Scénario de bout en bout de Lakehouse : vue d’ensemble et architecture
Microsoft Fabric est une solution d’analytique tout-en-un pour les entreprises qui couvre tout, du déplacement des données à la science des données, à l’analytique en temps réel et au décisionnel. Il offre une suite complète de services, y compris le lac de données, l’engineering données et l’intégration des données, le tout au même endroit. Pour plus d’informations, voir Qu’est-ce que Microsoft Fabric ?
Ce tutoriel vous guide tout au long d’un scénario de bout en bout, de l’acquisition de données à la consommation de données. Il vous aide à développer une compréhension de base de Fabric, y compris les différentes expériences et la façon dont elles s’intègrent, ainsi que les expériences de développement professionnel et citoyen qui accompagnent l’utilisation de cette plateforme. Ce tutoriel n’est pas destiné à être une architecture de référence, une liste exhaustive de caractéristiques et de fonctionnalités ou une recommandation de meilleures pratiques spécifiques.
Scénario de bout en bout de Lakehouse
Traditionnellement, les organisations créent des entrepôts de données modernes pour leurs besoins d’analytique des données transactionnelles et structurées, ainsi que des data lakehouses pour les besoins d’analytique de données Big Data (semi/non structurée). Ces deux systèmes fonctionnaient en parallèle, créant des silos, des duplications des données et augmentant le coût total de possession.
Fabric, avec son unification du magasin de données et de la normalisation au format Delta Lake, vous permet d’éliminer les silos, de supprimer la duplication des données et de réduire considérablement le coût total de possession.
Grâce à la flexibilité offerte par Fabric, vous pouvez mettre en œuvre des architectures lakehouse ou d’entrepôt de données ou les combiner pour tirer le meilleur des deux avec une implémentation simple. Dans ce tutoriel, vous allez prendre un exemple d’organisation de vente au détail et créer son lakehouse du début à la fin. Il utilise l’architecture de médaillon où la couche de bronze contient les données brutes, la couche argent a les données validées et dédupliquées, et la couche or présente des données hautement affinées. Vous pouvez adopter la même approche pour implémenter un Lakehouse pour n’importe quel organisation de n’importe quel secteur.
Ce tutoriel explique comment un développeur de la société fictive Wide World Importers du domaine de vente au détail effectue les étapes suivantes :
Connectez-vous à votre compte Power BI et inscrivez-vous à l’essai gratuit de Microsoft Fabric. Si vous n’avez pas de licence Power BI, inscrivez-vous à une licence gratuite Fabric, puis vous pouvez démarrer la version d’évaluation de Fabric.
Créez et implémentez un lakehouse de bout en bout pour votre organisation :
- Créer un espace de travail Fabric.
- Créer un lakehouse.
- Ingérer des données, transformer des données et les charger dans le lakehouse. Vous pouvez également explorer OneLake, une copie de vos données en mode Lakehouse et en mode point de terminaison d’analytique SQL.
- Connectez-vous à votre lakehouse à l’aide du point de terminaison d’analytique SQL et créez un rapport Power BI à l’aide de DirectLake pour analyser les données de vente dans différentes dimensions.
- Si vous le souhaitez, vous pouvez orchestrer et planifier l’ingestion et le flux de transformation des données avec un pipeline.
Nettoyez les ressources en supprimant l’espace de travail et d’autres éléments.
Architecture
L’image suivante montre l’architecture de bout en bout de lakehouse. Les composants impliqués sont décrits dans la liste suivante.
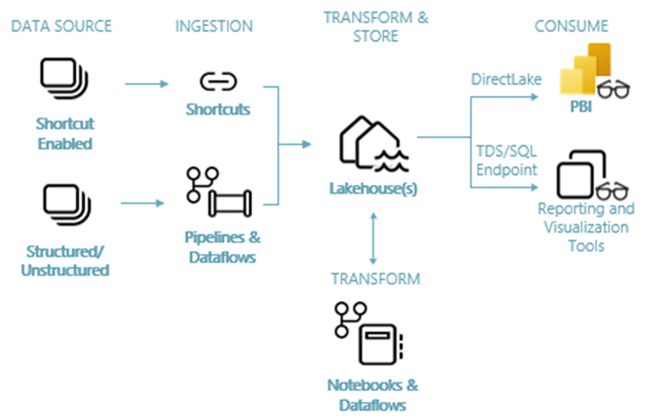
Sources de données : Fabric permet de se connecter rapidement et facilement à Azure Data Services, ainsi qu’à d’autres plateformes cloud et sources de données locales, pour une ingestion simplifiée des données.
Ingestion : vous pouvez rapidement générer des insights pour votre organisation à l’aide de plus de 200 connecteurs natifs. Ces connecteurs sont intégrés au pipeline Fabric et utilisent la transformation de données par glisser-déplacer facile à utiliser avec le flux de données. En outre, avec la fonctionnalité Raccourci dans Fabric, vous pouvez vous connecter à des données existantes, sans avoir à les copier ou à les déplacer.
Transformer et stocker : la structure est standardisée au format Delta Lake. Cela signifie que tous les moteurs de Fabric peuvent accéder au même jeu de données stocké dans OneLake et les manipuler sans les dupliquer. Ce système de stockage offre la possibilité de créer des lakehouses à l’aide d’une architecture de médaillon ou d’un maillage de données, en fonction des besoins de votre organisation. Vous pouvez choisir entre une expérience à faible code ou sans code pour la transformation des données, en utilisant des pipelines/flux de données ou un notebook/Spark pour une expérience code-first.
Consommer : Power BI peut consommer des données de Lakehouse à des fins de création de rapports et de visualisation. Chaque Lakehouse dispose d’un point de terminaison TDS intégré, appelé point de terminaison d’analytique SQL, qui vous permet de vous connecter aux données et de les interroger facilement dans les tables Lakehouse à partir d’autres outils de reporting. Le point de terminaison d’analytique SQL fournit aux utilisateurs la fonctionnalité de connexion SQL.
Exemple de jeu de données
Ce tutoriel utilise l’exemple de base de données Wide World Importers (WWI), que vous allez importer dans le lakehouse dans le tutoriel suivant. Pour le scénario lakehouse de bout en bout, nous avons généré suffisamment de données pour explorer les fonctionnalités de mise à l’échelle et de performances de la plateforme Fabric.
Wide World Importers (WWI) est un importateur et distributeur de produits de nouveauté de gros qui opère à partir de la baie de San Francisco. En tant que grossiste, les clients de la WWI sont principalement des entreprises qui revendent aux particuliers. La WWI vend aux clients de vente au détail dans les États-Unis y compris les magasins spécialisés, les supermarchés, les magasins informatiques, les magasins d’attraction touristique et certains individus. WWI vend également à d'autres grossistes via un réseau d'agents qui assurent la promotion des produits au nom de WWI. Pour en savoir plus sur le profil et le fonctionnement de l’entreprise, consultez Exemples de bases de données Wide World Importers pour Microsoft SQL.
En général, les données sont introduites à partir de systèmes transactionnels ou d’applications métier dans un lakehouse. Toutefois, pour simplifier ce tutoriel, nous utilisons le modèle dimensionnel fourni par WWI comme source de données initiale. Nous l’utilisons comme source pour ingérer les données dans un lakehouse et les transformer à travers différentes étapes (bronze, argent et or) d’une architecture de médaillon.
Modèle de données
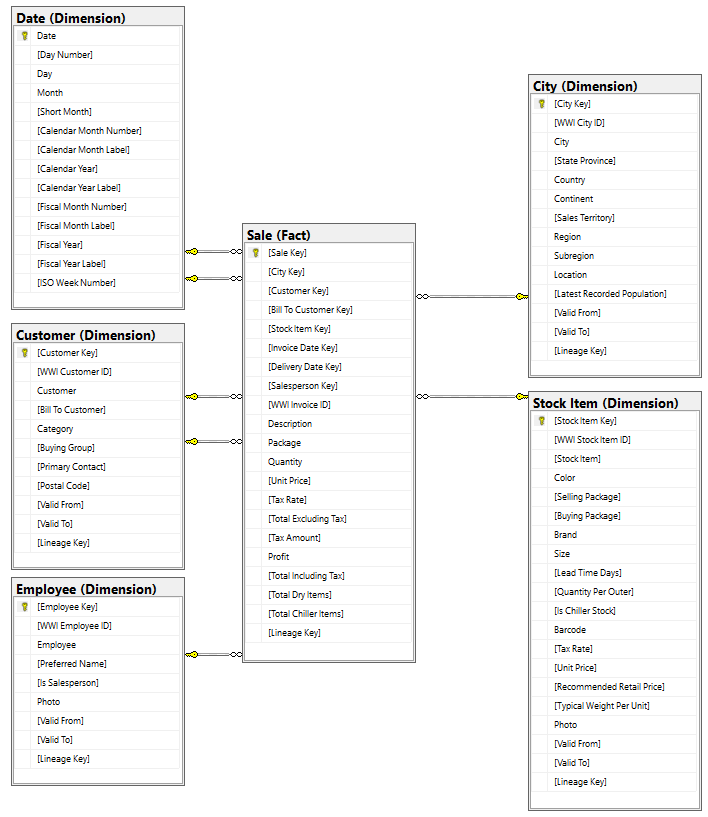
Bien que le modèle dimensionnel de la Première Guerre mondiale contienne de nombreuses tables de faits, pour ce tutoriel, nous utilisons la table de faits Ventes et ses dimensions corrélées. L’exemple suivant illustre le modèle de données de WWI :
Flux de données et de transformation
Comme décrit précédemment, nous utilisons les exemples de données de Wide World Importers (WWI) pour générer ce lakehouse de bout en bout. Dans cette implémentation, les exemples de données sont stockés dans un compte de stockage d’Azure Data au format de fichier Parquet pour toutes les tables. Toutefois, dans des scénarios réels, les données proviennent généralement de différentes sources et dans différents formats.
L’image suivante montre la source, la destination et la transformation des données :
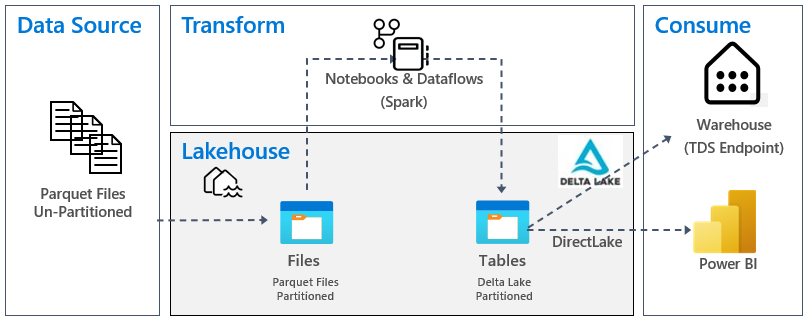
Source de données : les données sources sont au format de fichier Parquet et dans une structure non partitionnée. Il est stocké dans un dossier pour chaque table. Dans ce tutoriel, nous avons configuré un pipeline pour ingérer les données historiques complètes ou ponctuelles dans lakehouse.
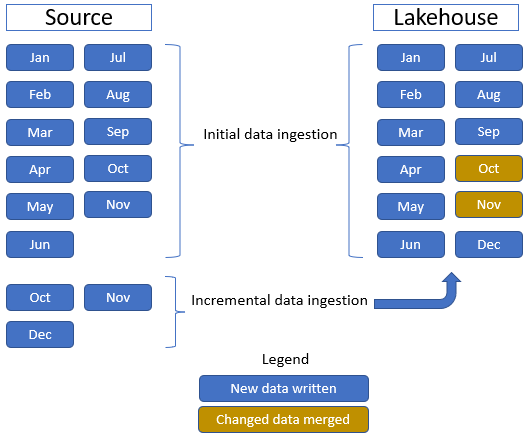
Dans ce tutoriel, nous utilisons la table de faits Sale, qui a un dossier parent avec des données historiques pendant 11 mois (avec un sous-dossier pour chaque mois) et un autre dossier contenant des données incrémentielles pendant trois mois (un sous-dossier par mois). Pendant l’ingestion initiale des données, les 11 mois de données sont ingérés dans la table lakehouse. Toutefois, lorsque les données incrémentielles arrivent, elles incluent des données mises à jour pour octobre et novembre, et de nouvelles données pour décembre. Les données d’octobre et de novembre sont fusionnées avec les données existantes et les nouvelles données de décembre sont écrites dans la table lakehouse, comme illustré dans l’image suivante :
Lakehouse : dans ce didacticiel, vous allez créer un lakehouse, ingérer des données dans la section fichiers du lakehouse, puis créer des tables delta lake dans la section Tables du lakehouse.
Transformation : pour la préparation et la transformation des données, il existe deux approches différentes. Nous démontrons l’utilisation de Notebooks/Spark pour les utilisateurs qui préfèrent une expérience code-first et l’utilisation des pipelines/flux de données pour les utilisateurs qui préfèrent une expérience à faible code ou sans code.
Consommer : pour illustrer la consommation des données, regardez comment utiliser la fonctionnalité DirectLake de Power BI pour créer des rapports, des tableaux de bord et interroger directement des données à partir du lakehouse. Nous montrons aussi comment rendre vos données disponibles pour des outils de reporting tiers avec le point de terminaison TDS/d’analytique SQL. Ce point de terminaison vous permet de vous connecter à l’entrepôt et d’exécuter des requêtes SQL pour l’analytique.