Qu’est-ce que l’architecture de médaillon dans un lakehouse ?
L’architecture de médaillon décrit une série de couches de données qui indiquent la qualité des données stockées dans le lakehouse. Azure Databricks recommande d’adopter une approche multicouche pour créer une source unique de vérité pour les produits de données d’entreprise.
Cette architecture garantit l’atomicité, la cohérence, l’isolation et la durabilité lorsque les données passent par plusieurs couches de validations et de transformations avant d’être stockées dans une disposition optimisée pour une analytique efficace. Les termes bronze (brut), argent (validé) et or (enrichi) décrivent la qualité des données dans chacune de ces couches.
Architecture Medallion en tant que modèle de conception de données
Une architecture de médaillon est un modèle de conception de données utilisé pour organiser les données logiquement. Son objectif est d’améliorer progressivement la structure et la qualité des données au fur et à mesure qu’elle traverse chaque couche de l’architecture (de Bronze ⇒ Silver ⇒ tables de couche Gold). Les architectures Medallion sont parfois appelées architectures multi-tronçons.
En progressant les données par le biais de ces couches, les organisations peuvent améliorer de manière incrémentielle la qualité et la fiabilité des données, ce qui le rend plus adapté aux applications business intelligence et Machine Learning.
La suite de l’architecture de médaillon est une bonne pratique recommandée, mais pas une exigence.
| Question | Bronze | Argent | Or |
|---|---|---|---|
| Que se passe-t-il dans cette couche ? | Ingestion des données brutes | Nettoyage et validation des données | Modélisation et agrégation dimensionnelles |
| Qui est l’utilisateur prévu ? | - Ingénieurs données - Opérations de données - Équipes de conformité et d’audit |
- Ingénieurs données - Analystes de données (utilisez la couche Silver pour un jeu de données plus affiné qui conserve toujours des informations détaillées nécessaires pour l’analyse approfondie) - Scientifiques des données (créer des modèles et effectuer des analyses avancées) |
- Analystes métier et développeurs décisionnels - Scientifiques des données et ingénieurs Machine Learning (ML) - Cadres et décideurs - Équipes opérationnelles |
Exemple d’architecture de médaillon
Cet exemple d’architecture de médaillon montre des couches de bronze, d’argent et d’or à utiliser par une équipe d’opérations commerciales. Chaque couche est stockée dans un schéma différent du catalogue ops.
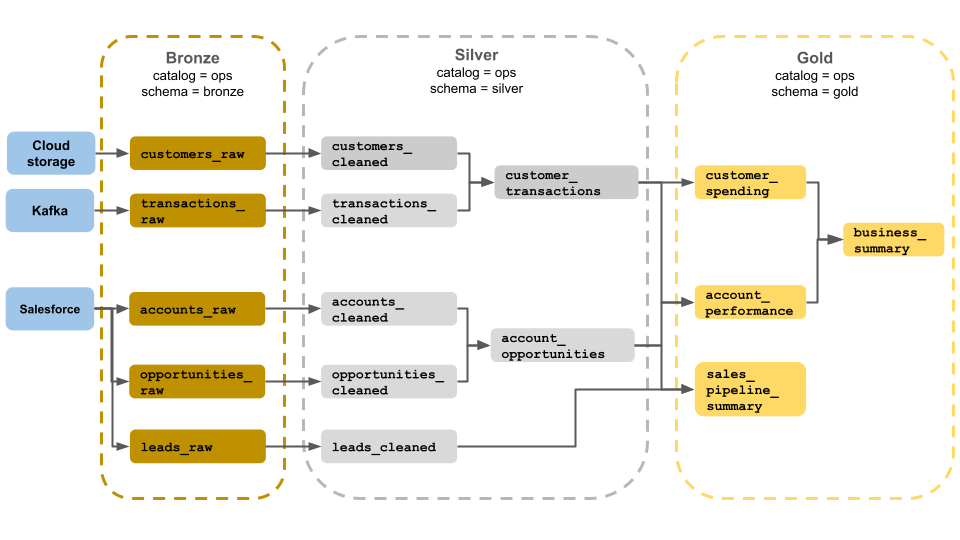
- Couche bronze (
ops.bronze) : ingère des données brutes à partir du stockage cloud, kafka et Salesforce. Aucun nettoyage ou validation des données n’est effectué ici. - Couche Argent (
ops.silver) : le nettoyage et la validation des données sont effectués dans cette couche.- Les données relatives aux clients et aux transactions sont nettoyées en supprimant les valeurs Null et en mettant en quarantaine les enregistrements non valides. Ces jeux de données sont joints à un nouveau jeu de données appelé
customer_transactions. Les scientifiques des données peuvent utiliser ce jeu de données pour l’analytique prédictive. - De même, les comptes et les jeux de données d’opportunité de Salesforce sont joints pour créer
account_opportunities, ce qui est amélioré avec les informations de compte. - Les
leads_rawdonnées sont nettoyées dans un jeu de données appeléleads_cleaned.
- Les données relatives aux clients et aux transactions sont nettoyées en supprimant les valeurs Null et en mettant en quarantaine les enregistrements non valides. Ces jeux de données sont joints à un nouveau jeu de données appelé
- Couche d’or (
ops.gold) : cette couche est conçue pour les utilisateurs professionnels. Il contient moins de jeux de données que l’argent et l’or.customer_spending: Dépense moyenne et totale pour chaque client.account_performance: performances quotidiennes pour chaque compte.sales_pipeline_summary: informations sur le pipeline de vente de bout en bout.business_summary: informations hautement agrégées pour le personnel exécutif.
Ingérer des données brutes dans la couche bronze
La couche bronze contient des données brutes et non valides. Les données ingérées dans la couche bronze présentent généralement les caractéristiques suivantes :
- Contient et conserve l’état brut de la source de données dans ses formats d’origine.
- Est ajouté de façon incrémentielle et augmente au fil du temps.
- Est destiné à la consommation par les charges de travail qui enrichissent les données pour les tables silver, et non pour l’accès par les analystes et les scientifiques des données.
- Sert de source unique de vérité, préservant la fidélité des données.
- Active le retraitement et l’audit en conservant toutes les données historiques.
- Il peut s’agir de n’importe quelle combinaison de transactions de streaming et de traitement par lots à partir de sources, notamment le stockage d’objets cloud (par exemple, S3, GCS, ADLS), les bus de messages (par exemple, Kafka, Brokers, etc.) et les systèmes fédérés (par exemple, Lakehouse Federation).
Limiter le nettoyage ou la validation des données
Une validation minimale des données est effectuée dans la couche bronze. Pour vous assurer que les données supprimées sont supprimées, Azure Databricks recommande de stocker la plupart des champs sous forme de chaîne, VARIANT ou binaire pour vous protéger contre les modifications inattendues du schéma. Les colonnes de métadonnées peuvent être ajoutées, telles que la provenance ou la source des données (par exemple). _metadata.file_name
Valider et dédupliquer les données dans la couche argent
Le nettoyage et la validation des données sont effectués en couche argent.
Créer des tables argent à partir de la couche bronze
Pour créer la couche argent, lisez les données d’une ou plusieurs tables bronze ou argent, puis écrivez des données dans des tables argent.
Azure Databricks ne recommande pas d’écrire dans des tables argent directement à partir de l’ingestion. Si vous écrivez directement à partir de l’ingestion, vous allez introduire des échecs en raison de modifications de schéma ou d’enregistrements endommagés dans les sources de données. En supposant que toutes les sources sont ajoutées uniquement, configurez la plupart des lectures de bronze en tant que lectures en streaming. Les lectures par lots doivent être réservées pour les petits jeux de données (par exemple, des tables de petite dimension).
La couche argent représente les versions validées, nettoyées et enrichies des données. Couche argent :
- Doit toujours inclure au moins une représentation validée et non agrégée de chaque enregistrement. Si les représentations agrégées pilotent de nombreuses charges de travail en aval, ces représentations peuvent se trouver dans la couche argent, mais généralement elles se trouvent dans la couche or.
- Est l’endroit où vous effectuez le nettoyage, la déduplication et la normalisation des données.
- Améliore la qualité des données en corrigeant les erreurs et les incohérences.
- Structure les données dans un format plus consommable pour le traitement en aval.
Appliquer la qualité des données
Les opérations suivantes sont effectuées dans des tables argent :
- Application du schéma
- Gestion des valeurs null et manquantes
- Déduplication des données
- Résolution des problèmes de données obsolètes et d’arrivée tardive
- Vérifications et application de la qualité des données
- Évolution des schémas
- Cast de type
- Joins
Démarrer la modélisation des données
Il est courant de commencer à modéliser des données dans la couche Argent, notamment en choisissant comment représenter des données fortement imbriquées ou semi-structurées :
- Utilisez le
VARIANTtype de données. - Utilisez
JSONdes chaînes. - Créez des structs, des mappages et des tableaux.
- Aplatir le schéma ou normaliser les données dans plusieurs tables.
Stimuler l’analyse avec la couche or
La couche or représente des vues hautement affinées des données qui pilotent l’analytique en aval, les tableaux de bord, ML et les applications. Les données de couche Or sont souvent fortement agrégées et filtrées pour des périodes spécifiques ou des régions géographiques. Il contient des jeux de données sémantiquement significatifs qui correspondent aux fonctions métier et aux besoins.
Couche d’or :
- Se compose de données agrégées adaptées à l’analytique et aux rapports.
- S’aligne sur la logique métier et les exigences.
- Est optimisé pour les performances dans les requêtes et les tableaux de bord.
Aligner avec la logique métier et les exigences
La couche or est l’endroit où vous allez modéliser vos données pour la création de rapports et l’analytique à l’aide d’un modèle dimensionnel en établissant des relations et en définissant des mesures. Les analystes disposant d’un accès aux données en or doivent être en mesure de trouver des données spécifiques au domaine et de répondre aux questions.
Étant donné que la couche or modélise un domaine d’entreprise, certains clients créent plusieurs couches d’or pour répondre à différents besoins métier, tels que les ressources humaines, les finances et l’informatique.
Créer des agrégats adaptés à l’analytique et aux rapports
Les organisations doivent souvent créer des fonctions d’agrégation pour des mesures telles que les moyennes, les nombres, les maximums et les minimums. Par exemple, si votre entreprise doit répondre à des questions sur le total des ventes hebdomadaires, vous pouvez créer une vue matérialisée appelée weekly_sales qui préaggrege ces données afin que les analystes et d’autres n’aient pas besoin de recréer des vues matérialisées fréquemment utilisées.
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
Optimiser les performances dans les requêtes et les tableaux de bord
L’optimisation des tables de couche or pour les performances est une bonne pratique, car ces jeux de données sont fréquemment interrogés. De grandes quantités de données historiques sont généralement accessibles dans la couche sliver et ne sont pas matérialisées dans la couche or.
Contrôler les coûts en ajustant la fréquence d’ingestion des données
Contrôler les coûts en déterminant la fréquence à laquelle ingérer des données.
| Fréquence d’ingestion des données | Cost | Latence | Exemples déclaratifs | Exemples procéduraux |
|---|---|---|---|---|
| Ingestion incrémentielle continue | Élevée | Faible | - Diffusion en continu de table à l’aide spark.readStream de l’ingestion à partir du stockage cloud ou du bus de messages.- Le pipeline Delta Live Tables qui met à jour cette table de diffusion en continu s’exécute en continu. - Code de streaming structuré à l’aide spark.readStream d’un notebook pour ingérer à partir du stockage cloud ou du bus de messages dans une table Delta.- Le notebook est orchestré à l’aide d’un travail Azure Databricks avec un déclencheur de travail continu. |
|
| Ingestion incrémentielle déclenchée | Faible | Élevée | - Diffusion en continu de la table ingérée à partir du stockage cloud ou du bus de messages à l’aide spark.readStreamde .- Le pipeline qui met à jour cette table de diffusion en continu est déclenché par le déclencheur planifié du travail ou un déclencheur d’arrivée de fichier. - Code structured Streaming dans un notebook avec un Trigger.Available déclencheur.- Ce notebook est déclenché par le déclencheur planifié du travail ou un déclencheur d’arrivée de fichier. |
|
| Ingestion par lots avec ingestion incrémentielle manuelle | Faible | Le plus élevé, en raison d’exécutions peu fréquentes. | - Diffusion en continu de la table ingérée à partir du stockage cloud à l’aide spark.readde .- N’utilise pas Structured Streaming. Utilisez plutôt des primitives comme le remplacement de partition pour mettre à jour une partition entière à la fois. - Nécessite une architecture en amont étendue pour configurer le traitement incrémentiel, ce qui permet un coût similaire aux lectures/écritures Structured Streaming. - Nécessite également le partitionnement des données sources par un datetime champ, puis le traitement de tous les enregistrements de cette partition dans la cible. |