Qualité des données pour microsoft synapse serverless et entrepôt de données
Azure Synapse Analytics est un service d’analytique d’entreprise qui accélère le temps d’insight dans les entrepôts de données et les systèmes Big Data. Il réunit les meilleures technologies SQL utilisées dans l’entreposage de données d’entreprise, les technologies Apache Spark pour le Big Data et Azure Data Explorer pour l’analytique des journaux et des séries chronologiques.
Azure Synapse est un service d’analytique illimité qui regroupe l’entreposage de données d’entreprise et l’analytique Big Data. Il vous donne la liberté d’interroger des données selon vos conditions, à l’aide de ressources serverless ou dédiées, à grande échelle, pour plus d’informations sur Azure Synapse consultez la documentation Fabric.
Exemple d’espace de travail Synapse avec un instance de table Synapse Data Warehouse dédié (DWH) Table EMPLOYEE et une base de données serverless (SQL_ON_DEMAND) avec table SynapseSalesDelta.
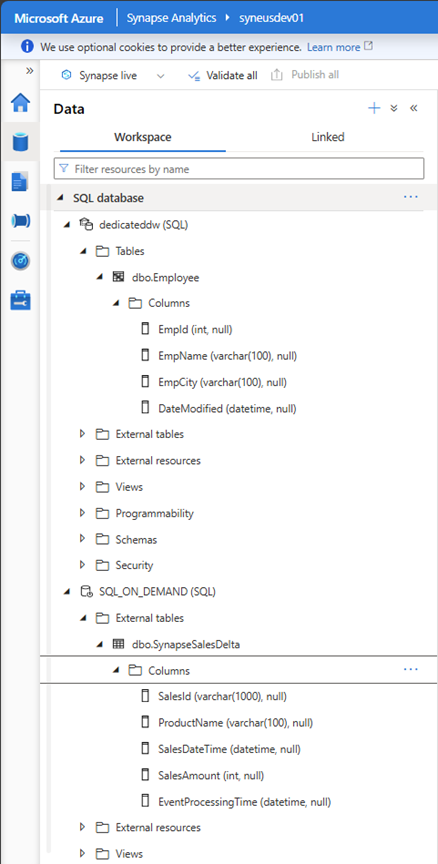
Une fois analysées, les ressources sont disponibles dans Microsoft Purview. Voici un exemple de table employee sur Synapse Analytics Dedicated instance.
analytique Azure Synapse dédiée (Data Warehouse)
Configurer l’analyse data map
Pour analyser Azure Synapse Analytics Dedicated (Data Warehouse), suivez la documentation : et pour accorder les autorisations mi nécessaires sur le instance DWH dédié, suivez la documentation.
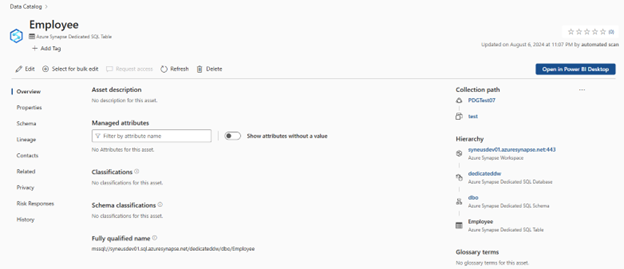
Une fois analysées, les ressources sont disponibles dans le catalogue Microsoft Purview. Voici un exemple de table employee sur Synapse Analytics Dedicated instance.
Configurer la connexion à votre entrepôt de données synapse dédié
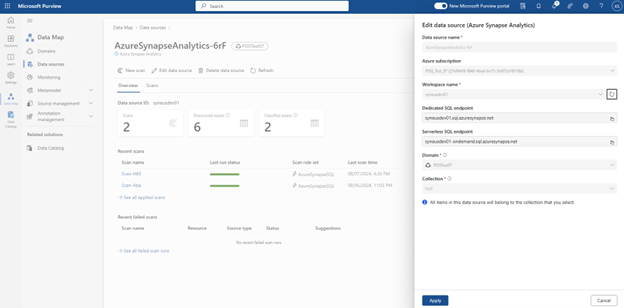
À ce stade, nous avons la ressource analysée prête pour le catalogage et la gouvernance. Associez la ressource analysée au produit de données dans un sele de domaine de gouvernance. Sous l’onglet Qualité des données, ajoutez un nouveau Azure SQL Connexion à la base de données : obtenir le nom de la base de données entré manuellement.
Sélectionnez l’onglet Gestion du domaine > de gouvernance de la qualité > des données pour créer la connexion.

Configurez la connexion dans la page de connexion.
- Ajoutez le nom et la description de la connexion.
- Sélectionnez le type de source Azure Synapse Analytics.
- Sélectionnez Abonnement Azure.
- Sélectionnez Nom de l’espace de travail.
- Sélectionnez Point de terminaison SQL dédié.
- Sélectionnez point de terminaison SQL serverless.
- Sélectionnez Type de point de terminaison.
- Sélectionnez Base de données.
- Ajoutez MSI en tant qu’informations d’identification.

Testez la connexion. Après avoir configuré la connexion à la source de données et l’avoir testée correctement, vous pouvez procéder à la configuration et à l’exécution des analyses de profilage des données et de la qualité des données.
Si votre source de données Synapse se trouve derrière un point de terminaison privé, vous devez activer le réseau virtuel managé. Suivez le document sur la configuration d’un réseau virtuel managé.


Importante
Les gestionnaires de la qualité des données ont besoin d’un accès en lecture seule à l’entrepôt de données synapse dédié pour configurer la connexion de qualité des données. Pour la configuration du réseau virtuel managé, vous ne pouvez pas tester la connexion.
Profilage et analyse de la qualité des données dans l’entrepôt de données synapse dédié
Une fois la configuration de la connexion terminée, vous pouvez profiler, créer et appliquer des règles, et exécuter l’analyse DQ de vos données dans l’entrepôt Synapse. Suivez les instructions pas à pas décrites dans les documents ci-dessous :
- Comment configurer et exécuter le profilage des données de vos données
- Comment configurer et exécuter l’analyse de la qualité des données
Importante
- Les performances des requêtes et même leurs exécutions réussies dépendent de la configuration DW dont disposent les clients pour leurs instances de base de données dédiées.
- Les travaux d’évaluation de la DQ respectifs ou, d’ailleurs, tout autre travail DQ induit une connexion sur le DW dédié et peut échouer si le instance est sous provisionné ou échoue sur les limites d’accès concurrentiel, les clients doivent être conscients de la configuration DW. Son accès concurrentiel a des limites très difficiles pour toute instance dans le temps.
- Les limites d’accès concurrentiel peuvent entraîner l’arrêt du travail. Les limites DW (telles que 1 000 DW) fournissent la puissance pour exécuter les requêtes.
- La prise en charge du réseau virtuel est en préversion avec la prise en charge de la disponibilité générale.
Azure Synapse Analytics serverless
Configurer l’analyse de la carte de données
Pour analyser Azure Synapse Analytics Serverless, suivez la documentation : et pour accorder les autorisations mi nécessaires sur le instance DWH dédié, suivez la documentation. Une fois analysées, les ressources serverless sont disponibles dans le catalogue Microsoft Purview.
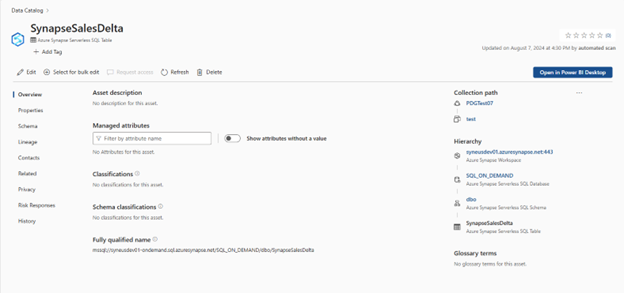
Configurer la connexion à votre synapse Serverless
À ce stade, nous avons la ressource analysée prête pour le catalogage et la gouvernance. Associez la ressource analysée au produit de données dans un sele de domaine de gouvernance. Dans Qualité des données, ajoutez un nouveau Azure SQL Connexion à la base de données : obtenir le nom de la base de données entré manuellement.
Sélectionnez l’ongletGestiondu domaine> de gouvernance de la qualité > des données pour créer la connexion.
Configurez la connexion dans la page de connexion.
- Ajoutez le nom et la description de la connexion.
- Sélectionnez le type de source Azure Synapse Analytics.
- Sélectionnez Abonnement Azure.
- Sélectionnez Nom de l’espace de travail.
- Sélectionnez Point de terminaison SQL dédié.
- Sélectionnez point de terminaison SQL serverless.
- Sélectionnez Type de point de terminaison.
- Sélectionnez Base de données.
- Ajoutez MSI en tant qu’informations d’identification.
Testez la connexion. Après avoir configuré la connexion à la source de données et l’avoir testée correctement, vous pouvez procéder à la configuration et à l’exécution des analyses de profilage des données et de la qualité des données.
Si votre source de données Synapse se trouve derrière un point de terminaison privé, vous devez activer le réseau virtuel managé. Suivez le document sur la configuration d’un réseau virtuel managé.
Importante
- Les gestionnaires de la qualité des données ont besoin d’un accès en lecture seule à l’entrepôt de données synapse dédié pour configurer la connexion de qualité des données.
- Dans l’installation serverless de Synapse, la table externe pointe vers des données au format Delta stockées dans ADLS Gen2.
- La prise en charge du réseau virtuel est en préversion contrôlée. Contactez l’équipe des ventes Purview pour autoriser votre locataire pour la préversion contrôlée.
- Synapse Connector détecte et prend uniquement en charge les sql.azuresynapse.net. Si le nom complet (FQN) généré par votre analyse Mmap de données contient database.windows.net, votre connexion Synapse pour l’analyse DQ échoue.
Profilage et analyse de la qualité des données (DQ) pour les données dans synapse serverless
Une fois la configuration de la connexion terminée, vous pouvez profiler, créer et appliquer des règles, et exécuter l’analyse de la qualité des données (DQ) de vos données dans l’entrepôt Synapse. Suivez les instructions pas à pas décrites dans les documents ci-dessous :
- Comment configurer et exécuter le profilage des données de vos données
- Comment configurer et exécuter l’analyse de la qualité des données
Importante
- Les évaluations DQ, le profilage s’exécutent sur Spark en arrière-plan, les clients auront plusieurs connexions où chaque nœud Spark aura une connexion SPID. DWH peut donc rencontrer les limites de requête actuelles s’il est utilisé/planifié au-delà des limites DW, ce qui entraîne des échecs. Mais pour Azure Synapse table SQL serverless , aucune limite d’accès concurrentiel de ce type ne s’applique ; cela dépend totalement des optimisations parquet delta serverless que les clients ont sur leur instance ADLS Gen2. Le moteur peut être considéré comme résonant étroitement Databricks Serverless DW fonctionnent sur des sources Lakehouse externes telles que des tables au format DELTA.