Tutoriel Lakehouse : ingérer des données dans le lakehouse
Dans ce tutoriel, vous allez ingérer davantage de tables de faits et de dimensions à partir de Wide World Importers (WWI) dans le lakehouse.
Prérequis
- Si vous n’avez pas de lakehouse, vous devez en créer un.
Ingérer des données
Dans cette section, vous allez utiliser l’activité Copier des données du pipeline Data Factory pour ingérer des exemples de données d’un compte de stockage Azure vers la section Fichiers du lakehouse que vous avez créé précédemment.
Sélectionnez Espaces de travail dans le volet de navigation gauche, puis votre nouvel espace de travail dans le menu Espaces de travail. La vue Éléments de votre espace de travail s’affiche.
Dans l’option Nouvel élément du ruban de l’espace de travail, sélectionnez Pipeline de données.
Dans la boîte de dialogue Nouveau pipeline, spécifiez le nom IngestDataFromSourceToLakehouse, puis sélectionnez Créer. Un pipeline de fabrique de données est créé et ouvert.
Ensuite, configurez une connexion HTTP pour importer les exemples de données World Wide Importers dans le lakehouse. Dans la liste des Nouvelles sources, sélectionnez Afficher plus, recherchez HTTP et sélectionnez-le.
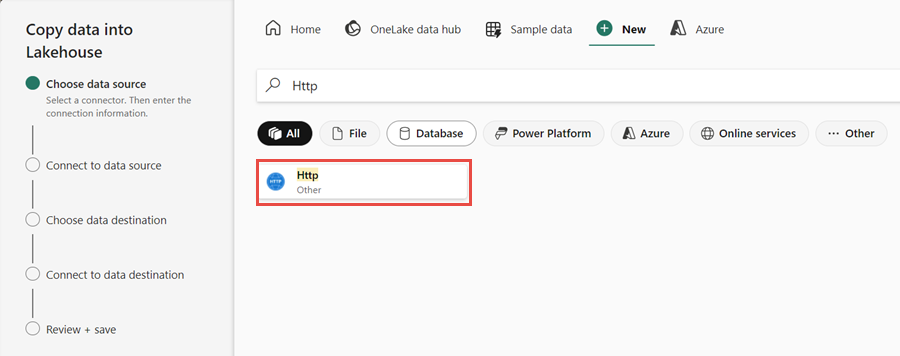
Dans la fenêtre Se connecter à la source de données, entrez les détails du tableau ci-dessous, puis sélectionnez Suivant.
Propriété Valeur URL https://assetsprod.microsoft.com/en-us/wwi-sample-dataset.zipConnexion Créer une connexion Nom de la connexion wwisampledata Passerelle de données Aucun(e) Type d'authentification Anonyme 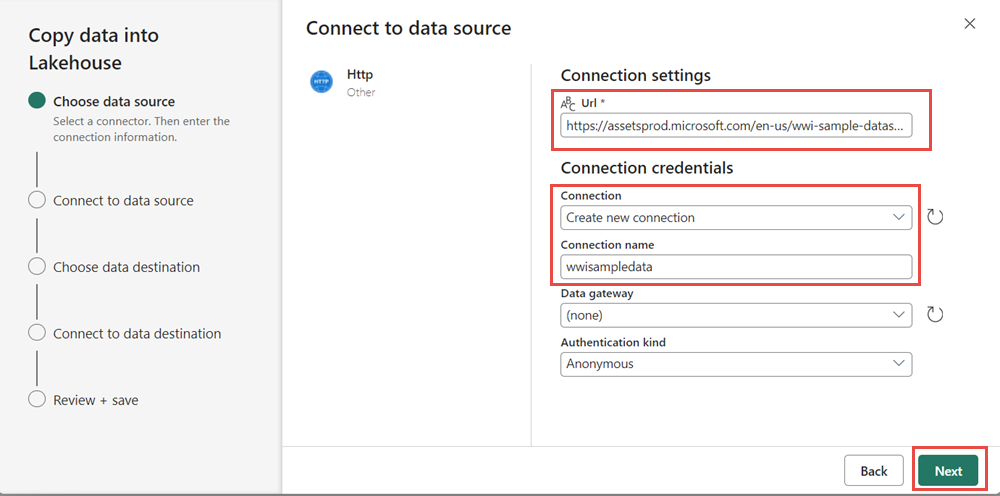
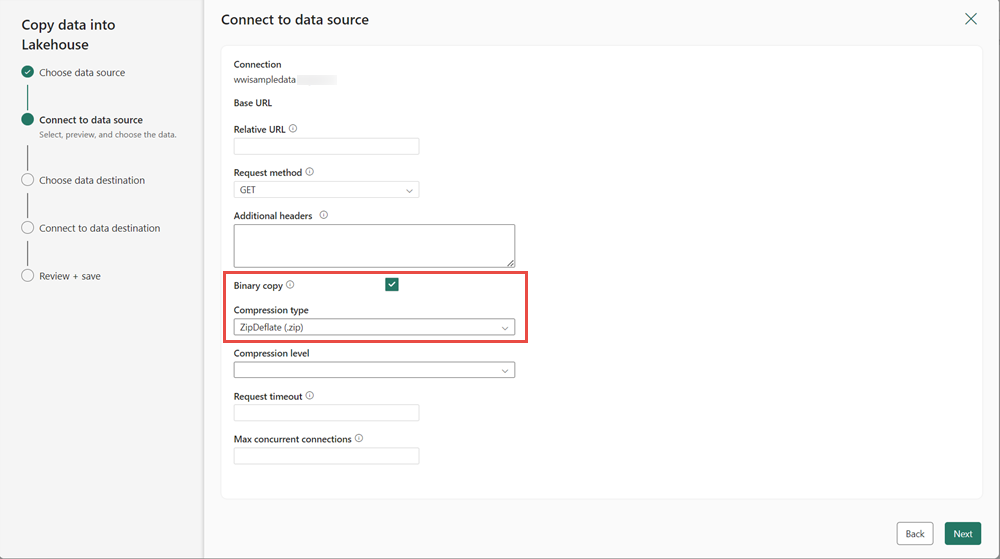
À l’étape suivante, activez la copie binaire et choisissez ZipDeflate (.zip) comme Type de compression, car la source est un fichier .zip. Conservez les valeurs par défaut des autres champs, puis cliquez sur Suivant.
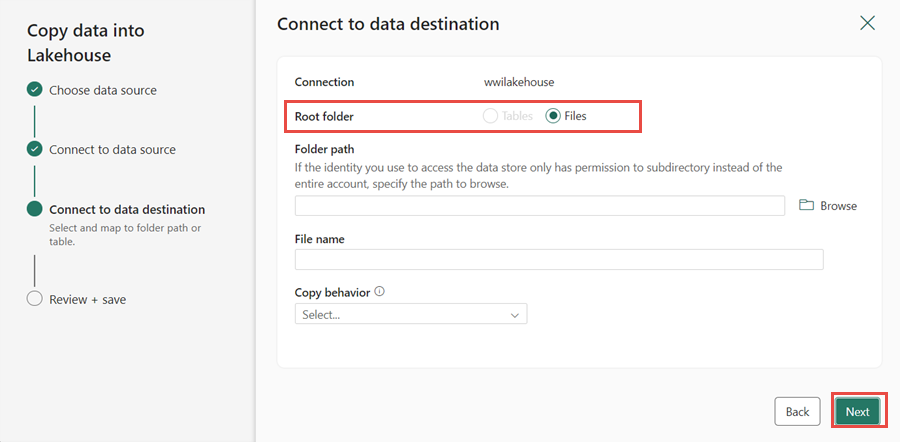
Dans la fenêtre Se connecter à la destination des données, spécifiez Fichiers comme Dossier racine, puis sélectionnez Suivant. Cela écrit les données dans la section Fichiers du lakehouse.
Choisissez Binaire comme Format de fichier pour la destination. Sélectionnez Suivant, puis Enregistrer + exécuter. Vous pouvez planifier des pipelines pour actualiser régulièrement les données. Dans ce tutoriel, nous n’exécutons le pipeline qu’une seule fois. Le processus de copie de données prend environ 10-15 minutes.
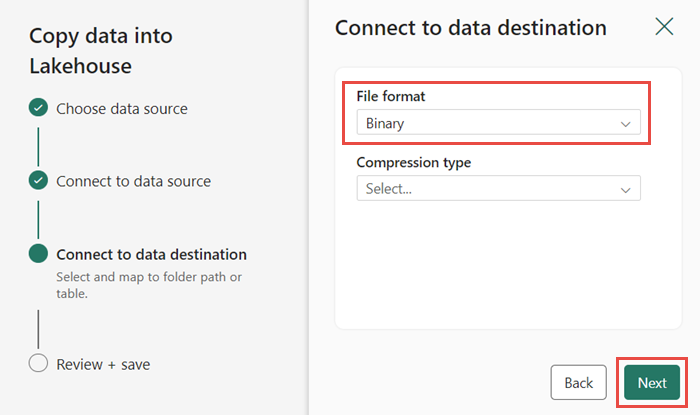
Vous pouvez surveiller l’exécution et l’activité du pipeline sous l’onglet Sortie. Vous pouvez également afficher des informations détaillées sur le transfert de données en sélectionnant l’icône de lunettes en regard du nom du pipeline, qui apparaît lorsque vous pointez sur le nom.
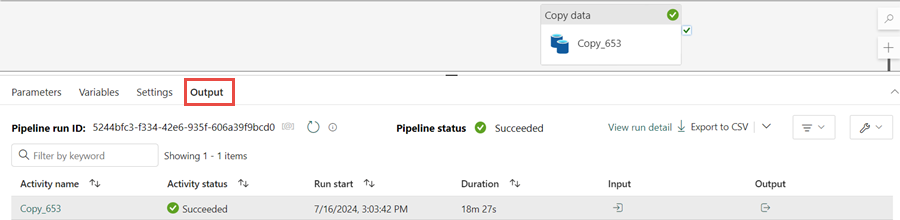
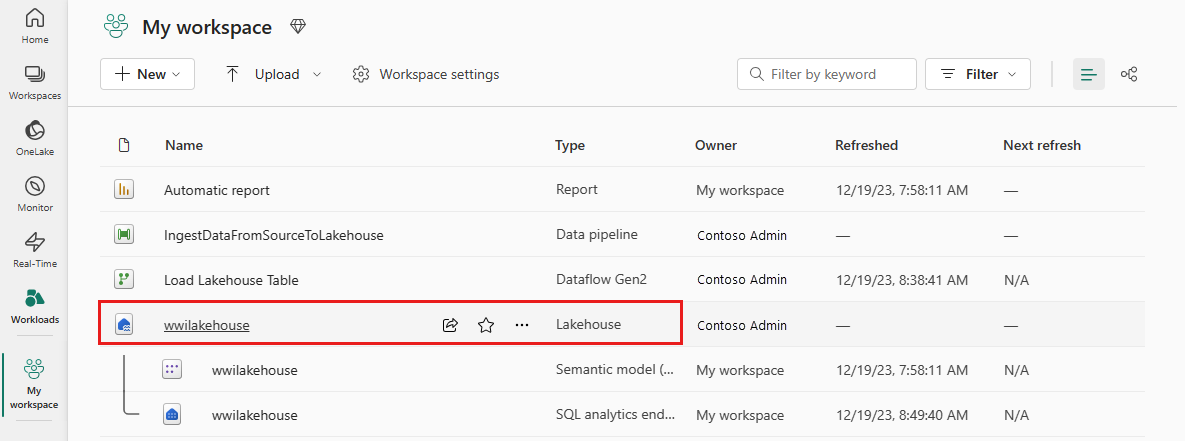
Après l’exécution réussie du pipeline, accédez à votre lakehouse (wwilakehouse) et ouvrez l’explorateur pour afficher les données importées.
Vérifiez que le dossier WideWorldImportersDW est présent dans la vue Explorateur et contient des données pour toutes les tables.
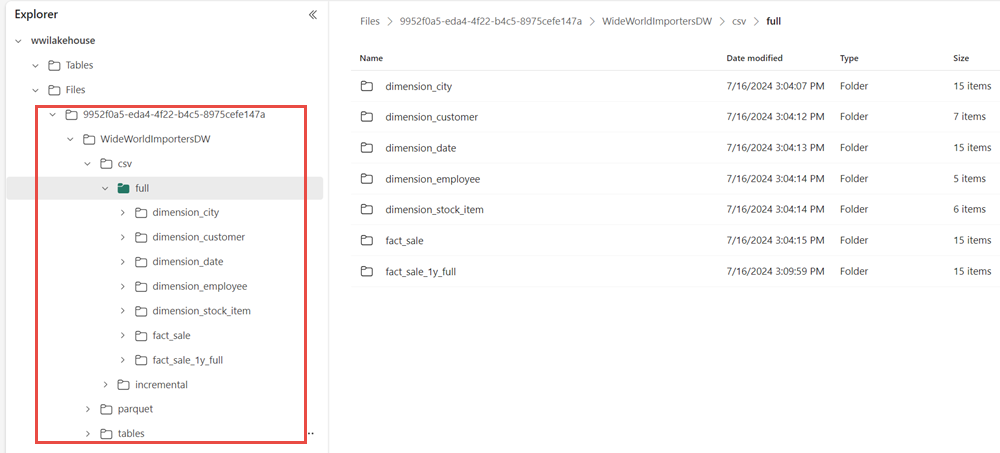
Les données sont créées dans la section Fichiers de l’explorateur de lakehouse. Un nouveau dossier avec GUID contient toutes les données nécessaires. Renommez le GUID wwi-raw-data.

Pour charger des données incrémentielles dans un lakehouse, voir Charger de manière incrémentielle des données de Data Warehouse vers Lakehouse.