Résoudre les problèmes de performances UPDATE avec des plans étroits et larges dans SQL Server
S'applique à : SQL Server
Une UPDATE instruction peut être plus rapide dans certains cas et plus lente dans d’autres. Il existe de nombreux facteurs qui peuvent entraîner une telle variance, y compris le nombre de lignes mises à jour et l’utilisation des ressources sur le système (blocage, processeur, mémoire ou E/S). Cet article aborde une raison spécifique de la variance : le choix du plan de requête effectué par SQL Server.
Qu’est-ce que les plans étroits et larges ?
Lorsque vous exécutez une UPDATE instruction sur une colonne d’index cluster, SQL Server met à jour non seulement l’index cluster lui-même, mais également tous les index non cluster, car les index non cluster contiennent la clé d’index du cluster.
SQL Server propose deux options pour effectuer la mise à jour :
Plan étroit : effectuez la mise à jour d’index non cluster avec la mise à jour de clé d’index cluster. Cette approche simple est facile à comprendre ; mettez à jour l’index cluster, puis mettez à jour tous les index non cluster en même temps. SQL Server met à jour une ligne et passe à la suivante jusqu’à ce que tous soient terminés. Cette approche est appelée mise à jour de plan étroite ou mise à jour par ligne. Toutefois, cette opération est relativement coûteuse, car l’ordre des données d’index non cluster qui seront mises à jour peut ne pas être dans l’ordre des données d’index cluster. Si de nombreuses pages d’index sont impliquées dans la mise à jour, lorsque les données se trouvent sur le disque, un grand nombre de requêtes d’E/S aléatoires peuvent se produire.
Plan large : pour optimiser les performances et réduire les E/S aléatoires, SQL Server peut choisir un plan large. Elle ne met pas à jour les index non cluster, ainsi que la mise à jour d’index cluster. Au lieu de cela, il trie toutes les données d’index non cluster en mémoire, puis met à jour tous les index dans cet ordre. Cette approche est appelée un plan large (également appelé mise à jour par index).
Voici une capture d’écran des plans étroits et larges :

Quand SQL Server choisit-il un plan large ?
Deux critères doivent être remplis pour que SQL Server choisisse un plan large :
- Le nombre de lignes affectées est supérieur à 250.
- La taille du niveau feuille des index non cluster (nombre de pages d’index * 8 Ko) est au moins 1/1000 du paramètre de mémoire maximale du serveur.
Comment fonctionnent les plans étroits et larges ?
Pour comprendre le fonctionnement des plans étroits et larges, procédez comme suit dans l’environnement suivant :
- SQL Server 2019 CU11
- Mémoire maximale du serveur = 1 500 Mo
Exécutez le script suivant pour créer une table
mytable1avec 41 501 lignes, un index cluster sur la colonnec1et cinq index non cluster sur le reste des colonnes, respectivement.CREATE TABLE mytable1(c1 INT,c2 CHAR(30),c3 CHAR(20),c4 CHAR(30),c5 CHAR(30)) GO WITH cte AS ( SELECT ROW_NUMBER() OVER(ORDER BY c1.object_id) id FROM sys.columns CROSS JOIN sys.columns c1 ) INSERT mytable1 SELECT TOP 41000 id,REPLICATE('a',30),REPLICATE('a',20),REPLICATE('a',30),REPLICATE('a',30) FROM cte GO INSERT mytable1 SELECT TOP 250 50000,c2,c3,c4,c5 FROM mytable1 GO INSERT mytable1 SELECT TOP 251 50001,c2,c3,c4,c5 FROM mytable1 GO CREATE CLUSTERED INDEX ic1 ON mytable1(c1) CREATE INDEX ic2 ON mytable1(c2) CREATE INDEX ic3 ON mytable1(c3) CREATE INDEX ic4 ON mytable1(c4) CREATE INDEX ic5 ON mytable1(c5)Exécutez les trois instructions T-SQL
UPDATEsuivantes et comparez les plans de requête :UPDATE mytable1 SET c1=c1 WHERE c1=1 OPTION(RECOMPILE)- une ligne est mise à jourUPDATE mytable1 SET c1=c1 WHERE c1=50000 OPTION(RECOMPILE)- 250 lignes sont mises à jour.UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE)- 251 lignes sont mises à jour.
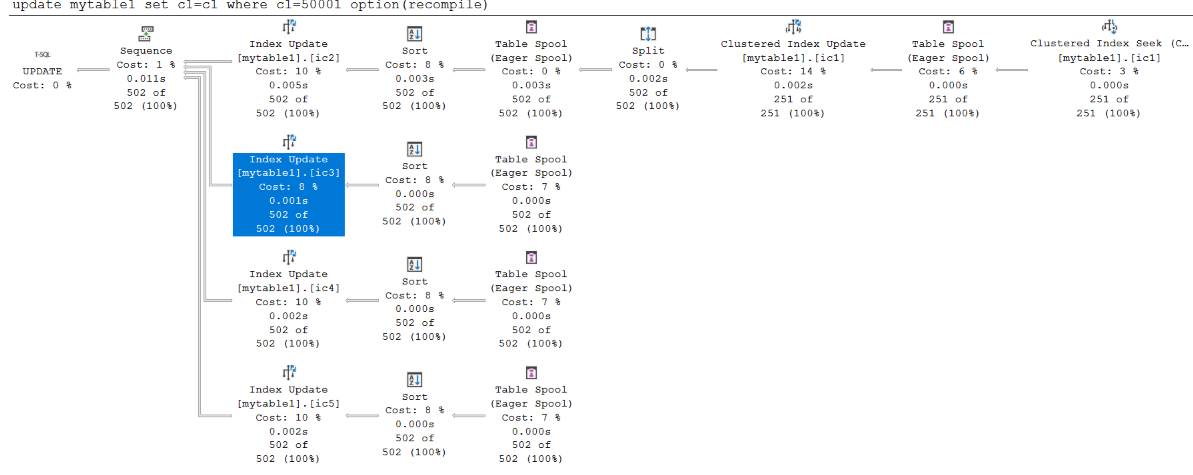
Examinez les résultats en fonction du premier critère (le seuil du nombre de lignes affecté est de 250).
La capture d’écran suivante montre les résultats en fonction du premier critère :

Comme prévu, l’optimiseur de requête choisit un plan étroit pour les deux premières requêtes, car le nombre de lignes affectées est inférieur à 250. Un plan large est utilisé pour la troisième requête, car le nombre de lignes impacté est 251, qui est supérieur à 250.
Examinez les résultats en fonction du deuxième critère (la mémoire de la taille d’index feuille est au moins 1/1000 du paramètre de mémoire maximale du serveur).
La capture d’écran suivante montre les résultats en fonction du deuxième critère :

Un plan large est sélectionné pour la troisième
UPDATErequête. Mais l’indexic3(sur la colonnec3) n’est pas visible dans le plan. Le problème se produit parce que le deuxième critère n’est pas satisfait : la taille de l’index des pages feuilles par rapport à la mémoire maximale du serveur définie.Type de données de colonne
c2,c4etc4estchar(30), tandis que le type de données de colonnec3estchar(20). La taille de chaque ligne d’indexic3est inférieure à d’autres, de sorte que le nombre de pages feuilles est inférieur à d’autres.Avec l’aide de la fonction de gestion dynamique (DMF),
sys.dm_db_database_page_allocationsvous pouvez calculer le nombre de pages pour chaque index. Pour lesic2index,ic4et , chaqueic5index a 214 pages et 209 d’entre eux sont des pages feuilles (les résultats peuvent varier légèrement). La mémoire consommée par les pages feuilles est de 209 x 8 = 1 672 Ko. Par conséquent, le ratio est 1672/(1500 x 1024) = 0,00108854101, supérieur à 1/1000. Toutefois, leic3seul compte 161 pages ; 159 d’entre elles sont des pages feuilles. Le ratio est 159 x 8/(1500 x 1024) = 0,000828125, qui est inférieur à 1/1000 (0,001).Si vous insérez plus de lignes ou réduisez la mémoire maximale du serveur pour répondre au critère, le plan change. Pour que la taille de niveau feuille de l’index soit supérieure à 1/1000, vous pouvez réduire le paramètre de mémoire maximale du serveur un peu à 1 200 en exécutant les commandes suivantes :
sp_configure 'show advanced options', 1; GO RECONFIGURE; GO sp_configure 'max server memory', 1200; GO RECONFIGURE GO UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE) --251 rows are updated.Dans ce cas, 159 x 8/(1200 x 1024) = 0,00103515625 > 1/1000. Après cette modification, l’affichage
ic3apparaît dans le plan.Pour plus d’informations sur
show advanced options, consultez Utiliser Transact-SQL.La capture d’écran suivante montre que le plan large utilise tous les index lorsque le seuil de mémoire est atteint :



Un plan large est-il plus rapide qu’un plan étroit ?
La réponse est qu’elle varie selon que les données et les pages d’index sont mises en cache dans le pool de mémoires tampons ou non.
Les données sont mises en cache dans le pool de mémoires tampons
Si les données se trouvent déjà dans le pool de mémoires tampons, la requête avec le plan large n’offre pas nécessairement d’avantages supplémentaires en matière de performances par rapport aux plans étroits, car le plan large est conçu pour améliorer les performances des E/S (lectures physiques, et non des lectures logiques).
Pour tester si un plan large est plus rapide qu’un plan étroit lorsque les données se situent dans un pool de mémoires tampons, procédez comme suit dans l’environnement suivant :
SQL Server 2019 CU11
Mémoire maximale du serveur : 30 000 Mo
La taille des données est de 64 Mo, tandis que la taille de l’index est d’environ 127 Mo.
Les fichiers de base de données se trouvent sur deux disques physiques différents :
- I :\sql19\dbWideplan.mdf
- H :\sql19\dbWideplan.ldf
Créez une autre table,
mytable2en exécutant les commandes suivantes :CREATE TABLE mytable2(C1 INT,C2 INT,C3 INT,C4 INT,C5 INT) GO CREATE CLUSTERED INDEX IC1 ON mytable2(C1) CREATE INDEX IC2 ON mytable2(C2) CREATE INDEX IC3 ON mytable2(C3) CREATE INDEX IC4 ON mytable2(C4) CREATE INDEX IC5 ON mytable2(C5) GO DECLARE @N INT=1 WHILE @N<1000000 BEGIN DECLARE @N1 INT=RAND()*4500 DECLARE @N2 INT=RAND()*100000 DECLARE @N3 INT=RAND()*100000 DECLARE @N4 INT=RAND()*100000 DECLARE @N5 INT=RAND()*100000 INSERT mytable2 VALUES(@N1,@N2,@N3,@N4,@N5) SET @N+=1 END GO UPDATE STATISTICS mytable2 WITH FULLSCANExécutez les deux requêtes suivantes pour comparer les plans de requête :
update mytable2 set c1=c1 where c2<260 option(querytraceon 8790) --trace flag 8790 will force Wide plan update mytable2 set c1=c1 where c2<260 option(querytraceon 2338) --trace flag 2338 will force Narrow planPour plus d’informations, consultez l’indicateur de trace 8790 et l’indicateur de trace 2338.
La requête avec le plan large prend 0,136 secondes, tandis que la requête avec le plan étroit ne prend que 0,112 secondes. Les deux durées sont très proches et la mise à jour par index (plan large) est moins bénéfique, car les données se trouvent déjà dans la mémoire tampon avant l’exécution de l’instruction
UPDATE.La capture d’écran suivante montre des plans larges et étroits lorsque les données sont mises en cache dans le pool de mémoires tampons :


Les données ne sont pas mises en cache dans le pool de mémoires tampons
Pour tester si un plan large est plus rapide qu’un plan étroit lorsque les données ne se trouvent pas dans le pool de mémoires tampons, exécutez les requêtes suivantes :
Note
Lorsque vous effectuez le test, vérifiez que la vôtre est la seule charge de travail dans SQL Server et que les disques sont dédiés à SQL Server.
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 seconds
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 8790) --force Wide plan
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 SECONDS
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 2338) --force Narrow plan
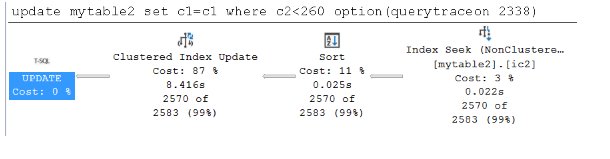
La requête avec un plan large prend 3,554 secondes, tandis que la requête avec un plan étroit prend 6,701 secondes. La requête de plan large s’exécute plus rapidement cette fois.
La capture d’écran suivante montre le plan large lorsque les données ne sont pas mises en cache dans le pool de mémoires tampons :

La capture d’écran suivante montre le plan étroit lorsque les données ne sont pas mises en cache dans le pool de mémoires tampons :
Une requête de plan large est-elle toujours plus rapide qu’un plan de requête étroit lorsque les données ne se trouvent pas dans la mémoire tampon ?
La réponse est « pas toujours ». Pour tester si la requête de plan large est toujours plus rapide que le plan de requête étroit lorsque les données ne se trouvent pas dans la mémoire tampon, procédez comme suit :
Créez une autre table,
mytable2en exécutant les commandes suivantes :SELECT c1,c1 AS c2,c1 AS C3,c1 AS c4,c1 AS C5 INTO mytable3 FROM mytable2 GO CREATE CLUSTERED INDEX IC1 ON mytable3(C1) CREATE INDEX IC2 ON mytable3(C2) CREATE INDEX IC3 ON mytable3(C3) CREATE INDEX IC4 ON mytable3(C4) CREATE INDEX IC5 ON mytable3(C5) GOLa
mytable3valeur est identique à celle desmytable2données, à l’exception des données.mytable3a les cinq colonnes avec la même valeur, ce qui rend l’ordre des index non cluster suivez l’ordre de l’index cluster. Ce tri des données réduit l’avantage du plan à l’échelle.Exécutez les commandes suivantes pour comparer les plans de requête :
CHECKPOINT GO DBCC DROPCLEANBUFFERS go UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 8790) --tf 8790 will force Wide plan CHECKPOINT GO DBCC DROPCLEANBUFFERS GO UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 2338) --tf 2338 will force Narrow planLa durée des deux requêtes est réduite de manière significative ! Le plan large prend 0,304 secondes, ce qui est un peu plus lent que le plan étroit cette fois.
La capture d’écran suivante montre la comparaison des performances quand des performances larges et étroites sont utilisées :


Scénarios dans lesquels les plans étendus sont appliqués
Voici les autres scénarios dans lesquels des plans étendus sont également appliqués :
La colonne d’index cluster a une clé unique ou primaire, et plusieurs lignes sont mises à jour
Voici un exemple pour reproduire le scénario :
CREATE TABLE mytable4(c1 INT primary key,c2 INT,c3 INT,c4 INT)
GO
CREATE INDEX ic2 ON mytable4(c2)
CREATE INDEX ic3 ON mytable4(c3)
CREATE INDEX ic4 ON mytable4(c4)
GO
INSERT mytable4 VALUES(0,0,0,0)
INSERT mytable4 VALUES(1,1,1,1)
La capture d’écran suivante montre que le plan large est utilisé lorsque l’index de cluster a une clé unique :

Pour plus d’informations, consultez Maintenance des index uniques.
La colonne d’index de cluster est spécifiée dans le schéma de partition
Voici un exemple pour reproduire le scénario :
CREATE TABLE mytable5(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS1')
DROP PARTITION SCHEME PS1
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF1')
DROP PARTITION FUNCTION PF1
GO
CREATE PARTITION FUNCTION PF1(INT) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS1 AS
PARTITION PF1 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable5(c1) ON PS1(c1)
CREATE INDEX c2 ON mytable5(c2)
CREATE INDEX c3 ON mytable5(c3)
CREATE INDEX c4 ON mytable5(c4)
GO
UPDATE mytable5 SET c1=c1 WHERE c1=1
La capture d’écran suivante montre que le plan large est utilisé lorsqu’il existe une colonne en cluster dans le schéma de partition :

La colonne d’index cluster ne fait pas partie du schéma de partition et la colonne de schéma de partition est mise à jour
Voici un exemple pour reproduire le scénario :
CREATE TABLE mytable6(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS2')
DROP PARTITION SCHEME PS2
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF2')
DROP PARTITION FUNCTION PF2
GO
CREATE PARTITION FUNCTION PF2(int) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS2 AS
PARTITION PF2 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable6(c1) ON PS2(c2) --on c2 column
CREATE INDEX c3 ON mytable6(c3)
CREATE INDEX c4 ON mytable6(c4)
La capture d’écran suivante montre que le plan large est utilisé lorsque la colonne du schéma de partition est mise à jour :

Conclusion
SQL Server choisit une mise à jour de plan large lorsque les critères suivants sont remplis en même temps :
- Le nombre de lignes concerné est supérieur à 250.
- La mémoire de l’index feuille est au moins 1/1000 du paramètre max server memory.
Les plans étendus augmentent les performances au détriment de la consommation de mémoire supplémentaire.
Si le plan de requête attendu n’est pas utilisé, il peut être dû à des statistiques obsolètes (ne signalant pas une taille de données correcte), au paramètre de mémoire maximale du serveur ou à d’autres problèmes non liés tels que les plans sensibles aux paramètres.
La durée des
UPDATEinstructions utilisant un plan large dépend de plusieurs facteurs et, dans certains cas, il peut prendre plus de temps que des plans étroits.L’indicateur de trace 8790 force un plan large ; l’indicateur de trace 2338 force un plan étroit.