Résoudre les problèmes des requêtes qui semblent ne jamais se terminer dans SQL Server
Cet article décrit les étapes de résolution des problèmes liés au problème où vous avez une requête qui semble ne jamais être terminée, ou l’obtenir peut prendre plusieurs heures ou jours.
Qu’est-ce qu’une requête sans fin ?
Ce document se concentre sur les requêtes qui continuent d’exécuter ou de compiler, autrement dit, leur processeur continue d’augmenter. Elle ne s’applique pas aux requêtes qui sont bloquées ou en attente sur une ressource qui n’est jamais publiée (le processeur reste constant ou change très peu).
Important
Si une requête est laissée pour terminer son exécution, elle se terminera finalement. Cela peut prendre quelques secondes, ou il peut prendre plusieurs jours.
Le terme jamais terminé est utilisé pour décrire la perception d’une requête qui ne se termine pas quand en fait, la requête se termine.
Identifier une requête sans fin
Pour déterminer si une requête est en cours d’exécution ou bloquée sur un goulot d’étranglement, procédez comme suit :
Exécutez la requête suivante :
DECLARE @cntr int = 0 WHILE (@cntr < 3) BEGIN SELECT TOP 10 s.session_id, r.status, r.wait_time, r.wait_type, r.wait_resource, r.cpu_time, r.logical_reads, r.reads, r.writes, r.total_elapsed_time / (1000 * 60) 'Elaps M', SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1, ((CASE r.statement_end_offset WHEN -1 THEN DATALENGTH(st.TEXT) ELSE r.statement_end_offset END - r.statement_start_offset) / 2) + 1) AS statement_text, COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid)) + N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text, r.command, s.login_name, s.host_name, s.program_name, s.last_request_end_time, s.login_time, r.open_transaction_count, atrn.name as transaction_name, atrn.transaction_id, atrn.transaction_state FROM sys.dm_exec_sessions AS s JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st LEFT JOIN (sys.dm_tran_session_transactions AS stran JOIN sys.dm_tran_active_transactions AS atrn ON stran.transaction_id = atrn.transaction_id) ON stran.session_id =s.session_id WHERE r.session_id != @@SPID ORDER BY r.cpu_time DESC SET @cntr = @cntr + 1 WAITFOR DELAY '00:00:05' ENDVérifiez l’exemple de sortie.
Les étapes de résolution des problèmes décrites dans cet article s’appliquent spécifiquement lorsque vous remarquez une sortie similaire à celle suivante où le processeur augmente proportionnellement avec le temps écoulé, sans temps d’attente significatif. Il est important de noter que les modifications
logical_readsne sont pas pertinentes dans ce cas, car certaines requêtes T-SQL liées au processeur peuvent ne pas effectuer de lectures logiques du tout (par exemple, effectuer des calculs ou uneWHILEboucle).session_id statut cpu_time logical_reads wait_time wait_type 56 exécution en cours 7038 101000 0 NULL 56 exécutable 12040 301000 0 NULL 56 exécution en cours 17020 523000 0 NULL Cet article n’est pas applicable si vous observez un scénario d’attente similaire à celui suivant où l’UC ne change pas ou change très légèrement, et que la session attend une ressource.
session_id statut cpu_time logical_reads wait_time wait_type 56 interrompu 0 3 8312 LCK_M_U 56 interrompu 0 3 13318 LCK_M_U 56 interrompu 0 5 18331 LCK_M_U
Pour plus d’informations, consultez Diagnostiquer les attentes ou les goulots d’étranglement.
Temps de compilation long
Dans de rares cas, vous pouvez observer que le processeur augmente en continu au fil du temps, mais ce n’est pas piloté par l’exécution des requêtes. Au lieu de cela, elle peut être pilotée par une compilation excessivement longue (l’analyse et la compilation d’une requête). Dans ces cas, vérifiez la colonne de sortie transaction_name et recherchez une valeur de sqlsource_transform. Ce nom de transaction indique une compilation.
Collecter des données de diagnostic
- SQL Server 2008 - SQL Server 2014 (avant SP2)
- SQL Server 2014 (après SP2) et SQL Server 2016 (avant SP1)
- SQL Server 2016 (après SP1) et SQL Server 2017
- SQL Server 2019 et versions ultérieures
Pour collecter des données de diagnostic à l’aide de SQL Server Management Studio (SSMS), procédez comme suit :
Capturez le code XML du plan d’exécution de requête estimé.
Passez en revue le plan de requête pour voir s’il existe des indications évidentes de l’endroit où la lenteur peut provenir. Parmi les exemples standard on trouve :
- Analyses de table ou d’index (examinez les lignes estimées).
- Boucles imbriquées pilotées par un jeu de données de table externe énorme.
- Boucles imbriquées avec une grande branche dans le côté interne de la boucle.
- Pools de tables.
- Fonctions dans la
SELECTliste qui prennent beaucoup de temps pour traiter chaque ligne.
Si la requête s’exécute rapidement à tout moment, vous pouvez capturer les exécutions « rapides » du plan d’exécution XML réel à comparer.
Méthode pour passer en revue les plans collectés
Cette section explique comment passer en revue les données collectées. Il utilise plusieurs plans de requête XML (à l’aide de l’extension *.sqlplan) collectés dans SQL Server 2016 SP1 et versions ultérieures.
Procédez comme suit pour comparer les plans d’exécution :
Ouvrez un fichier de plan d’exécution de requête précédemment enregistré (.sqlplan).
Cliquez avec le bouton droit dans une zone vide du plan d’exécution, puis sélectionnez Comparer le plan d’exécution.
Choisissez le deuxième fichier de plan de requête que vous souhaitez comparer.
Recherchez des flèches épaisses qui indiquent un grand nombre de lignes qui circulent entre les opérateurs. Sélectionnez ensuite l’opérateur avant ou après la flèche, puis comparez le nombre de lignes réelles sur deux plans.
Comparez les deuxième et troisième plans pour voir si le plus grand flux de lignes se produit dans les mêmes opérateurs.
Voici un exemple :
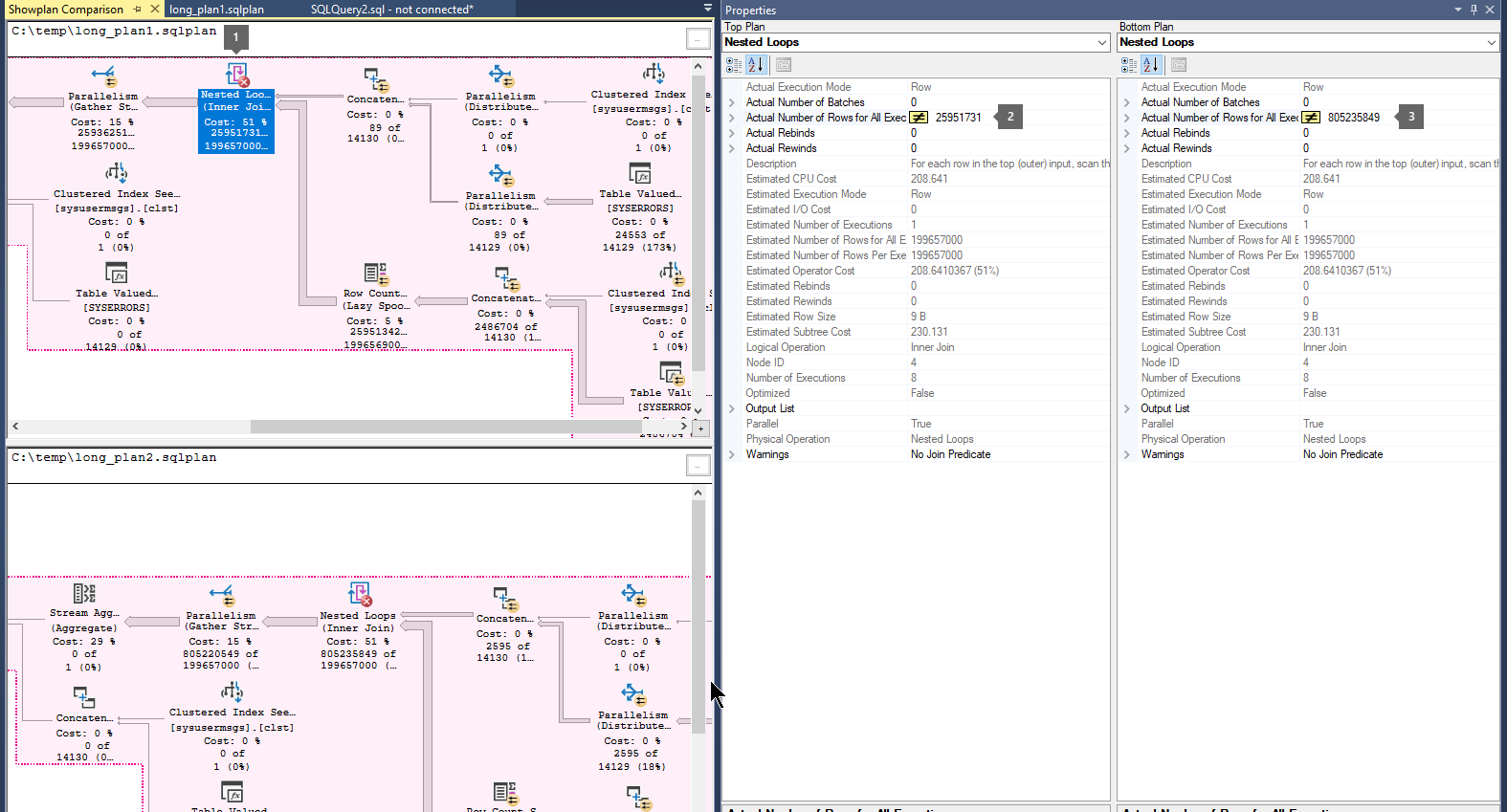

Résolution
Vérifiez que les statistiques sont mises à jour pour les tables utilisées dans la requête.
Recherchez une recommandation d’index manquante dans le plan de requête et appliquez-en une.
Réécrire la requête avec l’objectif de le simplifier :
- Utilisez des prédicats plus sélectifs
WHEREpour réduire les données traitées en amont. - Dissoyez-le.
- Sélectionnez certaines parties dans des tables temporaires et joignez-les ultérieurement.
- Supprimez
TOP,EXISTSetFAST(T-SQL) dans les requêtes qui s’exécutent pendant très longtemps en raison de l’objectif de ligne d’optimiseur. Vous pouvez également utiliser l’indicateurDISABLE_OPTIMIZER_ROWGOAL. Pour plus d’informations, consultez Les objectifs de ligne disparus non autorisés. - Évitez d’utiliser des expressions de table courantes (CTEs) dans des cas tels qu’ils combinent des instructions en une seule requête volumineuse.
- Utilisez des prédicats plus sélectifs
Essayez d’utiliser des indicateurs de requête pour produire un meilleur plan :
HASH JOINouMERGE JOINindicateur- Indicateur
FORCE ORDER - Indicateur
FORCESEEK RECOMPILE- USE
PLAN N'<xml_plan>'si vous avez un plan de requête rapide que vous pouvez forcer
Utilisez Magasin des requêtes (QDS) pour forcer un plan connu s’il existe un tel plan et si votre version de SQL Server prend en charge Magasin des requêtes.
Diagnostiquer les attentes ou les goulots d’étranglement
Cette section est incluse ici comme référence dans le cas où votre problème n’est pas une requête de conduite processeur longue. Vous pouvez l’utiliser pour résoudre les problèmes de requêtes qui sont longues en raison d’attentes.
Pour optimiser une requête qui attend des goulots d’étranglement, identifiez la durée d’attente et l’emplacement du goulot d’étranglement (type d’attente). Une fois le type d’attente confirmé, réduisez le temps d’attente ou éliminez complètement l’attente.
Pour calculer le temps d’attente approximatif, soustrayez le temps processeur (temps de travail) du temps écoulé d’une requête. En règle générale, le temps processeur est le temps d’exécution réel et la partie restante de la durée de vie de la requête est en attente.
Exemples de calcul de la durée d’attente approximative :
| Temps écoulé (ms) | Temps processeur (ms) | Temps d’attente (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1 000 | 6080 |
Identifier le goulot d’étranglement ou attendre
Pour identifier les requêtes d’attente longue historiques (par exemple, >20 % du temps d’attente total écoulé) exécutent la requête suivante. Cette requête utilise des statistiques de performances pour les plans de requête mis en cache depuis le début de SQL Server.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCPour identifier les requêtes en cours d’exécution avec des attentes supérieures à 500 ms, exécutez la requête suivante :
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Si vous pouvez collecter un plan de requête, vérifiez WaitStats à partir des propriétés du plan d’exécution dans SSMS :
- Exécutez la requête avec inclure le plan d’exécution réel activé.
- Cliquez avec le bouton droit sur l’opérateur le plus à gauche dans l’onglet Plan d’exécution
- Sélectionnez Propriétés , puis propriété WaitStats .
- Vérifiez les waitTimeMs et WaitType.
Si vous connaissez les scénarios PSSDiag/SQLdiag ou SQL LogScout LightPerf/GeneralPerf, envisagez d’utiliser l’un d’eux pour collecter des statistiques de performances et identifier les requêtes en attente sur votre instance SQL Server. Vous pouvez importer les fichiers de données collectés et analyser les données de performances avec SQL Nexus.
Références pour éliminer ou réduire les attentes
Les causes et les résolutions de chaque type d’attente varient. Il n’existe aucune méthode générale pour résoudre tous les types d’attente. Voici des articles pour résoudre et résoudre les problèmes courants liés au type d’attente :
- Comprendre et résoudre les problèmes de blocage (LCK_M_*)
- Comprendre et résoudre les problèmes de blocage d’Azure SQL Database
- Résoudre les problèmes de performances lentes de SQL Server causés par des problèmes d’E/S (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- Résoudre l’insertion de la dernière page PAGELATCH_EX contention dans SQL Server
- Mémoire accorde des explications et des solutions (RESOURCE_SEMAPHORE)
- Résoudre les problèmes de requêtes lentes résultant de ASYNC_NETWORK_IO type d’attente
- Résolution des problèmes liés au type d’attente haute HADR_SYNC_COMMIT avec les groupes de disponibilité Always On
- Fonctionnement : CMEMTHREAD et débogage
- Rendre les attentes parallélisme exploitables (CXPACKET et CXCONSUMER)
- Attente THREADPOOL
Pour obtenir des descriptions de nombreux types d’attente et de ce qu’ils indiquent, consultez le tableau dans Types d’attente.