Tutoriel Lakehouse : Créer un lakehouse, ingérer des exemples de données et générer un rapport
Dans ce tutoriel, vous allez créer un lakehouse, ingérer des exemples de données dans la table Delta, appliquer une transformation si nécessaire, puis créer des rapports. Dans ce tutoriel, vous allez découvrir comment :
- Créer une maison du lac dans Microsoft Fabric
- Télécharger et ingérer des exemples de données client
- Ajouter des tables au modèle sémantique
- Créer un rapport
Si vous n’avez pas de Microsoft Fabric, inscrivez-vous à une capacité d’essai gratuite.
Prérequis
- Avant de pouvoir créer un lakehouse, vous devez créer un espace de travail Fabric.
- Avant d’ingérer un fichier CSV, vous devez avoir configuré OneDrive. Si vous n’avez pas configuré OneDrive, inscrivez-vous à l’essai gratuit de Microsoft 365 : Essai gratuit - Essayez Microsoft 365 pendant un mois.
Créer un lakehouse.
Dans cette section, vous allez créer un "lakehouse" dans Fabric.
Dans Fabric, sélectionnez Espaces de travail dans la barre de navigation.
Pour ouvrir votre espace de travail, entrez son nom dans la zone de recherche située en haut et sélectionnez-le dans les résultats de la recherche.
Dans l’espace de travail, sélectionnez Nouvel élément, puis Lakehouse.
Dans la boîte de dialogue Nouveau lakehouse , entrez wwilakehouse dans le champ Nom.
Sélectionnez Créer pour créer et ouvrir le nouveau lakehouse.
Ingérer des exemples de données
Dans cette section, vous allez ingérer des exemples de données client dans le lakehouse.
Remarque
Si vous n’avez pas configuré OneDrive, inscrivez-vous à l’essai gratuit de Microsoft 365 : Essai gratuit - Essayez Microsoft 365 pendant un mois.
Téléchargez le fichier dimension_customer.csv à partir du référentiel d’exemples Fabric.
Dans l’onglet Accueil, sous Obtenir des données dans votre lakehouse, vous voyez les options permettant de charger des données dans le lakehouse. Sélectionnez Nouveau Dataflow Gen2.
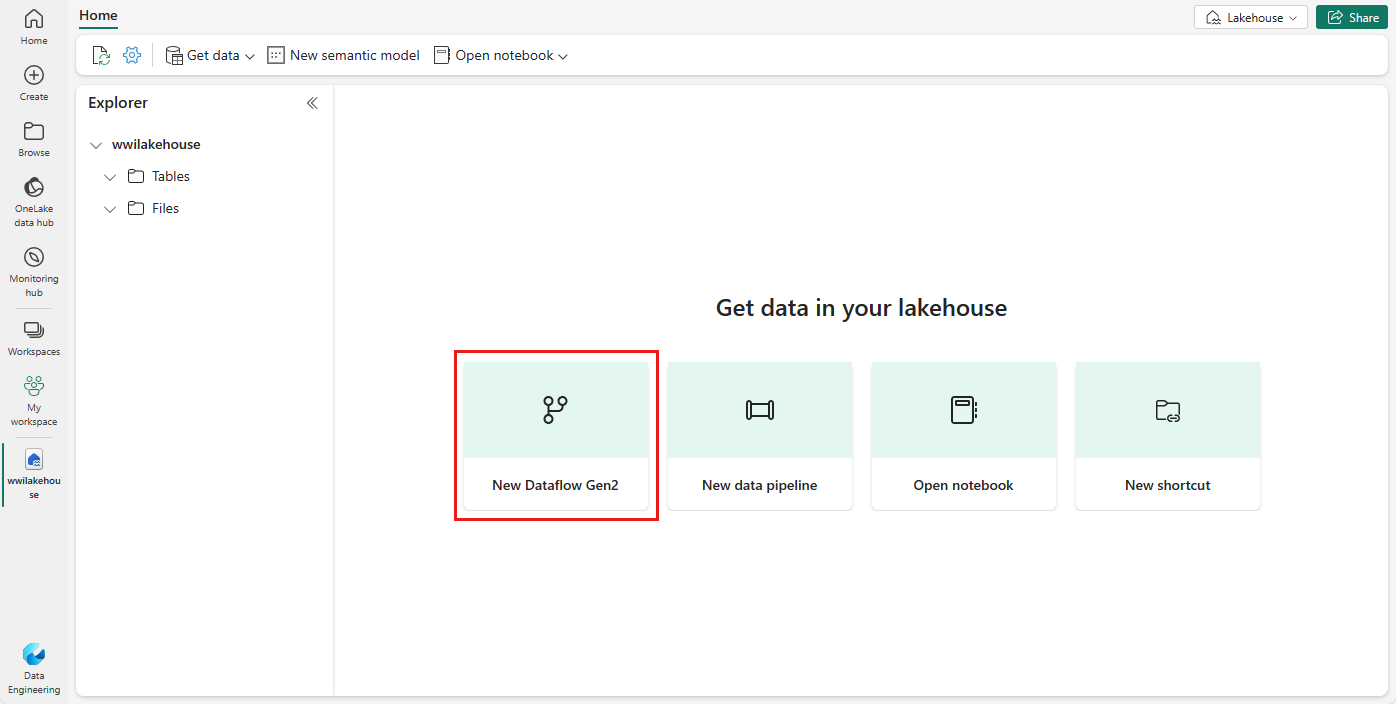
Dans l’écran Nouveau flux de données, sélectionnez Importer à partir d’un fichier Texte/CSV.
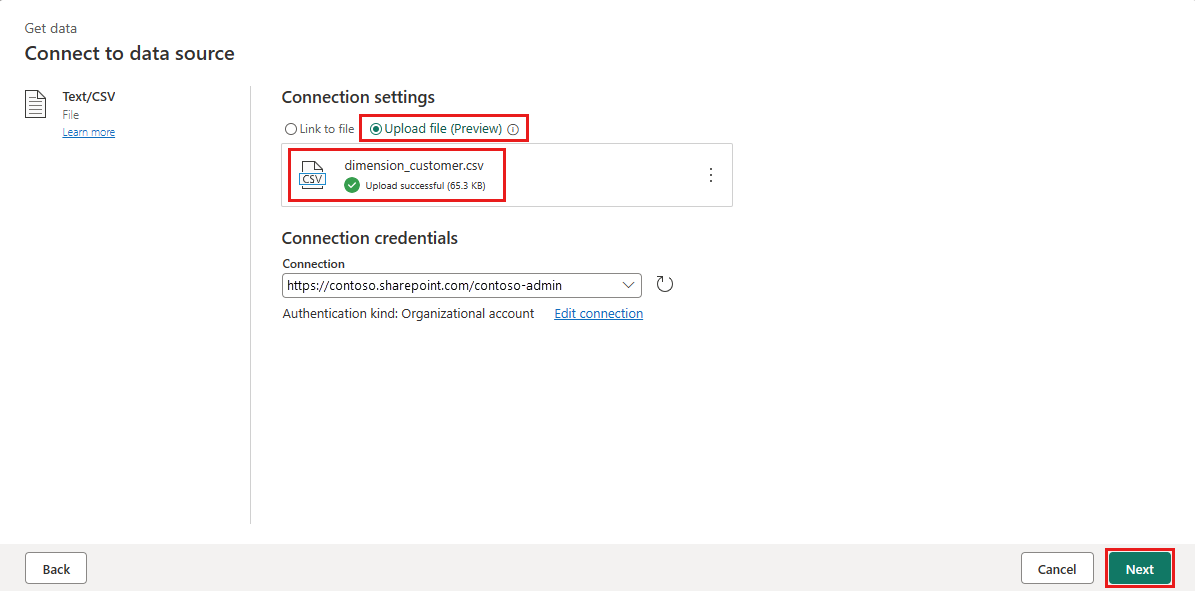
Dans l’écran Se connecter à la source de données, sélectionnez le bouton radio Charger le fichier. Faites glisser et déposez le fichier dimension_customer.csv que vous avez téléchargé à l’étape 1. Une fois le fichier chargé, sélectionnez Suivant.
Dans la page Aperçu des données du fichier, affichez un aperçu des données, puis sélectionnez Créer pour continuer et revenir au canevas du flux de données.
Dans le volet Paramètres de la requête, mettez à jour le champ Nom avec dimension_customer.
Remarque
Fabric ajoute un espace et un nombre à la fin du nom de la table par défaut. Les noms de table doivent être en minuscules et ne doivent pas contenir d’espaces. Renommez-le correctement et supprimez les espaces du nom de la table.
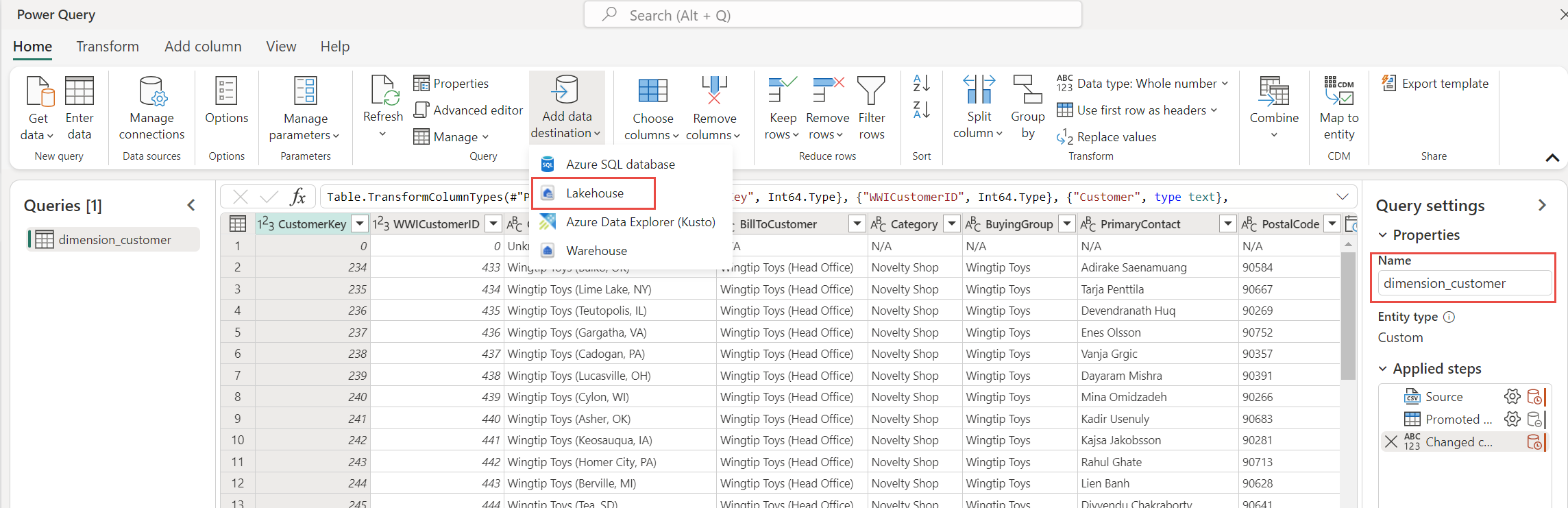
Dans ce tutoriel, vous avez associé les données client à un lakehouse. Si vous avez d’autres éléments de données que vous souhaitez associer au lakehouse, vous pouvez les ajouter :
Dans les éléments de menu, sélectionnez Ajouter une destination de données, puis lakehouse. À partir de l’écran Se connecter à la destination des données, connectez-vous à votre compte si nécessaire et sélectionnez Suivant.
Accédez à la wwilakehouse de votre espace de travail.
Si la table dimension_customer n’existe pas, sélectionnez le paramètre Nouvelle table et entrez le nom de la table dimension_customer. Si la table existe déjà, sélectionnez le paramètre Table existante et choisissez dimension_customer dans la liste des tables de l’Explorateur d’objets. Cliquez sur Suivant.
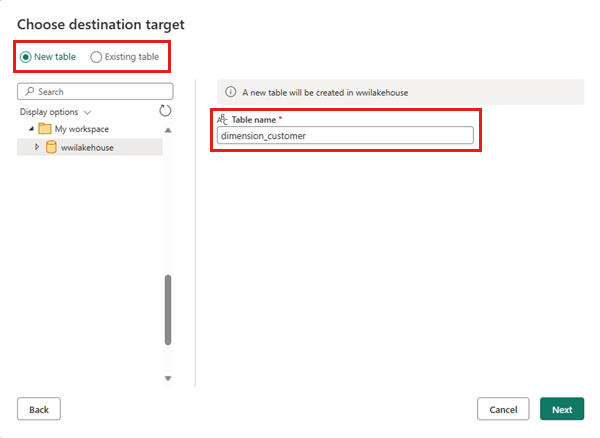
Dans le volet Choisir les paramètres de destination , sélectionnez Remplacer comme méthode Mise à jour. Sélectionnez Enregistrer les paramètres pour revenir au canevas du flux de données.
À partir du canevas de flux de données, vous pouvez facilement transformer les données en fonction des besoins de votre entreprise. Par souci de simplicité, nous n’apportons aucune modification dans ce tutoriel. Pour continuer, sélectionnez Publier en bas à droite de l’écran.
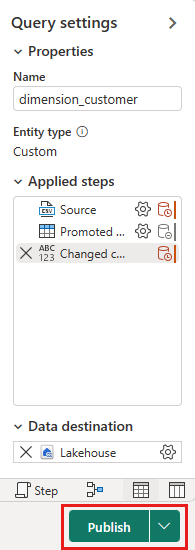
Un cercle tournant en regard du nom du flux de données indique que la publication est en cours dans la vue d’élément. Une fois la publication terminée, sélectionnez ... et sélectionnez Propriétés. Renommez le flux de données en Charger la table Lakehouse et sélectionnez Enregistrer.
Sélectionnez l’option Actualiser maintenant en regard du nom du flux de données pour actualiser le flux de données. Cette option exécute le flux de données et déplace les données du fichier source vers la table lakehouse. Pendant qu’il est en cours, vous voyez un cercle tournant sous colonne Actualisée dans l’affichage d’élément.
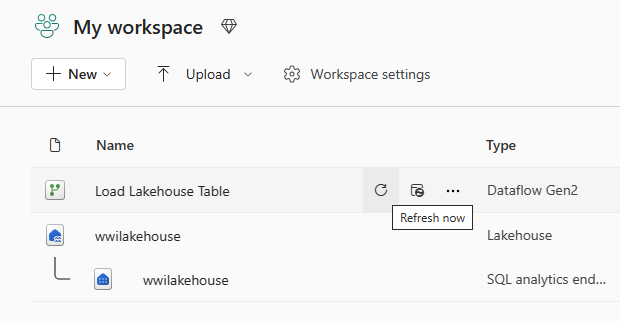
Une fois le flux de données actualisé, sélectionnez votre nouveau lakehouse dans la barre de navigation pour afficher la table Delta dimension_customer.
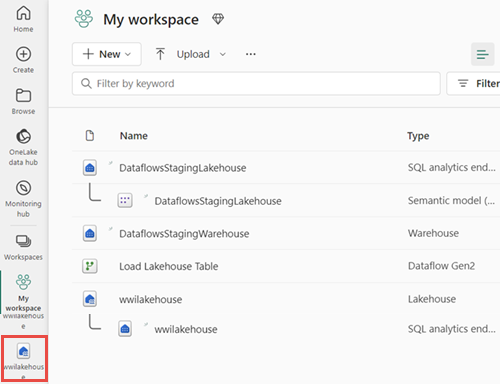
Sélectionnez la table pour afficher un aperçu de ses données. Vous pouvez également utiliser le point de terminaison d’analytique SQL du lakehouse pour interroger les données avec des instructions SQL. Sélectionnez point de terminaison d’analytique SQL dans le menu déroulant Lakehouse en haut à droite de l’écran.
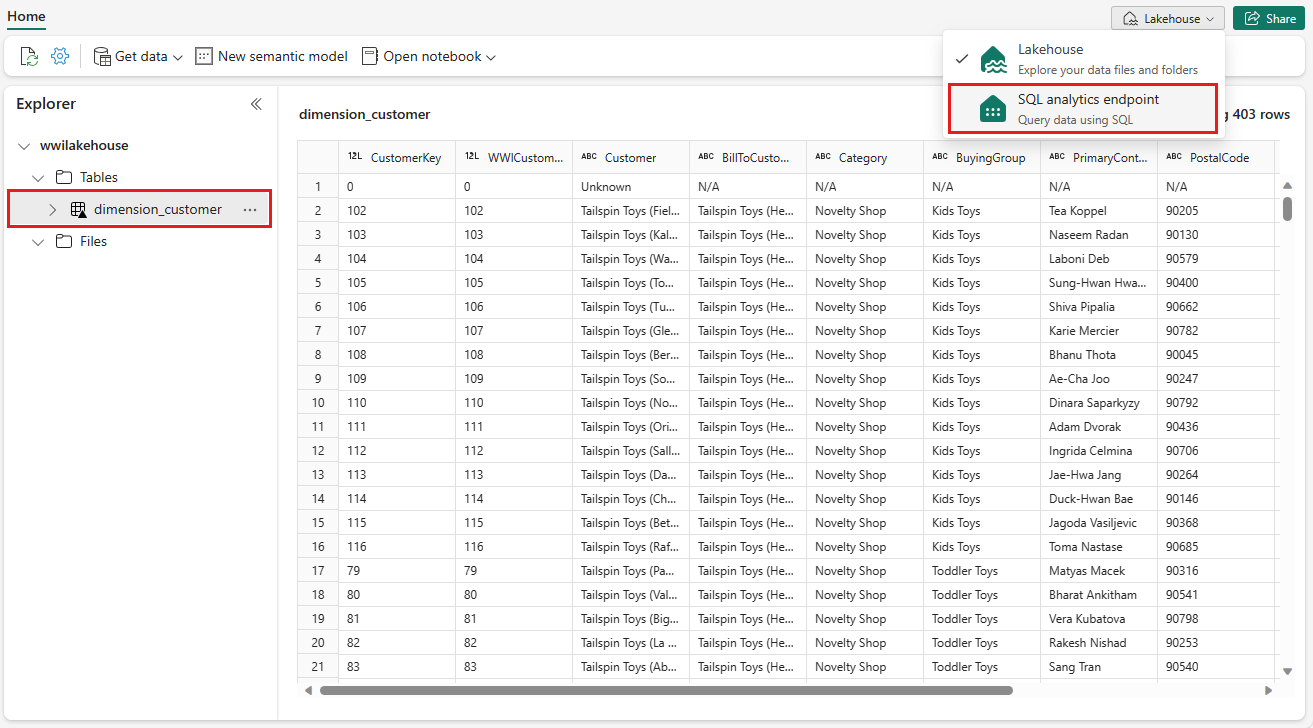
Sélectionnez la table dimension_customer pour afficher un aperçu de ses données ou sélectionnez Nouvelle requête SQL pour écrire vos instructions SQL.
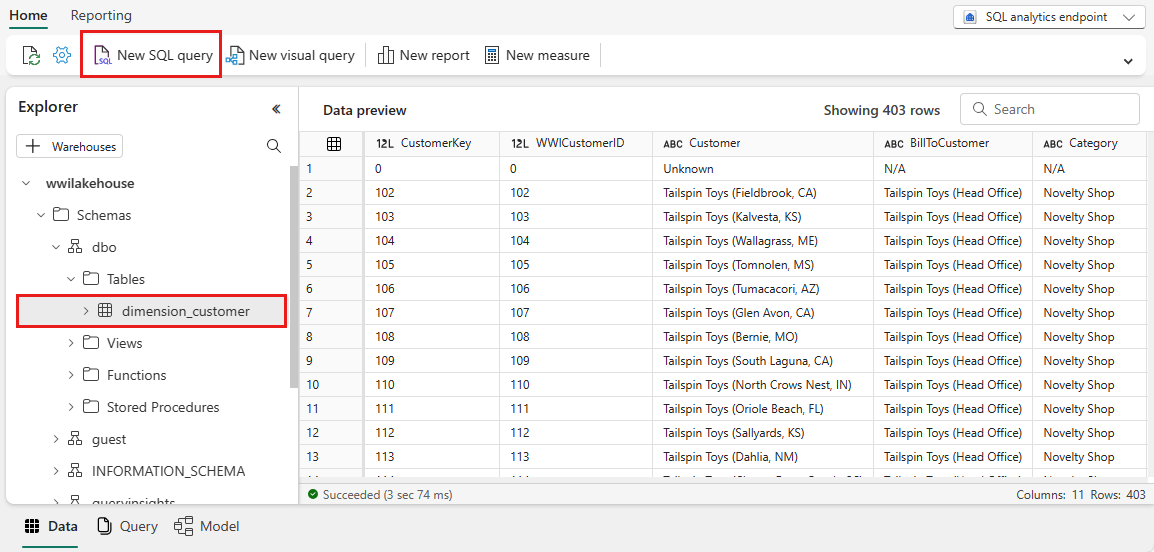
L’exemple de requête suivant agrège le nombre de lignes en fonction de la colonne BuyingGroup de la table dimension_customer. Les fichiers de requête SQL sont enregistrés automatiquement pour référence ultérieure, et vous pouvez renommer ou supprimer ces fichiers en fonction de vos besoins.
Pour exécuter le script, sélectionnez l’icône Exécuter en haut du fichier de script.
SELECT BuyingGroup, Count(*) AS Total FROM dimension_customer GROUP BY BuyingGroup



Créer un rapport
Dans cette section, vous allez générer un rapport à partir des données ingérées.
Auparavant, toutes les tables et vues de Lakehouse étaient automatiquement ajoutées au modèle sémantique. Avec les récentes mises à jour, pour les nouvelles maisons de lac, vous devez ajouter manuellement vos tables au modèle sémantique. Ouvrez votre lakehouse et basculez vers la vue du Point de terminaison d’analytique SQL. Dans l'onglet Reporting, sélectionnez Gérer le modèle sémantique par défaut et sélectionnez les tables que vous souhaitez ajouter au modèle sémantique. Dans ce cas, sélectionnez la table dimension_customer.
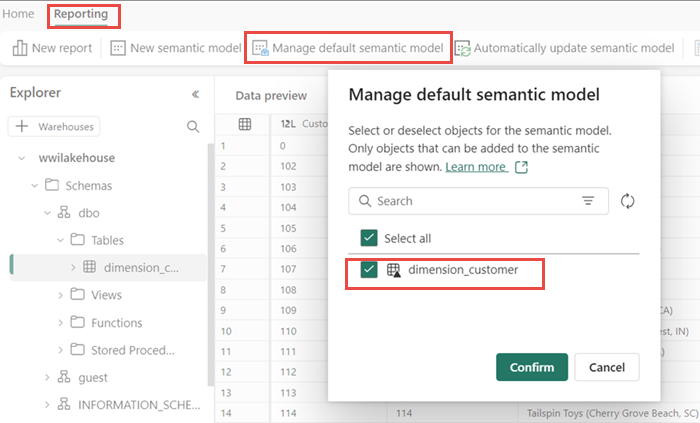
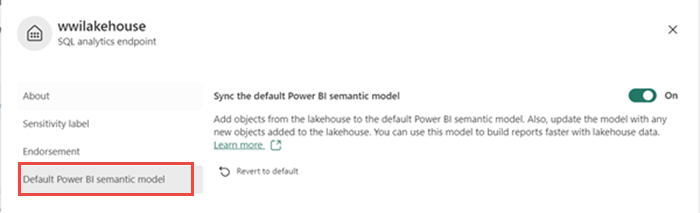
Pour vous assurer que les tables du modèle sémantique sont toujours synchronisées, passez à la vue du point de terminaison Analytique SQL et ouvrez le volet paramètres de l'entrepôt de données. Sélectionnez Modèle sémantique Power BI par défaut et activez Synchroniser le modèle sémantique Power BI par défaut. Pour plus d’informations, consultez Modèles sémantiques Power BI par défaut.
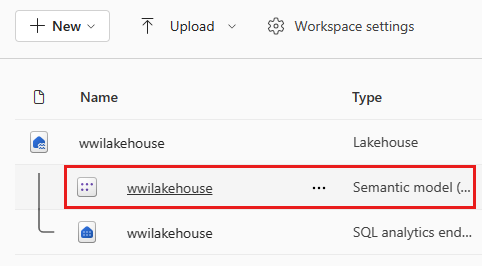
Une fois la table ajoutée, Fabric crée un modèle sémantique portant le même nom que le lakehouse.
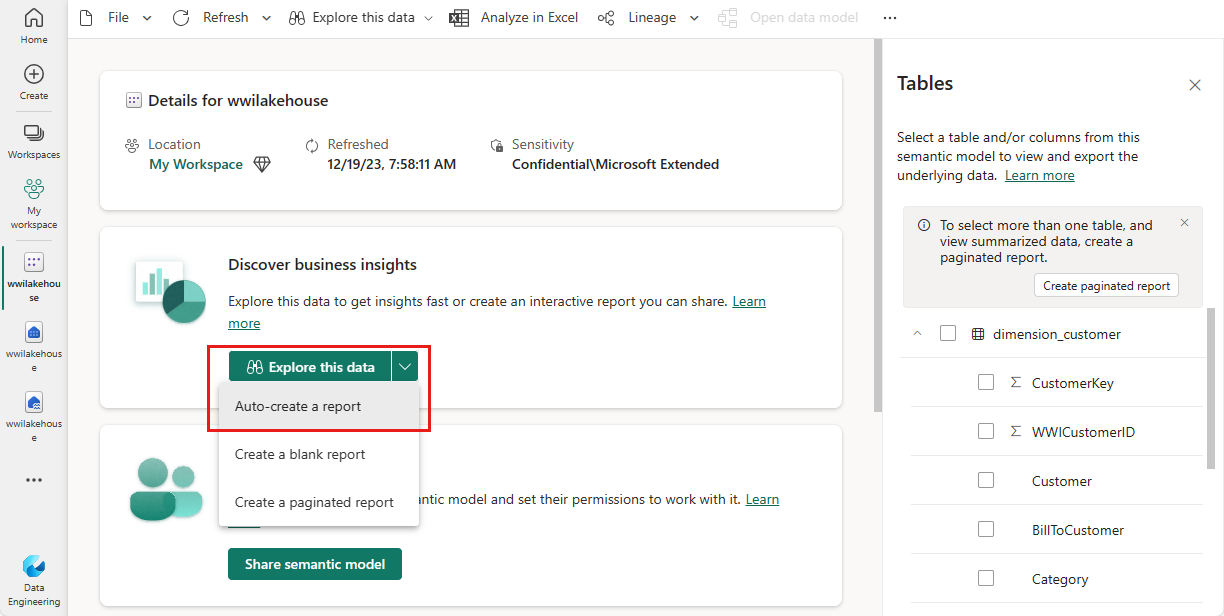
Dans le volet de modèle sémantique, vous pouvez afficher toutes les tables. Vous disposez d’options pour créer des rapports à partir de zéro, des rapports paginés ou laisser Power BI créer automatiquement un rapport en fonction de vos données. Dans le cadre de ce tutoriel, sous Explorer ces données, sélectionnez Créer automatiquement un rapport. Dans le tutoriel suivant, nous créons un rapport à partir de zéro.
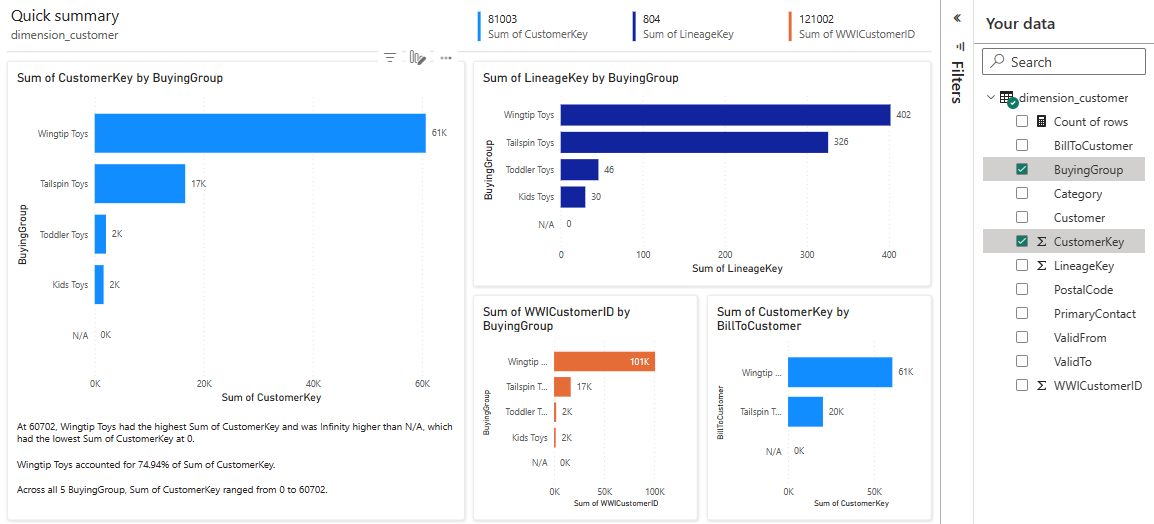
Étant donné que la table est une dimension et qu’il n’y a aucune mesure, Power BI crée une mesure pour le nombre de lignes et l’agrège sur différentes colonnes, et crée différents graphiques, comme illustré dans l’image suivante. Vous pouvez enregistrer ce rapport pour l’avenir en sélectionnant Enregistrer dans le ruban supérieur. Vous pouvez apporter d’autres modifications à ce rapport pour répondre à vos besoins en incluant ou en excluant d’autres tables ou colonnes.