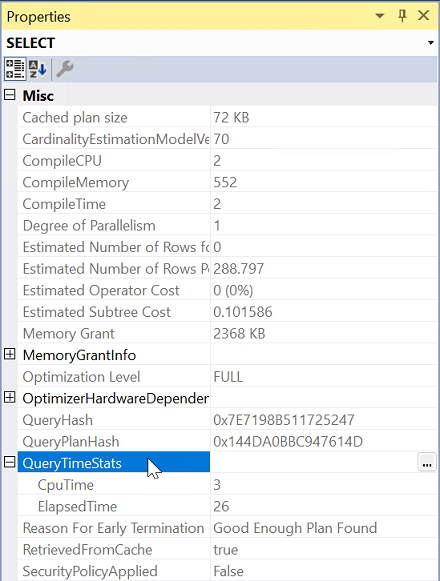
Comparez le temps écoulé et le temps processeur de la requête pour déterminer le type de problème pour les deux serveurs.
Type 1 : lié au processeur (exécuteur)
Si le temps processeur est proche, égal ou supérieur au temps écoulé, vous pouvez le traiter comme une requête liée au processeur. Par exemple, si le temps écoulé est de 3 000 millisecondes (ms) et que le temps processeur est de 2900 ms, cela signifie que la plupart du temps écoulé est consacré au processeur. Nous pouvons ensuite dis-le’s une requête liée au processeur.
Exemples de requêtes en cours d’exécution (liées au processeur) :
| Temps écoulé (ms) | Temps processeur (ms) | Lectures (logiques) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1 000 | 20 |
Les lectures logiques - lecture de pages de données/d’index dans le cache - sont les pilotes de l’utilisation du processeur dans SQL Server. Il peut y avoir des scénarios où l’utilisation du processeur provient d’autres sources : une boucle while (dans T-SQL ou d’autres codes tels que XProcs ou sql CRL). Le deuxième exemple du tableau illustre un tel scénario, où la majorité de l’UC ne provient pas de lectures.
Note
Si le temps processeur est supérieur à la durée, cela indique qu’une requête parallèle est exécutée ; plusieurs threads utilisent le processeur en même temps. Pour plus d’informations, consultez Requêtes parallèles - Exécuteur ou serveur.
Type 2 : Attente sur un goulot d’étranglement (serveur)
Une requête attend un goulot d’étranglement si le temps écoulé est nettement supérieur au temps processeur. Le temps écoulé inclut le temps d’exécution de la requête sur le processeur (temps processeur) et le temps d’attente d’une ressource à libérer (temps d’attente). Par exemple, si le temps écoulé est de 2000 ms et que le temps processeur est de 300 ms, le temps d’attente est de 1700 ms (2000 - 300 = 1700). Pour plus d’informations, consultez Types d’attente.
Exemples de requêtes en attente :
| Temps écoulé (ms) | Temps processeur (ms) | Lectures (logiques) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
Requêtes parallèles - Exécuteur ou serveur
Les requêtes parallèles peuvent utiliser plus de temps processeur que la durée globale. L’objectif du parallélisme est de permettre à plusieurs threads d’exécuter simultanément des parties d’une requête. Dans une seconde de temps d’horloge, une requête peut utiliser huit secondes de temps processeur en exécutant huit threads parallèles. Par conséquent, il devient difficile de déterminer une requête liée au processeur ou en attente en fonction du temps écoulé et de la différence de temps processeur. Toutefois, en règle générale, suivez les principes répertoriés dans les deux sections ci-dessus. Le résumé est le suivant :
- Si le temps écoulé est beaucoup plus élevé que le temps processeur, considérez-le comme un serveur.
- Si le temps processeur est beaucoup plus élevé que le temps écoulé, considérez-le comme un exécuteur.
Exemples de requêtes parallèles :
| Temps écoulé (ms) | Temps processeur (ms) | Lectures (logiques) |
|---|---|---|
| 1 200 | 8100 | 850 000 |
| 3080 | 12300 | 1500000 |
Étape 3 : comparer les données des deux serveurs, déterminer le scénario et résoudre le problème
Supposons qu’il existe deux machines nommées Server1 et Server2. Et la requête s’exécute plus lentement sur Server1 que sur Server2. Comparez les heures des deux serveurs, puis suivez les actions du scénario qui correspond le mieux à la vôtre à partir des sections suivantes.
Scénario 1 : La requête sur Server1 utilise plus de temps processeur et les lectures logiques sont plus élevées sur Server1 que sur Server2
Si le temps processeur sur Server1 est beaucoup plus élevé que sur Server2 et que le temps écoulé correspond étroitement au temps processeur sur les deux serveurs, il n’y a pas d’attente ou de goulots d’étranglement majeurs. L’augmentation du temps processeur sur Server1 est probablement due à une augmentation des lectures logiques. Une modification significative des lectures logiques indique généralement une différence dans les plans de requête. Par exemple :
| Serveur | Temps écoulé (ms) | Temps processeur (ms) | Lectures (logiques) |
|---|---|---|---|
| Serveur1 | 3100 | 3000 | 300000 |
| Serveur2 | 1100 | 1 000 | 90200 |
Action : Vérifier les plans d’exécution et les environnements
- Comparez les plans d’exécution de la requête sur les deux serveurs. Pour ce faire, utilisez l’une des deux méthodes suivantes :
- Comparez visuellement les plans d’exécution. Pour plus d’informations, consultez Afficher un plan d’exécution réel.
- Enregistrez les plans d’exécution et comparez-les à l’aide de la fonctionnalité de comparaison des plans SQL Server Management Studio.
- Comparez les environnements. Différents environnements peuvent entraîner des différences de plan de requête ou des différences directes dans l’utilisation du processeur. Les environnements incluent les versions du serveur, les paramètres de configuration de la base de données ou du serveur, les indicateurs de trace, le nombre d’UC ou la vitesse d’horloge, et la machine virtuelle par rapport à la machine physique. Pour plus d’informations, consultez Diagnostiquer les différences de plan de requête.
Scénario 2 : La requête est un serveur sur Server1, mais pas sur Server2
Si les temps processeur de la requête sur les deux serveurs sont similaires, mais que le temps écoulé sur Server1 est beaucoup plus élevé que sur Server2, la requête sur Server1 passe beaucoup plus de temps en attente sur un goulot d’étranglement. Par exemple :
| Serveur | Temps écoulé (ms) | Temps processeur (ms) | Lectures (logiques) |
|---|---|---|---|
| Serveur1 | 4500 | 1 000 | 90200 |
| Serveur2 | 1100 | 1 000 | 90200 |
- Temps d’attente sur Server1 : 4500 - 1000 = 3500 ms
- Temps d’attente sur Server2 : 1100 - 1000 = 100 ms
Action : Vérifier les types d’attente sur Server1
Identifiez et éliminez le goulot d’étranglement sur Server1. Des exemples d’attente bloquent (attentes de verrou), attendent le verrou, les attentes d’E/S de disque, les attentes réseau et les attentes de mémoire. Pour résoudre les problèmes courants de goulot d’étranglement, passez à Diagnostiquer les attentes ou les goulots d’étranglement.
Scénario 3 : Les requêtes sur les deux serveurs sont des serveurs, mais les types d’attente ou les heures sont différents
Par exemple :
| Serveur | Temps écoulé (ms) | Temps processeur (ms) | Lectures (logiques) |
|---|---|---|---|
| Serveur1 | 8000 | 1 000 | 90200 |
| Serveur2 | 3000 | 1 000 | 90200 |
- Temps d’attente sur Server1 : 8000 - 1000 = 7000 ms
- Temps d’attente sur Server2 : 3000 - 1000 = 2000 ms
Dans ce cas, les temps processeur sont similaires sur les deux serveurs, ce qui indique que les plans de requête sont probablement identiques. Les requêtes s’exécutent de façon égale sur les deux serveurs s’ils n’attendent pas les goulots d’étranglement. Ainsi, les différences de durée proviennent des différentes quantités de temps d’attente. Par exemple, la requête attend les verrous sur Server1 pour 7000 ms pendant qu’elle attend les E/S sur Server2 pour 2000 ms.
Action : Vérifier les types d’attente sur les deux serveurs
Résolvez chaque goulot d’étranglement individuellement sur chaque serveur et accélérez les exécutions sur les deux serveurs. La résolution de ce problème est gourmande en main-d’œuvre, car vous devez éliminer les goulots d’étranglement sur les deux serveurs et rendre les performances comparables. Pour résoudre les problèmes courants de goulot d’étranglement, passez à Diagnostiquer les attentes ou les goulots d’étranglement.
Scénario 4 : La requête sur Server1 utilise plus de temps processeur que sur Server2, mais les lectures logiques sont proches
Par exemple :
| Serveur | Temps écoulé (ms) | Temps processeur (ms) | Lectures (logiques) |
|---|---|---|---|
| Serveur1 | 3000 | 3000 | 90200 |
| Serveur2 | 1 000 | 1 000 | 90200 |
Si les données correspondent aux conditions suivantes :
- Le temps processeur sur Server1 est beaucoup plus élevé que sur Server2.
- Le temps écoulé correspond au temps processeur de près sur chaque serveur, ce qui indique qu’aucune attente n’est nécessaire.
- Les lectures logiques, généralement le pilote le plus élevé du temps processeur, sont similaires sur les deux serveurs.
Ensuite, le temps processeur supplémentaire provient d’autres activités liées au processeur. Ce scénario est le plus rare de tous les scénarios.
Causes : Suivi, fonctions définies par l’utilisateur et intégration clR
Ce problème peut être dû à :
- Suivi XEvents/SQL Server, en particulier avec le filtrage sur les colonnes de texte (nom de la base de données, nom de connexion, texte de requête, etc.). Si le suivi est activé sur un serveur, mais pas sur l’autre, cela peut être la raison de la différence.
- Fonctions définies par l’utilisateur (UDF) ou autre code T-SQL qui effectue des opérations liées au processeur. Cela est généralement la cause lorsque d’autres conditions sont différentes sur Server1 et Server2, telles que la taille des données, la vitesse de l’horloge du processeur ou le plan d’alimentation.
- Intégration du CLR SQL Server ou procédures stockées étendues (XPs) qui peuvent conduire le processeur, mais qui n’effectuent pas de lectures logiques. Les différences dans les DLL peuvent entraîner des temps processeur différents.
- Différence dans la fonctionnalité SQL Server liée au processeur (par exemple, code de manipulation de chaîne).
Action : Vérifier les traces et les requêtes
Vérifiez les traces sur les deux serveurs pour connaître les éléments suivants :
- S’il existe une trace activée sur Server1, mais pas sur Server2.
- Si une trace est activée, désactivez la trace et réexécutez la requête sur Server1.
- Si la requête s’exécute plus rapidement cette fois, activez la trace en arrière, mais supprimez les filtres de texte de celui-ci, le cas échéant.
Vérifiez si la requête utilise des fonctions définies par l’utilisateur qui effectuent des manipulations de chaînes ou effectuent un traitement approfondi sur les colonnes de données de la
SELECTliste.Vérifiez si la requête contient des boucles, des récursivités de fonction ou des imbrications.
Diagnostiquer les différences d’environnement
Vérifiez les questions suivantes et déterminez si la comparaison entre les deux serveurs est valide.
Les deux instances SQL Server sont-elles de la même version ou de la même build ?
Si ce n’est pas le cas, il peut y avoir des correctifs qui ont provoqué les différences. Exécutez la requête suivante pour obtenir des informations de version sur les deux serveurs :
SELECT @@VERSIONLa quantité de mémoire physique est-elle similaire sur les deux serveurs ?
Si un serveur a 64 Go de mémoire tandis que l’autre a 256 Go de mémoire, cela serait une différence significative. Avec davantage de mémoire disponible pour mettre en cache les pages de données/index et les plans de requête, la requête peut être optimisée différemment en fonction de la disponibilité des ressources matérielles.
Les configurations matérielles liées au processeur sont-elles similaires sur les deux serveurs ? Par exemple :
Le nombre de processeurs varie entre les machines (24 PROCESSEURs sur un ordinateur et 96 processeurs sur l’autre).
Plans d’alimentation : équilibrés et hautes performances.
Machine virtuelle par rapport à la machine physique (nue).
Hyper-V et VMware : différence de configuration.
Différence de vitesse d’horloge (vitesse d’horloge inférieure et vitesse d’horloge supérieure). Par exemple, 2 GHz par rapport à 3,5 GHz peuvent faire une différence. Pour obtenir la vitesse de l’horloge sur un serveur, exécutez la commande PowerShell suivante :
Get-CimInstance Win32_Processor | Select-Object -Expand MaxClockSpeed
Utilisez l’une des deux méthodes suivantes pour tester la vitesse du processeur des serveurs. S’ils ne produisent pas de résultats comparables, le problème se trouve en dehors de SQL Server. Il peut s’agir d’une différence de plan d’alimentation, d’un nombre inférieur de processeurs, d’un problème de logiciel de machine virtuelle ou d’une différence de vitesse d’horloge.
Exécutez le script PowerShell suivant sur les deux serveurs et comparez les sorties.
$bf = [System.DateTime]::Now for ($i = 0; $i -le 20000000; $i++) {} $af = [System.DateTime]::Now Write-Host ($af - $bf).Milliseconds " milliseconds" Write-Host ($af - $bf).Seconds " Seconds"Exécutez le code Transact-SQL suivant sur les deux serveurs et comparez les sorties.
SET NOCOUNT ON DECLARE @spins INT = 0 DECLARE @start_time DATETIME = GETDATE(), @time_millisecond INT WHILE (@spins < 20000000) BEGIN SET @spins = @spins +1 END SELECT @time_millisecond = DATEDIFF(millisecond, @start_time, getdate()) SELECT @spins Spins, @time_millisecond Time_ms, @spins / @time_millisecond Spins_Per_ms
Diagnostiquer les attentes ou les goulots d’étranglement
Pour optimiser une requête qui attend des goulots d’étranglement, identifiez la durée d’attente et l’emplacement du goulot d’étranglement (type d’attente). Une fois le type d’attente confirmé, réduisez le temps d’attente ou éliminez complètement l’attente.
Pour calculer le temps d’attente approximatif, soustrayez le temps processeur (temps de travail) du temps écoulé d’une requête. En règle générale, le temps processeur est le temps d’exécution réel et la partie restante de la durée de vie de la requête est en attente.
Exemples de calcul de la durée d’attente approximative :
| Temps écoulé (ms) | Temps processeur (ms) | Temps d’attente (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1 000 | 6080 |
Identifier le goulot d’étranglement ou attendre
Pour identifier les requêtes d’attente longue historiques (par exemple, >20 % du temps d’attente total écoulé) exécutent la requête suivante. Cette requête utilise des statistiques de performances pour les plans de requête mis en cache depuis le début de SQL Server.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCPour identifier les requêtes en cours d’exécution avec des attentes supérieures à 500 ms, exécutez la requête suivante :
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Si vous pouvez collecter un plan de requête, vérifiez WaitStats à partir des propriétés du plan d’exécution dans SSMS :
- Exécutez la requête avec inclure le plan d’exécution réel activé.
- Cliquez avec le bouton droit sur l’opérateur le plus à gauche dans l’onglet Plan d’exécution
- Sélectionnez Propriétés , puis propriété WaitStats .
- Vérifiez les waitTimeMs et WaitType.
Si vous connaissez les scénarios PSSDiag/SQLdiag ou SQL LogScout LightPerf/GeneralPerf, envisagez d’utiliser l’un d’eux pour collecter des statistiques de performances et identifier les requêtes en attente sur votre instance SQL Server. Vous pouvez importer les fichiers de données collectés et analyser les données de performances avec SQL Nexus.
Références pour éliminer ou réduire les attentes
Les causes et les résolutions de chaque type d’attente varient. Il n’existe aucune méthode générale pour résoudre tous les types d’attente. Voici des articles pour résoudre et résoudre les problèmes courants liés au type d’attente :
- Comprendre et résoudre les problèmes de blocage (LCK_M_*)
- Comprendre et résoudre les problèmes de blocage d’Azure SQL Database
- Résoudre les problèmes de performances lentes de SQL Server causés par des problèmes d’E/S (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- Résoudre l’insertion de la dernière page PAGELATCH_EX contention dans SQL Server
- Mémoire accorde des explications et des solutions (RESOURCE_SEMAPHORE)
- Résoudre les problèmes de requêtes lentes résultant de ASYNC_NETWORK_IO type d’attente
- Résolution des problèmes liés au type d’attente haute HADR_SYNC_COMMIT avec les groupes de disponibilité Always On
- Fonctionnement : CMEMTHREAD et débogage
- Rendre les attentes parallélisme exploitables (CXPACKET et CXCONSUMER)
- Attente THREADPOOL
Pour obtenir des descriptions de nombreux types d’attente et de ce qu’ils indiquent, consultez le tableau dans Types d’attente.
Diagnostiquer les différences de plan de requête
Voici quelques causes courantes des différences dans les plans de requête :
Différences entre la taille des données ou les valeurs de données
La même base de données est-elle utilisée sur les deux serveurs, à l’aide de la même sauvegarde de base de données ? Les données ont-elles été modifiées sur un serveur par rapport à l’autre ? Les différences de données peuvent entraîner des plans de requête différents. Par exemple, la jointure de la table T1 (1000 lignes) avec la table T2 (2 000 000 lignes) diffère de la jointure de la table T1 (100 lignes) avec la table T2 (2 000 000 lignes). Le type et la vitesse de l’opération
JOINpeuvent être considérablement différents.Différences entre les statistiques
Les statistiques ont-elles été mises à jour sur une base de données et non sur l’autre ? Les statistiques ont-elles été mises à jour avec un taux d’échantillonnage différent (par exemple, 30 % contre 100 % d’analyse complète) ? Veillez à mettre à jour les statistiques des deux côtés avec le même taux d’échantillonnage.
Différences de niveau de compatibilité de base de données
Vérifiez si les niveaux de compatibilité des bases de données sont différents entre les deux serveurs. Pour obtenir le niveau de compatibilité de la base de données, exécutez la requête suivante :
SELECT name, compatibility_level FROM sys.databases WHERE name = '<YourDatabase>'Différences de version/build du serveur
Les versions ou builds de SQL Server sont-elles différentes entre les deux serveurs ? Par exemple, un serveur SQL Server version 2014 et l’autre SQL Server version 2016 ? Il peut y avoir des modifications de produit qui peuvent entraîner des modifications dans la façon dont un plan de requête est sélectionné. Veillez à comparer la même version et la même build de SQL Server.
SELECT ServerProperty('ProductVersion')Différences de version de l’estimateur de cardinalité (CE)
Vérifiez si l’estimateur de cardinalité hérité est activé au niveau de la base de données. Pour plus d’informations sur CE, consultez Estimation de la cardinalité (SQL Server).
SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'LEGACY_CARDINALITY_ESTIMATION'Correctifs logiciels de l’optimiseur activés/désactivés
Si les correctifs logiciels de l’optimiseur de requête sont activés sur un serveur, mais désactivés l’autre, différents plans de requête peuvent être générés. Pour plus d’informations, consultez le modèle de maintenance du correctif logiciel de l’optimiseur de requête SQL Server 4199.
Pour obtenir l’état des correctifs logiciels de l’optimiseur de requête, exécutez la requête suivante :
-- Check at server level for TF 4199 DBCC TRACESTATUS (-1) -- Check at database level USE <YourDatabase> SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'QUERY_OPTIMIZER_HOTFIXES'Différences entre les indicateurs de trace
Certains indicateurs de trace affectent la sélection du plan de requête. Vérifiez s’il existe des indicateurs de trace activés sur un serveur qui ne sont pas activés sur l’autre. Exécutez la requête suivante sur les deux serveurs et comparez les résultats :
-- Check at server level for trace flags DBCC TRACESTATUS (-1)Différences matérielles (nombre d’UC, taille de mémoire)
Pour obtenir les informations matérielles, exécutez la requête suivante :
SELECT cpu_count, physical_memory_kb/1024/1024 PhysicalMemory_GB FROM sys.dm_os_sys_infoDifférences matérielles selon l’optimiseur de requête
Vérifiez le
OptimizerHardwareDependentPropertiesplan de requête et vérifiez si les différences matérielles sont considérées comme significatives pour différents plans.WITH xmlnamespaces(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan') SELECT txt.text, t.OptHardw.value('@EstimatedAvailableMemoryGrant', 'INT') AS EstimatedAvailableMemoryGrant , t.OptHardw.value('@EstimatedPagesCached', 'INT') AS EstimatedPagesCached, t.OptHardw.value('@EstimatedAvailableDegreeOfParallelism', 'INT') AS EstimatedAvailDegreeOfParallelism, t.OptHardw.value('@MaxCompileMemory', 'INT') AS MaxCompileMemory FROM sys.dm_exec_cached_plans AS cp CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp CROSS APPLY qp.query_plan.nodes('//OptimizerHardwareDependentProperties') AS t(OptHardw) CROSS APPLY sys.dm_exec_sql_text (CP.plan_handle) txt WHERE text Like '%<Part of Your Query>%'Délai d’expiration de l’optimiseur
Existe-t-il un problème de délai d’expiration de l’optimiseur ? L’optimiseur de requête peut arrêter l’évaluation des options de plan si la requête en cours d’exécution est trop complexe. Lorsqu’il s’arrête, il choisit le plan avec le coût le plus bas disponible au moment. Cela peut conduire à ce qui semble être un choix de plan arbitraire sur un serveur par rapport à un autre.
Options définies
Certaines options SET affectent les plans, telles que SET ARITHABORT. Pour plus d’informations, consultez Options SET.
Différences entre les indicateurs de requête
Une requête utilise-t-elle des indicateurs de requête et l’autre non ? Vérifiez manuellement le texte de la requête pour établir la présence d’indicateurs de requête.
Plans sensibles aux paramètres (problème de détection de paramètre)
Testez-vous la requête avec exactement les mêmes valeurs de paramètre ? Si ce n’est pas le cas, vous pouvez commencer là-bas. Le plan a-t-il été compilé précédemment sur un serveur en fonction d’une valeur de paramètre différente ? Testez les deux requêtes à l’aide de l’indicateur de requête RECOMPILE pour vous assurer qu’aucune réutilisation de plan n’a lieu. Pour plus d’informations, consultez Examiner et résoudre les problèmes liés à la sensibilité aux paramètres.
Différentes options de base de données/paramètres de configuration délimités
Les mêmes options de base de données ou paramètres de configuration délimités sont-ils utilisés sur les deux serveurs ? Certaines options de base de données peuvent influencer les choix de plan. Par exemple, compatibilité de la base de données, ce hérité par rapport à CE par défaut et détection de paramètre. Exécutez la requête suivante à partir d’un serveur pour comparer les options de base de données utilisées sur les deux serveurs :
-- On Server1 add a linked server to Server2 EXEC master.dbo.sp_addlinkedserver @server = N'Server2', @srvproduct=N'SQL Server' -- Run a join between the two servers to compare settings side by side SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value_in_use AS srv1_value_in_use, s2.value_in_use AS srv2_value_in_use, Variance = CASE WHEN ISNULL(s1.value_in_use, '##') != ISNULL(s2.value_in_use,'##') THEN 'Different' ELSE '' END FROM sys.configurations s1 FULL OUTER JOIN [server2].master.sys.configurations s2 ON s1.name = s2.name SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value srv1_value_in_use, s2.value srv2_value_in_use, s1.is_value_default, s2.is_value_default, Variance = CASE WHEN ISNULL(s1.value, '##') != ISNULL(s2.value, '##') THEN 'Different' ELSE '' END FROM sys.database_scoped_configurations s1 FULL OUTER JOIN [server2].master.sys.database_scoped_configurations s2 ON s1.name = s2.nameRepères de plan
Existe-t-il des repères de plan utilisés pour vos requêtes sur un serveur, mais pas sur l’autre ? Exécutez la requête suivante pour établir des différences :
SELECT * FROM sys.plan_guides