Configurer et exécuter le profilage des données pour une ressource de données
Le profilage des données consiste à examiner les données disponibles dans différentes sources de données et à collecter des statistiques et des informations sur ces données. Le profilage des données permet d’évaluer le niveau de qualité des données en fonction d’un ensemble d’objectifs défini. Si les données sont de mauvaise qualité ou gérées dans des structures qui ne peuvent pas être intégrées pour répondre aux besoins de l’entreprise, les processus métier et la prise de décision en souffrent. Le profilage des données vous permet de comprendre la fiabilité et la qualité de vos données, ce qui est une condition préalable à la prise de décisions pilotées par les données qui augmentent le chiffre d’affaires et favorisent la croissance.
Configuration requise
- Pour exécuter et planifier des analyses d’évaluation de la qualité des données, vos utilisateurs doivent avoir le rôle de gestionnaire de la qualité des données.
- Actuellement, le compte Microsoft Purview peut être défini pour autoriser l’accès public ou l’accès au réseau virtuel géré afin que les analyses de la qualité des données puissent s’exécuter.
Cycle de vie de la qualité des données
Le profilage des données est la cinquième étape du cycle de vie de qualité des données pour une ressource de données. Les étapes précédentes sont les suivantes :
- Attribuez aux utilisateurs des autorisations de gestionnaire de la qualité des données dans Catalogue unifié d’utiliser toutes les fonctionnalités de qualité des données.
- Inscrivez et analysez une source de données dans votre Mappage de données Microsoft Purview.
- Ajouter votre ressource de données à un produit de données
- Configurez une connexion à la source de données pour préparer votre source pour l’évaluation de la qualité des données.
Sources de données multicloud prises en charge
- Azure Data Lake Storage (ADLS Gen2)
- Types de fichiers : Delta Parquet et Parquet
- Base de données Azure SQL
- Le patrimoine de données fabric dans OneLake inclut le raccourci et la mise en miroir du patrimoine de données. Le profilage des données est pris en charge uniquement pour les tables delta Lakehouse et les fichiers Parquet.
- Mise en miroir du patrimoine de données : Cosmos DB, Snowflake, Azure SQL
- Patrimoine de données de raccourci : AWS S3, GCS, AdlsG2 et Dataverse
- Azure Synapse serverless et l’entrepôt de données
- Catalogue Unity d' Azure Databricks
- Flocon de neige
- Google Big Query (préversion)
- Données iceberg dans ADLS Gen2, Microsoft Fabric Lakehouse, AWS S3 et GCP GCS
Importante
La qualité des données du fichier Parquet est conçue pour prendre en charge :
- Répertoire avec fichier de composant Parquet. Par exemple : ./Sales/{Parquet Part Files}. Le nom complet doit suivre
https://(storage account).dfs.core.windows.net/(container)/path/path2/{SparkPartitions}. Veillez à ne pas avoir de modèles {n} dans la structure des répertoires/sous-répertoires ; il doit s’agir d’un nom de domaine complet direct menant à {SparkPartitions}. - Répertoire avec des fichiers Parquet partitionnés, partitionnés par colonnes dans le jeu de données, comme les données de ventes partitionnée par année et par mois. Par exemple : ./Sales/{Year=2018}/{Month=Dec}/{Parquet Part Files}.
Ces deux scénarios essentiels, qui présentent un schéma de jeu de données Parquet cohérent, sont pris en charge. Limitation: Il n’est pas conçu pour ou ne prend pas en charge N hiérarchies arbitraires de répertoires avec des fichiers Parquet. Nous vous recommandons de présenter des données dans (1) ou (2) structure construite.
Méthodes d’authentification prises en charge
Actuellement, Microsoft Purview peut uniquement exécuter des analyses de qualité des données à l’aide de l’option Identité managée comme option d’authentification. Les services de qualité des données s’exécutent sur Apache Spark 3.4 et Delta Lake 2.4. Pour plus d’informations sur les régions prises en charge, consultez Vue d’ensemble de la qualité des données.
Importante
- Si le schéma est mis à jour sur la source de données, il est nécessaire de réexécuter l’analyse du mappage de données avant d’exécuter un profilage de données. Vous pouvez importer un schéma à partir de la page vue d’ensemble de la qualité des données à l’aide de la fonctionnalité d’importation de schéma. Si votre source de données s’exécute sur un réseau virtuel managé ou dans un point de terminaison privé, la fonctionnalité d’importation de schéma n’est pas prise en charge.
- Le réseau virtuel n’est pas pris en charge pour Azure Databricks, Google BigQuery et Snowflake.
- Dans la version actuelle, vous pouvez profiler 50 colonnes par lot. Si votre ressource de données comporte plus de 50 colonnes, vous pouvez profiler des colonnes supplémentaires dans plusieurs lots.
- Si une colonne contient une valeur distincte, nous vous recommandons de ne pas profiler cette colonne. Une colonne avec des valeurs distinctes n’est pas en mesure de créer une distribution normale.
Étapes de configuration du travail de profilage des données
Configurez une connexion de source de données à la ressource si vous n’en avez pas déjà créé une.
Dans Catalogue unifié Microsoft Purview, sélectionnez le menu Gestion de l’intégrité et le sous-menu Qualité des données.
Dans le sous-menu Qualité des données, sélectionnez le domaine Gouvernance pour le profilage des données.
Sélectionnez un produit de données pour profiler une ressource de données liée à ce produit.
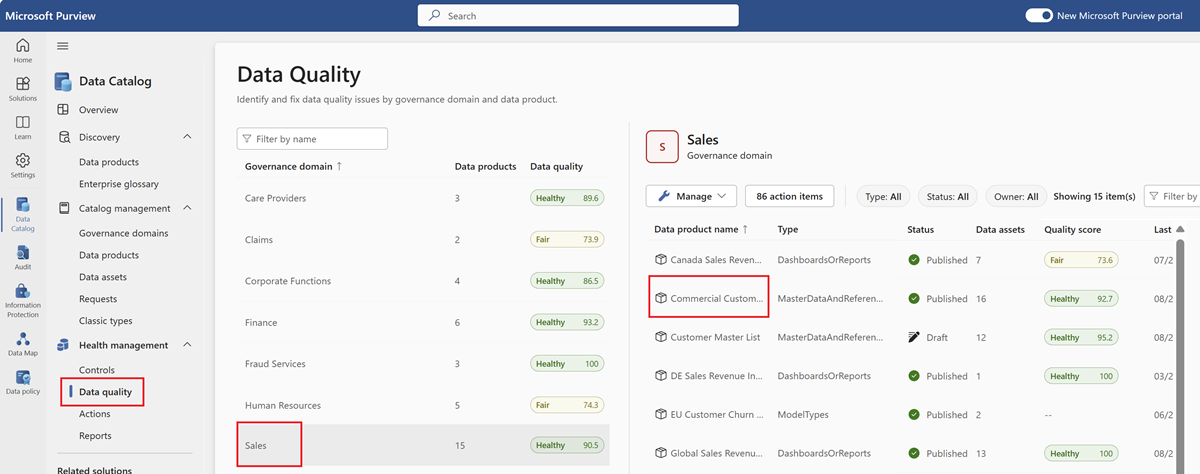
Sélectionnez une ressource de données pour accéder à la page Vue d’ensemble de la qualité des données à des fins de profilage.
Sélectionnez le bouton Profil pour exécuter le travail de profilage pour la ressource de données sélectionnée.
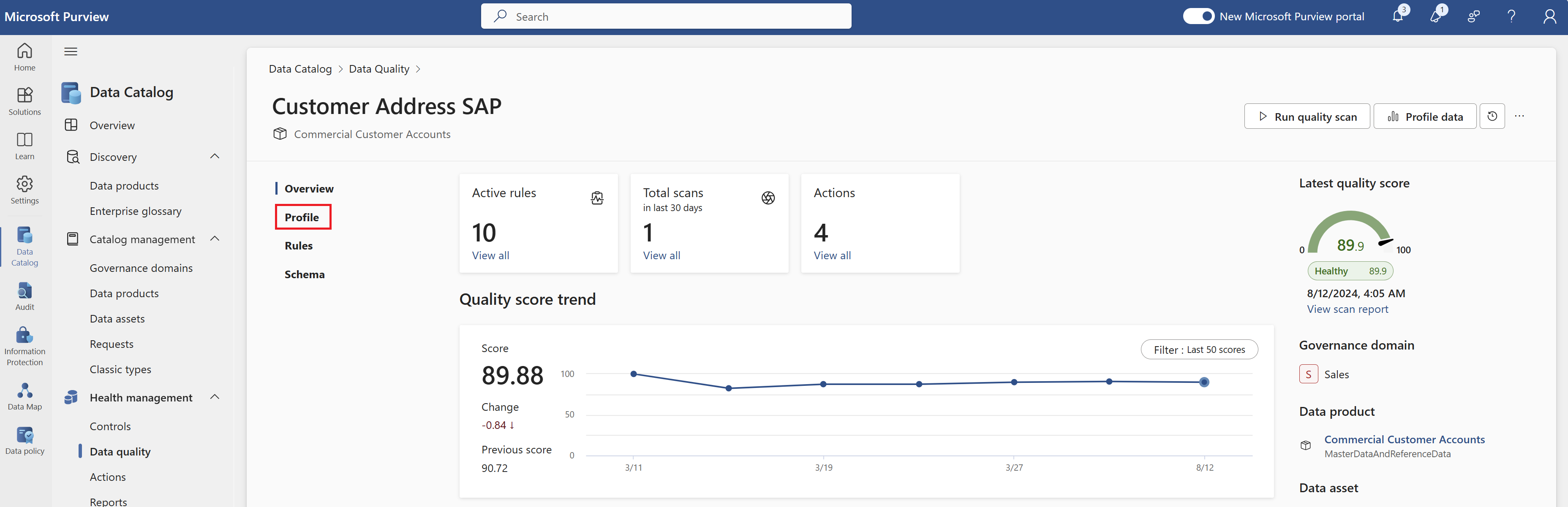
Le moteur de recommandation d’IA suggère des colonnes potentiellement importantes sur lesquelles exécuter le profilage des données. Vous pouvez désélectionner les colonnes recommandées et/ou sélectionner d’autres colonnes à profiler.
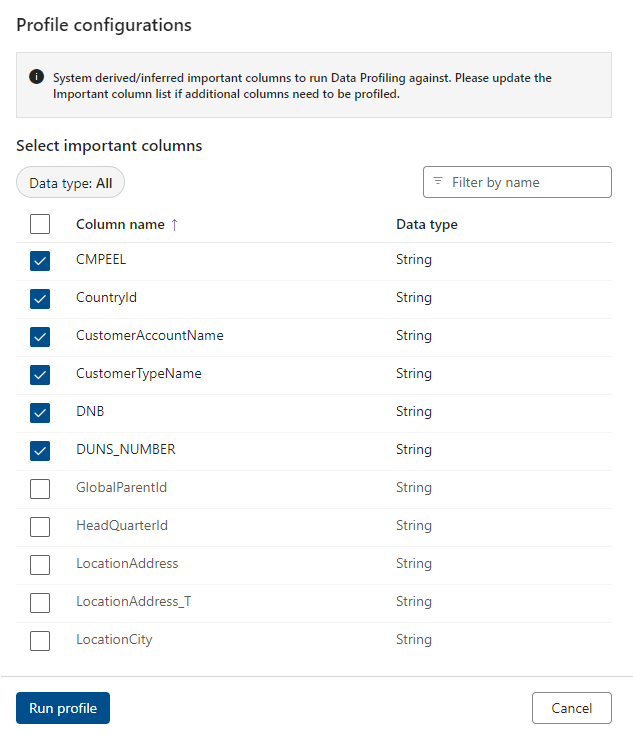
Une fois que vous avez sélectionné les colonnes pertinentes, sélectionnez Exécuter le profil.
Pendant l’exécution du travail, vous pouvez suivre sa progression à partir de la page de surveillance de la qualité des données dans le domaine de gouvernance.
Une fois le travail terminé, sélectionnez l’onglet Profil dans le menu de gauche de la page de qualité des données de la ressource pour répertorier les résultats de profilage et les instantané statistiques. Il peut y avoir plusieurs pages de résultats de profil en fonction du nombre de colonnes de vos ressources de données.
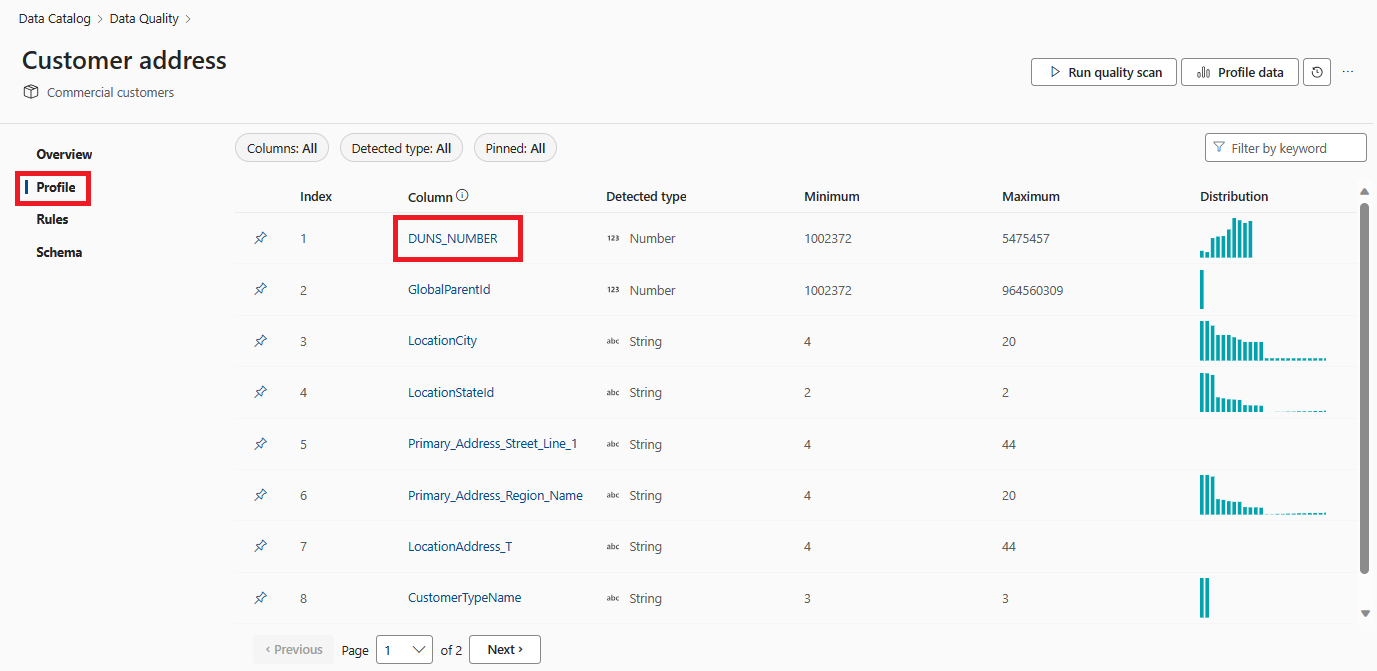
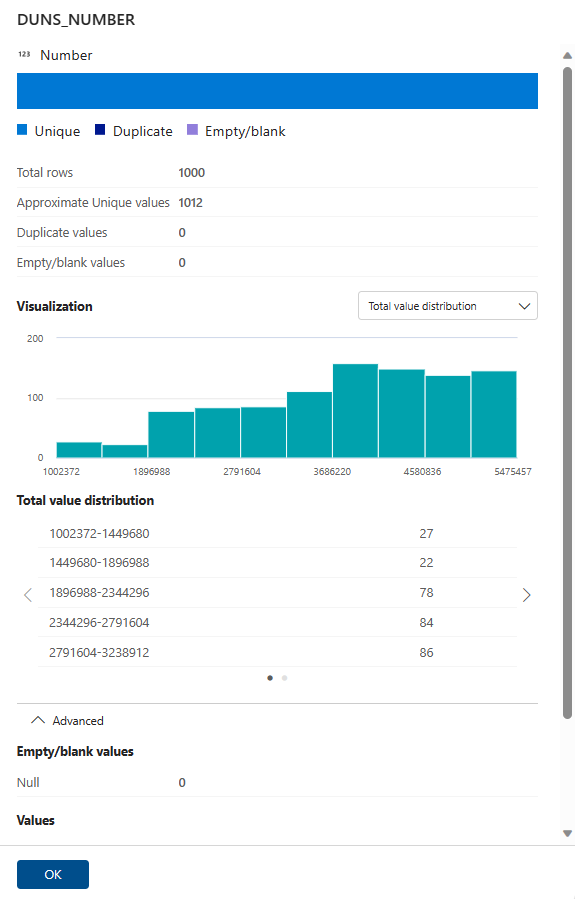
Parcourez les résultats de profilage et les mesures statistiques pour chaque colonne.



Importante
Le format delta est généralement détecté automatiquement si le format est standard et correct dans les systèmes sources. Pour profiler le format de fichier Parquet ou iceberg, vous devez remplacer le type de ressource de données par Parquet ou iceberg. Comme illustré dans la capture d’écran ci-dessous, modifiez le type de ressource de données par défaut Parquet ou un autre format pris en charge si le format de votre fichier de ressource de données n’est pas delta. Cette modification doit être effectuée avant de configurer le travail de profilage.

Contenu associé
- Qualité des données pour le patrimoine de données fabric
- Qualité des données pour les sources de données en miroir Fabric
- Qualité des données des sources de données de raccourci Fabric
- Qualité des données pour Azure Synapse entrepôts de données et serverless
- Qualité des données pour le catalogue Unity Databricks d’Azure
- Qualité des données pour les sources de données Snowflake
- Qualité des données pour Google Big Query
Étapes suivantes
- Configurez des règles de qualité des données basées sur les résultats du profilage et appliquez-les à votre ressource de données.
- Configurez et exécutez une analyse de la qualité des données sur un produit de données pour évaluer la qualité de toutes les ressources prises en charge dans le produit de données.
- Passez en revue les résultats de votre analyse pour évaluer la qualité actuelle des données de votre produit de données.