Découvrir et créer des règles de qualité des données
La qualité des données est la mesure de l’intégrité des données dans un organization et est évaluée à l’aide des scores de qualité des données. Scores générés en fonction de l’évaluation des données par rapport aux règles définies dans Catalogue unifié Microsoft Purview.
Les règles de qualité des données sont des directives essentielles que les organisations établissent pour garantir l’exactitude, la cohérence et l’exhaustivité de leurs données. Ces règles permettent de maintenir l’intégrité et la fiabilité des données.
Voici quelques aspects clés des règles de qualité des données :
Précision : les données doivent représenter avec précision des entités réelles. Le contexte est important ! Par exemple, si vous stockez les adresses des clients, assurez-vous qu’elles correspondent aux emplacements réels.
Exhaustivité : l’objectif de cette règle est d’identifier les données vides, null ou manquantes. Cette règle vérifie que toutes les valeurs sont présentes (mais pas nécessairement correctes).
Conformité : cette règle garantit que les données respectent les normes de mise en forme des données, telles que la représentation des dates, des adresses et des valeurs autorisées.
Cohérence : cette règle vérifie que les différentes valeurs du même enregistrement sont conformes à une règle donnée et qu’il n’y a pas de contradictions. La cohérence des données garantit que les mêmes informations sont représentées uniformément dans différents enregistrements. Par instance, si vous disposez d’un catalogue de produits, des noms et des descriptions de produits cohérents sont essentiels.
Chronologie : cette règle vise à garantir que les données sont accessibles en un laps de temps aussi court que possible. Il garantit que les données sont à jour.
Unicité : cette règle vérifie que les valeurs ne sont pas dupliquées, par exemple, s’il n’y a qu’un seul enregistrement par client, il n’y a pas plusieurs enregistrements pour le même client. Chaque client, produit ou transaction doit avoir un identificateur unique.
Cycle de vie de la qualité des données
La création de règles de qualité des données est la sixième étape du cycle de vie de la qualité des données. Les étapes précédentes sont les suivantes :
- Attribuez aux utilisateurs des autorisations de gestionnaire de la qualité des données dans Catalogue unifié d’utiliser toutes les fonctionnalités de qualité des données.
- Inscrivez et analysez une source de données dans votre Mappage de données Microsoft Purview.
- Ajouter votre ressource de données à un produit de données
- Configurez une connexion à la source de données pour préparer votre source pour l’évaluation de la qualité des données.
- Configurez et exécutez le profilage des données pour une ressource dans votre source de données.
Rôles requis
- Pour créer et gérer des règles de qualité des données, vos utilisateurs doivent avoir le rôle de gestionnaire de la qualité des données.
- Pour afficher les règles de qualité existantes, vos utilisateurs doivent avoir le rôle lecteur de qualité des données.
Afficher les règles de qualité des données existantes
Dans Catalogue unifié Microsoft Purview, sélectionnez le menu Gestion de l’intégrité et le sous-menu Qualité des données.
Dans le sous-menu Qualité des données, sélectionnez un domaine de gouvernance.
Sélectionnez un produit de données.
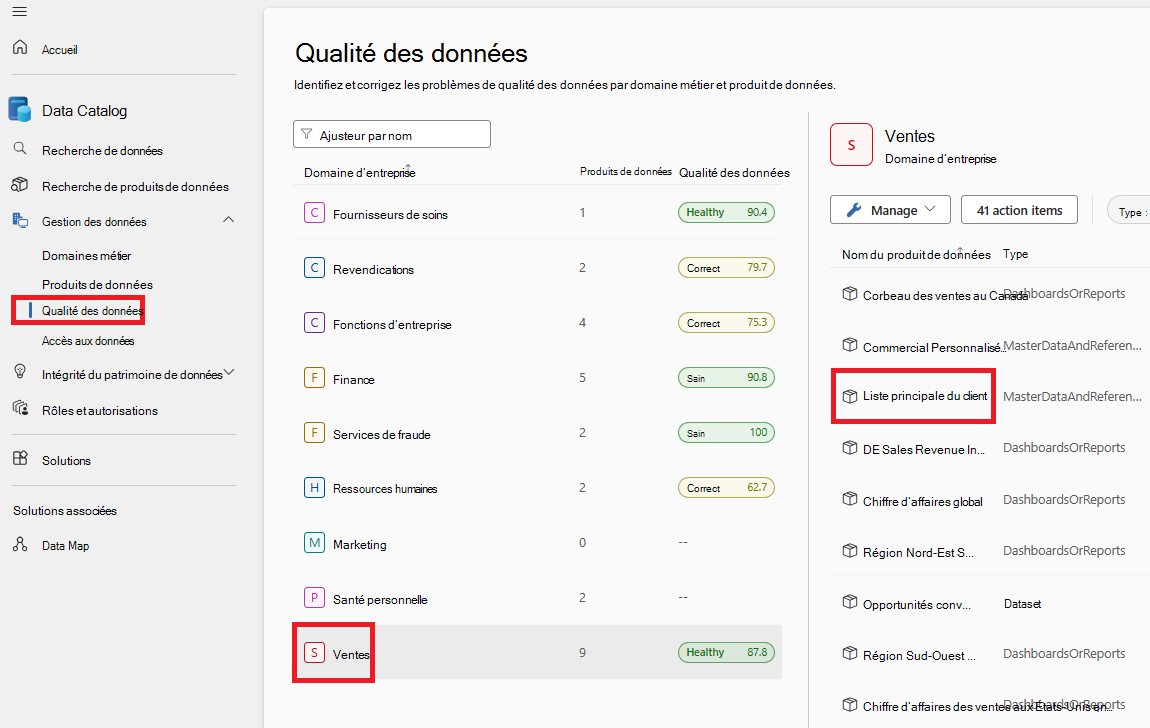
Sélectionnez une ressource de données dans la liste des ressources du produit de données sélectionné.
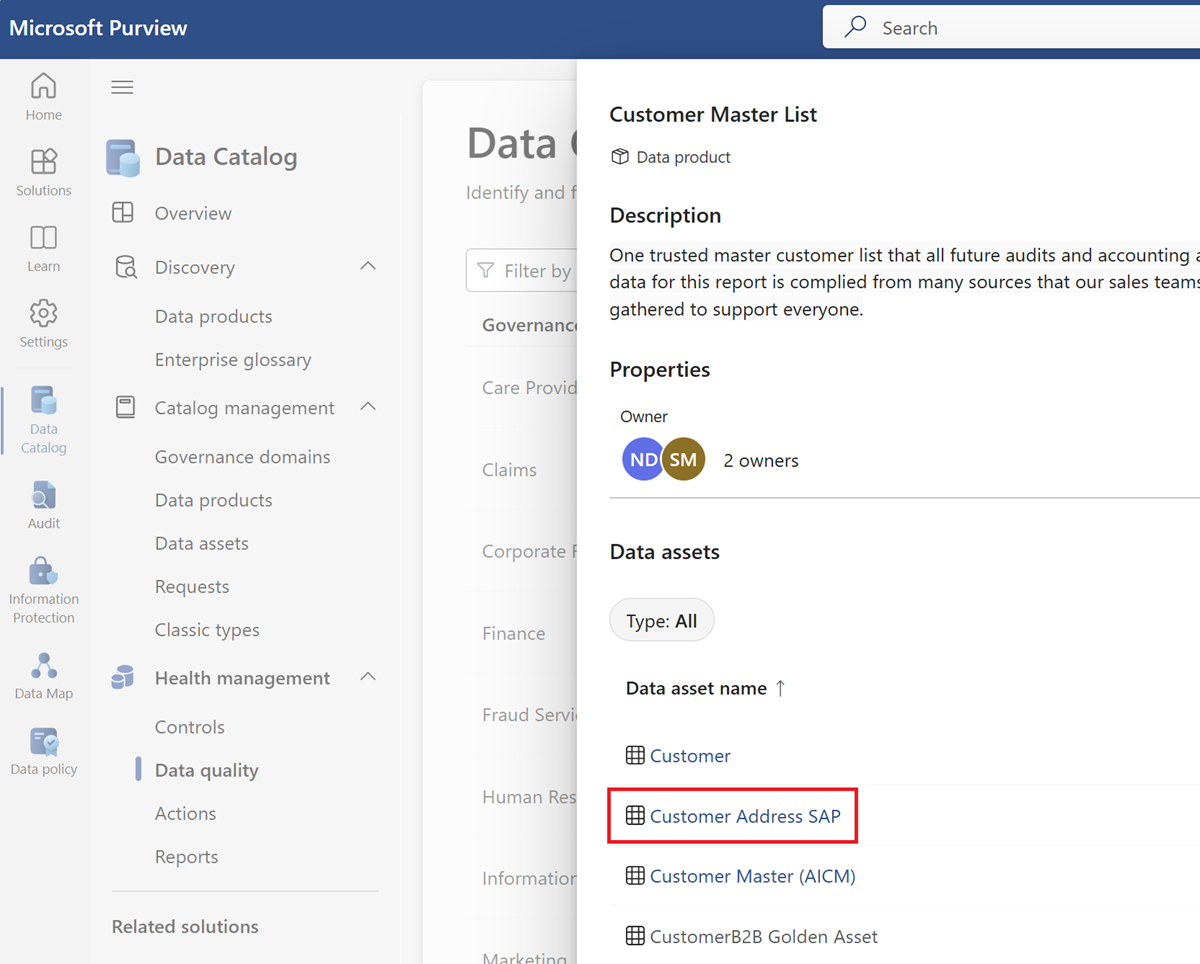
Sélectionnez l’onglet du menu Règles pour afficher les règles existantes appliquées à la ressource.
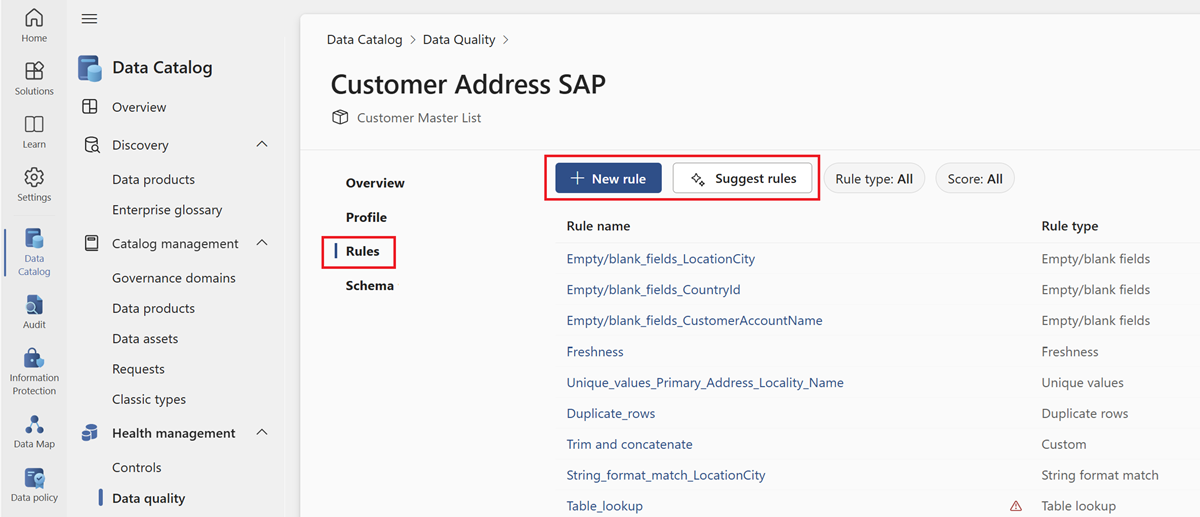
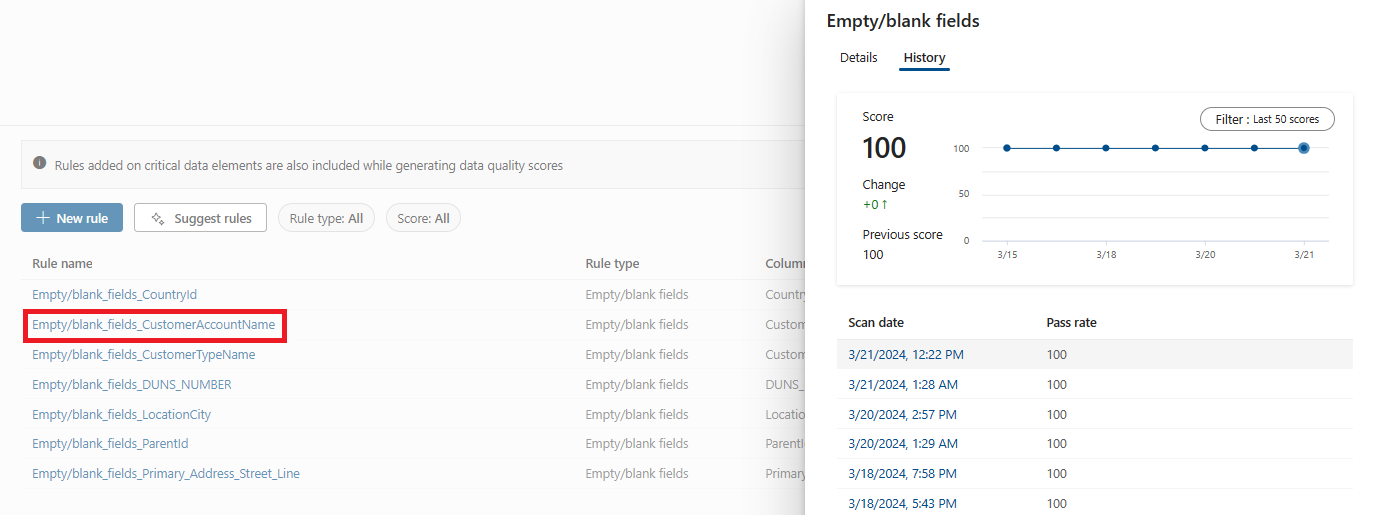
Sélectionnez une règle pour parcourir l’historique des performances de la règle appliquée à la ressource de données sélectionnée.




Règles de qualité des données disponibles
Qualité des données Microsoft Purview permet la configuration des règles ci-dessous, il s’agit de règles prêtes à l’emploi qui offrent un moyen de mesurer la qualité de vos données à faible code ou sans code.
| Règle | Définition |
|---|---|
| Actualisation | Confirme que toutes les valeurs sont à jour. |
| Valeurs uniques | Confirme que les valeurs d’une colonne sont uniques. |
| Correspondance de format de chaîne | Confirme que les valeurs d’une colonne correspondent à un format spécifique ou à d’autres critères. |
| Correspondance du type de données | Confirme que les valeurs d’une colonne correspondent à leurs exigences en matière de type de données. |
| Lignes dupliquées | Recherche les lignes en double avec les mêmes valeurs sur deux colonnes ou plus. |
| Champs vides/vides | Recherche les champs vides et vides dans une colonne où il doit y avoir des valeurs. |
| Recherche de table | Confirme qu’une valeur dans une table se trouve dans la colonne spécifique d’une autre table. |
| Personnalisé | Créez une règle personnalisée avec le générateur d’expressions visuelles. |
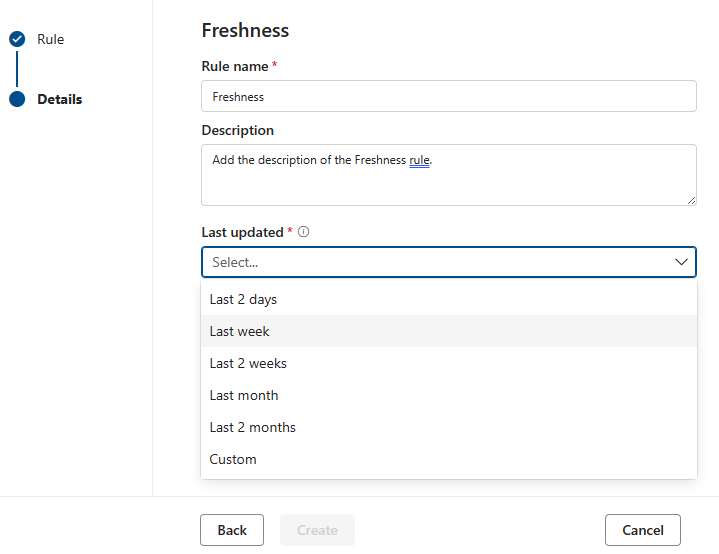
Actualisation
L’objectif de la règle d’actualisation est de déterminer si la ressource a été mise à jour dans le délai prévu. Microsoft Purview prend actuellement en charge la vérification de l’actualisation en examinant les dates de dernière modification.
Remarque
Le score de la règle d’actualisation est 100 (elle a réussi) ou 0 (échec). La règle d’actualisation n’est pas prise en charge pour Snowflake, Azure Databricks UC, Google BigQuery, Synapes et Azure SQL.
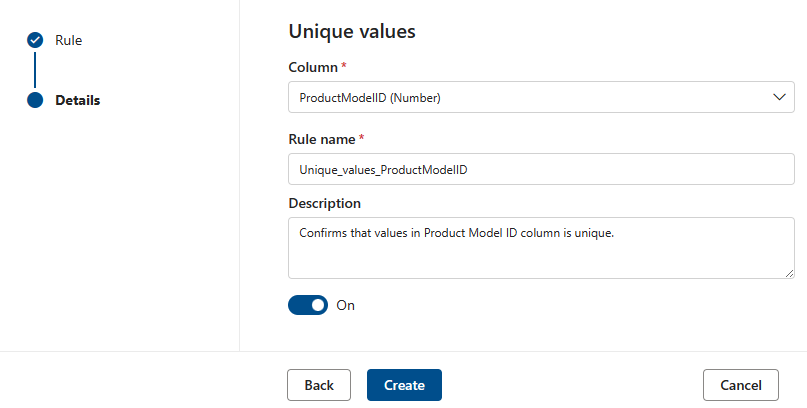
Valeurs uniques
La règle Valeurs uniques indique que toutes les valeurs de la colonne spécifiée doivent être uniques. Toutes les valeurs « pass » uniques et celles qui ne sont pas traitées comme échouent. Si la règle champs vides/vides n’est pas définie sur la colonne, les valeurs null/vides sont ignorées pour les besoins de cette règle.
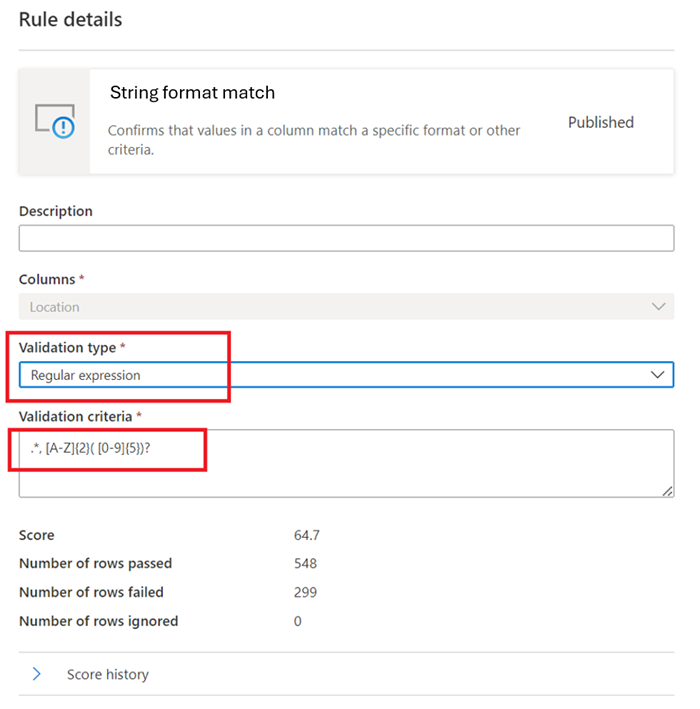
Correspondance de format de chaîne
La règle de correspondance de format vérifie si toutes les valeurs de la colonne sont valides. Si la règle champs vides/vides n’est pas définie sur une colonne, les valeurs null/vides sont ignorées pour les besoins de cette règle.
Cette règle peut valider chaque valeur de la colonne à l’aide de trois approches différentes :
Énumération : liste de valeurs séparées par des virgules. Si la valeur évaluée ne peut pas être comparée à l’une des valeurs répertoriées, la case activée échoue. Les virgules et les barres obliques inverses peuvent être placées dans une séquence d’échappement à l’aide d’une barre oblique inverse :
\. Contient donca \, b, cdeux valeurs, la première esta , bet la seconde estc.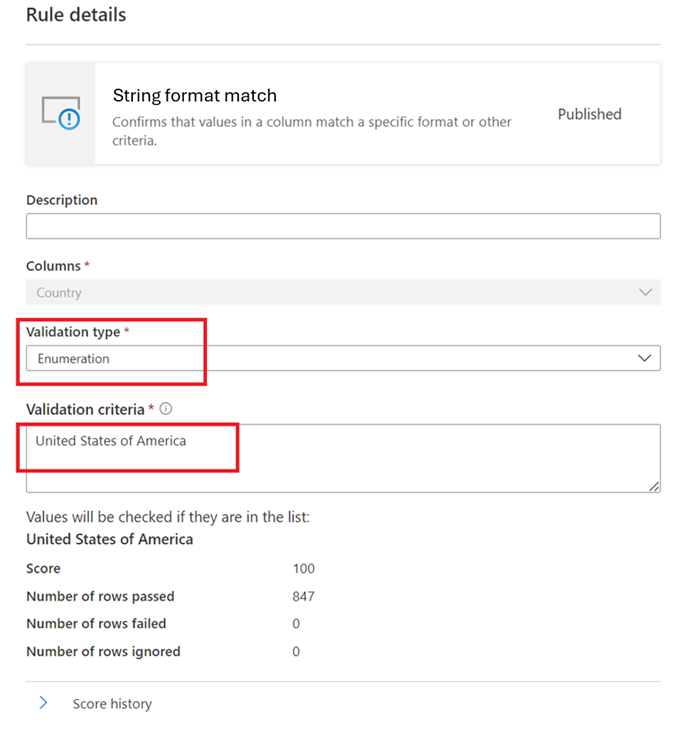
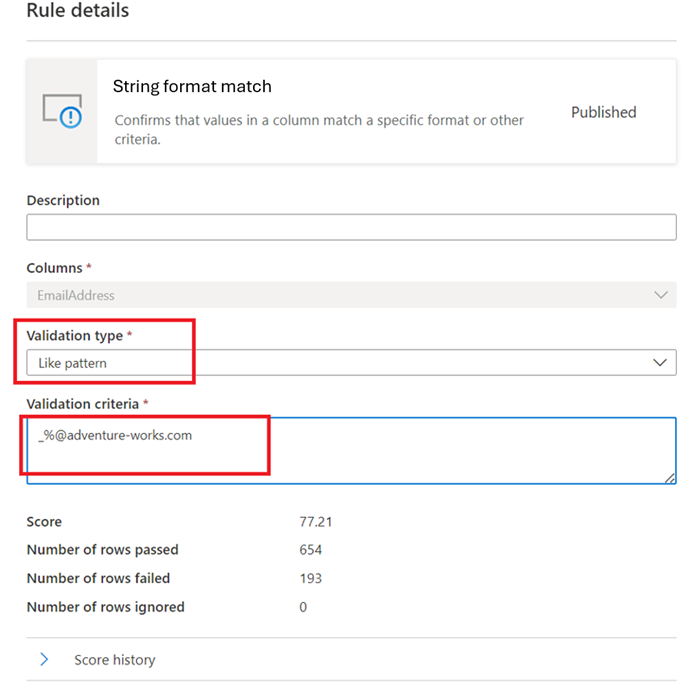
Modèle j’aime -
like(<string> : string, <pattern match> : string) => boolean
Le modèle est une chaîne qui correspond littéralement. Les exceptions sont les symboles spéciaux suivants : _ correspond à n’importe quel caractère dans l’entrée (similaire à . dansposixles expressions régulières) % correspond à zéro ou plusieurs caractères dans l’entrée (similaire à .* dansposixles expressions régulières). Le caractère d’échappement est « ». Si un caractère d’échappement précède un symbole spécial ou un autre caractère d’échappement, le caractère suivant est mis en correspondance littéralement. L’échappement d’un autre caractère n’est pas valide.like('icecream', 'ice%') -> true
Expression régulière –
regexMatch(<string> : string, <regex to match> : string) => boolean
Vérifie si la chaîne correspond au modèle d’expression régulière donné. Utilisez<regex>(guillemet précédent) pour faire correspondre une chaîne sans échappement.regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true
Correspondance du type de données
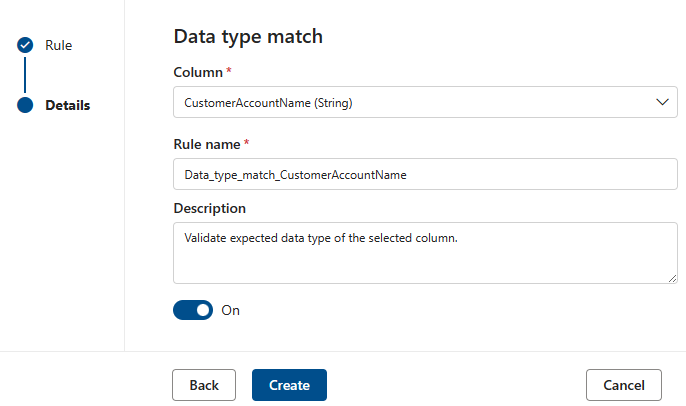
La règle de correspondance de type de données spécifie le type de données que la colonne associée doit contenir. Étant donné que le moteur de règle doit s’exécuter sur de nombreuses sources de données différentes, il ne peut pas utiliser de types natifs tels que BIGINT ou VARCHAR. Au lieu de cela, il a son propre système de type dans lequel il traduit les types natifs. Cette règle indique au moteur d’analyse de qualité les types intégrés vers lesquels le type natif doit être traduit. Le système de type de données provient du système de type Azure Data Flow utilisé dans Azure Data Factory.
Pendant une analyse de qualité, tous les types natifs sont testés par rapport au type de correspondance de type de données et s’il n’est pas possible de traduire le type natif en type de correspondance de type de données, cette ligne sera traitée comme étant en erreur.
Lignes dupliquées
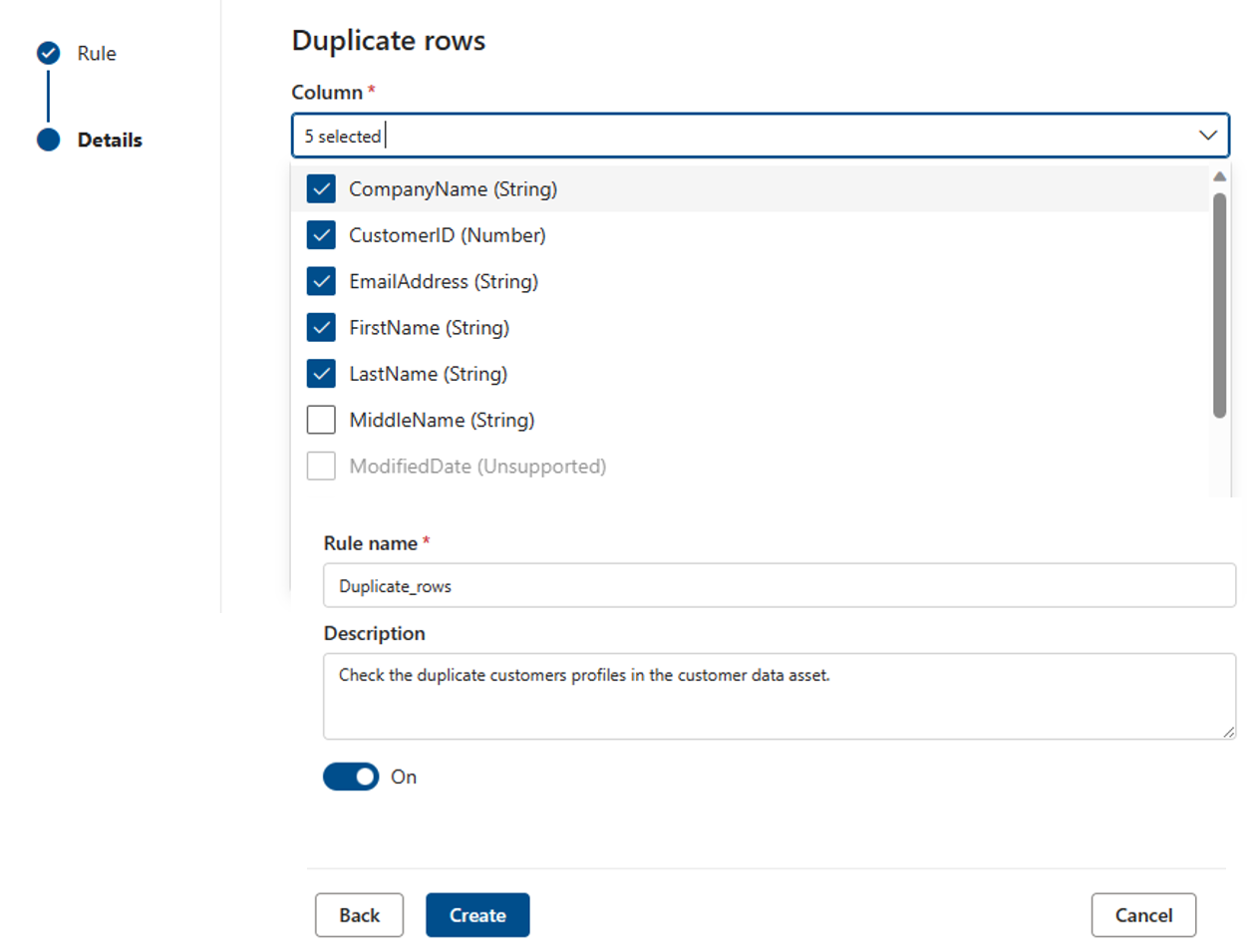
La règle Lignes en double vérifie si la combinaison des valeurs de la colonne est unique pour chaque ligne de la table.
Dans l’exemple ci-dessous, la concaténation de _CompanyName, CustomerID, EmailAddress, FirstName et LastName produit une valeur unique pour toutes les lignes de la table.
Chaque ressource peut avoir zéro ou un instance de cette règle.
Champs vides/vides
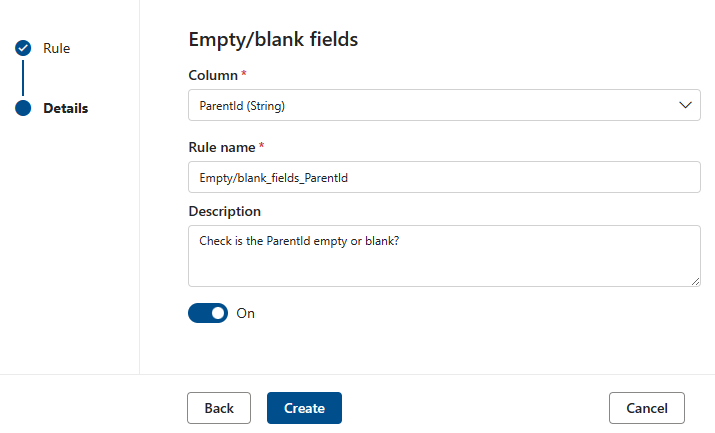
La règle champs vides/vides affirme que les colonnes identifiées ne doivent pas contenir de valeurs Null et, dans le cas spécifique des chaînes, aucune valeur vide ou espace blanc uniquement. Pendant une analyse de qualité, toute valeur de cette colonne qui n’est pas null sera traitée comme correcte. Cette règle affecte d’autres règles telles que les règles De valeurs uniques ou De correspondance de format . Si cette règle n’est pas définie sur une colonne, ces règles lorsqu’elles sont exécutées sur cette colonne ignorent automatiquement les valeurs Null. Si cette règle est définie sur une colonne, ces règles examinent les valeurs null/vides sur cette colonne et les considèrent à des fins de score.
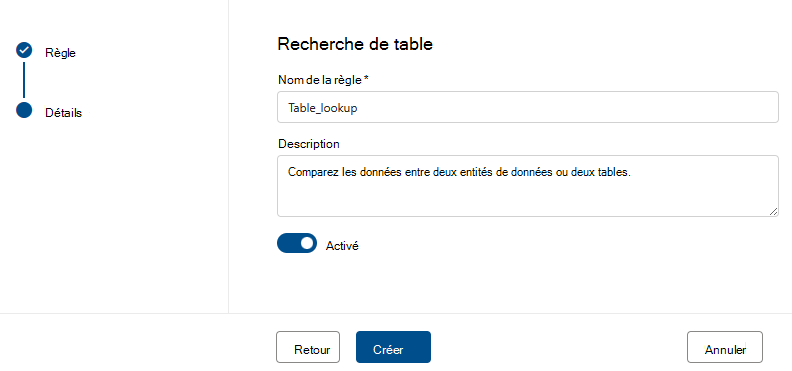
Recherche de table
La règle de recherche de table examine chaque valeur de la colonne sur laquelle la règle est définie et la compare à une table de référence. Par exemple, la table primaire comporte une colonne appelée « emplacement » qui contient des villes, des états et des codes postaux sous la forme « ville, zip d’état ». Il existe une table de référence, appelée citystate, qui contient toutes les combinaisons légales de villes, d’états et de codes postaux prises en charge dans le États-Unis. L’objectif est de comparer tous les emplacements de la colonne actuelle à cette liste de références pour s’assurer que seules les combinaisons juridiques sont utilisées.
Pour ce faire, nous tapons d’abord le nom de « citystatezip » dans la boîte de dialogue de recherche des ressources. Nous sélectionnons ensuite la ressource souhaitée, puis la colonne à laquelle nous voulons comparer.
Remarque
La table de référence ou la ressource de données doit appartenir au même domaine de gouvernance. La comparaison d’une ressource de données entre différents domaines de gouvernance n’est pas autorisée.
Règles personnalisées
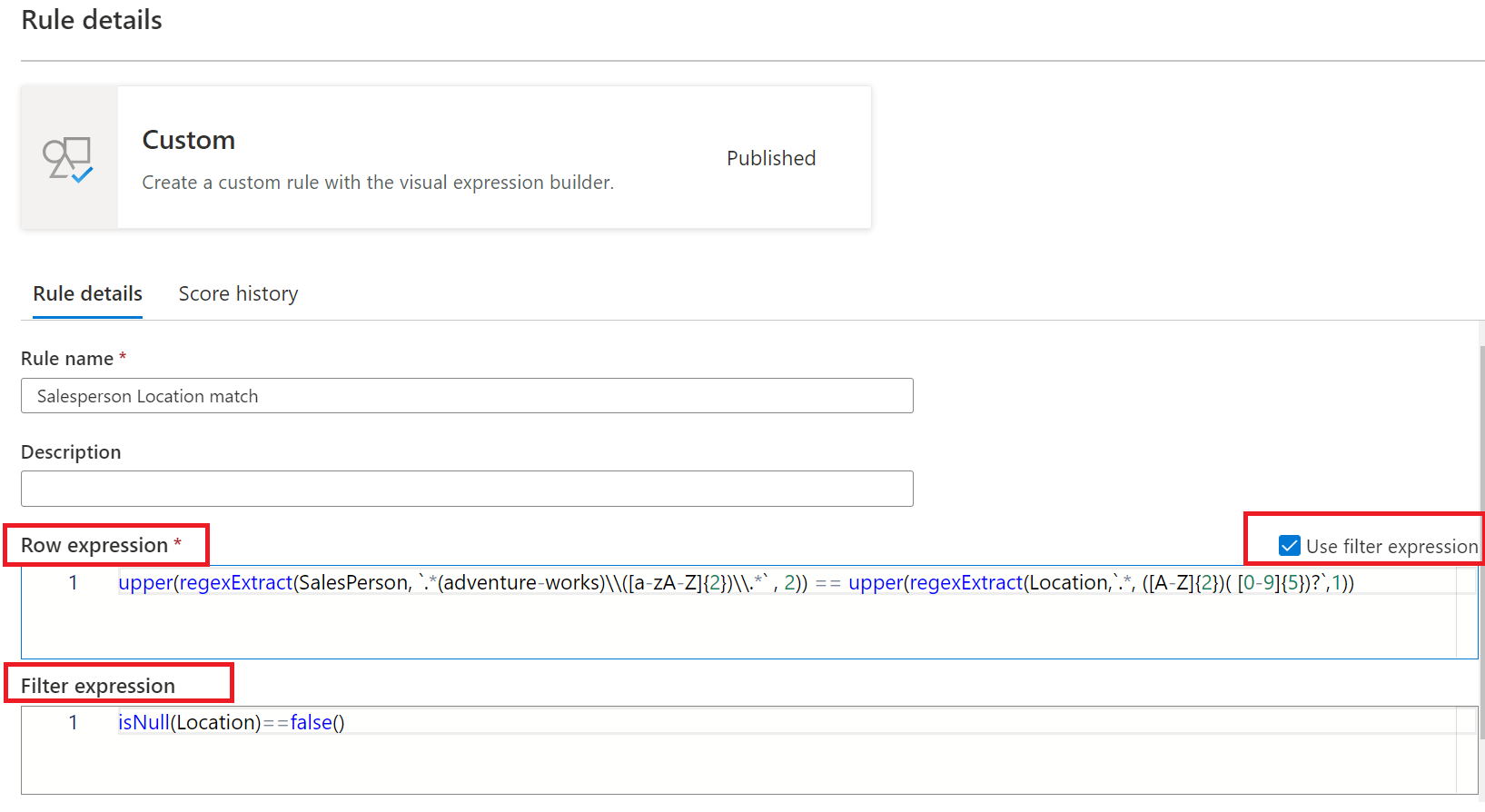
La règle personnalisée permet de spécifier des règles qui tentent de valider des lignes en fonction d’une ou plusieurs valeurs de cette ligne. La règle personnalisée comprend deux parties :
- La première partie est l’expression de filtre qui est facultative et est activée en sélectionnant la zone case activée par « Utiliser l’expression de filtre ». Il s’agit d’une expression qui retourne une valeur booléenne. L’expression de filtre sera appliquée à une ligne et si elle retourne true, cette ligne sera prise en compte pour la règle. Si l’expression de filtre retourne false pour cette ligne, cela signifie que cette ligne sera ignorée pour les besoins de cette règle. Le comportement par défaut de l’expression de filtre est de passer toutes les lignes. Par conséquent, si aucune expression de filtre n’est spécifiée et qu’une expression de filtre n’est pas requise, toutes les lignes sont prises en compte.
- La deuxième partie est l’expression de ligne. Il s’agit d’une expression booléenne appliquée à chaque ligne qui est approuvée par l’expression de filtre. Si cette expression retourne true, la ligne passe, si la valeur est false, elle est marquée comme un échec.
Exemples de règles personnalisées
| Scénario | Expression de ligne |
|---|---|
| Vérifiez si state_id est égal à la Californie et aba_Routing_Number correspond à un certain modèle d’expression régulière, et si la date de naissance se situe dans une certaine plage | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Vérifier si VendorID est égal à 124 | {VendorID}=='124' |
| Vérifier si fare_amount est égal ou supérieur à 100 | {fare_amount} >= "100" |
| Vérifiez si fare_amount est supérieur à 100 et tolls_amount n’est pas égal à 100 | {fare_amount} >= "100" || {tolls_amount} != "400" |
| Vérifier si l’évaluation est inférieure à 5 | Rating < 5 |
| Vérifier si le nombre de chiffres dans l’année est de 4 | length(toString(year)) == 4 |
| Comparer deux colonnes bbToLoanRatio et bankBalance à case activée si leurs valeurs sont égales | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| Vérifiez si le nombre de caractères supprimés et concaténés dans firstName, lastName, LoanID, uuid est supérieur à 20 | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| Vérifiez si aba_Routing_Number correspond à un modèle d’expression régulière, et si la date de transaction initiale est supérieure à 2022-11-12, et Disallow-Listed a la valeur false, et bankBalance moyenne est supérieure à 50000, et state_id est égal à « Massachuse », « Tennessee », « Dakota du Nord » ou « Albama » | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachuse' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Albama') |
| Vérifiez si aba_Routing_Number correspond à un modèle d’expression régulière et si dateOfBirth est compris entre 1968-12-13 et 2020-12-13 | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Vérifiez si le nombre de valeurs uniques dans aba_Routing_Number est égal à 1 000 000 et si le nombre de valeurs uniques dans EMAIL_ADDR est égal à 1 000 000 | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
L’expression de filtre et l’expression de ligne sont définies à l’aide du langage d’expression Azure Data Factory comme présenté ici avec le langage défini ici. Notez toutefois que toutes les fonctions définies pour le langage d’expression ADF générique ne sont pas disponibles. La liste complète des fonctions disponibles se trouve dans la liste Fonctions disponible dans la boîte de dialogue d’expression. Les fonctions suivantes définies ici ne sont pas prises en charge : isDelete, isError, isIgnore, isInsert, isMatch, isUpdate, isUpsert, partitionId, recherche mise en cache et Fonctions Window.
Remarque
<regex> (backquote) peut être utilisé dans les expressions régulières incluses dans les règles personnalisées pour faire correspondre une chaîne sans échappement de caractères spéciaux. Le langage d’expression régulière est basé sur Java et fonctionne comme indiqué ici.
Cette page identifie les caractères qui doivent être placés dans une séquence d’échappement.
Règles générées automatiquement par l’IA
La génération de règles automatisées assistées par l’IA pour la mesure de la qualité des données implique l’utilisation de techniques d’intelligence artificielle (IA) pour créer automatiquement des règles d’évaluation et d’amélioration de la qualité des données. Les règles générées automatiquement sont spécifiques au contenu. La plupart des règles courantes sont générées automatiquement afin que les utilisateurs n’ont pas besoin de faire autant d’efforts pour créer des règles personnalisées.
Pour parcourir et appliquer des règles générées automatiquement :
- Sélectionnez Suggérer des règles dans la page règles.
- Parcourez la liste des règles suggérées.

- Sélectionnez des règles dans la liste des règles suggérées à appliquer à la ressource de données.

Étapes suivantes
- Configurez et exécutez une analyse de la qualité des données sur un produit de données pour évaluer la qualité de toutes les ressources prises en charge dans le produit de données.
- Passez en revue les résultats de votre analyse pour évaluer la qualité actuelle des données de votre produit de données.