Notes de publication archivées
Résumé
Azure HDInsight est l’un des services les plus populaires parmi les clients d’entreprise pour l’analytique open source sur Azure. Abonnez-vous aux notes de publication de HDInsight pour obtenir des informations à jour concernant HDInsight et toutes ses versions.
Pour vous abonner, cliquez sur le bouton « watch » dans la bannière et surveillez les versions de HDInsight.
Informations de version
Date de publication : 22 octobre 2024
Remarque
Ceci est un correctif logiciel / une version de maintenance pour le fournisseur de ressources. Pour plus d’informations, consultez Fournisseur de ressources.
Azure HDInsight publie régulièrement des mises à jour de maintenance pour fournir des correctifs de bogues, des améliorations du niveau de performance et des correctifs de sécurité. Veillez à effectuer ces mises à jour pour garantir des performances et une fiabilité optimales.
Cette note de publication s’applique à
![]() HDInsight version 5.1.
HDInsight version 5.1.
![]() HDInsight version 5.0.
HDInsight version 5.0.
![]() HDInsight version 4.0.
HDInsight version 4.0.
La version HDInsight va être disponible dans toutes les régions sur plusieurs jours. Cette note de publication s’applique au numéro d’image 2409240625. Comment vérifier le numéro d’image ?
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 5.1 : noyau Linux Ubuntu 18.04.5 LTS 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Remarque
Ubuntu 18.04 est pris en charge dans le cadre de la maintenance ESM (maintenance de sécurité étendue) par l’équipe Azure Linux pour Azure HDInsight juillet 2023, et ses versions ultérieures.
Pour connaître les versions spécifiques à la charge de travail, consultez les versions des composants HDInsight 5.x.
Mis à jour
Prise en charge de l’authentification basée sur MSI disponible pour le stockage d’objets blob Azure.
- Azure HDInsight prend désormais en charge l’authentification basée sur OAuth pour accéder au stockage Blob Azure en s’appuyant sur Azure Active Directory (AAD) et les identités managées (MSI). Avec cette amélioration, HDInsight utilise des identités managées attribuées à l’utilisateur pour accéder au stockage Blob Azure. Pour plus d’informations, consultez Identités managées pour les ressources Azure.
Le service HDInsight est passé à l’utilisation d’équilibreurs de charge standard pour toutes ses configurations de cluster en raison de l’annonce de dépréciation de l’équilibreur de charge de base Azure.
Remarque
Cette modification est disponible dans toutes les régions. Recréez votre cluster pour utiliser cette modification. Pour obtenir de l'aide, contactez le support.
Important
Si vous utilisez votre propre réseau virtuel (réseau virtuel personnalisé) lors de la création du cluster, notez que la création du cluster n’aboutira pas une fois cette modification activée. Nous vous recommandons de faire référence au guide de migration pour recréer le cluster. Pour obtenir de l'aide, contactez le support.
 À venir
À venir
Mise hors service des machines virtuelles de la série A Essentiel et Standard.
- Le 31 août 2024, nous procéderons à la mise hors service des machines virtuelles des plans De base et Standard de la série A. Avant cette date, vous devez avoir migré vos charges de travail vers des machines virtuelles de la série Av2, qui offrent une plus grande capacité de mémoire par processeur virtuel et un stockage plus rapide sur disque SSD.
- Pour éviter les interruptions de service, migrez vos charges de travail des machines virtuelles de la série A De base et Standard vers des machines virtuelles de la série Av2 avant le 31 août 2024.
Notifications de mise hors service pour HDInsight 4.0 et HDInsight 5.0.
Si vous avez d’autres questions, contactez le support Azure.
Vous pouvez toujours nous poser des questions concernant HDInsight sur Azure HDInsight – Microsoft Q&A.
Nous sommes à l’écoute : nous vous invitons à ajouter d’autres idées et d’autres sujets ici et à voter en leur faveur (Idées HDInsight). Pour rester au fait des dernières nouveautés, inscrivez-vous à la communauté AzureHDInsight.
Remarque
Nous conseillons aux clients d’utiliser les dernières versions des Images HDInsight, car elles proposent le meilleur des mises à jour open source, des mises à jour Azure et des correctifs de sécurité. Pour plus d’informations, consultez Meilleures pratiques.
Date de publication : 30 août 2024
Remarque
Ceci est un correctif logiciel / une version de maintenance pour le fournisseur de ressources. Pour plus d’informations, consultez Fournisseur de ressources.
Azure HDInsight publie régulièrement des mises à jour de maintenance pour fournir des correctifs de bogues, des améliorations du niveau de performance et des correctifs de sécurité. Veillez à effectuer ces mises à jour pour garantir des performances et une fiabilité optimales.
Cette note de publication s’applique à
![]() HDInsight version 5.1.
HDInsight version 5.1.
![]() HDInsight version 5.0.
HDInsight version 5.0.
![]() HDInsight version 4.0.
HDInsight version 4.0.
La version HDInsight va être disponible dans toutes les régions sur plusieurs jours. Cette note de publication s’applique au numéro d’image 2407260448. Comment vérifier le numéro d’image ?
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 5.1 : noyau Linux Ubuntu 18.04.5 LTS 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Remarque
Ubuntu 18.04 est pris en charge dans le cadre de la maintenance ESM (maintenance de sécurité étendue) par l’équipe Azure Linux pour Azure HDInsight juillet 2023, et ses versions ultérieures.
Pour connaître les versions spécifiques à la charge de travail, consultez les versions des composants HDInsight 5.x.
Problème corrigé
- Correction d’un bogue affectant la base de données par défaut.
Bientôt disponible
-
Mise hors service des machines virtuelles de la série A Essentiel et Standard.
- Le 31 août 2024, nous procéderons à la mise hors service des machines virtuelles des plans De base et Standard de la série A. Avant cette date, vous devez avoir migré vos charges de travail vers des machines virtuelles de la série Av2, qui offrent une plus grande capacité de mémoire par processeur virtuel et un stockage plus rapide sur disque SSD.
- Pour éviter les interruptions de service, migrez vos charges de travail des machines virtuelles de la série A De base et Standard vers des machines virtuelles de la série Av2 avant le 31 août 2024.
- Notifications de mise hors service pour HDInsight 4.0 et HDInsight 5.0.
Si vous avez d’autres questions, contactez le support Azure.
Vous pouvez toujours nous poser des questions concernant HDInsight sur Azure HDInsight – Microsoft Q&A.
Nous sommes à l’écoute : nous vous invitons à ajouter d’autres idées et d’autres sujets ici et à voter en leur faveur (Idées HDInsight). Pour rester au fait des dernières nouveautés, inscrivez-vous à la communauté AzureHDInsight.
Remarque
Nous conseillons aux clients d’utiliser les dernières versions des Images HDInsight, car elles proposent le meilleur des mises à jour open source, des mises à jour Azure et des correctifs de sécurité. Pour plus d'informations, consultez Meilleures pratiques.
Date de publication : 09 août 2024
Cette note de publication s’applique à
![]() HDInsight version 5.1.
HDInsight version 5.1.
![]() HDInsight version 5.0.
HDInsight version 5.0.
![]() HDInsight version 4.0.
HDInsight version 4.0.
La version HDInsight va être disponible dans toutes les régions sur plusieurs jours. Cette note de publication s’applique au numéro d’image 2407260448. Comment vérifier le numéro d’image ?
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 5.1 : noyau Linux Ubuntu 18.04.5 LTS 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Remarque
Ubuntu 18.04 est pris en charge dans le cadre de la maintenance ESM (maintenance de sécurité étendue) par l’équipe Azure Linux pour Azure HDInsight juillet 2023, et ses versions ultérieures.
Pour connaître les versions spécifiques à la charge de travail, consultez les versions des composants HDInsight 5.x.
Mises à jour
Ajout de l’agent Azure Monitor pour Log Analytics dans HDInsight
Ajout de SystemMSI et d’une règle de collecte de données (DCR) automatisée pour Log Analytics, compte tenu de la dépréciation de la nouvelle expérience Azure Monitor (préversion).
Remarque
Numéro d’image efficace 2407260448, les clients utilisant le portail pour l’analytique des journaux d’activité ont l’expérience Agent Azure Monitor par défaut. Au cas où vous souhaitez basculer vers l’expérience Azure Monitor (préversion), vous pouvez épingler vos clusters à d’anciennes images en créant une demande de support.
Date de publication : 5 juillet 2024
Remarque
Ceci est un correctif logiciel / une version de maintenance pour le fournisseur de ressources. Pour plus d’informations, consultez Fournisseur de ressources.
Problèmes résolus
Les balises HOBO remplacent les balises utilisateur.
- Les balises HOBO remplacent les balises utilisateur sur les sous-ressources dans le cadre de la création d’un cluster HDInsight.
Date de publication : 19 juin 2024
Cette note de publication s’applique à
![]() HDInsight version 5.1.
HDInsight version 5.1.
![]() HDInsight version 5.0.
HDInsight version 5.0.
![]() HDInsight version 4.0.
HDInsight version 4.0.
La version HDInsight va être disponible dans toutes les régions sur plusieurs jours. Cette note de publication s’applique au numéro d’image 2406180258. Comment vérifier le numéro d’image ?
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 5.1 : noyau Linux Ubuntu 18.04.5 LTS 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Remarque
Ubuntu 18.04 est pris en charge dans le cadre de la maintenance ESM (maintenance de sécurité étendue) par l’équipe Azure Linux pour Azure HDInsight juillet 2023, et ses versions ultérieures.
Pour connaître les versions spécifiques à la charge de travail, consultez les versions des composants HDInsight 5.x.
Problèmes résolus
Améliorations de la sécurité
Améliorations apportées à HDInsight Log Analytics avec la prise en charge de l’identité managée système pour le fournisseur de ressources HDInsight.
Ajout de nouvelles activités pour mettre à niveau la version de l’agent
mdsdpour l’ancienne image (créée avant 2024).Activation de MISE dans la passerelle dans le cadre des améliorations continues apportées à la migration MSAL.
Incorporation de
Httpheader hiveConfdu serveur Spark Thrift à Jetty HTTP ConnectionFactory.Rétablissement de RANGER-3753 et RANGER-3593.
L’implémentation
setOwnerUserdonnée dans Ranger 2.3.0 a un problème de régression critique lorsqu’elle est utilisée par Hive. Dans Ranger 2.3.0, lorsque HiveServer2 tente d’évaluer les stratégies, Ranger Client tente d’obtenir le propriétaire de la table Hive en appelant le metastore dans la fonction setOwnerUser qui effectue essentiellement l’appel au stockage pour vérifier l’accès à cette table. Ce problème entraîne l’exécution lente des requêtes lorsque Hive s’exécute sur Ranger 2.3.0.
Nouvelles régions ajoutées
- Italie Nord
- Israël Central
- Espagne Centre
- Mexique Centre
- JIO Inde Centre
Ajout aux notes d’archive de juin 2024
Bientôt disponible
-
Mise hors service des machines virtuelles de la série A Essentiel et Standard.
- Le 31 août 2024, nous procéderons à la mise hors service des machines virtuelles des plans De base et Standard de la série A. Avant cette date, vous devez avoir migré vos charges de travail vers des machines virtuelles de la série Av2, qui offrent une plus grande capacité de mémoire par processeur virtuel et un stockage plus rapide sur disque SSD.
- Pour éviter les interruptions de service, migrez vos charges de travail des machines virtuelles de la série A De base et Standard vers des machines virtuelles de la série Av2 avant le 31 août 2024.
- Notifications de mise hors service pour HDInsight 4.0 et HDInsight 5.0.
Si vous avez d’autres questions, contactez le support Azure.
Vous pouvez toujours nous poser des questions concernant HDInsight sur Azure HDInsight – Microsoft Q&A.
Nous sommes à l’écoute : nous vous invitons à ajouter d’autres idées et d’autres sujets ici et à voter en leur faveur (Idées HDInsight). Pour rester au fait des dernières nouveautés, inscrivez-vous à la communauté AzureHDInsight.
Remarque
Nous conseillons aux clients d’utiliser les dernières versions des Images HDInsight, car elles proposent le meilleur des mises à jour open source, des mises à jour Azure et des correctifs de sécurité. Pour plus d'informations, consultez Meilleures pratiques.
Date de publication : 16 mai 2024
Cette note de publication s’applique à
![]() HDInsight version 5.0.
HDInsight version 5.0.
![]() HDInsight version 4.0.
HDInsight version 4.0.
La version HDInsight va être disponible dans toutes les régions sur plusieurs jours. Cette note de publication s’applique au numéro d’image 2405081840. Comment vérifier le numéro d’image ?
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Remarque
Ubuntu 18.04 est pris en charge dans le cadre de la maintenance ESM (maintenance de sécurité étendue) par l’équipe Azure Linux pour Azure HDInsight juillet 2023, et ses versions ultérieures.
Pour connaître les versions spécifiques à la charge de travail, consultez les versions des composants HDInsight 5.x.
Problèmes résolus
- Ajout de l’API dans la passerelle pour obtenir un jeton pour Keyvault, dans le cadre de l’initiative SFI.
- Dans la nouvelle table moniteur
HDInsightSparkLogsde journal, pour le type de journalSparkDriverLog, certains des champs étaient manquants. Par exemple :LogLevel & Message. Cette version ajoute les champs manquants aux schémas et à la mise en forme fixe pourSparkDriverLog. - Les journaux Livy ne sont pas disponibles dans la table de surveillance Log Analytics
SparkDriverLog, ce qui était dû à un problème lié au chemin d’accès source du journal Livy et à l’analyse des journaux d’activité dans les configurationsSparkLivyLog. - N’importe quel cluster HDInsight, à l’aide de ADLS Gen2 en tant que compte de stockage principal, peut tirer parti de l’accès MSI à l’une des ressources Azure (par exemple, SQL, Coffres de clés) utilisées dans le code de l’application.
À venir
-
Mise hors service des machines virtuelles de la série A Essentiel et Standard.
- Le 31 août 2024, nous procéderons à la mise hors service des machines virtuelles des plans De base et Standard de la série A. Avant cette date, vous devez avoir migré vos charges de travail vers des machines virtuelles de la série Av2, qui offrent une plus grande capacité de mémoire par processeur virtuel et un stockage plus rapide sur disque SSD.
- Pour éviter les interruptions de service, migrez vos charges de travail des machines virtuelles de la série A De base et Standard vers des machines virtuelles de la série Av2 avant le 31 août 2024.
- Notifications de mise hors service pour HDInsight 4.0 et HDInsight 5.0.
Si vous avez d’autres questions, contactez le support Azure.
Vous pouvez toujours nous poser des questions concernant HDInsight sur Azure HDInsight – Microsoft Q&A.
Nous sommes à l’écoute : nous vous invitons à ajouter d’autres idées et d’autres sujets ici et à voter en leur faveur (Idées HDInsight). Pour rester au fait des dernières nouveautés, inscrivez-vous à la communauté AzureHDInsight.
Remarque
Nous conseillons aux clients d’utiliser les dernières versions des Images HDInsight, car elles proposent le meilleur des mises à jour open source, des mises à jour Azure et des correctifs de sécurité. Pour plus d'informations, consultez Meilleures pratiques.
Date de publication : 15 avril 2024
Cette note de publication s’applique à ![]() HDInsight version 5.1.
HDInsight version 5.1.
La version HDInsight va être disponible dans toutes les régions sur plusieurs jours. Cette note de publication s’applique au numéro d’image 2403290825. Comment vérifier le numéro d’image ?
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 5.1 : noyau Linux Ubuntu 18.04.5 LTS 5.4
Remarque
Ubuntu 18.04 est pris en charge dans le cadre de la maintenance ESM (maintenance de sécurité étendue) par l’équipe Azure Linux pour Azure HDInsight juillet 2023, et ses versions ultérieures.
Pour connaître les versions spécifiques à la charge de travail, consultez les versions des composants HDInsight 5.x.
Problèmes résolus
- Correctifs de bogues pour Ambari DB, Hive Warehouse Controller (HWC), Spark, HDFS
- Correctifs de bogues pour le module Log Analytics pour HDInsightSparkLogs
- Correctifs CVE pour le fournisseur de ressources HDInsight.
Bientôt disponible
-
Mise hors service des machines virtuelles de la série A Essentiel et Standard.
- Le 31 août 2024, nous procéderons à la mise hors service des machines virtuelles des plans De base et Standard de la série A. Avant cette date, vous devez avoir migré vos charges de travail vers des machines virtuelles de la série Av2, qui offrent une plus grande capacité de mémoire par processeur virtuel et un stockage plus rapide sur disque SSD.
- Pour éviter les interruptions de service, migrez vos charges de travail des machines virtuelles de la série A De base et Standard vers des machines virtuelles de la série Av2 avant le 31 août 2024.
- Notifications de mise hors service pour HDInsight 4.0 et HDInsight 5.0.
Si vous avez d’autres questions, contactez le support Azure.
Vous pouvez toujours nous poser des questions concernant HDInsight sur Azure HDInsight – Microsoft Q&A.
Nous sommes à l’écoute : nous vous invitons à ajouter d’autres idées et d’autres sujets ici et à voter en leur faveur (Idées HDInsight). Pour rester au fait des dernières nouveautés, inscrivez-vous à la communauté AzureHDInsight.
Remarque
Nous conseillons aux clients d’utiliser les dernières versions des Images HDInsight, car elles proposent le meilleur des mises à jour open source, des mises à jour Azure et des correctifs de sécurité. Pour plus d'informations, consultez Meilleures pratiques.
Date de publication : 15 février 2024
Cette publication s’applique aux versions 4.x et 5.x de HDInsight. La version HDInsight va être disponible dans toutes les régions sur plusieurs jours. Cette publication s’applique à l’image numéro 2401250802. Comment vérifier le numéro d’image ?
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1 : noyau Linux Ubuntu 18.04.5 LTS 5.4
Remarque
Ubuntu 18.04 est pris en charge dans le cadre de la maintenance ESM (maintenance de sécurité étendue) par l’équipe Azure Linux pour Azure HDInsight juillet 2023, et ses versions ultérieures.
Pour les versions propres à la charge de travail, voir
Nouvelles fonctionnalités
- Prise en charge de Spark SQL par Apache Ranger dans Spark 3.3.0 (HDInsight version 5.1) avec le Pack Sécurité Entreprise. Cliquez ici pour en savoir plus.
Problèmes résolus
- Correctifs de sécurité des composants Ambari et Oozie
À venir
- Mise hors service des machines virtuelles de la série A Essentiel et Standard.
- Le 31 août 2024, nous procéderons à la mise hors service des machines virtuelles des plans De base et Standard de la série A. Avant cette date, vous devez avoir migré vos charges de travail vers des machines virtuelles de la série Av2, qui offrent une plus grande capacité de mémoire par processeur virtuel et un stockage plus rapide sur disque SSD.
- Pour éviter les interruptions de service, migrez vos charges de travail des machines virtuelles de la série A De base et Standard vers des machines virtuelles de la série Av2 avant le 31 août 2024.
Si vous avez d’autres questions, contactez le support Azure.
Vous pouvez toujours nous poser des questions concernant HDInsight sur Azure HDInsight : Microsoft Q&A
Nous sommes à l’écoute : nous vous invitons à y ajouter d’autres t idées et d’autres sujets et à voter en leur faveur : Idées HDInsight. Suivez-nous sur la Communauté AzureHDInsight pour rester au fait des dernières nouveautés
Remarque
Nous conseillons aux clients d’utiliser les dernières versions des Images HDInsight, car elles proposent le meilleur des mises à jour open source, des mises à jour Azure et des correctifs de sécurité. Pour plus d'informations, consultez Meilleures pratiques.
Étapes suivantes
- Azure HDInsight : Forum Aux Questions
- Configurer la planification de la mise à jour corrective du système d’exploitation pour les clusters HDInsight sous Linux
- Note de publication précédente
Azure HDInsight est l’un des services les plus populaires parmi les clients d’entreprise pour l’analytique open source sur Azure. Si vous souhaitez vous abonner aux notes de publication, regardez les communiqués sur ce référentiel GitHub.
Date de publication : 10 janvier 2024
Cette mise en production de correctif logiciel s’applique aux versions 4.x et 5.x de HDInsight. La version HDInsight va être disponible dans toutes les régions sur plusieurs jours. Cette mise en production s’applique à l’image numéro 2401030422. Comment vérifier le numéro d’image ?
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1 : noyau Linux Ubuntu 18.04.5 LTS 5.4
Remarque
Ubuntu 18.04 est pris en charge dans le cadre de la maintenance ESM (maintenance de sécurité étendue) par l’équipe Azure Linux pour Azure HDInsight juillet 2023, et ses versions ultérieures.
Pour les versions propres à la charge de travail, voir
Problèmes résolus
- Correctifs de sécurité des composants Ambari et Oozie
À venir
- Mise hors service des machines virtuelles de la série A Essentiel et Standard.
- Le 31 août 2024, nous procéderons à la mise hors service des machines virtuelles des plans De base et Standard de la série A. Avant cette date, vous devez avoir migré vos charges de travail vers des machines virtuelles de la série Av2, qui offrent une plus grande capacité de mémoire par processeur virtuel et un stockage plus rapide sur disque SSD.
- Pour éviter les interruptions de service, migrez vos charges de travail des machines virtuelles de la série A De base et Standard vers des machines virtuelles de la série Av2 avant le 31 août 2024.
Si vous avez d’autres questions, contactez le support Azure.
Vous pouvez toujours nous poser des questions concernant HDInsight sur Azure HDInsight : Microsoft Q&A
Nous sommes à l’écoute : nous vous invitons à y ajouter d’autres t idées et d’autres sujets et à voter en leur faveur : Idées HDInsight. Suivez-nous sur la Communauté AzureHDInsight pour rester au fait des dernières nouveautés
Remarque
Nous conseillons aux clients d’utiliser les dernières versions des Images HDInsight, car elles proposent le meilleur des mises à jour open source, des mises à jour Azure et des correctifs de sécurité. Pour plus d'informations, consultez Meilleures pratiques.
Date de publication : 26 octobre 2023
Cette note de publication s’applique à HDInsight 4.x ; la version 5.x de HDInsight sera disponible dans toutes les régions dans les prochains jours. Cette mise en production s’applique au numéro d’image 2310140056. Comment vérifier le numéro d’image ?
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1 : noyau Linux Ubuntu 18.04.5 LTS 5.4
Pour les versions propres à la charge de travail, voir
Nouveautés
HDInsight annonce la disponibilité générale de HDInsight 5.1 à partir du 1 novembre 2023. Cette version apporte une actualisation de la pile complète des composants open source et des intégrations de Microsoft.
- Dernières versions open source : HDInsight 5.1 est fourni avec la dernière version open source stable disponible. Les clients peuvent tirer parti de toutes les dernières fonctionnalités open source, des améliorations des performances Microsoft et des correctifs de bogues.
- Sécurisé : les dernières versions sont fournies avec les correctifs de sécurité les plus récents, à la fois les correctifs de sécurité open source et les améliorations de sécurité de Microsoft.
- Réduction du coût TCO : avec des améliorations de performances, les clients peuvent réduire le coût d’exploitation, ainsi que la mise à l’échelle automatique améliorée.
Autorisations de cluster pour un stockage sécurisé
- Les clients peuvent indiquer (lors de la création du cluster) si un canal sécurisé doit être utilisé pour permettre aux nœuds de cluster HDInsight de se connecter au compte de stockage.
Création de clusters HDInsight avec des réseaux virtuels personnalisés.
- Pour améliorer la posture de sécurité globale des clusters HDInsight, les clusters HDInsight utilisant des VNET personnalisés doivent s'assurer que l'utilisateur doit avoir l'autorisation
Microsoft Network/virtualNetworks/subnets/join/actiond'effectuer des opérations de création. Le client peut rencontrer des échecs de création si cette vérification n’est pas activée.
- Pour améliorer la posture de sécurité globale des clusters HDInsight, les clusters HDInsight utilisant des VNET personnalisés doivent s'assurer que l'utilisateur doit avoir l'autorisation
Clusters ABFS non-ESP [Autorisations de cluster pour Word Readable]
- Les clusters ABFS non ESP empêchent les utilisateurs de groupe non Hadoop d’exécuter des commandes Hadoop pour les opérations de stockage. Cette modification améliore la posture de sécurité du cluster.
Mise à jour de quota en ligne.
- Vous pouvez maintenant demander une augmentation du quota directement de la page Mon quota. Avec l’appel direct de l’API, c’est beaucoup plus rapide. En cas d’échec de l’appel de l’API, vous pouvez créer une demande de support pour une augmentation de quota.
À venir
La longueur maximale des noms de clusters passe de 59 à 45 caractères dans le but d’améliorer la posture de sécurité des clusters. Cette modification sera déployée dans toutes les régions à compter de la prochaine version.
Mise hors service des machines virtuelles de la série A De base et Standard.
- Le 31 août 2024, nous procéderons à la mise hors service des machines virtuelles des plans De base et Standard de la série A. Avant cette date, vous devez avoir migré vos charges de travail vers des machines virtuelles de la série Av2, qui offrent une plus grande capacité de mémoire par processeur virtuel et un stockage plus rapide sur disque SSD.
- Pour éviter les interruptions de service, migrez vos charges de travail des machines virtuelles de la série A De base et Standard vers des machines virtuelles de la série Av2 avant le 31 août 2024.
Si vous avez d’autres questions, contactez le support Azure.
Vous pouvez toujours nous poser des questions concernant HDInsight sur Azure HDInsight : Microsoft Q&A
Nous sommes à l’écoute : nous vous invitons à y ajouter d’autres t idées et d’autres sujets et à voter en leur faveur : Idées HDInsight. Suivez-nous sur la Communauté AzureHDInsight pour rester au fait des dernières nouveautés
Remarque
Cette version corrige les CVE suivants publiés par MSRC le 12 septembre 2023. L’action consiste à mettre à jour la dernière image 2308221128 ou 2310140056. Les clients sont invités à planifier en conséquence.
| CVE | Gravité | Titre CVE | Remarque |
|---|---|---|---|
| CVE-2023-38156 | Important | Vulnérabilité d’élévation de privilèges Dans Azure HDInsight Apache Ambari | Inclus dans l’image 2308221128 ou 2310140056 |
| CVE-2023-36419 | Important | Vulnérabilité d’élévation de privilèges du planificateur de workflow dans Azure HDInsight Apache Oozie | Appliquer Action de script sur vos clusters ou effectuer une mise à jour vers l’image 2310140056 |
Remarque
Nous conseillons aux clients d’utiliser les dernières versions des Images HDInsight, car elles proposent le meilleur des mises à jour open source, des mises à jour Azure et des correctifs de sécurité. Pour plus d'informations, consultez Meilleures pratiques.
Date de publication : 7 septembre 2023
Cette note de publication s’applique à HDInsight 4.x ; la version 5.x de HDInsight sera disponible dans toutes les régions dans les prochains jours. Cette mise en production s’applique au numéro d’image 2308221128. Comment vérifier le numéro d’image ?
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1 : noyau Linux Ubuntu 18.04.5 LTS 5.4
Pour les versions propres à la charge de travail, voir
Important
Cette version corrige les CVE suivants publiés par MSRC le 12 septembre 2023. L'action consiste à mettre à jour la dernière image 2308221128. Les clients sont invités à planifier en conséquence.
| CVE | Gravité | Titre CVE | Remarque |
|---|---|---|---|
| CVE-2023-38156 | Important | Vulnérabilité d’élévation de privilèges Dans Azure HDInsight Apache Ambari | Inclus sur l’image 2308221128 |
| CVE-2023-36419 | Important | Vulnérabilité d’élévation de privilèges du planificateur de workflow dans Azure HDInsight Apache Oozie | Appliquer Action de script sur vos clusters |
Bientôt disponible
- La longueur maximale des noms de clusters passe de 59 à 45 caractères dans le but d’améliorer la posture de sécurité des clusters. Cette modification sera implémentée d’ici le 30 septembre 2023.
- Autorisations de cluster pour un stockage sécurisé
- Les clients peuvent indiquer (lors de la création du cluster) si un canal sécurisé doit être utilisé pour permettre aux nœuds de cluster HDInsight de contacter le compte de stockage.
- Mise à jour de quota en ligne.
- Les demandes d’augmentation de quota s’effectuent directement dans la page Mon quota. Il s’agit d’un appel d’API direct, ce qui est plus rapide. En cas d’échec de l’appel d’APdl, les clients doivent alors créer une demande de support pour augmentation de quota.
- Création de clusters HDInsight avec des réseaux virtuels personnalisés.
- Pour améliorer la posture de sécurité globale des clusters HDInsight, les clusters HDInsight utilisant des VNET personnalisés doivent s'assurer que l'utilisateur doit avoir l'autorisation
Microsoft Network/virtualNetworks/subnets/join/actiond'effectuer des opérations de création. Les clients devraient planifier en conséquence car ce changement serait une vérification obligatoire pour éviter les échecs de création de cluster avant le 30 septembre 2023.
- Pour améliorer la posture de sécurité globale des clusters HDInsight, les clusters HDInsight utilisant des VNET personnalisés doivent s'assurer que l'utilisateur doit avoir l'autorisation
- Mise hors service des machines virtuelles de la série A De base et Standard.
- Le 31 août 2024, nous procéderons à la mise hors service des machines virtuelles des plans De base et Standard de la série A. Avant cette date, vous devez avoir migré vos charges de travail vers des machines virtuelles de la série Av2, qui offrent une plus grande capacité de mémoire par processeur virtuel et un stockage plus rapide sur disque SSD. Pour éviter les interruptions de service, migrez vos charges de travail des machines virtuelles de la série A De base et Standard vers des machines virtuelles de la série Av2 avant le 31 août 2024.
- Clusters ABFS non-ESP [Autorisations de cluster pour Word Readable]
- Prévoyez d’introduire une modification dans les clusters ABFS non-ESP qui empêche l’exécution par les utilisateurs de groupe non Hadoop de commandes Hadoop pour les opérations de stockage. Cette modification permet d’améliorer l’état de la sécurité du cluster. Les clients doivent planifier les mises à jour avant le 30 septembre 2023.
Si vous avez d’autres questions, contactez le support Azure.
Vous pouvez toujours nous poser des questions concernant HDInsight sur Azure HDInsight : Microsoft Q&A
Nous vous invitons à y ajouter d’autres propositions et idées et d’autres sujets et à voter en leur faveur – Communauté HDInsight (azure.com).
Remarque
Nous conseillons aux clients d’utiliser les dernières versions des Images HDInsight, car elles proposent le meilleur des mises à jour open source, des mises à jour Azure et des correctifs de sécurité. Pour plus d'informations, consultez Meilleures pratiques.
Date de sortie : 25 juillet 2023
Cette note de publication s’applique à HDInsight 4.x ; la version 5.x de HDInsight sera disponible dans toutes les régions dans les prochains jours. Cette version s'applique à l'image numéro 2307201242. Comment vérifier le numéro d’image ?
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1 : noyau Linux Ubuntu 18.04.5 LTS 5.4
Pour les versions propres à la charge de travail, voir
 Quoi de neuf
Quoi de neuf
- HDInsight 5.1 est désormais pris en charge avec le cluster ESP.
- La version mise à jour de Ranger 2.3.0 et Oozie 5.2.1 fait désormais partie de HDInsight 5.1
- Le cluster Spark 3.3.1 (HDInsight 5.1) est fourni avec Hive Warehouse Connector (HWC) 2.1, qui fonctionne avec le cluster Interactive Query (HDInsight 5.1).
- Ubuntu 18.04 est pris en charge sous ESM (Maintenance de sécurité étendue) par l’équipe Azure Linux pour Azure HDInsight juillet 2023, version ultérieure.
Important
Cette version corrige les CVE suivants publiés par MSRC le 8 août 2023. L'action consiste à mettre à jour la dernière image 2307201242. Les clients sont invités à planifier en conséquence.
| CVE | Gravité | Titre CVE |
|---|---|---|
| CVE-2023-35393 | Important | Vulnérabilité d'usurpation d'Azure Apache Hive |
| CVE-2023-35394 | Important | Vulnérabilité d'usurpation de bloc-notes Azure HDInsight Jupyter |
| CVE-2023-36877 | Important | Vulnérabilité d'usurpation Azure Apache Oozie |
| CVE-2023-36881 | Important | Vulnérabilité d'usurpation Azure Apache Ambari |
| CVE-2023-38188 | Important | Vulnérabilité d'usurpation d'Azure Apache Hadoop |
À venir
- La longueur maximale des noms de clusters passe de 59 à 45 caractères dans le but d’améliorer la posture de sécurité des clusters. Les clients doivent planifier les mises à jour avant le 30 septembre 2023.
- Autorisations de cluster pour un stockage sécurisé
- Les clients peuvent indiquer (lors de la création du cluster) si un canal sécurisé doit être utilisé pour permettre aux nœuds de cluster HDInsight de contacter le compte de stockage.
- Mise à jour de quota en ligne.
- Les demandes d’augmentation de quota s’effectuent directement dans la page Mon quota. Il s’agit d’un appel d’API direct, ce qui est plus rapide. En cas d’échec de l’appel d’API, les clients doivent créer une demande de support pour augmentation de quota.
- Création de clusters HDInsight avec des réseaux virtuels personnalisés.
- Pour améliorer la posture de sécurité globale des clusters HDInsight, les clusters HDInsight utilisant des VNET personnalisés doivent s'assurer que l'utilisateur doit avoir l'autorisation
Microsoft Network/virtualNetworks/subnets/join/actiond'effectuer des opérations de création. Les clients devraient planifier en conséquence car ce changement serait une vérification obligatoire pour éviter les échecs de création de cluster avant le 30 septembre 2023.
- Pour améliorer la posture de sécurité globale des clusters HDInsight, les clusters HDInsight utilisant des VNET personnalisés doivent s'assurer que l'utilisateur doit avoir l'autorisation
- Mise hors service des machines virtuelles de la série A De base et Standard.
- Le 31 août 2024, nous procèderons à la mise hors service des machines virtuelles des plans De base et Standard de la série A. Avant cette date, vous devez avoir migré vos charges de travail vers des machines virtuelles de la série Av2, qui offrent une plus grande capacité de mémoire par processeur virtuel et un stockage plus rapide sur disque SSD. Pour éviter les interruptions de service, migrez vos charges de travail des VM de base et standard de la série A vers les VM de la série Av2 avant le 31 août 2024.
- Clusters ABFS non-ESP [Autorisations de cluster pour Word Readable]
- Prévoyez d’introduire une modification dans les clusters ABFS non-ESP qui empêche l’exécution par les utilisateurs de groupe non Hadoop de commandes Hadoop pour les opérations de stockage. Cette modification permet d’améliorer l’état de la sécurité du cluster. Les clients doivent planifier les mises à jour avant le 30 septembre 2023.
Si vous avez d’autres questions, contactez le support Azure.
Vous pouvez toujours nous poser des questions concernant HDInsight sur Azure HDInsight : Microsoft Q&A
Nous vous invitons à rejoindre la communauté HDInsight (azure.com) pour y ajouter d’autres propositions et idées et d’autres sujets et voter en leur faveur. Pour rester au fait des dernières nouveautés, suivez-nous sur X.
Remarque
Nous conseillons aux clients d’utiliser les dernières versions des Images HDInsight, car elles proposent le meilleur des mises à jour open source, des mises à jour Azure et des correctifs de sécurité. Pour plus d'informations, consultez Meilleures pratiques.
Date de publication : 08 mai 2023
Cette note de publication s’applique à HDInsight 4.x ; la version 5.x de HDInsight est disponible dans toutes les régions dans les prochains jours. Cette mise en production s’applique au numéro d’image 2304280205. Comment vérifier le numéro d’image ?
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Pour les versions propres à la charge de travail, voir
![]()
Azure HDInsight 5.1 mis à jour avec
- Apache HBase 2.4.11
- Apache Phoenix 5.1.2
- Apache Hive 3.1.2
- Apache Spark 3.3.1
- Apache Tez 0.9.1
- Apache Zeppelin 0.10.1
- Apache Livy 0.5
- Apache Kafka 3.2.0
Remarque
- Tous les composants sont intégrés à Hadoop 3.3.4 et ZK 3.6.3
- Tous les composants mis à niveau ci-dessus sont désormais disponibles dans les clusters non ESP pour la préversion publique.
![]()
Mise à l’échelle automatique améliorée pour HDInsight
Azure HDInsight a apporté d’importantes améliorations à la stabilité et la latence concernant la mise à l’échelle automatique. Les modifications essentielles comprennent l’amélioration de la boucle de commentaires pour les décisions de mise à l’échelle, une amélioration significative de la latence pour la mise à l’échelle et la prise en charge de la remise en service de nœuds désactivés. En savoir plus sur les améliorations, la configuration personnalisée et la migration de votre cluster vers une mise à l’échelle automatique améliorée. La fonctionnalité de mise à l’échelle automatique améliorée est disponible depuis 17 mai 2023 dans toutes les régions prises en charge.
Azure HDInsight ESP pour Apache Kafka 2.4.1 est désormais en disponibilité générale.
Azure HDInsight ESP pour Apache Kafka 2.4.1 est en préversion publique depuis avril 2022. Après les améliorations notables au niveau des correctifs CVE et de la stabilité, Azure HDInsight ESP Kafka 2.4.1 passe désormais en disponibilité générale et est prêt pour les charges de travail de production. Découvrez les procédures détaillées deconfiguration et de migration.
Gestion de quota pour HDInsight
HDInsight alloue actuellement un quota aux abonnements des clients à un niveau régional. Les cœurs alloués aux clients sont génériques et ne sont pas classifiés au niveau d’une famille de machines virtuelles (par exemple,
Dv2,Ev3,Eav4, etc.).HDInsight a introduit une vue améliorée, qui fournit des détails et une classification de quotas pour les machines virtuelles au niveau de la famille. Cette fonctionnalité permet aux clients d’examiner les quotas actuels et restants pour une région au niveau de la famille de machines virtuelles. Cette vue améliorée confère aux clients une plus grande visibilité, ce qui facilite la planification de quotas, ainsi qu’une meilleure expérience utilisateur. Cette fonctionnalité est actuellement disponible sur HDInsight 4.x et 5.x pour la région USA Est EUAP. D’autres régions suivront ultérieurement.
Pour plus d’informations, consultez Planification de la capacité de cluster dans Azure HDInsight | Microsoft Learn
![]()
- Pologne Centre
- La longueur maximale des noms de clusters passe de 59 à 45 caractères dans le but d’améliorer la posture de sécurité des clusters.
- Autorisations de cluster pour un stockage sécurisé
- Les clients peuvent indiquer (lors de la création du cluster) si un canal sécurisé doit être utilisé pour permettre aux nœuds de cluster HDInsight de contacter le compte de stockage.
- Mise à jour de quota en ligne.
- Les demandes d’augmentation de quota s’effectuent directement dans la page Mon quota. Il s’agit d’un appel d’API direct, ce qui est plus rapide. En cas d’échec de l’appel d’API, les clients doivent créer une demande de support pour augmentation de quota.
- Création de clusters HDInsight avec des réseaux virtuels personnalisés.
- Pour améliorer la posture de sécurité globale des clusters HDInsight, les clusters HDInsight qui utilisent des réseaux virtuels personnalisés doivent vérifier que l’utilisateur a besoin d’une autorisation pour permettre à
Microsoft Network/virtualNetworks/subnets/join/actiond’effectuer des opérations de création. Les clients doivent prendre des dispositions en conséquence, car il s’agit d’une vérification obligatoire pour éviter les échecs de création de cluster.
- Pour améliorer la posture de sécurité globale des clusters HDInsight, les clusters HDInsight qui utilisent des réseaux virtuels personnalisés doivent vérifier que l’utilisateur a besoin d’une autorisation pour permettre à
- Mise hors service des machines virtuelles de la série A De base et Standard.
- Le 31 août 2024, nous procèderons à la mise hors service des machines virtuelles des plans De base et Standard de la série A. Avant cette date, vous devez avoir migré vos charges de travail vers des machines virtuelles de la série Av2, qui offrent une plus grande capacité de mémoire par processeur virtuel et un stockage plus rapide sur disque SSD. Pour éviter les interruptions de service, migrez vos charges de travail des machines virtuelles de la série A De base et Standard vers des machines virtuelles de la série Av2 avant le 31 août 2024.
- Clusters ABFS non-ESP [Autorisations de cluster pour Lecture dans le Monde]
- Prévoyez d’introduire une modification dans les clusters ABFS non-ESP qui empêche l’exécution par les utilisateurs de groupe non Hadoop de commandes Hadoop pour les opérations de stockage. Cette modification permet d’améliorer l’état de la sécurité du cluster. Les clients ont à prévoir les mises à jour.
Date de publication : 28 février 2023
Cette version s’applique à HDInsight 4.0. et 5.0, 5.1. La version HDInsight est disponible dans toutes les régions sur plusieurs jours. Cette version est valable pour le numéro d’image 2302250400. Comment vérifier le numéro d’image ?
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Pour les versions propres à la charge de travail, voir
Important
Microsoft a émis CVE-2023-23408, lequel est fixe sur la version actuelle et il est conseillé aux clients de mettre à niveau leurs clusters vers l’image la plus récente.
![]()
HDInsight 5.1
Nous avons commencé le déploiement d’une nouvelle version de HDInsight 5.1. Toutes les nouvelles versions open source ajoutées en tant que versions incrémentielles à HDInsight 5.1.
Pour plus d’informations, consultez HDInsight version 5.1.0
![]()
Mise à niveau de Kafka 3.2.0 (préversion)
- Kafka 3.2.0 apporte plusieurs nouvelles fonctionnalités/améliorations significatives.
- Mise à niveau vers la version 3.6.3 de Zookeeper
- Prise en charge de Kafka Streams
- Des garanties de livraison plus fortes activées par défaut pour le producteur Kafka.
-
log4j1.x remplacé parreload4j. - Envoyez un conseil au responsable de partition pour récupérer la partition.
-
JoinGroupRequestetLeaveGroupRequestsont lié à une raison. - Ajout de métriques du nombre de répartiteur8.
- Améliorations de Mirror
Maker2.
Mise à niveau de HBase 2.4.11 (Préversion)
- Cette version apporte de nouvelles fonctionnalités comme l’ajout de nouveaux types de mécanismes de mise en cache pour la mise en cache de blocs, la possibilité de modifier
hbase:meta tableet d’afficher le tableauhbase:metaà partir de l’interface utilisateur WEB HBase.
Mise à niveau de Phoenix 5.1.2 (Préversion)
- Mise à niveau vers la version 5.1.2 de Phoenix dans cette version. Cette mise à niveau comprend le serveur Phoenix Query Server. Le serveur Phoenix Query Server mandate le pilote standard JDBC Phoenix et fournit un protocole filaire rétrocompatible pour appeler ce pilote JDBC.
Ambari CVE
- Plusieurs Ambari CVE ont été corrigés.
Notes
ESP n’est pas pris en charge pour Kafka et HBase dans cette version.
![]()
Étapes suivantes
- Mise à l’échelle automatique
- Mise à l’échelle automatique avec une meilleure latence et plusieurs améliorations
- Limitation des modifications de nom de cluster
- La longueur maximale du nom du cluster passe de 45 à 59 dans Public, Azure Chine et Azure Government.
- Autorisations de cluster pour un stockage sécurisé
- Les clients peuvent indiquer (lors de la création du cluster) si un canal sécurisé doit être utilisé pour permettre aux nœuds de cluster HDInsight de contacter le compte de stockage.
- Clusters ABFS non-ESP [Autorisations de cluster pour Lecture dans le Monde]
- Prévoyez d’introduire une modification dans les clusters ABFS non-ESP qui empêche l’exécution par les utilisateurs de groupe non Hadoop de commandes Hadoop pour les opérations de stockage. Cette modification permet d’améliorer l’état de la sécurité du cluster. Les clients ont à prévoir les mises à jour.
- Des mises à niveau open source
- Apache Spark 3.3.0 et Hadoop 3.3.4 sont en cours de développement sur HDInsight 5.1 et comportent plusieurs nouvelles fonctionnalités, performances et autres améliorations significatives.
Notes
Nous conseillons aux clients d’utiliser les dernières versions des Images HDInsight, car elles proposent le meilleur des mises à jour open source, des mises à jour Azure et des correctifs de sécurité. Pour plus d'informations, consultez Meilleures pratiques.
Date de publication : 12 décembre 2022
Cette version s’applique à HDInsight 4.0. et la version 5.0 HDInsight est mise à disposition dans toutes les régions sur plusieurs jours.
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
Versions du système d’exploitation
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
![]()
- Log Analytics : les clients peuvent activer la surveillance classique pour obtenir la dernière version d’OMS 14.19. Pour supprimer les anciennes versions, désactivez et activez la surveillance classique.
- Déconnexion automatique de l’interface utilisateur de l’utilisateurAmbari en raison d’une inactivité. Vous trouverez plus d’informations ici.
- Spark : une nouvelle version optimisée de Spark 3.1.3 est incluse dans cette version. Nous avons testé Apache Spark 3.1.2 (version précédente) et Apache Spark 3.1.3 (version actuelle) à l’aide du benchmark TPC-DS. Le test a été effectué à l’aide de la référence SKU E8 V3, pour Apache Spark sur une charge de travail de 1 To. Apache Spark 3.1.3 (version actuelle) a dépassé Apache Spark 3.1.2 (version précédente) de plus de 40 % dans le runtime de requête total pour les requêtes TPC-DS utilisant les mêmes spécifications matérielles. L’équipe Microsoft Spark a ajouté des optimisations disponibles dans Azure Synapse avec Azure HDInsight. Pour plus d’informations, consultez Accélérer vos charges de travail de données avec les mises à jour des performances d’Apache Spark 3.1.2 dans Azure Synapse
![]()
- Qatar Central
- Allemagne Nord
![]()
HDInsight est passé du JDK Java Azul Zulu 8 à
Adoptium Temurin JDK 8, qui prend en charge les runtimes certifiés TCK de haute qualité et la technologie associée pour une utilisation dans l’écosystème Java.HDInsight a migré vers
reload4j. Les modificationslog4js’appliquent à- Apache Hadoop
- Apache Zookeeper
- Apache Oozie
- Apache Ranger
- Apache Sqoop
- Apache Pig
- Apache Ambari
- Apache Kafka
- Apache Spark
- Apache Zeppelin
- Apache Livy
- Apache Rubix
- Apache Hive
- Apache Tez
- Apache HBase
- OMI
- Apache Pheonix
![]()
HDInsight doit implémenter TLS1.2 à l’avenir, et les versions antérieures sont mises à jour sur la plateforme. Si vous exécutez des applications sur HDInsight et qu’elles utilisent TLS 1.0 et 1.1, effectuez une mise à niveau vers TLS 1.2 pour éviter toute interruption des services.
Pour plus d’informations, consultez Guide pratique pour activer le protocole TLS (Transport Layer Security)
![]()
Fin de la prise en charge des clusters Azure HDInsight sur Ubuntu 16.04 LTS à partir du 30 novembre 2022. HDInsight commence à publier des images de cluster à l’aide d’Ubuntu 18.04 à compter du 27 juin 2021. Nous recommandons à nos clients qui exécutent des clusters à l’aide d’Ubuntu 16.04 de reconstruire leurs clusters avec les dernières images HDInsight d’ici le 30 novembre 2022.
Pour plus d’informations sur la vérification de la version Ubuntu du cluster, consultez ici
Exécutez la commande « lsb_release -a » dans le terminal.
Si la valeur de la propriété « Description » dans la sortie est « Ubuntu 16.04 LTS », cette mise à jour s’applique au cluster.
![]()
- Prise en charge de la sélection Zones de disponibilité pour les clusters Kafka et HBase (accès en écriture).
Correctifs de bogues open source
Correctifs de bogues pour Hive
| Correctifs de bogues | Apache JIRA |
|---|---|
| HIVE-26127 | Erreur INSERT OVERWRITE - Fichier introuvable |
| HIVE-24957 | Résultats incorrects lorsque la sous-requête a COALESCE dans le prédicat de corrélation |
| HIVE-24999 | HiveSubQueryRemoveRule génère un plan non valide pour la sous-requête IN avec plusieurs corrélations |
| HIVE-24322 | S’il existe une insertion directe, l’ID de tentative doit être vérifié lors de la lecture des manifestes échoue |
| HIVE-23363 | Mettre à niveau la dépendance DataNucleus vers la version 5.2 |
| HIVE-26412 | Créer une interface pour extraire les emplacements disponibles et ajouter la valeur par défaut |
| HIVE-26173 | Mettre à niveau derby vers 10.14.2.0 |
| HIVE-25920 | Placez Xerce2 à 2.12.2. |
| HIVE-26300 | Mettre à niveau la version de liaison de données Jackson vers la version 2.12.6.1+ pour éviter CVE-2020-36518 |
Date de publication : 10/08/2022
Cette version s’applique à HDInsight 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours.
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
![]()
Nouvelle fonctionnalité
1. Attacher des disques externes dans des clusters Hadoop/Spark HDI
Un cluster HDInsight est fourni avec un espace disque prédéfini basé sur une référence SKU. Cet espace peut ne pas suffire dans des scénarios de travail volumineux.
Cette nouvelle fonctionnalité vous permet d’ajouter des disques dans un cluster utilisé comme répertoire local du gestionnaire de nœuds. Ajoutez des disques aux nœuds Worker pendant la création de clusters HIVE et Spark, alors que les disques sélectionnés font partie des répertoires locaux du gestionnaire de nœuds.
Notes
Les disques ajoutés sont configurés uniquement pour les répertoires locaux du gestionnaire de nœuds.
Vous trouverez plus d’informations ici.
2. Analyse de journalisation sélective
L’analyse de journalisation sélective est désormais disponible dans toutes les régions pour la préversion publique. Vous pouvez connecter votre cluster à un espace de travail Log Analytics. Une fois l’analyse activée, vous pouvez voir les journaux et métriques tels que les journaux de sécurité HDInsight, Yarn Resource Manager, les métriques système, etc. Vous pouvez surveiller les charges de travail et voir comment elles affectent la stabilité du cluster. La journalisation sélective vous permet d’activer/désactiver toutes les tables ou d’activer des tables sélectives dans l’espace de travail Log Analytics. Vous pouvez ajuster le type de source pour chaque table car, dans la nouvelle version de Geneva Monitoring, une table a plusieurs sources.
- Le système Geneva Monitoring utilise mdsd (démon MDS) qui est un agent de surveillance, et fluentd pour collecter des journaux à l’aide de la couche de journalisation unifiée.
- La journalisation sélective utilise une action de script pour activer/désactiver des tables et leurs types de journaux. Étant donné qu’elle n’ouvre aucun nouveau port et ne modifie aucun paramètre de sécurité existant, il n’y a aucune modification de sécurité.
- L’action de script s’exécute en parallèle sur tous les nœuds spécifiés, et modifie les fichiers de configuration pour activer/désactiver des tables et leurs types de journaux.
Vous trouverez plus d’informations ici.
![]()
Fixe
Analytique des journaux d'activité
Log Analytics intégré avec Azure HDInsight exécutant OMS version 13 nécessite une mise à niveau vers OMS version 14 pour appliquer les dernières mises à jour de sécurité. Les clients qui utilisent une version antérieure du cluster avec OMS version 13 doivent installer OMS version 14 pour répondre aux exigences de sécurité. (Comment vérifier la version actuelle et Installer 14)
Comment vérifier votre version d’OMS actuelle
- Connectez-vous au cluster en utilisant SSH.
- Exécutez la commande suivante dans votre client SSH.
sudo /opt/omi/bin/ominiserver/ --version

Comment mettre à niveau votre version d’OMS de 13 à 14
- Connectez-vous au portail Azure
- Dans le groupe de ressources, sélectionnez la ressource de cluster HDInsight
- Sélectionnez Actions de script
- Dans le panneau Envoyer une action de script, choisissez un Type de script personnalisé
- Collez le lien suivant dans la zone URL du script Bash https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Sélectionnez Type(s) de nœud
- Sélectionnez Créer
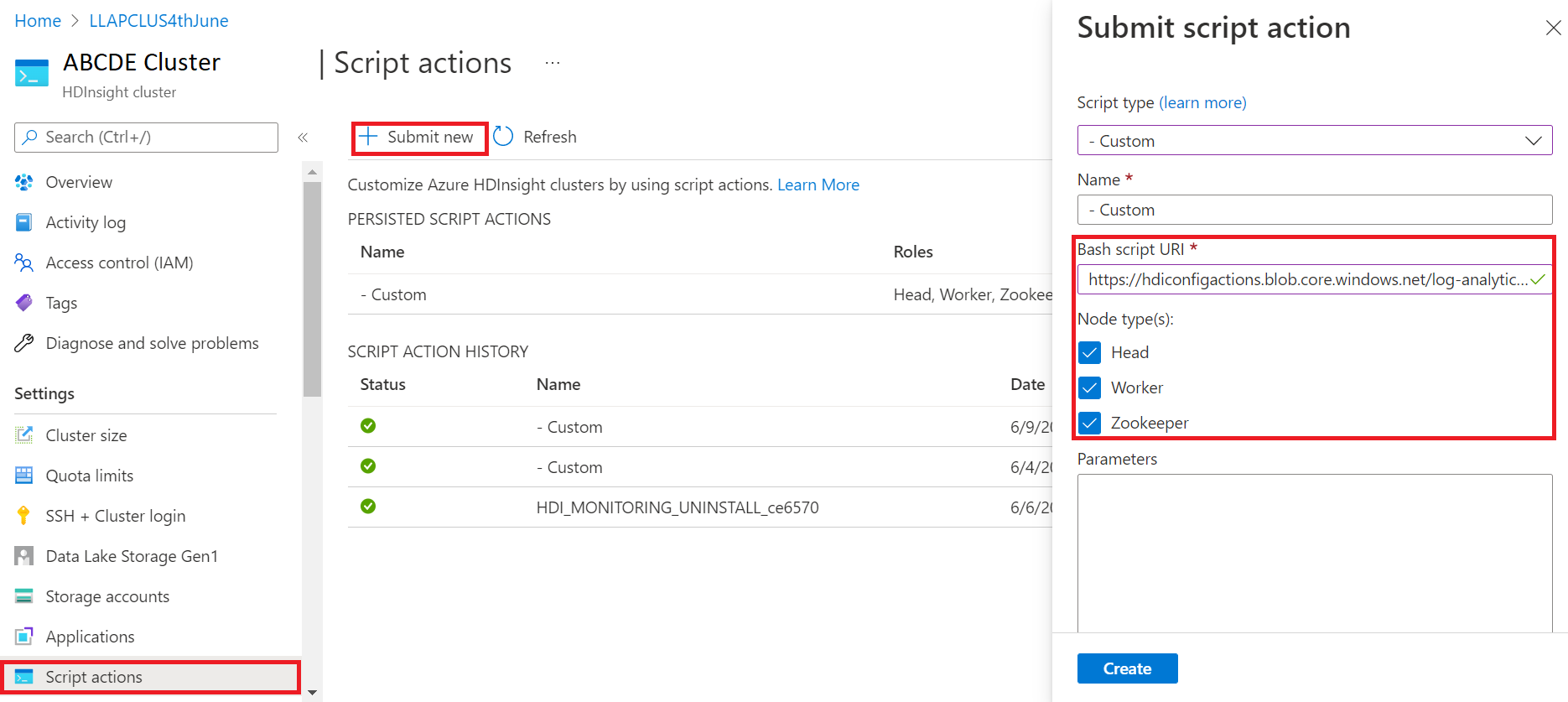
Vérifiez la réussite de l’installation du correctif en procédant comme suit :
Connectez-vous au cluster en utilisant SSH.
Exécutez la commande suivante dans votre client SSH.
sudo /opt/omi/bin/ominiserver/ --version
Autres correctifs de bogues
- L’interface CLI du journal Yarn ne pouvait pas récupérer les journaux si un fichier
TFileétait endommagé ou vide. - Résolution de l’erreur de détails du principal de service non valide lors de l’obtention du jeton OAuth à partir d’Azure Active Directory.
- Amélioration de la fiabilité de la création de cluster lorsque plus de 100 nœuds worker sont configurés.
Correctifs de bogues open source
Résolution des bogues TEZ
| Correctifs de bogues | Apache JIRA |
|---|---|
| Échec de build Tez : FileSaver.js introuvable | TEZ-4411 |
Exception de FS incorrecte quand l’entrepôt et scratchdir se trouvent sur des FS différentes |
TEZ-4406 |
| TezUtils.createConfFromByteString sur une configuration supérieure à 32 Mo lève l’exception com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils createByteStringFromConf devrait utiliser snappy au lieu de DeflaterOutputStream | TEZ-4113 |
| Mise à jour de la dépendance protobuf vers 3.x | TEZ-4363 |
Correctifs de bogues pour Hive
| Correctifs de bogues | Apache JIRA |
|---|---|
| Optimisations des performances de génération de fractionnement ORC | HIVE-21457 |
| Éviter de lire la table comme ACID quand son nom commence par « delta », mais que la table n’est pas transactionnelle et qu’une stratégie de fractionnement BI est utilisée | HIVE-22582 |
| Suppression d’un appel FS#exists d’AcidUtils#getLogicalLength | HIVE-23533 |
| Vectorisation d’OrcAcidRowBatchReader.computeOffset et optimisation du compartiment | HIVE-17917 |
Problèmes connus
HDInsight est compatible avec Apache HIVE 3.1.2. En raison d’un bogue dans cette version, la version de Hive affichée est 3.1.0 dans les interfaces de Hive. Toutefois, cela n’a aucun impact sur les fonctionnalités.
Date de publication : 10/08/2022
Cette version s’applique à HDInsight 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours.
HDInsight applique des pratiques de déploiement sécurisé qui impliquent un déploiement graduel des régions. La mise à disposition d’une nouvelle version dans toutes les régions peut durer jusqu’à 10 jours ouvrés.
![]()
Nouvelle fonctionnalité
1. Attacher des disques externes dans des clusters Hadoop/Spark HDI
Un cluster HDInsight est fourni avec un espace disque prédéfini basé sur une référence SKU. Cet espace peut ne pas suffire dans des scénarios de travail volumineux.
Cette nouvelle fonctionnalité vous permet d’ajouter des disques dans le cluster, qui seront utilisés comme répertoire local du gestionnaire de nœuds. Ajoutez des disques aux nœuds Worker pendant la création de clusters HIVE et Spark, alors que les disques sélectionnés font partie des répertoires locaux du gestionnaire de nœuds.
Notes
Les disques ajoutés sont configurés uniquement pour les répertoires locaux du gestionnaire de nœuds.
Vous trouverez plus d’informations ici.
2. Analyse de journalisation sélective
L’analyse de journalisation sélective est désormais disponible dans toutes les régions pour la préversion publique. Vous pouvez connecter votre cluster à un espace de travail Log Analytics. Une fois l’analyse activée, vous pouvez voir les journaux et métriques tels que les journaux de sécurité HDInsight, Yarn Resource Manager, les métriques système, etc. Vous pouvez surveiller les charges de travail et voir comment elles affectent la stabilité du cluster. La journalisation sélective vous permet d’activer/désactiver toutes les tables ou d’activer des tables sélectives dans l’espace de travail Log Analytics. Vous pouvez ajuster le type de source pour chaque table car, dans la nouvelle version de Geneva Monitoring, une table a plusieurs sources.
- Le système Geneva Monitoring utilise mdsd (démon MDS) qui est un agent de surveillance, et fluentd pour collecter des journaux à l’aide de la couche de journalisation unifiée.
- La journalisation sélective utilise une action de script pour activer/désactiver des tables et leurs types de journaux. Étant donné qu’elle n’ouvre aucun nouveau port et ne modifie aucun paramètre de sécurité existant, il n’y a aucune modification de sécurité.
- L’action de script s’exécute en parallèle sur tous les nœuds spécifiés, et modifie les fichiers de configuration pour activer/désactiver des tables et leurs types de journaux.
Vous trouverez plus d’informations ici.
![]()
Fixe
Analytique des journaux d'activité
Log Analytics intégré avec Azure HDInsight exécutant OMS version 13 nécessite une mise à niveau vers OMS version 14 pour appliquer les dernières mises à jour de sécurité. Les clients qui utilisent une version antérieure du cluster avec OMS version 13 doivent installer OMS version 14 pour répondre aux exigences de sécurité. (Comment vérifier la version actuelle et Installer 14)
Comment vérifier votre version d’OMS actuelle
- Connectez-vous au cluster en utilisant le protocole SSH.
- Exécutez la commande suivante dans votre client SSH.
sudo /opt/omi/bin/ominiserver/ --version
Comment mettre à niveau votre version d’OMS de 13 à 14
- Connectez-vous au portail Azure
- Dans le groupe de ressources, sélectionnez la ressource de cluster HDInsight
- Sélectionnez Actions de script
- Dans le panneau Envoyer une action de script, choisissez un Type de script personnalisé
- Collez le lien suivant dans la zone URL du script Bash https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Sélectionnez Type(s) de nœud
- Sélectionnez Créer
Vérifiez la réussite de l’installation du correctif en procédant comme suit :
Connectez-vous au cluster en utilisant SSH.
Exécutez la commande suivante dans votre client SSH.
sudo /opt/omi/bin/ominiserver/ --version
Autres correctifs de bogues
- L’interface CLI du journal Yarn ne pouvait pas récupérer les journaux si un fichier
TFileétait endommagé ou vide. - Résolution de l’erreur de détails du principal de service non valide lors de l’obtention du jeton OAuth à partir d’Azure Active Directory.
- Amélioration de la fiabilité de la création de cluster lorsque plus de 100 nœuds worker sont configurés.
Correctifs de bogues open source
Résolution des bogues TEZ
| Correctifs de bogues | Apache JIRA |
|---|---|
| Échec de build Tez : FileSaver.js introuvable | TEZ-4411 |
Exception de FS incorrecte quand l’entrepôt et scratchdir se trouvent sur des FS différentes |
TEZ-4406 |
| TezUtils.createConfFromByteString sur une configuration supérieure à 32 Mo lève l’exception com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils createByteStringFromConf devrait utiliser snappy au lieu de DeflaterOutputStream | TEZ-4113 |
| Mise à jour de la dépendance protobuf vers 3.x | TEZ-4363 |
Correctifs de bogues pour Hive
| Correctifs de bogues | Apache JIRA |
|---|---|
| Optimisations des performances de génération de fractionnement ORC | HIVE-21457 |
| Éviter de lire la table comme ACID quand son nom commence par « delta », mais que la table n’est pas transactionnelle et qu’une stratégie de fractionnement BI est utilisée | HIVE-22582 |
| Suppression d’un appel FS#exists d’AcidUtils#getLogicalLength | HIVE-23533 |
| Vectorisation d’OrcAcidRowBatchReader.computeOffset et optimisation du compartiment | HIVE-17917 |
Problèmes connus
HDInsight est compatible avec Apache HIVE 3.1.2. En raison d’un bogue dans cette version, la version de Hive affichée est 3.1.0 dans les interfaces de Hive. Toutefois, cela n’a aucun impact sur les fonctionnalités.
Date de publication : 03/06/2022
Cette version s’applique à HDInsight 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Présentation de la nouvelle version
Hive Warehouse Connector (HWC) sur Spark v3.1.2
Le connecteur d’entrepôt Hive (HWC) vous permet de profiter des fonctionnalités uniques de Hive et de Spark afin de créer de puissantes applications Big Data. HWC est actuellement pris en charge pour Spark v2.4 uniquement. Cette fonctionnalité ajoute une valeur métier en autorisant les transactions ACID sur les tables Hive à l’aide de Spark. Cette fonctionnalité est utile pour les clients qui utilisent Hive et Spark dans leur patrimoine de données. Pour plus d’informations, consultez Apache Spark et Hive – Hive Warehouse Connector – Azure HDInsight | Microsoft Docs
Ambari
- Modifications apportées à la mise à l’échelle et à l’approvisionnement
- HDI Hive est désormais compatible avec OSS version 3.1.2
La version HDI Hive 3.1 est mise à niveau vers OSS Hive 3.1.2. Cette version comporte l’ensemble des correctifs et fonctionnalités disponibles dans la version open source Hive 3.1.2.
Notes
Spark
- Si vous utilisez l’interface utilisateur Azure pour créer un cluster Spark pour HDInsight, vous verrez dans la liste déroulante une autre version de Spark 3.1 (HDI 5.0) avec les versions antérieures. Cette version est une version renommée de Spark 3.1 (HDI 4.0). Il s’agit uniquement d’une modification au niveau de l’interface utilisateur, qui n’a aucun impact sur les utilisateurs existants et ceux qui utilisent déjà le modèle ARM.
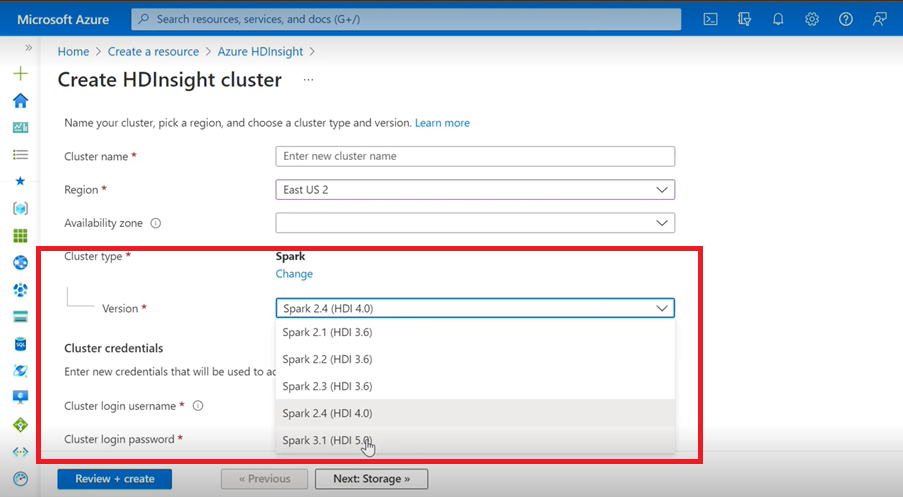
Notes
Interactive Query
- Si vous créez un cluster Interactive Query, vous verrez dans la liste déroulante une autre version, Interactive Query 3.1 (HDI 5.0).
- Si vous comptez utiliser la version Spark 3.1 avec Hive, qui nécessite la prise en charge d’ACID, vous devez sélectionner cette version, Interactive Query 3.1 (HDI 5.0).
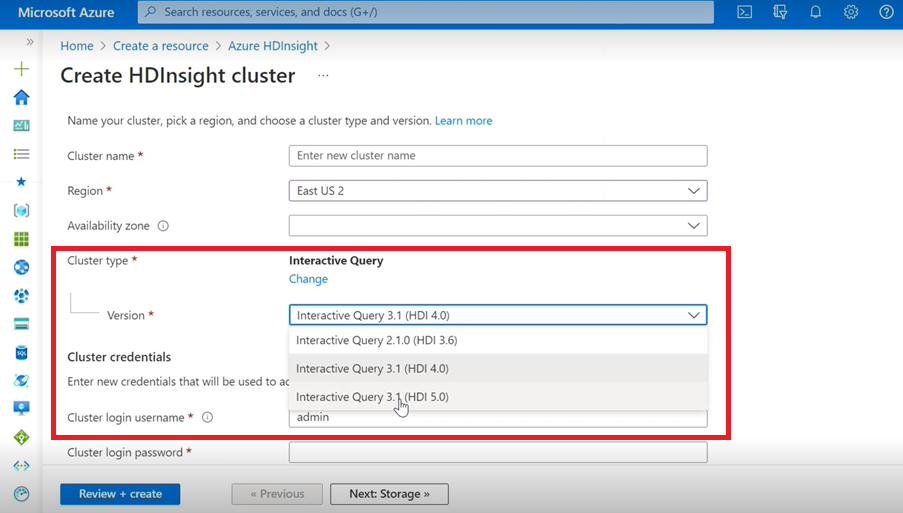
Résolution des bogues TEZ
| Correctifs de bogues | Apache JIRA |
|---|---|
| TezUtils.createConfFromByteString sur une configuration supérieure à 32 Mo lève l’exception com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils createByteStringFromConf doit utiliser snappy au lieu de DeflaterOutputStream | TEZ-4113 |
Correctifs de bogues pour HBase
| Correctifs de bogues | Apache JIRA |
|---|---|
TableSnapshotInputFormat doit utiliser ReadType.STREAM pour analyser les fichiers HFiles |
HBASE-26273 |
| Ajout d’une option pour désactiver scanMetrics dans TableSnapshotInputFormat | HBASE-26330 |
| Correctif pour ArrayIndexOutOfBoundsException lorsque l’équilibreur est exécuté | HBASE-22739 |
Correctifs de bogues pour Hive
| Correctifs de bogues | Apache JIRA |
|---|---|
| NPE lors de l’insertion de données avec la clause ’distribute by’ avec optimisation du tri dynpart | HIVE-18284 |
| La commande MSCK REPAIR avec filtrage de partition échoue lors de la suppression de partitions | HIVE-23851 |
| Exception incorrecte levée si capacity<=0 | HIVE-25446 |
| Prise en charge de la charge parallèle pour HastTables - Interfaces | HIVE-25583 |
| Inclusion de MultiDelimitSerDe dans HiveServer2 par défaut | HIVE-20619 |
| Suppression des classes glassfish.jersey et mssql-jdbc de jdbc-standalone jar | HIVE-22134 |
| Exception de pointeur Null lors de l’exécution du compactage sur une table MM. | HIVE-21280 |
Les requêtes Hive de grande taille par le biais de knox échouent avec Canal cassé - échec de l’écriture |
HIVE-22231 |
| Ajout de la possibilité pour l’utilisateur de définir un utilisateur de liaison | HIVE-21009 |
| Implémentation d’UDF pour interpréter la date/le timestamp à l’aide de sa représentation interne et de son calendrier hybride grégorien-julien | HIVE-22241 |
| Option Beeline pour afficher/ne pas afficher le rapport d’exécution | HIVE-22204 |
| Tez : SplitGenerator tente de rechercher des fichiers de plan, qui n’existent pas pour Tez | HIVE-22169 |
Suppression de la journalisation coûteuse du cache LLAP hotpath |
HIVE-22168 |
| UDF : FunctionRegistry synchronise la classe org.apache.hadoop.hive.ql.udf.UDFType | HIVE-22161 |
| Empêchement de la création d’un ajout de routage de requête si la propriété a la valeur false | HIVE-22115 |
| Suppression de la synchronisation entre requêtes pour l’évaluation de partition | HIVE-22106 |
| Configuration du répertoire de base de Hive ignorée lors de la planification | HIVE-21182 |
| Création d’un répertoire de base pour Tez ignorée si RPC est activé | HIVE-21171 |
Basculement des UDF Hive pour utiliser le moteur regex Re2J |
HIVE-19661 |
| Les tables en cluster migrées utilisant bucketing_version 1 sur hive 3 utilisent bucketing_version 2 pour les insertions | HIVE-22429 |
| Compartimentage : la version 1 du compartimentage partitionnait incorrectement les données | HIVE-21167 |
| Ajout de l’en-tête de licence ASF au fichier nouvellement ajouté | HIVE-22498 |
| Améliorations apportées à l’outil de schéma pour prendre en charge mergeCatalog | HIVE-22498 |
| Hive avec TEZ UNION ALL et UDTF cause une perte de données | HIVE-21915 |
| Fractionner des fichiers texte même si l’en-tête/pied de page existe | HIVE-21924 |
| MultiDelimitSerDe retourne des résultats incorrects dans la dernière colonne quand le fichier chargé contient plus de colonnes que le schéma de table | HIVE-22360 |
| Client externe LLAP - Besoin de réduire l’empreinte LlapBaseInputFormat#getSplits() | HIVE-22221 |
| Le nom de colonne avec mot clé réservé n’est pas bouclé lorsque la requête incluant la jointure sur la table avec la colonne masque est réécrite (Zoltan Matyus via Zoltan Haindrich) | HIVE-22208 |
Empêchement du RuntimeException lié à l’arrêt de LLAP sur AMReporter |
HIVE-22113 |
| Le pilote du service d’état LLAP peut être bloqué avec un ID d’application Yarn incorrect | HIVE-21866 |
| OperationManager.queryIdOperation ne nettoie pas correctement plusieurs queryIds | HIVE-22275 |
| L’arrêt d’un gestionnaire de nœuds bloque le redémarrage du service LLAP | HIVE-22219 |
| Stack OverflowError lors de la suppression d’un grand nombre de partitions | HIVE-15956 |
| Échec de la vérification d’accès lorsqu’un répertoire temporaire est supprimé | HIVE-22273 |
| Correction des mauvais résultats/de l’exception ArrayOutOfBound dans les jointures de mappage externe gauche sur des conditions de limites spécifiques | HIVE-22120 |
| Suppression de la balise de gestion de distribution de pom.xml | HIVE-19667 |
| Le temps d’analyse peut être élevé s’il existe des sous-requêtes profondément imbriquées | HIVE-21980 |
Pour ALTER TABLE t SET TBLPROPERTIES (’EXTERNAL’=’TRUE’); TBL_TYPE modifications d’attribut ne se reflétant pas pour les non-majuscules |
HIVE-20057 |
JDBC : HiveConnection nuance les interfaces log4j |
HIVE-18874 |
Mise à jour des URL de référentiel dans poms - branch version 3.1 |
HIVE-21786 |
Tests DBInstall rompus sur les versions master et branch-3.1 |
HIVE-21758 |
| Le chargement des données dans une table compartimentée ignore les spécifications des partitions et charge les données dans une partition par défaut | HIVE-21564 |
| Requêtes avec condition de jointure ayant un timestamp ou un timestamp avec un littéral de fuseau horaire local lèvent une SemanticException | HIVE-21613 |
| L’analyse les statistiques de calcul pour la colonne laissent le répertoire intermédiaire sur HDFS | HIVE-21342 |
| Modification incompatible dans le calcul de compartiment Hive | HIVE-21376 |
| Fourniture d’un autoriseur de secours lorsqu’aucun autre autoriseur n’est utilisé | HIVE-20420 |
| Certains appels à alterPartitions lèvent une exception « NumberFormatException: null » | HIVE-18767 |
| HiveServer2 : Le sujet préauthentifié pour le transport http n’est pas conservé pendant toute la durée de la communication http dans certains cas | HIVE-20555 |
Date de publication : 10/03/2022
Cette version s’applique à HDInsight 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Les versions de système d’exploitation pour cette mise en production sont les suivantes :
- HDInsight 4.0 : Ubuntu 18.04.5
Spark 3.1 est désormais généralement disponible
Spark 3.1 est désormais généralement disponible sur la version HDInsight 4.0. Cette version inclut
- Exécution de requête adaptative,
- Conversion de jointure par tri-fusion en jointure par hachage-diffusion,
- Optimiseur Catalyst Spark,
- Nettoyage de partition dynamique,
- Les clients seront en mesure de créer des clusters Spark 3.1, non des clusters Spark 3.0 (préversion).
Pour plus d’informations, consultez Apache Spark 3.1 est désormais généralement disponible sur HDInsight - Communauté Microsoft Tech.
Pour obtenir la liste complète des améliorations, consultez les Notes de publication d’Apache Spark 3.1.
Pour plus d’informations sur la migration, consultez le guide de migration.
Kafka 2.4 est désormais généralement disponible
Kafka 2.4.1 est désormais généralement disponible. Pour plus d’informations, consultez les Notes de publication de Kafka 2.4.1. Parmi les autres fonctionnalités, citons la disponibilité de MirrorMaker 2, une nouvelle partition de rubrique AtMinIsr de catégorie de métrique, un temps de démarrage de répartiteur amélioré par mmap différé à la demande de fichiers d’index, davantage de métriques de consommateur pour observer le comportement d’interrogation des utilisateurs.
Le type de données de mappage dans HWC est désormais pris en charge dans HDInsight 4.0
Cette version inclut la prise en charge du type de données de mappage pour HWC 1.0 (Spark 2.4) via l’application spark-Shell, et tous les autres clients Spark pris en charge par HWC. Les améliorations suivantes sont incluses comme d’autres types de données :
Un utilisateur peut
- Créer une table Hive avec une ou plusieurs colonnes contenant un type de données de mappage, insérer des données dans celle-ci et lire les résultats à partir de celle-ci.
- Créer une tramedonnées Apache Spark avec le type de mappage et effectuer des lectures et écritures de lot/flux.
Nouvelles régions
HDInsight a désormais étendu sa présence géographique à deux nouvelles régions : Chine Est 3 et Chine Nord 3.
Modifications du rétroportage OSS
Rétroportages OSS inclus dans Hive, y compris HWC 1.0 (Spark 2.4), qui prend en charge le type de données de mappage.
Voici les JIRA Apache rétroportés OSS pour cette version :
| Fonctionnalité affectée | Apache JIRA |
|---|---|
| Les requêtes SQL directes de metastore avec IN/(NOT in) doivent être fractionnées en fonction des paramètres maximaux autorisés par SQL DB | HIVE-25659 |
Mise à niveau de log4j 2.16.0 vers 2.17.0 |
HIVE-25825 |
Mise à jour de la version Flatbuffer |
HIVE-22827 |
| Prise en charge du type de données de mappage en mode natif au format Arrow | HIVE-25553 |
| Client externe LLAP - Gestion des valeurs imbriquées quand le struct parent est null | HIVE-25243 |
| Mise à niveau de la version Arrow vers 0.11.0 | HIVE-23987 |
Avis de dépréciation
Groupes de machines virtuelles identiques Azure sur HDInsight
HDInsight n’utilisera plus de groupes de machines virtuelles identiques Azure pour approvisionner les clusters. Aucun changement cassant n’est attendu. Les clusters HDInsight existants sur des groupes de machines virtuelles identiques n’ont aucun impact. Les nouveaux clusters sur les dernières images n’utiliseront plus Virtual Machine Scale Sets.
La mise à l’échelle de charges de travail Azure HDInsight HBase sera désormais prise en charge uniquement à l’aide d’une mise à l’échelle manuelle
À partir du 1° mars 2022, HDInsight prendra uniquement en charge la mise à l’échelle manuelle pour HBase. Cela n’aura aucun impact sur les clusters en cours d’exécution. Les nouveaux clusters HBase ne pourront pas activer la mise à l’échelle automatique basée sur une planification. Pour plus d’informations sur la mise à l’échelle manuelle de votre cluster HBase, reportez-vous à notre documentation sur la mise à l’échelle manuelle des clusters Azure HDInsight
Date de publication : 27/12/2021
Cette version s’applique à HDInsight 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Les versions de système d’exploitation pour cette mise en production sont les suivantes :
- HDInsight 4.0 : Ubuntu 18.04.5 LTS
L’image HDInsight 4.0 a été mise à jour pour atténuer la vulnérabilité de Log4j, comme décrit dans la Réponse de Microsoft à CVE-2021-44228 Apache Log4j 2.
Remarque
- Les clusters HDI 4.0 créés après le 27 décembre 2021 00:00 UTC sont créés avec une version mise à jour de l’image qui atténue les vulnérabilités de
log4j. Par conséquent, les clients n’ont pas besoin de patcher/redémarrer ces clusters. - Pour les nouveaux clusters HDInsight 4.0 créés entre le 16 décembre 2021 à 1h15 UTC et le 27 décembre 2021 à minuit UTC, HDInsight 3.6 ou dans les abonnements épinglés après 16 décembre 2021, le correctif est automatiquement appliqué dans l’heure de création du cluster. Toutefois, les clients doivent redémarrer leurs nœuds pour que la mise à jour corrective soit terminée (sauf pour les nœuds de gestion Kafka, qui sont redémarrés automatiquement).
Date de publication : 27/07/2021
Cette version s’applique à la fois à HDInsight 3.6 et HDInsight 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Les versions de système d’exploitation pour cette mise en production sont les suivantes :
- HDInsight 3.6 : Ubuntu 16.04.7 LTS
- HDInsight 4.0 : Ubuntu 18.04.5 LTS
Nouvelles fonctionnalités
La prise en charge par Azure HDInsight de la connectivité publique restreinte est en disponibilité générale depuis le 15 octobre 2021
Azure HDInsight prend désormais en charge une connectivité publique restreinte dans toutes les régions. Voici quelques-unes des principales caractéristiques de cette capacité :
- Possibilité d’inverser la communication entre le fournisseur de ressources et le cluster de façon à obtenir un trafic sortant du cluster vers le fournisseur de ressources
- Prise en charge de l’apport de vos propres ressources Private Link (par exemple, stockage, SQL, coffre de clés) pour que le cluster HDinsight accède aux ressources via le réseau privé uniquement
- Aucune IP publique n’est provisionnée
Grâce à cette nouvelle capacité, vous pouvez également ignorer les règles de trafic entrant relatives aux étiquettes de service de groupe de sécurité réseau (NSG) pour les adresses IP de gestion HDInsight. En savoir plus sur la restriction de la connectivité publique
La prise en charge par Azure HDInsight d’Azure Private Link est en disponibilité générale depuis le 15 octobre 2021
Vous pouvez maintenant utiliser des points de terminaison privés pour vous connecter à vos clusters HDInsight par liaison privée. La liaison privée peut être utilisée dans des scénarios inter-réseaux virtuels où l’appairage de réseaux virtuels n’est pas disponible ni activé.
Azure Private Link vous permet d’accéder aux services Azure PaaS (par exemple Stockage Azure et SQL Database) ainsi qu’aux services de partenaires ou de clients hébergés par Azure sur un point de terminaison privé dans votre réseau virtuel.
Le trafic entre votre réseau virtuel et le service transite par le réseau principal de Microsoft. L’exposition de votre service à l’Internet public n’est plus nécessaire.
Pour plus d’informations, consultezActiver une liaison privée.
Nouvelle expérience d’intégration d’Azure Monitor (préversion)
La nouvelle expérience d’intégration d’Azure Monitor sera en préversion dans les régions USA Est et Europe Ouest avec cette version. Découvrez-en plus sur la nouvelle expérience d’Azure Monitor ici.
Dépréciation
HDInsight version 3.6 est déprécié depuis le 1er octobre 2022.
Changements de comportement
La requête interactive HDInsight prend uniquement en charge la mise à l’échelle automatique basée sur une planification
À mesure que les scénarios client augmentent et se diversifient, nous avons identifié certaines limitations avec la mise à l’échelle automatique basée sur la charge Interactive Query (LLAP). Ces limitations sont dues à la nature de la dynamique des requêtes LLAP, aux problèmes de précision de la prédiction de la charge future et aux problèmes dans la redistribution des tâches du planificateur LLAP. En raison de ces limitations, les utilisateurs peuvent voir leurs requêtes s’exécuter plus lentement sur les clusters LLAP lorsque la mise à l’échelle automatique est activée. L’impact sur les performances peut être plus important que le coût de la mise à l’échelle automatique.
À partir de juillet 2021, la charge de travail Interactive Query dans HDInsight prend uniquement en charge la mise à l’échelle automatique basée sur la planification. Vous ne pouvez plus activer la mise à l’échelle automatique basée sur la charge sur les nouveaux clusters Interactive Query. Les clusters en cours d’exécution existants peuvent continuer à s’exécuter avec les limitations connues décrites ci-dessus.
Microsoft vous recommande de passer à une mise à l’échelle automatique basée sur une planification pour LLAP. Vous pouvez analyser le modèle d’utilisation actuel de votre cluster via le tableau de bord Grafana Hive. Pour plus d’informations, consultez Mettre à l’échelle automatiquement les clusters Azure HDInsight.
Changements à venir
Les modifications suivantes se produiront dans les versions à venir.
Le composant LLAP intégré dans le cluster ESP Spark sera supprimé
Le cluster HDInsight 4.0 ESP Spark contient des composants LLAP intégrés s’exécutant sur les deux nœuds principaux. Les composants LLAP du cluster ESP Spark ont été ajoutés à l’origine pour HDInsight 3.6 ESP Spark, mais n’ont pas de cas utilisateur réel pour HDInsight 4.0 ESP Spark. Dans la prochaine version prévue pour septembre 2021, HDInsight supprimera le composant LLAP intégré du cluster HDInsight 4.0 ESP Spark. Cette modification permet de décharger la charge de travail du nœud principal, puis d’éviter la confusion entre ESP Spark et le type de cluster ESP Interactive Hive.
Nouvelle région
- USA Ouest 3
-
JioInde Ouest - Centre de l’Australie
Changement de la version des composants
La version du composant suivante a été modifiée avec cette version :
- ORC version 1.5.1 à 1.5.9
Les versions actuelles des composants pour HDInsight 4.0 et HDInsight 3.6 sont indiquées dans ce document.
JIRA rétroportés
Les JIRA Apache rétroportés pour cette version sont les suivants :
| Fonctionnalité affectée | Apache JIRA |
|---|---|
| Date / Timestamp | HIVE-25104 |
| HIVE-24074 | |
| HIVE-22840 | |
| HIVE-22589 | |
| HIVE-22405 | |
| HIVE-21729 | |
| HIVE-21291 | |
| HIVE-21290 | |
| Fonctions définies par l'utilisateur | HIVE-25268 |
| HIVE-25093 | |
| HIVE-22099 | |
| HIVE-24113 | |
| HIVE-22170 | |
| HIVE-22331 | |
| ORC | HIVE-21991 |
| HIVE-21815 | |
| HIVE-21862 | |
| Schéma de table | HIVE-20437 |
| HIVE-22941 | |
| HIVE-21784 | |
| HIVE-21714 | |
| HIVE-18702 | |
| HIVE-21799 | |
| HIVE-21296 | |
| Gestion des charges de travail | HIVE-24201 |
| Compactage | HIVE-24882 |
| HIVE-23058 | |
| HIVE-23046 | |
| Vue matérialisée | HIVE-22566 |
Correction du prix pour les machines virtuelles HDInsight Dv2
Une erreur de tarification a été corrigée le 25 avril 2021, pour la série de machines virtuelles Dv2 sur HDInsight. L’erreur de tarification a entraîné un coût réduit pour les factures de certains clients avant le 25 avril, et avec la correction, les prix correspondent désormais à ceux qui ont été publiés dans la page de tarification HDInsight et la calculatrice de prix HDInsight. L’erreur de tarification a affecté les clients qui ont utilisé des machines virtuelles Dv2 dans les régions suivantes :
- Centre du Canada
- Est du Canada
- Asie Est
- Afrique du Sud Nord
- Asie Sud-Est
- Émirats arabes unis Centre
À partir du 25 avril 2021, le montant corrigé pour les machines virtuelles Dv2 s’appliquera à votre compte. Les notifications client ont été envoyées aux propriétaires d’abonnements avant la modification. Vous pouvez utiliser la calculatrice de prix, la page de tarification HDInsight ou le panneau Créer un cluster HDInsight dans le portail Azure pour afficher les coûts corrigés pour les machines virtuelles Dv2 dans votre région.
Aucune autre action n’est nécessaire de votre côté. La correction du prix s’applique uniquement à l’utilisation le 25 avril 2021 ou après dans les régions spécifiées, et non à toute utilisation avant cette date. Pour vous assurer que vous disposez de la solution la plus performante et la plus rentable, nous vous recommandons de passer en revue la tarification, les processeurs virtuels et la RAM pour vos clusters Dv2, et de comparer les spécifications Dv2 aux machines virtuelles Ev3 afin de déterminer si votre solution peut tirer parti de l’utilisation de l’une des nouvelles séries de machines virtuelles.
Date de publication : 02/06/2021
Cette version s’applique à la fois à HDInsight 3.6 et HDInsight 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Les versions de système d’exploitation pour cette mise en production sont les suivantes :
- HDInsight 3.6 : Ubuntu 16.04.7 LTS
- HDInsight 4.0 : Ubuntu 18.04.5 LTS
Nouvelles fonctionnalités
Mise à niveau de la version du système d’exploitation
Comme indiqué dans l’article sur le cycle de publication d’Ubuntu, le noyau Ubuntu 16.04 arrive en fin de vie (EOL) en avril 2021. Nous avons commencé à déployer la nouvelle image de cluster HDInsight 4.0 qui s’exécute sur Ubuntu 18.04 avec cette mise en production. Une fois disponibles, les clusters HDInsight 4.0 nouvellement créés s’exécutent par défaut sur Ubuntu 18.04. Les clusters existants sur Ubuntu 16.04 s’exécutent en l’état avec une prise en charge complète.
HDInsight 3.6 continuera de s’exécuter sur Ubuntu 16.04. Il passera au support De base (au lieu du support Standard) à partir du 1er juillet 2021. Pour plus d’informations sur les dates et les options de prise en charge, consultez Versions d’Azure HDInsight. Ubuntu 18.04 ne sera pas pris en charge pour HDInsight 3.6. Si vous souhaitez utiliser Ubuntu 18.04, vous devez migrer vos clusters vers HDInsight 4.0.
Vous devez supprimer et recréer vos clusters si vous souhaitez déplacer des clusters HDInsight 4.0 existants vers Ubuntu 18.04. Prévoyez de créer ou de recréer vos clusters une fois que la prise en charge d’Ubuntu 18.04 devient disponible.
Après avoir créé le nouveau cluster, vous pouvez établir une connexion SSH à votre cluster et exécuter sudo lsb_release -a pour vérifier qu’il s’exécute sur Ubuntu 18.04. Nous vous recommandons de tester d’abord vos applications dans vos abonnements de test avant de passer à la production.
Optimisations de la mise à l’échelle sur les clusters d’écritures accélérées HBase
HDInsight a apporté quelques améliorations et optimisations concernant la mise à l’échelle pour les clusters activés en écriture accélérée HBase. En savoir plus sur l’écriture accélérée HBase.
Dépréciation
Cette version ne fait l’objet d’aucune dépréciation.
Changements de comportement
Désactiver la taille de machine virtuelle Standard_A5 comme nœud principal pour HDInsight 4.0
Le nœud principal de cluster HDInsight est chargé de l’initialisation et de la gestion du cluster. La taille de machine virtuelle Standard_A5 présente des problèmes de fiabilité en tant que nœud principal pour HDInsight 4.0. À partir de cette version, les clients ne pourront plus créer de clusters avec la taille de machine virtuelle Standard_A5 comme nœud principal. Vous pouvez utiliser d’autres machines virtuelles à deux cœurs comme E2_v3 ou E2s_v3. Les clusters existants fonctionneront tels quels. Une machine virtuelle à quatre cœurs est fortement recommandée pour le nœud principal afin de garantir la haute disponibilité et la fiabilité des clusters HDInsight de production.
Ressource d’interface réseau non visible pour les clusters s’exécutant sur des groupes de machines virtuelles identiques Azure
HDInsight migre progressivement vers les groupes de machines virtuelles identiques Azure. Les interfaces réseau des machines virtuelles ne sont plus visibles par les clients pour les clusters qui utilisent des groupes de machines virtuelles identiques Azure.
Changements à venir
Les changements suivants se produiront dans les prochaines versions.
La requête interactive HDInsight prend uniquement en charge la mise à l’échelle automatique basée sur une planification
À mesure que les scénarios client augmentent et se diversifient, nous avons identifié certaines limitations avec la mise à l’échelle automatique basée sur la charge Interactive Query (LLAP). Ces limitations sont dues à la nature de la dynamique des requêtes LLAP, aux problèmes de précision de la prédiction de la charge future et aux problèmes dans la redistribution des tâches du planificateur LLAP. En raison de ces limitations, les utilisateurs peuvent voir leurs requêtes s’exécuter plus lentement sur les clusters LLAP lorsque la mise à l’échelle automatique est activée. L’impact sur les performances peut être plus important que le coût de la mise à l’échelle automatique.
À partir de juillet 2021, la charge de travail Interactive Query dans HDInsight prend uniquement en charge la mise à l’échelle automatique basée sur la planification. Vous ne pouvez plus activer la mise à l’échelle automatique sur les nouveaux clusters Interactive Query. Les clusters en cours d’exécution existants peuvent continuer à s’exécuter avec les limitations connues décrites ci-dessus.
Microsoft vous recommande de passer à une mise à l’échelle automatique basée sur une planification pour LLAP. Vous pouvez analyser le modèle d’utilisation actuel de votre cluster via le tableau de bord Grafana Hive. Pour plus d’informations, consultez Mettre à l’échelle automatiquement les clusters Azure HDInsight.
La convention d’affectation de noms pour les hôtes de machine virtuelle sera modifié le 1er juillet 2021
HDInsight utilise désormais les machines virtuelles Azure pour approvisionner le cluster. Le service migre progressivement vers les groupes de machines virtuelles identiques Azure. Cette migration modifiera le format du nom de domaine complet des noms d’hôte de cluster, et la séquence des nombres dans le nom d’hôte ne sera pas garantie. Si vous souhaitez obtenir les noms de domaine complets pour chaque nœud, référez-vous à Rechercher les noms d’hôte des nœuds de cluster.
Passer à des groupes de machines virtuelles identiques Azure
HDInsight utilise désormais les machines virtuelles Azure pour approvisionner le cluster. Le service migre progressivement vers les groupes de machines virtuelles identiques Azure. L’ensemble du processus peut prendre plusieurs mois. Une fois les régions et les abonnements migrés, les clusters HDInsight nouvellement créés s’exécuteront sur des groupes de machines virtuelles identiques sans l’intervention du client. Aucun changement cassant n’est prévu.
Date de publication : 24/03/2021
Nouvelles fonctionnalités
Version préliminaire Spark 3.0
HDInsight a ajouté la prise en charge de Spark 3.0.0 à HDInsight 4.0 en tant que fonctionnalité d’évaluation.
Version préliminaire Kafka 2.4
HDInsight a ajouté la prise en charge de Kafka 2.4.1 à HDInsight 4.0 en tant que fonctionnalité d’évaluation.
Prise en charge de la série Eav4
HDInsight a ajouté la prise en charge de la série Eav4 dans cette version.
Passage à des groupes de machines virtuelles identiques Azure
HDInsight utilise désormais les machines virtuelles Azure pour approvisionner le cluster. Le service migre progressivement vers les groupes de machines virtuelles identiques Azure. L’ensemble du processus peut prendre plusieurs mois. Une fois les régions et les abonnements migrés, les clusters HDInsight nouvellement créés s’exécuteront sur des groupes de machines virtuelles identiques sans l’intervention du client. Aucun changement cassant n’est prévu.
Dépréciation
Cette version ne fait l’objet d’aucune dépréciation.
Changements de comportement
La version de cluster par défaut est remplacée par la version 4.0
La version par défaut du cluster HDInsight passe de la version 3.6 à la version 4.0. Pour plus d’informations sur les versions disponibles, consultez Versions disponibles. En savoir plus sur les nouveautés de HDInsight 4.0.
Les tailles de machine virtuelle du cluster par défaut sont remplacées par la série Ev3
Les tailles de machine virtuelle du cluster par défaut passent de la série D à la série Ev3. Cette modification s’applique aux nœuds principaux et aux nœuds Worker. Pour éviter que cette modification n’ait une incidence sur vos workflows déjà testés, spécifiez les tailles de machine virtuelle que vous souhaitez utiliser dans le modèle ARM.
Ressource d’interface réseau non visible pour les clusters s’exécutant sur des groupes de machines virtuelles identiques Azure
HDInsight migre progressivement vers les groupes de machines virtuelles identiques Azure. Les interfaces réseau des machines virtuelles ne sont plus visibles par les clients pour les clusters qui utilisent des groupes de machines virtuelles identiques Azure.
Changements à venir
Les changements suivants se produiront dans les prochaines versions.
La requête interactive HDInsight prend uniquement en charge la mise à l’échelle automatique basée sur une planification
À mesure que les scénarios client augmentent et se diversifient, nous avons identifié certaines limitations avec la mise à l’échelle automatique basée sur la charge Interactive Query (LLAP). Ces limitations sont dues à la nature de la dynamique des requêtes LLAP, aux problèmes de précision de la prédiction de la charge future et aux problèmes dans la redistribution des tâches du planificateur LLAP. En raison de ces limitations, les utilisateurs peuvent voir leurs requêtes s’exécuter plus lentement sur les clusters LLAP lorsque la mise à l’échelle automatique est activée. L’impact sur les performances peut être plus important que le coût de la mise à l’échelle automatique.
À partir de juillet 2021, la charge de travail Interactive Query dans HDInsight prend uniquement en charge la mise à l’échelle automatique basée sur la planification. Vous ne pouvez plus activer la mise à l’échelle automatique sur les nouveaux clusters Interactive Query. Les clusters en cours d’exécution existants peuvent continuer à s’exécuter avec les limitations connues décrites ci-dessus.
Microsoft vous recommande de passer à une mise à l’échelle automatique basée sur une planification pour LLAP. Vous pouvez analyser le modèle d’utilisation actuel de votre cluster via le tableau de bord Grafana Hive. Pour plus d’informations, consultez Mettre à l’échelle automatiquement les clusters Azure HDInsight.
Mise à niveau de la version du système d’exploitation
Les clusters HDInsight sont en cours d’exécution sur Ubuntu 16.04 LTS. Comme indiqué dans l’article sur le cycle de publication d’Ubuntu, le noyau Ubuntu 16.04 arrivera en fin de vie (EOL) en avril 2021. Nous allons commencer à déployer la nouvelle image de cluster HDInsight 4.0 qui s’exécute sur Ubuntu 18.04 en mai 2021. Une fois disponibles, les clusters HDInsight 4.0 nouvellement créés s’exécuteront par défaut sur Ubuntu 18.04. Les clusters existants sur Ubuntu 16.04 s’exécuteront en l’état avec une prise en charge complète.
HDInsight 3.6 continuera de s’exécuter sur Ubuntu 16.04. Il atteindra la fin du support standard d’ici le 30 juin 2021 et passera au support De base à compter du 1er juillet 2021. Pour plus d’informations sur les dates et les options de prise en charge, consultez Versions d’Azure HDInsight. Ubuntu 18.04 ne sera pas pris en charge pour HDInsight 3.6. Si vous souhaitez utiliser Ubuntu 18.04, vous devez migrer vos clusters vers HDInsight 4.0.
Vous devez supprimer et recréer vos clusters si vous souhaitez déplacer les clusters existants vers Ubuntu 18.04. Prévoyez de créer ou de recréer votre cluster une fois que la prise en charge d’Ubuntu 18.04 devient disponible. Nous enverrons une autre notification une fois que la nouvelle image sera disponible dans toutes les régions.
Il est fortement recommandé de tester à l’avance vos actions de script et vos applications personnalisées déployées sur les nœuds de périphérie sur une machine virtuelle Ubuntu 18.04. Vous pouvez créer une machine virtuelle Ubuntu Linux sur 18.04-LTS, puis créer et utiliser une paire de clés SSH (Secure Shell) sur votre machine virtuelle pour exécuter et tester vos actions de script et vos applications personnalisées déployées sur les nœuds de périphérie.
Désactiver la taille de machine virtuelle Standard_A5 comme nœud principal pour HDInsight 4.0
Le nœud principal de cluster HDInsight est chargé de l’initialisation et de la gestion du cluster. La taille de machine virtuelle Standard_A5 présente des problèmes de fiabilité en tant que nœud principal pour HDInsight 4.0. À compter de la prochaine version de mai 2021, les clients ne pourront pas créer de clusters avec la taille de machine virtuelle Standard_A5 comme nœud principal. Vous pouvez utiliser d’autres machines virtuelles à 2 cœurs comme E2_v3 ou E2s_v3. Les clusters existants fonctionneront tels quels. Une machine virtuelle à 4 cœurs est fortement recommandée pour le nœud principal, afin de garantir la haute disponibilité et la fiabilité des clusters HDInsight de production.
Résolution des bogues
HDInsight continue à améliorer la fiabilité et les performances des clusters.
Changement de la version des composants
Ajout de la prise en charge de Spark 3.0.0 et Kafka 2.4.1 comme version préliminaire. Les versions actuelles des composants pour HDInsight 4.0 et HDInsight 3.6 sont indiquées dans ce document.
Date de publication : 05/02/2021
Cette version s’applique à la fois à HDInsight 3.6 et HDInsight 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Nouvelles fonctionnalités
Prise en charge de la série Dav4
HDInsight a ajouté la prise en charge de la série Dav4 dans cette version. En savoir plus sur la série Dav4.
Disponibilité générale du proxy REST Kafka
Le proxy REST Kafka vous permet d’interagir avec votre cluster Kafka via une API REST sur HTTPS. Le proxy REST Kafka est en disponibilité générale à partir de cette version. En savoir plus sur le proxy REST Kafka.
Passage à des groupes de machines virtuelles identiques Azure
HDInsight utilise désormais les machines virtuelles Azure pour approvisionner le cluster. Le service migre progressivement vers les groupes de machines virtuelles identiques Azure. L’ensemble du processus peut prendre plusieurs mois. Une fois les régions et les abonnements migrés, les clusters HDInsight nouvellement créés s’exécuteront sur des groupes de machines virtuelles identiques sans l’intervention du client. Aucun changement cassant n’est prévu.
Dépréciation
Tailles de machine virtuelle désactivées
À compter du 9 janvier 2021, HDInsight bloquera tous les clients qui créent des clusters en utilisant les tailles de machine virtuelle standard_A8, standard_A9, standard_A10 et standard_A11. Les clusters existants fonctionneront tels quels. Envisagez de migrer vers HDInsight 4.0 pour éviter une éventuelle interruption du système ou du support.
Changements de comportement
Remplacement des tailles de machine virtuelle du cluster par défaut par la série Ev3
Les tailles de machine virtuelle du cluster par défaut seront modifiées de la série D à la série Ev3. Cette modification s’applique aux nœuds principaux et aux nœuds Worker. Pour éviter que cette modification n’ait une incidence sur vos workflows déjà testés, spécifiez les tailles de machine virtuelle que vous souhaitez utiliser dans le modèle ARM.
Ressource d’interface réseau non visible pour les clusters s’exécutant sur des groupes de machines virtuelles identiques Azure
HDInsight migre progressivement vers les groupes de machines virtuelles identiques Azure. Les interfaces réseau des machines virtuelles ne sont plus visibles par les clients pour les clusters qui utilisent des groupes de machines virtuelles identiques Azure.
Changements à venir
Les changements suivants se produiront dans les prochaines versions.
La version de cluster par défaut sera remplacée par la version 4.0
À partir de février 2021, la version par défaut du cluster HDInsight passera de la version 3.6 à 4.0. Pour plus d’informations sur les versions disponibles, consultez Versions disponibles. En savoir plus sur les nouveautés de HDInsight 4.0.
Mise à niveau de la version du système d’exploitation
HDInsight met à niveau la version du système d’exploitation d’Ubuntu 16.04 à 18.04. La mise à niveau sera terminée avant avril 2021.
Fin de la prise en charge de HDInsight 3.6 le 30 juin 2021
HDInsight 3.6 ne sera plus pris en charge. À partir du 30 juin 2021, les clients ne pourront plus créer de nouveaux clusters HDInsight 3.6. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Envisagez de migrer vers HDInsight 4.0 pour éviter une éventuelle interruption du système ou du support.
Changement de la version des composants
Aucune modification de la version des composants pour cette version. Les versions actuelles des composants pour HDInsight 4.0 et HDInsight 3.6 sont indiquées dans ce document.
Date de publication : 18/11/2020
Cette version s’applique à la fois à HDInsight 3.6 et HDInsight 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Nouvelles fonctionnalités
Rotation automatique des clés pour le chiffrement à clé géré par le client au repos
À partir de cette version, les clients peuvent utiliser des URL de clé de chiffrement sans version Azure Key Vault pour le chiffrement à clé géré par le client au repos. HDInsight fait automatiquement pivoter les clés à mesure qu’elles expirent ou sont remplacées par les nouvelles versions. Vous trouverez plus de détails ici.
Possibilité de sélectionner différentes tailles de machine virtuelle Zookeeper pour les services Spark, Hadoop et ML
HDInsight ne prenait auparavant pas en charge la personnalisation de la taille de nœud Zookeeper pour les types de cluster des services Spark, Hadoop et ML. Les tailles de machine virtuelle sont définies par défaut sur A2_v2/A2, qui sont fournies sans frais. À partir de cette version, vous pourrez sélectionner la taille de machine virtuelle Zookeeper la plus appropriée pour votre scénario. Les nœuds Zookeeper avec une taille de machine virtuelle différente de A2_v2/A2 sont facturés. Les machines virtuelles A2_v2 et A2 sont toujours fournies sans frais.
Passage à des groupes de machines virtuelles identiques Azure
HDInsight utilise désormais les machines virtuelles Azure pour approvisionner le cluster. À compter de cette version, le service migrera progressivement vers des groupes de machines virtuelles identiques Azure. L’ensemble du processus peut prendre plusieurs mois. Une fois les régions et les abonnements migrés, les clusters HDInsight nouvellement créés s’exécuteront sur des groupes de machines virtuelles identiques sans l’intervention du client. Aucun changement cassant n’est prévu.
Dépréciation
Dépréciation du cluster ML Services HDInsight 3.6
Le type de cluster ML Services HDInsight 3.6 ne sera plus pris en charge au 31 décembre 2020. Après cette date, les clients ne pourront plus créer de cluster ML Services 3.6. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Vérifiez l’expiration de la prise en charge des versions HDInsight et des types de cluster ici.
Tailles de machine virtuelle désactivées
À compter du 16 novembre 2020, HDInsight bloquera les nouveaux clients qui créent des clusters en utilisant les tailles de machine virtuelle standard_A8, standard_A9, standard_A10 et standard_A11. Les clients existants qui ont utilisé ces tailles de machine virtuelle au cours des trois derniers mois ne seront pas concernés. À compter du 9 janvier 2021, HDInsight bloquera tous les clients qui créent des clusters en utilisant les tailles de machine virtuelle standard_A8, standard_A9, standard_A10 et standard_A11. Les clusters existants fonctionneront tels quels. Envisagez de migrer vers HDInsight 4.0 pour éviter une éventuelle interruption du système ou du support.
Changements de comportement
Ajout la vérification de la règle NSG avant l'opération de mise à l'échelle
HDInsight a ajouté la vérification des groupes de sécurité réseau (NSG) et des itinéraires définis par l'utilisateur (UDR) à l'opération de mise à l'échelle. La même validation intervient pour la mise à l'échelle des clusters en plus de leur création. Cette validation permet d'éviter les erreurs imprévisibles. Si la validation échoue, la mise à l'échelle échoue également. Pour en savoir plus sur la configuration des NSG et des UDR, reportez-vous à la section Adresses IP de gestion HDInsight.
Changement de la version des composants
Aucune modification de la version des composants pour cette version. Les versions actuelles des composants pour HDInsight 4.0 et HDInsight 3.6 sont indiquées dans ce document.
Date de publication : 09/11/2020
Cette version s’applique à la fois à HDInsight 3.6 et HDInsight 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Nouvelles fonctionnalités
HDInsight Identity Broker (HIB) est désormais en disponibilité générale
HDInsight Identity Broker (HIB) qui active l’authentification OAuth pour les clusters ESP est désormais en mis à la disposition générale avec cette version. Les clusters HIB créés après cette version seront dotés des fonctionnalités HIB les plus récentes :
- Haute disponibilité (HA)
- Prise en charge de l’authentification multifacteur (MFA)
- Les utilisateurs fédérés se connectent à AAD-DS sans synchronisation de hachage de mot de passe. Pour plus d’informations, consultez la documentation HIB.
Passage à des groupes de machines virtuelles identiques Azure
HDInsight utilise désormais les machines virtuelles Azure pour approvisionner le cluster. À compter de cette version, le service migrera progressivement vers des groupes de machines virtuelles identiques Azure. L’ensemble du processus peut prendre plusieurs mois. Une fois les régions et les abonnements migrés, les clusters HDInsight nouvellement créés s’exécuteront sur des groupes de machines virtuelles identiques sans l’intervention du client. Aucun changement cassant n’est prévu.
Dépréciation
Dépréciation du cluster ML Services HDInsight 3.6
Le type de cluster ML Services HDInsight 3.6 ne sera plus pris en charge au 31 décembre 2020. Après cette date, les clients ne devront plus créer de cluster ML Services 3.6. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Vérifiez l’expiration de la prise en charge des versions HDInsight et des types de cluster ici.
Tailles de machine virtuelle désactivées
À compter du 16 novembre 2020, HDInsight bloquera les nouveaux clients qui créent des clusters en utilisant les tailles de machine virtuelle standard_A8, standard_A9, standard_A10 et standard_A11. Les clients existants qui ont utilisé ces tailles de machine virtuelle au cours des trois derniers mois ne seront pas concernés. À compter du 9 janvier 2021, HDInsight bloquera tous les clients qui créent des clusters en utilisant les tailles de machine virtuelle standard_A8, standard_A9, standard_A10 et standard_A11. Les clusters existants fonctionneront tels quels. Envisagez de migrer vers HDInsight 4.0 pour éviter une éventuelle interruption du système ou du support.
Changements de comportement
Cette version n’est associée à aucun changement de comportement.
Changements à venir
Les changements suivants se produiront dans les prochaines versions.
Possibilité de sélectionner différentes tailles de machine virtuelle Zookeeper pour les services Spark, Hadoop et ML
HDInsight ne prend actuellement pas en charge la personnalisation de la taille de nœud Zookeeper pour les types de cluster des services Spark, Hadoop et ML. Les tailles de machine virtuelle sont définies par défaut sur A2_v2/A2, qui sont fournies sans frais. Dans la version à venir, vous pourrez sélectionner la taille de machine virtuelle Zookeeper la plus appropriée pour votre scénario. Les nœuds Zookeeper avec une taille de machine virtuelle différente de A2_v2/A2 sont facturés. Les machines virtuelles A2_v2 et A2 sont toujours fournies sans frais.
La version de cluster par défaut sera remplacée par la version 4.0
À partir de février 2021, la version par défaut du cluster HDInsight passera de la version 3.6 à 4.0. Pour plus d’informations sur les versions disponibles, consultez Versions prises en charge. En savoir plus sur les nouveautés de HDInsight 4.0.
Fin de la prise en charge de HDInsight 3.6 le 30 juin 2021
HDInsight 3.6 ne sera plus pris en charge. À partir du 30 juin 2021, les clients ne pourront plus créer de nouveaux clusters HDInsight 3.6. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Envisagez de migrer vers HDInsight 4.0 pour éviter une éventuelle interruption du système ou du support.
Résolution des bogues
HDInsight continue à améliorer la fiabilité et les performances des clusters.
Correction du problème de redémarrage des machines virtuelles dans le cluster
Le problème de redémarrage des machines virtuelles dans le cluster a été corrigé, vous pouvez de nouveau utiliser PowerShell ou l’API REST pour redémarrer les nœuds dans le cluster.
Changement de la version des composants
Aucune modification de la version des composants pour cette version. Les versions actuelles des composants pour HDInsight 4.0 et HDInsight 3.6 sont indiquées dans ce document.
Date de publication : 08/10/2020
Cette version s’applique à la fois à HDInsight 3.6 et HDInsight 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Nouvelles fonctionnalités
Clusters privés HDInsight sans adresse IP publique ni Private Link (aperçu)
HDInsight prend désormais en charge la création de clusters sans adresse IP publique ni accès Private Link aux clusters en préversion. Les clients peuvent utiliser les nouveaux paramètres avancés de mise en réseau pour créer un cluster entièrement isolé sans adresse IP publique et utiliser leurs propres points de terminaison privés pour accéder au cluster.
Passage à des groupes de machines virtuelles identiques Azure
HDInsight utilise désormais les machines virtuelles Azure pour approvisionner le cluster. À compter de cette version, le service migrera progressivement vers des groupes de machines virtuelles identiques Azure. L’ensemble du processus peut prendre plusieurs mois. Une fois les régions et les abonnements migrés, les clusters HDInsight nouvellement créés s’exécuteront sur des groupes de machines virtuelles identiques sans l’intervention du client. Aucun changement cassant n’est prévu.
Dépréciation
Dépréciation du cluster ML Services HDInsight 3.6
Le type de cluster ML Services HDInsight 3.6 ne sera plus pris en charge au 31 décembre 2020. Après cette date, les clients ne devront plus créer de cluster ML Services 3.6. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Vérifiez l’expiration de la prise en charge des versions HDInsight et des types de cluster ici.
Changements de comportement
Cette version n’est associée à aucun changement de comportement.
Changements à venir
Les changements suivants se produiront dans les prochaines versions.
Possibilité de sélectionner différentes tailles de machine virtuelle Zookeeper pour les services Spark, Hadoop et ML
HDInsight ne prend actuellement pas en charge la personnalisation de la taille de nœud Zookeeper pour les types de cluster des services Spark, Hadoop et ML. Les tailles de machine virtuelle sont définies par défaut sur A2_v2/A2, qui sont fournies sans frais. Dans la version à venir, vous pourrez sélectionner la taille de machine virtuelle Zookeeper la plus appropriée pour votre scénario. Les nœuds Zookeeper avec une taille de machine virtuelle différente de A2_v2/A2 sont facturés. Les machines virtuelles A2_v2 et A2 sont toujours fournies sans frais.
Résolution des bogues
HDInsight continue à améliorer la fiabilité et les performances des clusters.
Changement de la version des composants
Aucune modification de la version des composants pour cette version. Les versions actuelles des composants pour HDInsight 4.0 et HDInsight 3.6 sont indiquées dans ce document.
Date de publication : 28/9/2020
Cette version s’applique à la fois à HDInsight 3.6 et HDInsight 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Nouvelles fonctionnalités
La mise à l’échelle automatique pour Interactive Query avec HDInsight 4.0 est désormais en disponibilité générale
La mise à l’échelle automatique pour le type de cluster Interactive Query est désormais en disponibilité générale (GA) pour HDInsight 4.0. Tous les clusters Interactive Query 4.0 créés après le 27 août 2020 offriront une prise charge en disponibilité générale de la mise à l’échelle automatique.
Le cluster HBase prend en charge ADLS Gen2 Premium
HDInsight prend désormais en charge ADLS Gen2 Premium comme compte de stockage principal pour les clusters HDInsight HBase 3.6 et 4.0. Avec Écritures accélérées, vous pouvez bénéficier d’un meilleur niveau de performance pour vos clusters HBase.
Distribution de partitions Kafka dans les domaines d’erreur Azure
Un domaine d’erreur est un regroupement logique de matériel sous-jacent dans un datacenter Azure. Chaque domaine d’erreur partage une source d’alimentation et un commutateur réseau communs. Avant HDInsight, Kafka peut stocker tous les réplicas de partitions dans le même domaine d’erreur. À compter de cette version, HDInsight prend en charge la distribution automatique des partitions Kafka en fonction des domaines d’erreur Azure.
Chiffrement en transit
Les clients peuvent activer le chiffrement en transit entre des nœuds de cluster en utilisant le chiffrement IPsec avec des clés gérées par la plateforme. Cette option peut être activée au moment de créer le cluster. Découvrez de façon plus détaillée comment activer le chiffrement en transit.
Chiffrement sur l’hôte
Quand vous activez le chiffrement au niveau de l’hôte, les données stockées sur l’hôte de machine virtuelle sont chiffrées au repos et cheminent chiffrées jusqu’au service de stockage. À compter de cette version, vous pouvez activer le chiffrement au niveau de l’hôte sur le disque de données temporaire au moment de créer le cluster. Le chiffrement au niveau de l’hôte est uniquement pris en charge par certaines références SKU de machines virtuelles dans des régions limitées. HDInsight prend en charge les configurations de nœud et les références SKU suivantes. Découvrez de façon plus détaillée comment activer le chiffrement au niveau de l’hôte.
Passage à des groupes de machines virtuelles identiques Azure
HDInsight utilise désormais les machines virtuelles Azure pour approvisionner le cluster. À compter de cette version, le service migrera progressivement vers des groupes de machines virtuelles identiques Azure. L’ensemble du processus peut prendre plusieurs mois. Une fois les régions et les abonnements migrés, les clusters HDInsight nouvellement créés s’exécuteront sur des groupes de machines virtuelles identiques sans l’intervention du client. Aucun changement cassant n’est prévu.
Dépréciation
Cette version ne fait l’objet d’aucune dépréciation.
Changements de comportement
Cette version n’est associée à aucun changement de comportement.
Changements à venir
Les changements suivants se produiront dans les prochaines versions.
Possibilité de sélectionner différentes références SKU Zookeeper pour les services Spark, Hadoop et ML
HDInsight ne prend actuellement pas en charge la modification de la référence SKU Zookeeper pour les types de cluster des services Spark, Hadoop et ML. Il utilise la référence SKU A2_v2/A2 pour les nœuds Zookeeper et ceux-ci ne sont pas facturés aux clients. Dans la prochaine version, les clients pourront si nécessaire modifier la référence SKU Zookeeper pour les services Spark, Hadoop et ML. Les nœuds Zookeeper avec une référence différente de A2_v2/A2 sont facturés. La référence SKU par défaut sera toujours A2_v2/A2 et gratuite.
Résolution des bogues
HDInsight continue à améliorer la fiabilité et les performances des clusters.
Changement de la version des composants
Aucune modification de la version des composants pour cette version. Les versions actuelles des composants pour HDInsight 4.0 et HDInsight 3.6 sont indiquées dans ce document.
Date de publication : 09/08/2020
Cette version s’applique uniquement à HDInsight 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Nouvelles fonctionnalités
Prise en charge de SparkCruise
SparkCruise est un système de réutilisation automatique de calcul pour Spark. Il sélectionne les sous-expressions communes à matérialiser en fonction de la charge de travail des requêtes passées. SparkCruise matérialise ces sous-expressions dans le cadre du traitement des requêtes, et la réutilisation du calcul est automatiquement appliquée en arrière-plan. Vous pouvez tirer parti de SparkCruise sans aucune modification du code Spark.
Prise en charge de la vue Hive pour HDInsight 4.0
La vue Apache Ambari Hive est conçue pour vous aider à créer, optimiser et exécuter des requêtes Hive à partir de votre navigateur web. La vue Hive est prise en charge en mode natif pour les clusters HDInsight 4.0 à compter de cette version. Elle ne s’applique pas aux clusters existants. Vous devez supprimer et recréer le cluster pour obtenir la vue Hive intégrée.
Prise en charge de la vue Tez pour HDInsight 4.0
La vue Apache Tez est utilisée pour suivre et déboguer l’exécution de la tâche Hive Tez. La vue Tez est prise en charge en mode natif pour HDInsight 4.0 à compter de cette version. Elle ne s’applique pas aux clusters existants. Vous devez supprimer et recréer le cluster pour obtenir la vue Tez intégrée.
Dépréciation
Dépréciation de Spark 2.1 et 2.2 dans le cluster Spark HDInsight 3.6
À compter du 1er juillet 2020, les clients ne peuvent pas créer de clusters Spark avec Spark 2.1 et 2.2 sur HDInsight 3.6. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Envisagez de migrer vers Spark 2.3 sur HDInsight 3.6 d’ici le 30 juin 2020 pour éviter une éventuelle interruption du système ou du support.
Dépréciation de Spark 2.3 dans le cluster Spark HDInsight 4.0
À compter du 1er juillet 2020, les clients ne peuvent pas créer de clusters Spark avec Spark 2.3 sur HDInsight 4.0. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Envisagez de migrer vers Spark 2.4 sur HDInsight 4.0 d’ici le 30 juin 2020 pour éviter une éventuelle interruption du système ou du support.
Désapprobation de Kafka 1.1 dans le cluster Kafka HDInsight 4.0
À compter du 1er juillet 2020, les clients ne pourront pas créer de clusters Kafka avec Kafka 1.1 sur HDInsight 4.0. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Envisagez de migrer vers Kafka 2.1 sur HDInsight 4.0 d’ici le 30 juin 2020 pour éviter une éventuelle interruption du système ou du support.
Changements de comportement
Modification de la version de la pile Ambari
À partir de cette mise en production, la version d’Ambari passe de 2.x.x.x à 4.1. Vous pouvez vérifier la version de la pile (HDInsight 4,1) dans Ambari : Ambari > Utilisateur > Versions.
Changements à venir
Aucun changement cassant à venir auquel vous devez prêter attention.
Résolution des bogues
HDInsight continue à améliorer la fiabilité et les performances des clusters.
Les JIRA ci-dessous sont portés pour Hive :
Les JIRA ci-dessous sont portés pour HBase :
Changement de la version des composants
Aucune modification de la version des composants pour cette version. Les versions actuelles des composants pour HDInsight 4.0 et HDInsight 3.6 sont indiquées dans ce document.
Problèmes connus
Un problème a été résolu dans le portail Azure, en raison duquel les utilisateurs rencontraient une erreur en créant un cluster Azure HDInsight à l’aide d’un type d’authentification SSH de clé publique. Quand un utilisateur cliquait sur Vérifier + créer, il recevait l’erreur « Ne doit pas avoir trois caractères consécutifs du nom d’utilisateur SSH ». Ce problème a été résolu, mais vous devrez peut-être actualiser le cache de votre navigateur en appuyant sur Ctrl+F5 pour charger la vue corrigée. La solution de contournement à ce problème a consisté à créer un cluster avec un modèle ARM.
Date de publication : 13/07/2020
Cette version s’applique à la fois à HDInsight 3.6 et 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Nouvelles fonctionnalités
Support pour Customer Lockbox pour Microsoft Azure
Azure HDInsight prend maintenant en charge Azure Customer Lockbox. Il offre une interface permettant aux clients de passer en revue et d'approuver ou de rejeter les demandes d'accès aux données des clients. Il est utilisé lorsqu’un ingénieur Microsoft doit accéder aux données client dans le cadre d’une demande de support. Pour plus d’informations, consultez Customer Lockbox pour Microsoft Azure.
Stratégies de points de terminaison de service pour le stockage
Les clients peuvent maintenant utiliser des stratégies de point de terminaison de service sur le sous-réseau de cluster HDInsight. En savoir plus sur la stratégie de point de terminaison de service Azure.
Dépréciation
Dépréciation de Spark 2.1 et 2.2 dans le cluster Spark HDInsight 3.6
À compter du 1er juillet 2020, les clients ne peuvent pas créer de clusters Spark avec Spark 2.1 et 2.2 sur HDInsight 3.6. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Envisagez de migrer vers Spark 2.3 sur HDInsight 3.6 d’ici le 30 juin 2020 pour éviter une éventuelle interruption du système ou du support.
Dépréciation de Spark 2.3 dans le cluster Spark HDInsight 4.0
À compter du 1er juillet 2020, les clients ne peuvent pas créer de clusters Spark avec Spark 2.3 sur HDInsight 4.0. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Envisagez de migrer vers Spark 2.4 sur HDInsight 4.0 d’ici le 30 juin 2020 pour éviter une éventuelle interruption du système ou du support.
Désapprobation de Kafka 1.1 dans le cluster Kafka HDInsight 4.0
À compter du 1er juillet 2020, les clients ne pourront pas créer de clusters Kafka avec Kafka 1.1 sur HDInsight 4.0. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Envisagez de migrer vers Kafka 2.1 sur HDInsight 4.0 d’ici le 30 juin 2020 pour éviter une éventuelle interruption du système ou du support.
Changements de comportement
Aucun changement de comportement auquel vous devez être attentif.
Changements à venir
Les changements suivants se produiront dans les prochaines versions.
Possibilité de sélectionner différentes références SKU Zookeeper pour les services Spark, Hadoop et ML
HDInsight ne prend actuellement pas en charge la modification de la référence SKU Zookeeper pour les types de cluster des services Spark, Hadoop et ML. Il utilise la référence SKU A2_v2/A2 pour les nœuds Zookeeper et ceux-ci ne sont pas facturés aux clients. Dans la prochaine version, les clients pourront modifier la référence SKU Zookeeper pour les services Spark, Hadoop et ML en fonction des besoins. Les nœuds Zookeeper avec une référence différente de A2_v2/A2 sont facturés. La référence SKU par défaut sera toujours A2_v2/A2 et gratuite.
Résolution des bogues
HDInsight continue à améliorer la fiabilité et les performances des clusters.
Résolution du problème lié à Hive Warehouse Connector
Un problème de convivialité du connecteur Hive Warehouse se posait dans la version précédente. Ce problème est à présent résolu.
Résolution du problème de zéros non significatifs tronqués par le notebook Zeppelin
Zeppelin tronquait de manière incorrecte les zéros non significatifs dans la sortie de tableau pour le format de chaîne. Nou savons résolu ce problème dans cette version.
Changement de la version des composants
Aucune modification de la version des composants pour cette version. Les versions actuelles des composants pour HDInsight 4.0 et HDInsight 3.6 sont indiquées dans ce document.
Date de publication : 06/11/2020
Cette version s’applique à la fois à HDInsight 3.6 et 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Nouvelles fonctionnalités
Passage à des groupes de machines virtuelles identiques Azure
HDInsight utilise des machines virtuelles Azure pour provisionner le cluster maintenant. À partir de cette version release, les clusters HDInsight nouvellement créés commencent à utiliser le groupe de machines virtuelles identiques Azure. Le changement est déployé progressivement. Vous ne devez pas vous attendre à des changements cassants. En savoir plus sur les groupes de machines virtuelles identiques Azure.
Redémarrer des machines virtuelles dans le cluster HDInsight
Dans cette version release, nous prenons en charge le redémarrage des machines virtuelles dans le cluster HDInsight pour redémarrer les nœuds qui ne répondent pas. Actuellement, vous ne pouvez le faire que par le biais de l’API. La prise en charge de PowerShell et de l’interface CLI est en cours. Pour plus d’informations sur l’API, consultez ce document.
Dépréciation
Dépréciation de Spark 2.1 et 2.2 dans le cluster Spark HDInsight 3.6
À compter du 1er juillet 2020, les clients ne peuvent pas créer de clusters Spark avec Spark 2.1 et 2.2 sur HDInsight 3.6. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Envisagez de migrer vers Spark 2.3 sur HDInsight 3.6 d’ici le 30 juin 2020 pour éviter une éventuelle interruption du système ou du support.
Dépréciation de Spark 2.3 dans le cluster Spark HDInsight 4.0
À compter du 1er juillet 2020, les clients ne peuvent pas créer de clusters Spark avec Spark 2.3 sur HDInsight 4.0. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Envisagez de migrer vers Spark 2.4 sur HDInsight 4.0 d’ici le 30 juin 2020 pour éviter une éventuelle interruption du système ou du support.
Désapprobation de Kafka 1.1 dans le cluster Kafka HDInsight 4.0
À compter du 1er juillet 2020, les clients ne pourront pas créer de clusters Kafka avec Kafka 1.1 sur HDInsight 4.0. Les clusters existants s’exécuteront tels quels sans le support de Microsoft. Envisagez de migrer vers Kafka 2.1 sur HDInsight 4.0 d’ici le 30 juin 2020 pour éviter une éventuelle interruption du système ou du support.
Changements de comportement
Changement de la taille du nœud principal de cluster ESP Spark
La taille de nœud principal minimale autorisée pour le cluster ESP Spark est remplacée par la taille Standard_D13_V2. Les machines virtuelles ayant peu de cœurs et de mémoire comme nœud principal peuvent entraîner des problèmes de cluster ESP en raison d’une capacité de mémoire et de processeur relativement faible. À partir de la version release, utilisez des références SKU supérieures à Standard_D13_V2 et Standard_E16_V3 comme nœud principal pour les clusters ESP Spark.
Une machine virtuelle à au moins quatre cœurs est nécessaire pour le nœud principal
Une machine virtuelle à au moins 4 cœurs est nécessaire pour le nœud principal, afin de garantir la haute disponibilité et la fiabilité des clusters HDInsight. À compter du 6 avril 2020, les clients peuvent uniquement choisir des machines virtuelles à quatre cœurs ou plus comme nœud principal pour les nouveaux clusters HDInsight. Les clusters existants continueront à s’exécuter comme prévu.
Changement du provisionnement du nœud Worker du cluster
Quand 80 % des nœuds Worker sont prêts, le cluster entre dans la phase opérationnelle. Dans cette phase, les clients peuvent effectuer toutes les opérations de plan de données, comme l’exécution de scripts et de travaux. Toutefois, les clients ne peuvent effectuer aucune opération de plan de contrôle comme un scale-up/scale-down. Seule la suppression est prise en charge.
Après la phase opérationnelle, le cluster attend encore 60 minutes pour les 20 % de nœuds Worker restants. À la fin de cette période de 60 minutes, le cluster passe à la phase en cours d’exécution, même si tous les nœuds Worker ne sont toujours pas disponibles. Une fois qu’un cluster entre dans la phase en cours d’exécution, vous pouvez l’utiliser normalement. Les opérations de plan de contrôle comme un scale-up/scale-down aussi bien que les opérations de plan de données comme l’exécution de scripts et de travaux sont acceptées. Si certains des nœuds Worker demandés ne sont pas disponibles, le cluster est marqué comme ayant partiellement réussi. Les nœuds qui ont été correctement déployés vous sont facturés.
Créer un principal du service avec HDInsight
Auparavant, avec la création de cluster, les clients pouvaient créer un principal de service pour accéder au compte ADLS Gen 1 connecté dans le portail Azure. À compter du 15 juin 2020, la création de nouveaux principaux de service n’est plus possible dans le workflow de création de HDInsight, seul un principal de service existant est pris en charge. Consultez Créer un principal de service et des certificats à l’aide d’Azure Active Directory.
Délai d’attente pour les actions de script avec création de cluster
HDInsight prend en charge l’exécution d’actions de script avec création de cluster. À partir de cette version, toutes les actions de script avec création de cluster doivent se terminer dans un délai de 60 minutes, faute de quoi elles expirent. Les actions de script soumises à des clusters en cours d’exécution ne sont pas impactées. Vous trouverez plus de détails ici.
Changements à venir
Aucun changement cassant à venir auquel vous devez prêter attention.
Résolution des bogues
HDInsight continue à améliorer la fiabilité et les performances des clusters.
Changement de la version des composants
HBase 2.0 vers 2.1.6
La version de HBase est mise à niveau de la version 2.0 vers la version 2.1.6.
Spark 2.4.0 vers 2.4.4
La version de Spark est mise à niveau de la version 2.4.0 vers la version 2.4.4.
Kafka 2.1.0 vers 2.1.1
La version de Kafka est mise à niveau de la version 2.1.0 vers la version 2.1.1.
Les versions actuelles des composants pour HDInsight 4.0 et HDInsight 3.6 sont indiquées dans ce document.
Problèmes connus
Problème lié à Hive Warehouse Connector
Il y a un problème concernant Hive Warehouse Connector dans cette version. Le correctif sera inclus dans la prochaine version. Les clusters existants créés avant cette version ne sont pas impactés. Si possible, évitez de supprimer et de recréer le cluster. Si vous avez besoin d’aide supplémentaire à ce sujet, ouvrez un ticket de support.
Date de publication : 09/01/2020
Cette version s’applique à la fois à HDInsight 3.6 et 4.0. La version HDInsight est mise à disposition dans toutes les régions sur plusieurs jours. La date de publication mentionnée ici indique la date de publication dans la première région. Si vous ne voyez pas les changements suivants, attendez quelques jours que la version soit active dans votre région.
Nouvelles fonctionnalités
Application de TLS 1.2
TLS (Transport Layer Security) et SSL (Secure Sockets Layer) sont des protocoles de chiffrement qui permettent la sécurité des communications sur un réseau d’ordinateurs. Apprenez-en davantage sur TLS. HDInsight utilise TLS 1.2 sur les points de terminaison HTTPS publics, mais TLS 1.1 est toujours pris en charge à des fins de compatibilité descendante.
Avec cette version, les clients peuvent choisir TLS 1.2 uniquement pour toutes les connexions qui passent par le point de terminaison de cluster public. Pour prendre cela en charge, vous pouvez spécifier la nouvelle propriété minSupportedTlsVersion lors de la création du cluster. Si cette propriété n’est pas définie, le cluster prend toujours en charge TLS 1.0, 1.1 et 1.2, ce qui est identique au comportement actuel. Les clients peuvent affecter la valeur « 1.2 » à cette propriété, ce qui signifie que le cluster ne prend en charge que TLS 1.2 et versions ultérieures. Pour plus d’informations, consultez TLS.
BYOK (Bring Your Own Key) pour le chiffrement de disque
Tous les disques managés dans HDInsight sont protégés par Azure Storage Service Encryption (SSE). Par défaut, les données stockées sur ces disques sont chiffrées à l’aide de clés managées par Microsoft. À compter de cette version, vous pouvez utiliser votre propre clé (BYOK, Bring Your Own Key) pour le chiffrement de disque et effectuer la gestion à l’aide d’Azure Key Vault. Le chiffrement BYOK est une configuration en une étape qui a lieu lors de la création d’un cluster, sans coût supplémentaire. Il vous suffit d’inscrire HDInsight comme identité managée auprès d’Azure Key Vault et d’ajouter la clé de chiffrement pendant la création du cluster. Pour plus d’informations, consultez Chiffrement de disque avec clé gérée par le client.
Dépréciation
Cette version ne fait pas l’objet d’une dépréciation. Pour vous préparer aux dépréciations à venir, consultez Modifications à venir.
Changements de comportement
Cette version n’est associée à aucun changement de comportement. Pour vous préparer aux changements à venir, consultez Changements à venir.
Changements à venir
Les changements suivants se produiront dans les prochaines versions.
Dépréciation de Spark 2.1 et 2.2 dans le cluster Spark HDInsight 3.6
À compter du 1er juillet 2020, les clients ne pourront pas créer de clusters Spark avec Spark 2.1 et 2.2 sur HDInsight 3.6. Les clusters existants s’exécuteront en l’état sans support de Microsoft. Effectuez la migration vers Spark 2.3 sur HDInsight 3.6 d’ici le 30 juin 2020 pour éviter une éventuelle interruption du système ou du support.
Dépréciation de Spark 2.3 dans le cluster Spark HDInsight 4.0
À compter du 1er juillet 2020, les clients ne pourront pas créer de clusters Spark avec Spark 2.3 sur HDInsight 4.0. Les clusters existants s’exécuteront en l’état sans support de Microsoft. Effectuez la migration vers Spark 2.4 sur HDInsight 4.0 d’ici le 30 juin 2020 pour éviter une éventuelle interruption du système ou du support.
Dépréciation de Kafka 1.1 dans le cluster Kafka HDInsight 4.0
À compter du 1er juillet 2020, les clients ne pourront pas créer de clusters Kafka avec Kafka 1.1 sur HDInsight 4.0. Les clusters existants s’exécuteront en l’état sans support de Microsoft. Envisagez de migrer vers Kafka 2.1 sur HDInsight 4.0 d’ici le 30 juin 2020 pour éviter une éventuelle interruption du système ou du support. Pour plus d’informations, consultez Migrer des charges de travail Apache Kafka vers Azure HDInsight 4.0.
HBase 2.0 vers 2.1.6
Dans la prochaine version de HDInsight 4.0, la version de HBase sera mise à niveau de la version 2.0 vers 2.1.6
Spark 2.4.0 vers 2.4.4
Dans la prochaine version de HDInsight 4.0, la version de Spark sera mise à niveau de la version 2.4.0 vers 2.4.4.
Kafka 2.1.0 vers 2.1.1
Dans la prochaine version de HDInsight 4.0, la version de Kafka sera mise à niveau de la version 2.1.0 vers 2.1.1.
Une machine virtuelle à au moins quatre cœurs est nécessaire pour le nœud principal
Une machine virtuelle à au moins 4 cœurs est nécessaire pour le nœud principal, afin de garantir la haute disponibilité et la fiabilité des clusters HDInsight. À compter du 6 avril 2020, les clients peuvent uniquement choisir des machines virtuelles à quatre cœurs ou plus comme nœud principal pour les nouveaux clusters HDInsight. Les clusters existants continueront à s’exécuter comme prévu.
Modification de la taille du nœud de cluster ESP Spark
Dans la version à venir, la taille de nœud minimale autorisée pour le cluster ESP Spark sera remplacée par la taille Standard_D13_V2. Les machines virtuelles de la série A peuvent provoquer des problèmes liés au cluster ESP, en raison d’une capacité de mémoire et de processeur relativement faible. L’utilisation des machines virtuelles de la série A sera dépréciée pour la création de nouveaux clusters ESP.
Passage à des groupes de machines virtuelles identiques Azure
HDInsight utilise désormais les machines virtuelles Azure pour approvisionner le cluster. Dans la version à venir, HDInsight utilisera à la place des groupes de machines virtuelles identiques Azure. Apprenez-en davantage sur les groupes de machines virtuelles identiques Azure.
Résolution des bogues
HDInsight continue à améliorer la fiabilité et les performances des clusters.
Changement de la version des composants
Aucune modification de la version des composants pour cette version. Vous pouvez trouver les versions actuelles des composants pour HDInsight 4.0 et HDInsight 3.6 ici.
Date de publication : 17/12/2019
Cette version s’applique à la fois à HDInsight 3.6 et 4.0.
Nouvelles fonctionnalités
Balises de service
Les balises de service simplifient la sécurité des machines virtuelles Azure et des réseaux virtuels Azure en vous permettant de limiter facilement l’accès réseau aux services Azure. Vous pouvez utiliser des balises de service dans vos règles de groupe de sécurité réseau pour autoriser ou refuser le trafic vers un service Azure spécifique à l’échelle mondiale ou par région Azure. Azure fournit la maintenance des adresses IP sous-tendant chaque balise. Les balises de service HDInsight pour les groupes de sécurité réseau sont des groupes d’adresses IP pour les services d’intégrité et de gestion. Ces groupes permettent de réduire la complexité de la création de règles de sécurité. Les clients HDInsight peuvent activer l’étiquette de service via le portail Azure, PowerShell et l’API REST. Pour plus d’informations, consultez Étiquettes de service de groupe de sécurité réseau (NSG) pour Azure HDInsight.
Base de données Ambari personnalisée
HDInsight vous permet à présent d’utiliser votre propre base de données SQL pour Apache Ambari. Vous pouvez configurer cette instance Ambari DB personnalisée à partir du portail Azure ou par le biais du modèle Resource Manager. Cette fonctionnalité vous permet de choisir la base de données SQL adaptée à vos besoins en matière de traitement et de capacité. Vous pouvez également effectuer une mise à niveau facilement pour répondre aux besoins de croissance de l’entreprise. Pour plus d’informations, consultez Configurer des clusters HDInsight avec une base de données Ambari personnalisée.

Abandon
Cette version ne fait pas l’objet d’une dépréciation. Pour vous préparer aux dépréciations à venir, consultez Modifications à venir.
Changements de comportement
Cette version n’est associée à aucun changement de comportement. Pour vous préparer aux changements de comportement à venir, consultez Modifications à venir.
Changements à venir
Les changements suivants se produiront dans les prochaines versions.
Application de TLS (Transport Layer Security) 1.2
TLS (Transport Layer Security) et SSL (Secure Sockets Layer) sont des protocoles de chiffrement qui permettent la sécurité des communications sur un réseau d’ordinateurs. Pour plus d’informations, consultez TLS. Alors que les clusters Azure HDInsight acceptent les connexions TLS 1.2 sur les points de terminaison HTTPS publics, TLS 1.1 est toujours pris en charge pour la compatibilité descendante avec les clients plus anciens.
À partir de la prochaine version, vous serez en mesure d’activer et de configurer vos nouveaux clusters HDInsight pour qu’ils acceptent uniquement les connexions TLS 1.2.
Plus tard dans l’année, à compter du 30/06/2020, Azure HDInsight appliquera TLS 1.2 ou versions ultérieures pour toutes les connexions HTTPS. Nous vous recommandons de vous assurer que tous vos clients sont prêts à gérer TLS 1.2 ou versions ultérieures.
Passage à des groupes de machines virtuelles identiques Azure
HDInsight utilise désormais les machines virtuelles Azure pour approvisionner le cluster. À partir de février 2020 (la date sera précisée ultérieurement), HDInsight utilisera à la place les groupes de machines virtuelles identiques Azure. En savoir plus sur les groupes de machines virtuelles identiques Azure.
Modification de la taille du nœud de cluster ESP Spark
Dans la prochaine version :
- La taille de nœud minimale autorisée pour le cluster ESP Spark sera remplacée par la taille Standard_D13_V2.
- Les machines virtuelles de série A seront dépréciées pour la création de nouveaux clusters ESP, car elles peuvent provoquer des problèmes de cluster ESP en raison d’une capacité de processeur et de mémoire relativement faible.
HBase 2.0 à 2.1
Dans la prochaine version de HDInsight 4.0, la version de HBase sera mise à niveau de la version 2.0 à 2.1.
Résolution des bogues
HDInsight continue à améliorer la fiabilité et les performances des clusters.
Changement de la version des composants
Nous avons prolongé la prise en charge de HDInsight 3.6 jusqu’au 31 décembre 2020. Pour plus d’informations, consultez la page Versions HDInsight prises en charge.
Il n’y a aucune modification de la version des composants pour HDInsight 4.0.
Apache Zeppelin sur HDInsight 3.6 : 0.7.0-->0.7.3.
Vous pouvez trouver les versions les plus récentes des composants dans ce document.
Nouvelles régions
Émirats arabes unis Nord
Les adresses IP de gestion de la région Émirats arabes unis Nord sont les suivantes : 65.52.252.96 et 65.52.252.97.
Date de publication : 07/11/2019
Cette version s’applique à la fois à HDInsight 3.6 et 4.0.
Nouvelles fonctionnalités
HDInsight Identity Broker (HIB) (préversion)
HDInsight Identity Broker (HIB) permet aux utilisateurs de se connecter à Apache Ambari à l’aide de l’authentification multifacteur (MFA) et d’accéder aux tickets Kerberos requis sans avoir besoin de hachages de mot de passe dans Azure Active Directory Domain Services (AAD-DS). Actuellement, HIB est disponible uniquement pour les clusters déployés via un modèle Azure Resource Management (ARM).
Proxy d’API REST Kafka (préversion)
Le proxy d’API REST Kafka permet de déployer en un clic un proxy REST hautement disponible avec un cluster Kafka via une autorisation Azure AD sécurisée et le protocole OAuth.
Mise à l’échelle automatique
La mise à l’échelle automatique pour Azure HDInsight est désormais généralement disponible dans toutes les régions pour les types de cluster Apache Spark et Hadoop. Cette fonctionnalité permet de gérer les charges de travail d’analytique de Big Data Analytics de manière plus rentable et productive. Vous pouvez désormais optimiser l’utilisation de vos clusters HDInsight et payer uniquement ce dont vous avez besoin.
Selon vos besoins, vous pouvez choisir entre une mise à l’échelle automatique basée sur la charge et une mise à l’échelle automatique basée sur la planification. La mise à l’échelle automatique basée sur la charge permet d’augmenter ou de réduire la taille du cluster en fonction des besoins actuels en ressources, tandis que la mise à l’échelle automatique basée sur la planification permet de modifier la taille du cluster en fonction d’une planification prédéfinie.
La prise en charge de la mise à l’échelle automatique pour charge de travail HBase et LLAP est également disponible en préversion publique. Pour plus d’informations, consultez Mettre à l’échelle automatiquement les clusters Azure HDInsight.
Écritures accélérées pour Apache HBase dans HDInsight
La fonctionnalité Écritures accélérées utilise des disques managés SSD Premium Azure pour améliorer les performances du journal WAL (write-ahead log) Apache HBase. Pour plus d’informations, consultez Écritures accélérées pour Apache HBase dans Azure HDInsight.
Base de données Ambari personnalisée
HDInsight offre désormais une nouvelle capacité pour permettre aux clients d’utiliser leur propre base de données SQL pour Ambari. À présent, les clients peuvent choisir la base de données SQL appropriée pour Ambari et facilement la mettre à niveau en fonction de leurs propres besoins en croissance commerciale. Le déploiement est effectué avec un modèle Azure Resource Manager. Pour plus d’informations, consultez Configurer des clusters HDInsight avec une base de données Ambari personnalisée.
Les machines virtuelles de la série F sont désormais disponibles avec HDInsight
Les machines virtuelles de la série F peuvent être un bon choix pour prendre en main HDInsight avec des exigences de traitement légères. Affichant le coût le plus bas par heure, la série F offre le meilleur rapport prix-performances de la gamme Azure si l’on considère les unités de calcul Azure (ACU) par processeur virtuel. Pour plus d’informations, consultez Sélection de la taille de machine virtuelle adaptée à votre cluster Azure HDInsight.
Dépréciation
Dépréciation des machines virtuelles de la série G
À partir de cette version, les machines virtuelles de la série G ne sont plus proposées dans HDInsight.
Dépréciation des machines virtuelles Dv1
À partir de cette version, l’utilisation de machines virtuelles Dv1 avec HDInsight est déconseillée. Toute demande client concernant Dv1 sera traitée automatiquement avec Dv2. Il n’y a aucune différence de prix entre les machines virtuelles Dv1 et Dv2.
Changements de comportement
Modification de la taille du disque managé par le cluster
HDInsight fournit un espace disque managé avec le cluster. À partir de cette version, la taille du disque managé de chaque nœud dans le nouveau cluster créé est modifiée à 128 Go.
Changements à venir
Les changements suivants se produiront dans les prochaines versions.
Passage à des groupes de machines virtuelles identiques Azure
HDInsight utilise désormais les machines virtuelles Azure pour approvisionner le cluster. À partir de décembre, HDInsight utilisera à la place les groupes de machines virtuelles identiques Azure. En savoir plus sur les groupes de machines virtuelles identiques Azure.
HBase 2.0 à 2.1
Dans la prochaine version de HDInsight 4.0, la version de HBase sera mise à niveau de la version 2.0 à 2.1.
Dépréciation des machines virtuelles de la série A pour le cluster ESP
Les machines virtuelles de la série A peuvent provoquer des problèmes liés au cluster ESP en raison d’une capacité de mémoire et de l’UC relativement faible. Dans la prochaine version, l’utilisation des machines virtuelles de la série A sera déconseillée pour la création de nouveaux clusters ESP.
Résolution des bogues
HDInsight continue à améliorer la fiabilité et les performances des clusters.
Changement de la version des composants
Il n’y a aucune modification de la version des composants pour cette version. Vous pouvez trouver les versions actuelles des composants pour HDInsight 4.0 et HDInsight 3.6 ici.
Date de publication : 07/08/2019
Versions des composants
Les versions Apache officielles de tous les composants HDInsight 4.0 sont indiquées ci-dessous. Les versions des composants répertoriés sont les versions stables les plus récentes disponibles.
- Apache Ambari 2.7.1
- Apache Hadoop 3.1.1
- Apache HBase 2.0.0
- Apache Hive 3.1.0
- Apache Kafka 1.1.1, 2.1.0
- Apache Mahout 0.9.0+
- Apache Oozie 4.2.0
- Apache Phoenix 4.7.0
- Apache Pig 0.16.0
- Apache Ranger 0.7.0
- Apache Slider 0.92.0
- Apache Spark 2.3.1, 2.4.0
- Apache Sqoop 1.4.7
- Apache TEZ 0.9.1
- Apache Zeppelin 0.8.0
- Apache ZooKeeper 3.4.6
Les versions ultérieures des composants Apache sont parfois groupées dans la distribution de la plateforme HDP en plus des versions répertoriées ci-dessus. Dans ce cas, ces versions sont répertoriées dans le tableau des préversions techniques et ne doivent pas remplacer les versions des composants Apache de la liste ci-dessus dans un environnement de production.
Informations sur les correctifs Apache
Pour plus d’informations sur les correctifs disponibles dans HDInsight 4.0, consultez la liste des correctifs de chaque produit dans le tableau ci-dessous.
| Nom du produit | Informations sur les correctifs |
|---|---|
| Ambari | Informations sur les correctifs Ambari |
| Hadoop | Informations sur les correctifs Hadoop |
| hbase | Informations sur les correctifs HBase |
| Hive | Cette version fournit Hive 3.1.0 sans aucun autre correctif Apache. |
| Kafka | Cette version fournit Kafka 1.1.1 sans aucun autre correctif Apache. |
| Oozie | Informations sur les correctifs Oozie |
| Phoenix | Informations sur les correctifs Phoenix |
| Pig | Informations sur les correctifs Pig |
| Ranger | Informations sur les correctifs Ranger |
| Spark | Informations sur les correctifs Spark |
| Sqoop | Cette version fournit Sqoop 1.4.7 sans aucun correctif Apache supplémentaire. |
| Tez | Cette version fournit Tez 0.9.1 sans aucun autre correctif Apache. |
| Zeppelin | Cette version fournit Zeppelin 0.8.0 sans aucun autre correctif Apache. |
| Zookeeper | Informations sur les correctifs Zookeeper |
Failles et menaces courantes corrigées
Pour plus d’informations sur les problèmes de sécurité résolus dans cette version, consultez le document Fixed Common Vulnerabilities and Exposures for HDP 3.0.1 (Failles et menaces courantes corrigées pour HDP 3.0.1) sur la plateforme Hortonworks.
Problèmes connus
Réplication endommagée pour la base de données HBase sécurisée avec l’installation par défaut
Pour HDInsight 4.0, procédez comme suit :
Activez la communication entre les clusters.
Connectez-vous au nœud principal actif.
Téléchargez un script pour activer la réplication avec la commande suivante :
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shTapez la commande
sudo kinit <domainuser>.Tapez la commande suivante pour exécuter le script :
sudo bash hdi_enable_replication.sh -m <hn*> -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
Pour HDInsight 3.6
Connectez-vous à l’instance HMaster ZK active.
Téléchargez un script pour activer la réplication avec la commande suivante :
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shTapez la commande
sudo kinit -k -t /etc/security/keytabs/hbase.service.keytab hbase/<FQDN>@<DOMAIN>.Tapez la commande suivante :
sudo bash hdi_enable_replication.sh -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
Phoenix Sqlline cesse de fonctionner après la migration du cluster HBase vers HDInsight 4.0
Procédez comme suit :
- Supprimez les tables Phoenix suivantes :
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.MUTEXSYSTEM.CATALOG
- Si vous ne pouvez pas supprimer une table, redémarrez HBase pour effacer les connexions aux tables.
- Exécutez de nouveau
sqlline.py. Phoenix va recréer toutes les tables qui ont été supprimées à l’étape 1. - Régénérez les tables et les vues Phoenix des données HBase.
Phoenix Sqlline cesse de fonctionner après la réplication des métadonnées HBase Phoenix de HDInsight 3.6 à 4.0
Procédez comme suit :
- Avant de procéder à la réplication, accédez au cluster de destination 4.0 et exécutez
sqlline.py. Cette commande génère des tables Phoenix telles queSYSTEM.MUTEXetSYSTEM.LOGqui existent uniquement dans 4.0. - Supprimez les tables suivantes :
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.CATALOG
- Démarrez la réplication HBase.
Dépréciation
Apache Storm et les services ML ne sont pas disponibles dans HDInsight 4.0.
Date de publication : 14/04/2019
Nouvelles fonctionnalités
Les nouvelles mises à jour et fonctionnalités appartiennent aux catégories suivantes :
Mise à jour de Hadoop et d’autres projets open source – en plus des correctifs de bogues, qui se dénombrent à plus de 1000 dans plus 20 projets open source, cette mise à jour contient une nouvelle version de Spark (2.3) et Kafka (1.0).
Mise à jour de R Server 9.1 vers Machine Learning Services 9.3 – avec cette version, nous offrons aux scientifiques des données et aux ingénieurs le meilleur de l’open source qui bénéficie d’innovations algorithmiques et d’une grande facilité d’opérationnalisation, le tout disponible dans leur langage préféré avec la vitesse d’Apache Spark. Cette version étend les fonctionnalités offertes par R Server avec l’ajout de la prise en charge de Python, entraînant le remplacement du nom du cluster R Server par ML Services.
Prise en charge d’Azure Data Lake Storage Gen2 – HDInsight prendra en charge la préversion d’Azure Data Lake Storage Gen2. Dans les régions disponibles, les clients pourront choisir un compte ADLS Gen2 comme magasin principal ou secondaire pour leurs clusters HDInsight.
Mises à jour du Pack Sécurité Entreprise HDInsight (préversion) : (préversion) Les points de terminaison de service de réseau virtuel prennent en charge Stockage Blob Azure, ADLS Gen1, Azure Cosmos DB et Azure DB.
Versions des composants
Les versions Apache officielles de tous les composants HDInsight 3.6 sont répertoriées ci-dessous. Tous les composants répertoriés ici sont des versions Apache officielles des versions stables les plus récentes disponibles.
Apache Hadoop 2.7.3
Apache HBase 1.1.2
Apache Hive 1.2.1
Apache Hive 2.1.0
Apache Kafka 1.0.0
Apache Mahout 0.9.0+
Apache Oozie 4.2.0
Apache Phoenix 4.7.0
Apache Pig 0.16.0
Apache Ranger 0.7.0
Apache Slider 0.92.0
Apache Spark 2.2.0/2.3.0
Apache Sqoop 1.4.6
Apache Storm 1.1.0
Apache TEZ 0.7.0
Apache Zeppelin 0.7.3
Apache ZooKeeper 3.4.6
Les versions ultérieures de quelques composants Apache sont parfois groupées dans la distribution de la plateforme HDP en plus des versions répertoriées ci-dessus. Dans ce cas, ces versions sont répertoriées dans le tableau des préversions techniques et ne doivent pas remplacer les versions des composants Apache de la liste ci-dessus dans un environnement de production.
Informations sur les correctifs Apache
Hadoop
Cette version fournit Hadoop Common 2.7.3 et les correctifs Apache suivants :
HADOOP-13190 : Mention de LoadBalancingKMSClientProvider dans la documentation HA KMS.
HADOOP-13227 : AsyncCallHandler doit utiliser une architecture basée sur les événements pour gérer les appels asynchrones.
HADOOP-14104 : Le client doit toujours demander à NameNode le chemin du fournisseur KMS.
HADOOP-14799 : Mise à jour de nimbus-jose-jwt. vers 4.41.1.
HADOOP-14814 : Correction d’une modification d’API incompatible sur FsServerDefaults dans HADOOP-14104.
HADOOP-14903 : Ajout explicite de json-smart à pom.xml.
HADOOP-15042 : Azure PageBlobInputStream.skip() peut retourner une valeur négative quand numberOfPagesRemaining est égal à 0.
HADOOP-15255 : Prise en charge de la conversion des majuscules/minuscules pour les noms de groupe dans LdapGroupsMapping.
HADOOP-15265 : Exclusion explicite de json-smart de hadoop-auth pom.xml.
HDFS-7922 : ShortCircuitCachela fermeture ne libère pas ScheduledThreadPoolExecutors.
HDFS-8496 : l’appel de stopWriter() avec maintien du verrou FSDatasetImpl peut bloquer d’autres threads (cmccabe).
HDFS-10267 : « Synchronisation » supplémentaire sur FsDatasetImpl#recoverAppend et FsDatasetImpl#recoverClose.
HDFS-10489 : Dépréciation de dfs.encryption.key.provider.uri pour les zones de chiffrement HDFS.
HDFS-11384 : Ajout d’une option pour que l’équilibreur répartisse les appels getBlocks afin d’éviter le pic rpc.CallQueueLength de NameNode.
HDFS-11689 : La nouvelle exception levée par
DFSClient%isHDFSEncryptionEnableda interrompu le code Hivehacky.HDFS-11711 : Le nom de domaine ne doit pas supprimer le bloc sur l’exception « Trop de fichiers ouverts ».
HDFS-12347 : TestBalancerRPCDelay#testBalancerRPCDelay échoue fréquemment.
HDFS-12781 : Après l’arrêt de
Datanode, l’onglet InNamenodeUIDatanodelève un message d’avertissement.HDFS-13054 : Gestion de PathIsNotEmptyDirectoryException dans l’appel de suppression
DFSClient.HDFS-13120 : La diff de capture instantanée peut être endommagée après la concaténation.
YARN-3742 : YARN RM s’arrête si la création de
ZKClientarrive à expiration.YARN-6061 : Ajout d’UncaughtExceptionHandler pour les threads critiques dans RM.
YARN-7558 : La commande Journaux d’activité YARN ne peut pas obtenir de journaux d’activité pour les conteneurs en cours d’exécution si l’authentification de l’interface utilisateur est activée.
YARN-7697 : L’extraction des journaux d’activité pour l’application terminée échoue même si l’agrégation de journaux d’activité est finie.
HDP 2.6.4 a fourni Hadoop Common 2.7.3 et les correctifs Apache suivants :
HADOOP-13700 : suppression de l’exception
IOExceptionnon levée des signatures TrashPolicy#initialize et #getInstance.HADOOP-13709 : Possibilité de nettoyer les sous-processus engendrés par Shell à la fin du processus.
HADOOP-14059 : Faute de frappe dans le message d’erreur
s3arename(self, subdir).HADOOP-14542 : Ajout d’IOUtils.cleanupWithLogger qui accepte l’API de journalisation slf4j.
HDFS-9887 : Les délais d’expiration de socket WebHdfs doivent être configurables.
HDFS-9914 : Correction du délai d’expiration de connexion/lecture WebhDFS configurable.
MAPREDUCE-6698 : Augmentation du délai d’expiration sur TestUnnecessaryBlockingOnHist oryFileInfo.testTwoThreadsQueryingDifferentJobOfSameUser.
YARN-4550 : Certains tests dans TestContainerLanch échouent dans un environnement de paramètres régionaux qui n’est pas en anglais.
YARN-4717 : TestResourceLocalizationService.testPublicResourceInitializesLocalDiréchoue par intermittence en raison d’une IllegalArgumentException générée par le nettoyage.
YARN-5042 : Montage de /sys/fs/cgroup dans des conteneurs Docker en tant que montage en lecture seule.
YARN-5318 : correction d’un échec de test intermittent de TestRMAdminService#te stRefreshNodesResourceWithFileSystemBasedConfigurationProvider.
YARN-5641 : Le localisateur laisse des tarballs une fois le conteneur complet.
YARN-6004 : Refactorisation de TestResourceLocalizationService#testDownloadingResourcesOnContainer pour qu’il occupe moins de 150 lignes.
YARN-6078 : Les conteneurs sont bloqués en état de localisation.
YARN-6805 : NPE dans LinuxContainerExecutor en raison d’un code de sortie PrivilegedOperationException Null.
hbase
Cette version fournit HBase 1.1.2 et les correctifs Apache suivants.
HBASE-13376 : Améliorations apportées à un équilibreur de charge aléatoire.
HBASE-13716 : Arrêt de l’utilisation des FSConstants de Hadoop.
HBASE-13848 : Accès aux mots de passe SSL InfoServer via l’API de fournisseur d’informations d’identification.
HBASE-13947 : Utilisation de MasterServices au lieu de Server dans AssignmentManager.
HBASE-14135 : Rétroportage de sauvegarde/restauration Phase 3 : Fusion des images de sauvegarde.
HBASE-14473 : Calcul de la localité de région en parallèle.
HBASE-14517 : Montre la version de
regionserver'sdans la page d’état maître.HBASE-14606 : Les tests TestSecureLoadIncrementalHFiles ont expiré dans la génération de jonction sur apache.
HBASE-15210 : Annulation de la journalisation d’équilibreur de charge agressive à des dizaines de lignes par milliseconde.
HBASE-15515 : Amélioration de LocalityBasedCandidateGenerator dans l’équilibreur de charge.
HBASE-15615 : Durée de veille incorrecte quand une nouvelle tentative est nécessaire pour
RegionServerCallable.HBASE-16135 : PeerClusterZnode sous rs du pair supprimé peut ne jamais être supprimé.
HBASE-16570 : Calcul de la localité de région en parallèle au démarrage.
HBASE-16810 : L’équilibreur HBase lève ArrayIndexOutOfBoundsException quand des
regionserversse trouvent dans le znode /hbase/draining et sont déchargés.HBASE-16852 : TestDefaultCompactSelection a échoué sur branch-1.3.
HBASE-17387 : Réduction de la surcharge de rapport d’exception dans RegionActionResult pour multi().
HBASE-17850 : Utilitaire de réparation du système de sauvegarde.
HBASE-17931 : Affectation de tables système à des serveurs avec la version la plus récente.
HBASE-18083 : Définition du nombre de threads du nettoyage de fichiers de petite/grande taille comme configurable dans HFileCleaner.
HBASE-18084 : Amélioration de CleanerChore pour nettoyer à partir du répertoire, qui consomme davantage d’espace disque.
HBASE-18164 : Fonction de coût de localité beaucoup plus rapide et générateur de candidat.
HBASE-18212 : En mode autonome avec le système de fichiers local, HBase enregistre le message d’avertissement : Impossible d’appeler la méthode ’unbuffer’ dans la classe org.apache.hadoop.fs.FSDataInputStream.
HBASE-18808 : vérification de configuration inefficace dans BackupLogCleaner#getDeletableFiles().
HBASE-19052 : FixedFileTrailer doit reconnaître la classe CellComparatorImpl dans branch-1.x.
HBASE-19065 : HRegionbulk#LoadHFiles() doit attendre la fin de Regionflush() simultané.
HBASE-19285 : Ajout des histogrammes de latence par table.
HBASE-19393 : HTTP 413 FULL HEAD lors de l’accès à l’interface utilisateur de HBase à l’aide de SSL.
HBASE-19395 : [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting échoue avec NPE.
HBASE-19421 : branch-1 n’est pas compilé sur Hadoop 3.0.0.
HBASE-19934 : HBaseSnapshotException quand les réplicas en lecture sont activés et qu’une capture instantanée en ligne est prise après le fractionnement de la région.
HBASE-20008 : [rétroportage] de NullPointerException lors de la restauration d’une capture instantanée après le fractionnement d’une région.
Hive
Cette version fournit Hive 1.2.1 et Hive 2.1.0 en plus des correctifs suivants :
Correctifs Apache Hive 1.2.1 :
HIVE-10697 : ObjectInspectorConvertors#UnionConvertor effectue une conversion défectueuse.
HIVE-11266: résultat incorrect de count(*) basé sur les statistiques de table pour les tables externes.
HIVE-12245 : Prise en charge des commentaires de colonne pour une table sauvegardée HBase.
HIVE-12315 : Correction de double division par zéro vectorisée.
HIVE-12360 : Recherche incorrecte dans ORC non compressé avec pushdown de prédicat.
HIVE-12378 : Exception sur un champ binaire HBaseSerDe.serialize.
HIVE-12785 : La vue avec type d’union et UDF sur la structure est endommagée.
HIVE-14013 : La table Describe n’affiche pas correctement unicode.
HIVE-14205 : Hive ne prend pas en charge le type d’union avec le format de fichier AVRO.
HIVE-14421 : FS.deleteOnExit comporte des références aux fichiers _tmp_space.db.
HIVE-15563 : L’exception de transition d’état d’opération non conforme doit être ignorée dans SQLOperation.runQuery pour exposer l’exception réelle.
HIVE-15680 : Résultats incorrects quand hive.optimize.index.filter=true et la même table ORC est référencée deux fois dans la requête, en mode MR.
HIVE-15883 : Échec de l’insertion de la table mappée HBase dans Hive pour la colonne des décimales.
HIVE-16232 : Prise en charge du calcul de statistiques pour les colonnes dans QuotedIdentifier.
HIVE-16828 : Avec l’activation de CBO, la requête sur des vues partitionnées lève IndexOutOfBoundException.
HIVE-17013 : Suppression de la requête avec une sous-requête basée sur la sélection sur une vue.
HIVE-17063 : Échec de l’insertion d’une partition de remplacement sur une table externe quand la partition est supprimée en premier.
HIVE-17259 : Hive JDBC ne reconnaît pas les colonnes UNIONTYPE.
HIVE-17419 : La commande ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS affiche des statistiques calculées pour les tables masquées.
HIVE-17530 : ClassCastException lors de la conversion d’
uniontype.HIVE-17621 : Les paramètres de site Hive sont ignorés lors du calcul de fractionnement HCatInputFormat.
HIVE-17636 : Ajout du test multiple_agg.q pour les
blobstores.HIVE-17729 : Ajout de tests de magasins d’objets blob liés à Database & Explain.
HIVE-17731 : Ajout d’une option de
compatdescendante pour les utilisateurs externes à HIVE-11985.HIVE-17803 : Avec la multirequête Pig, 2 HCatStorers écrivant dans la même table compromettent les sorties de l’autre.
HIVE-17829 : ArrayIndexOutOfBoundsException - Tables sauvegardées par HBASE avec schéma Avro dans
Hive2.HIVE-17845 : Échec d’insertion si les colonnes de la table cible ne sont pas en minuscules.
HIVE-17900 : L’analyse des statistiques sur les colonnes déclenchée par le compacteur génère du SQL incorrect avec > 1 colonne de partition.
HIVE-18026 : Optimisation de la configuration principale de conversation web Hive.
HIVE-18031 : Prise en charge de la réplication pour l’opération Alter Database.
HIVE-18090 : Échec de pulsation ACID quand le metastore est connecté par le biais d’informations d’identification hadoop.
HIVE-18189 : La requête Hive retourne des résultats incorrects quand hive.groupby.orderby.position.alias a la valeur true.
HIVE-18258 : Vectorisation : Échec de Reduce-Side GROUP BY MERGEPARTIAL avec des colonnes en double.
HIVE-18293 : Hive ne parvient pas à compacter les tables contenues dans un dossier qui n’appartient pas à l’identité exécutant HiveMetaStore.
HIVE-18327 : Suppression de la dépendance HiveConf inutile pour MiniHiveKdc.
HIVE-18341 : Ajout de la prise en charge de REPL LOAD avec l’ajout d’espace de noms « brut » pour Transparent Data Encryption à l’aide des mêmes clés de chiffrement.
HIVE-18352 : Introduction d’une option METADATAONLY lors d’une opération REPL DUMP pour autoriser les intégrations d’autres outils.
HIVE-18353 : CompactorMR doit appeler jobclient.close() pour déclencher le nettoyage.
HIVE-18390 : IndexOutOfBoundsException lors de l’interrogation d’une vue partitionnée dans ColumnPruner.
HIVE-18429 : Le compactage doit faire face à l’éventualité où il ne produit aucune sortie.
HIVE-18447 : JDBC : Un moyen doit être fourni aux utilisateurs JDBC pour transmettre des informations de cookie via la chaîne de connexion.
HIVE-18460 : Le compacteur ne transmet pas les propriétés des tables au writer Orc.
HIVE-18467 : Prise en charge des événements de base de données vider/charger + créer/supprimer pour tout l’entrepôt (Anishek Agarwal, révision par Sankar Hariappan).
HIVE-18551 : Vectorisation : VectorMapOperator essaie d’écrire un trop grand nombre de colonnes de vecteur pour Hybrid Grace.
HIVE-18587 : un événement d’insertion DML peut tenter de calculer une somme de contrôle sur les répertoires.
HIVE-18613 : Extension de JsonSerDe pour prendre en charge le type BINARY.
HIVE-18626 : La clause « with » de REPL LOAD ne passe pas de configuration aux tâches.
HIVE-18660 : PCR ne fait pas la distinction entre les colonnes de partition et virtuelles.
HIVE-18754 : REPL STATUS doit prendre en charge la clause « with ».
HIVE-18754 : REPL STATUS doit prendre en charge la clause « with ».
HIVE-18788 : Nettoyage des entrées dans PreparedStatement JDBC.
HIVE-18794 : La clause « with » de REPL LOAD ne passe pas de configuration aux tâches pour les tables non partitionnées.
HIVE-18808 : Le compactage doit être plus solide en cas d’échec de la mise à jour des statistiques.
HIVE-18817 : Exception ArrayIndexOutOfBounds lors de la lecture de la table ACID.
HIVE-18833 : Échec de fusion automatique quand « insertion dans le répertoire comme orcfile ».
HIVE-18879 : L’interdiction de l’élément incorporé dans UDFXPathUtil doit fonctionner si xercesImpl.jar figure dans le classpath.
HIVE-18907 : Création d’un utilitaire pour résoudre le problème d’index de clé ACID depuis HIVE-18817.
Correctifs Apache Hive 2.1.0 :
HIVE-14013 : La table Describe n’affiche pas correctement unicode.
HIVE-14205 : Hive ne prend pas en charge le type d’union avec le format de fichier AVRO.
HIVE-15563 : L’exception de transition d’état d’opération non conforme doit être ignorée dans SQLOperation.runQuery pour exposer l’exception réelle.
HIVE-15680 : Résultats incorrects quand hive.optimize.index.filter=true et la même table ORC est référencée deux fois dans la requête, en mode MR.
HIVE-15883 : Échec de l’insertion de la table mappée HBase dans Hive pour la colonne des décimales.
HIVE-16757 : Suppression des appels à AbstractRelNode.getRows déprécié.
HIVE-16828 : Avec l’activation de CBO, la requête sur des vues partitionnées lève IndexOutOfBoundException.
HIVE-17063 : Échec de l’insertion d’une partition de remplacement sur une table externe quand la partition est supprimée en premier.
HIVE-17259 : Hive JDBC ne reconnaît pas les colonnes UNIONTYPE.
HIVE-17530 : ClassCastException lors de la conversion d’
uniontype.HIVE-17600 : enforceBufferSize d’OrcFile doit être paramétrable par l’utilisateur.
HIVE-17601 : Amélioration de la gestion des erreurs dans LlapServiceDriver.
HIVE-17613 : Suppression des pools d’objets pour les allocations courtes sur le même thread.
HIVE-17617 : Le cumul d’un jeu de résultats vide doit contenir le regroupement de l’ensemble de regroupements vide.
HIVE-17621 : Les paramètres de site Hive sont ignorés lors du calcul de fractionnement HCatInputFormat.
HIVE-17629 : CachedStore : La configuration d’une liste approuvée/non-approuvée doit permettre la mise en cache sélective des tables/partitions et autoriser la lecture pendant la préparation.
HIVE-17636 : Ajout du test multiple_agg.q pour les
blobstores.HIVE-17702 : Gestion incorrecte d’isRepeating dans le lecteur décimal dans ORC.
HIVE-17729 : Ajout de tests de magasins d’objets blob liés à Database & Explain.
HIVE-17731 : Ajout d’une option de
compatdescendante pour les utilisateurs externes à HIVE-11985.HIVE-17803 : Avec la multirequête Pig, 2 HCatStorers écrivant dans la même table compromettent les sorties de l’autre.
HIVE-17845 : Échec d’insertion si les colonnes de la table cible ne sont pas en minuscules.
HIVE-17900 : L’analyse des statistiques sur les colonnes déclenchée par le compacteur génère du SQL incorrect avec > 1 colonne de partition.
HIVE-18006 : Optimisation de l’encombrement de mémoire de HLLDenseRegister.
HIVE-18026 : Optimisation de la configuration principale de conversation web Hive.
HIVE-18031 : Prise en charge de la réplication pour l’opération Alter Database.
HIVE-18090 : Échec de pulsation ACID quand le metastore est connecté par le biais d’informations d’identification hadoop.
HIVE-18189 : L’ordre selon la position ne fonctionne pas quand
cboest désactivé.HIVE-18258 : Vectorisation : Échec de Reduce-Side GROUP BY MERGEPARTIAL avec des colonnes en double.
HIVE-18269 : LLAP : Des E/S
llaprapides avec un pipeline de traitement lent peuvent aboutir à un problème de mémoire insuffisante.HIVE-18293 : Hive ne parvient pas à compacter les tables contenues dans un dossier qui n’appartient pas à l’identité exécutant HiveMetaStore.
HIVE-18318 : Le lecteur d’enregistrement LLAP doit vérifier l’interruption même en l’absence de blocage.
HIVE-18326 : Planificateur Tez LLAP, anticipation des tâches uniquement s’il existe une dépendance entre elles.
HIVE-18327 : Suppression de la dépendance HiveConf inutile pour MiniHiveKdc.
HIVE-18331 : Ajout de reconnexion lors de l’expiration du ticket TGT et de journalisation/lambda.
HIVE-18341 : Ajout de la prise en charge de REPL LOAD avec l’ajout d’espace de noms « brut » pour Transparent Data Encryption à l’aide des mêmes clés de chiffrement.
HIVE-18352 : Introduction d’une option METADATAONLY lors d’une opération REPL DUMP pour autoriser les intégrations d’autres outils.
HIVE-18353 : CompactorMR doit appeler jobclient.close() pour déclencher le nettoyage.
HIVE-18384 : ConcurrentModificationException dans la bibliothèque
log4j2.x.HIVE-18390 : IndexOutOfBoundsException lors de l’interrogation d’une vue partitionnée dans ColumnPruner.
HIVE-18447 : JDBC : Un moyen doit être fourni aux utilisateurs JDBC pour transmettre des informations de cookie via la chaîne de connexion.
HIVE-18460 : Le compacteur ne transmet pas les propriétés des tables au writer Orc.
HIVE-18462 : (Explain mis en forme pour les requêtes avec jointure de mappage a columnExprMap avec un nom de colonne non mis en forme).
HIVE-18467 : Prise en charge des événements de base de données vider/charger + créer/supprimer pour tout l’entrepôt.
HIVE-18488 : Il manque des contrôles de valeur null aux lecteurs ORC LLAP.
HIVE-18490 : La requête avec EXISTS et NOT EXISTS et un prédicat différent peut produire un résultat incorrect.
HIVE-18506 : LlapBaseInputFormat - index de tableau négatif.
HIVE-18517 : Vectorisation : Correction de VectorMapOperator pour accepter des VRB et vérifier l’indicateur vectorisé correctement pour prendre en charge la mise en cache LLAP.
HIVE-18523 : Correction de la ligne de résumé s’il n’y a pas d’entrée.
HIVE-18528 : Les statistiques agrégées dans ObjectStore obtiennent un résultat incorrect.
HIVE-18530 : La réplication doit ignorer la table MM (pour l’instant).
HIVE-18548 : Correction de l’importation
log4j.HIVE-18551 : Vectorisation : VectorMapOperator essaie d’écrire un trop grand nombre de colonnes de vecteur pour Hybrid Grace.
HIVE-18577 : SemanticAnalyzer.validate a certains appels de metastore inutiles.
HIVE-18587 : un événement d’insertion DML peut tenter de calculer une somme de contrôle sur les répertoires.
HIVE-18597 : LLAP : Création systématique du package du fichier jar de l’API
log4j2pourorg.apache.log4j.HIVE-18613 : Extension de JsonSerDe pour prendre en charge le type BINARY.
HIVE-18626 : La clause « with » de REPL LOAD ne passe pas de configuration aux tâches.
HIVE-18643 : Pas de recherche de partitions archivées pour les opérations ACID.
HIVE-18660 : PCR ne fait pas la distinction entre les colonnes de partition et virtuelles.
HIVE-18754 : REPL STATUS doit prendre en charge la clause « with ».
HIVE-18788 : Nettoyage des entrées dans PreparedStatement JDBC.
HIVE-18794 : La clause « with » de REPL LOAD ne passe pas de configuration aux tâches pour les tables non partitionnées.
HIVE-18808 : Le compactage doit être plus solide en cas d’échec de la mise à jour des statistiques.
HIVE-18815 : Suppression des fonctionnalités inutilisées dans HPL/SQL.
HIVE-18817 : Exception ArrayIndexOutOfBounds lors de la lecture de la table ACID.
HIVE-18833 : Échec de fusion automatique quand « insertion dans le répertoire comme orcfile ».
HIVE-18879 : L’interdiction de l’élément incorporé dans UDFXPathUtil doit fonctionner si xercesImpl.jar figure dans le classpath.
HIVE-18944 : La position des jeux de regroupement est définie de façon incorrecte pendant DPP.
Kafka
Cette version fournit Kafka 1.0.0 et les correctifs Apache suivants.
KAFKA-4827 : Connexion Kafka : erreur avec des caractères spéciaux dans le nom du connecteur.
KAFKA-6118 : Échec passager dans kafka.api.SaslScramSslEndToEndAuthorizationTest.testTwoConsumersWithDifferentSaslCredentials.
KAFKA-6156 : JmxReporter ne peut pas gérer les chemins de répertoire de style Windows.
KAFKA-6164 : Des threads ClientQuotaManager empêchent l’arrêt en présence d’une erreur de chargement des journaux d’activité.
KAFKA-6167 : Un horodatage sur le répertoire de flux contient un signe deux-points, ce qui est un caractère non conforme.
KAFKA-6179 : RecordQueue.clear() n’efface pas la liste gérée de MinTimestampTracker.
KAFKA-6185 : Fuite de mémoire du sélecteur avec une probabilité élevée de problème de mémoire insuffisante en cas de conversion descendante.
KAFKA-6190 : GlobalKTable ne termine jamais la restauration lors de l’utilisation des messages transactionnels.
KAFKA-6210 : IllegalArgumentException si la version 1.0.0 est utilisée pour inter.broker.protocol.version ou log.message.format.version.
KAFKA-6214 : L’utilisation de réplicas en attente avec un magasin d’état en mémoire provoque le blocage des flux.
KAFKA-6215 : Échec de KafkaStreamsTest dans la jonction.
KAFKA-6238 : Problèmes avec la version de protocole lors de l’application d’une mise à niveau propagée à 1.0.0.
KAFKA-6260 : AbstractCoordinator ne gère pas clairement l’exception Null.
KAFKA-6261 : La journalisation des requêtes lève une exception si acks=0.
KAFKA-6274 : Amélioration des noms générés automatiquement du magasin d’état source
KTable.
Mahout
Dans HDP-2.3.x et 2.4.x, au lieu de livrer une version Apache spécifique de Mahout, nous avons procédé à une synchronisation vers un point particulier de révision sur la jonction Apache Mahout. Ce point de révision se situe après la version 0.9.0, mais avant la version 0.10.0. Cette opération propose un grand nombre de correctifs de bogues et d’améliorations fonctionnelles par rapport à la version 0.9.0, mais fournit une version stable de la fonctionnalité Mahout avant la conversion complète vers une nouvelle version de Mahout basée sur Spark dans 0.10.0.
Le point de révision choisi pour Mahout dans HDP 2.3.x et 2.4.x provient de la branche « mahout-0.10.x » d’Apache Mahout, à compter du 19 décembre 2014, révision 0f037cb03e77c096 dans GitHub.
Dans HDP-2.5.x et 2.6.x, nous avons supprimé la bibliothèque « commons-httpclient » de Mahout, car nous la considérions comme obsolète avec d’éventuels problèmes de sécurité, et avons mis à niveau Hadoop-Client dans Mahout vers la version 2.7.3, la même version utilisée dans HDP 2.5. Par conséquent :
Les tâches Mahout précédemment compilées devront être recompilées dans l’environnement HDP-2.5 ou 2.6.
Il existe un faible risque que certaines tâches Mahout rencontrent les erreurs « ClassNotFoundException » ou « Impossible de charger la classe » liées à « org.apache.commons.httpclient », « net.java.dev.jets3t » ou aux préfixes de nom de classe connexes. Si ces erreurs se produisent, vous pouvez envisager d’installer manuellement les fichiers jar nécessaires dans le classpath pour la tâche, si le risque de problèmes de sécurité dans la bibliothèque obsolète est acceptable dans votre environnement.
Il existe un risque encore plus faible que certaines tâches Mahout rencontrent des plantages dans les appels de code hbase-client de Mahout aux bibliothèques hadoop-common, en raison de problèmes de compatibilité binaire. Malheureusement, il n’existe aucun moyen de résoudre ce problème, si ce n’est de revenir à la version HDP-2.4.2 de Mahout, qui peut présenter des problèmes de sécurité. Là encore, ce problème doit être rare et il est peu probable qu’il se produise dans n’importe quelle suite de tâches Mahout donnée.
Oozie
Cette version fournit Oozie 4.2.0 avec les correctifs Apache suivants.
OOZIE-2571 : Ajout de la propriété Maven spark.scala.binary.version afin que Scala 2.11 puisse être utilisé.
OOZIE-2606 : Définition de spark.yarn.jars pour corriger Spark 2.0 avec Oozie.
OOZIE-2658 : --driver-class-path peut remplacer le classpath dans SparkMain.
OOZIE-2787 : Oozie distribue le fichier jar d’application à deux reprises et provoque l’échec du travail Spark.
OOZIE-2792 : L’action
Hive2n’analyse pas correctement l’ID d’application Spark à partir du fichier journal quand Hive se trouve sur Spark.OOZIE-2799 : Définition de l’emplacement du journal pour spark sql sur hive.
OOZIE-2802 : Échec de l’action Spark sur Spark 2.1.0 en raison de
sharelibsen double.OOZIE-2923 : Amélioration de l’analyse des options Spark.
OOZIE-3109 : SCA : Scripts de site à site : Réfléchi.
OOZIE-3139 : Oozie valide le workflow de façon incorrecte.
OOZIE-3167 : Mise à niveau de la version tomcat sur Oozie branche 4.3.
Phoenix
Cette version fournit Phoenix 4.7.0 et les correctifs Apache suivants :
PHOENIX-1751 : Exécution d’agrégations, de tris, etc. dans preScannerNext au lieu de postScannerOpen.
PHOENIX-2714 : Correction de l’estimation d’octets dans BaseResultIterators et exposition en tant qu’interface.
PHOENIX-2724 : Une requête avec un grand nombre d’indications est plus lente que sans statistiques.
PHOENIX-2855 : La solution de contournement Increment.timeRange n’est pas sérialisée pour HBase 1.2.
PHOENIX-3023: Ralentissement des performances quand les requêtes de limite sont exécutées en parallèle par défaut.
PHOENIX-3040 : Ne pas utiliser d’indications pour l’exécution de requêtes en série.
PHOENIX-3112 : L’analyse de ligne partielle n’est pas gérée correctement.
PHOENIX-3240 : ClassCastException à partir du chargeur Pig.
PHOENIX-3452 : Les valeurs NULL FIRST/NULL LAST ne doivent pas avoir d’impact sur la préservation ou non de l’ordre par GROUP BY.
PHOENIX-3469 : Ordre de tri incorrect pour la clé primaire DESC pour les valeurs NULL FIRST/NULL LAST.
PHOENIX-3789 : Exécution d’appels de maintenance d’index dans plusieurs régions dans postBatchMutateIndispensably.
PHOENIX-3865 : IS NULL ne retourne pas de résultats corrects quand la première famille de colonnes n’est pas filtrée sur cette valeur.
PHOENIX-4290 : Analyse de table complète effectuée pour DELETE avec une table ayant des index immuables.
PHOENIX-4373 : Une clé de longueur variable d’index local peut avoir des valeurs Null de fin lors d’une opération d’upsert.
PHOENIX-4466 : java.lang.RuntimeException : code de réponse 500. Exécution d’un travail Spark pour se connecter à Phoenix Query Server et charger des données.
PHOENIX-4489 : Perte de connexion HBase dans les travaux Phoenix MR.
PHOENIX-4525 : Dépassement d’entier dans l’exécution GroupBy.
PHOENIX-4560 : ORDER BY avec GROUP BY ne fonctionne pas si WHERE figure dans la colonne
pk.PHOENIX-4586 : UPSERT SELECT ne prend pas en compte les opérateurs de comparaison pour les sous-requêtes.
PHOENIX-4588 : l’expression doit également être clonée si ses enfants ont Determinism.PER_INVOCATION.
Pig
Cette version fournit Pig 0.16.0 avec les correctifs Apache suivants.
PIG-5159 : Correction de Pig qui n’enregistre pas l’historique grunt.
PIG-5175 : Mise à niveau de
jrubyvers 1.7.26.
Ranger
Cette version fournit Ranger 0.7.0 et les correctifs Apache suivants :
RANGER-1805 : Amélioration du code pour suivre les bonnes pratiques en js.
RANGER-1960 : Prise en considération du nom de table de la capture instantanée pour la suppression.
RANGER-1982 : Amélioration de la gestion des erreurs pour les métriques d’analytique de Ranger Admin et Ranger KMS.
RANGER-1984 : les enregistrements de journal d’audit HBase peuvent ne pas afficher toutes les balises associées à une colonne sollicitée.
RANGER-1988 : Correction du caractère aléatoire non sécurisé.
RANGER-1990 : Ajout de la prise en charge SSL MySQL unidirectionnel dans Ranger Admin.
RANGER-2006 : Correction des problèmes détectés par l’analyse de code statique dans Ranger
usersyncpour la source de synchronisationldap.RANGER-2008 : L’évaluation de la stratégie échoue dans des conditions de stratégie multiligne.
Curseur
Cette version fournit Slider 0.92.0 sans aucun correctif Apache supplémentaire.
Spark
Cette version fournit Spark 2.3.0 et les correctifs Apache suivants :
SPARK-13587 : Prise en charge de virtualenv dans pyspark.
SPARK-19964 : La lecture doit être évitée à partir de référentiels distants dans SparkSubmitSuite.
SPARK-22882 : Test ML pour le streaming structuré : ml.classification.
SPARK-22915 : Tests de streaming pour spark.ml.feature, de N à Z.
SPARK-23020 : Correction d’une autre concurrence dans le test de lanceur In-process.
SPARK-23040 : Retour de l’itérateur interruptible pour le lecteur aléatoire.
SPARK-23173 : La création de fichiers Parquet endommagés lors du chargement des données à partir de JSON doit être évitée.
SPARK-23264 : Correction de scala.MatchError dans literals.sql.out.
SPARK-23288 : Correction des métriques de sortie avec le récepteur Parquet.
SPARK-23329 : Correction de la documentation des fonctions trigonométriques.
SPARK-23406 : Activation de jointures réflexives entre flux pour branch-2.3.
SPARK-23434 : Spark ne doit pas avertir le « répertoire de métadonnées » d’un chemin de fichier HDFS.
SPARK-23436 : Déduction de la partition en tant que Date uniquement si elle peut être convertie en Date.
SPARK-23457 : Inscription tout d’abord des écouteurs d’achèvement des tâches dans ParquetFileFormat.
SPARK-23462 : amélioration du message d’erreur de champ manquant dans « StructType ».
SPARK-23490 : Vérification de storage.locationUri avec une table existante dans CreateTable.
SPARK-23524 : Il est inutile de vérifier si les blocs de lecture aléatoire locaux volumineux sont endommagés.
SPARK-23525 : Prise en charge de ALTER TABLE CHANGE COLUMN COMMENT pour la table externe hive.
SPARK-23553 : Les tests ne doivent pas présumer la valeur par défaut de « spark.sql.sources.default ».
SPARK-23569 : autorisation de l’utilisation de pandas_udf avec des fonctions annotées par le type de style python3.
SPARK-23570 : Ajout de Spark 2.3.0 dans HiveExternalCatalogVersionsSuite.
SPARK-23598 : Les méthodes dans BufferedRowIterator doivent être rendues publiques afin d’éviter l’erreur d’exécution pour une requête de grande taille.
SPARK-23599 : Ajout d’un générateur UUID à partir de nombres pseudo-aléatoires.
SPARK-23599 : Utilisation de RandomUUIDGenerator dans l’expression Uuid.
SPARK-23601 : Suppression de fichiers
.md5de la version.SPARK-23608 : Ajout de la synchronisation dans SHS entre les fonctions attachSparkUI et detachSparkUI afin d’éviter le problème de modification simultanée pour les gestionnaires Jetty.
SPARK-23614 : Correction d’un échange de réutilisation incorrect quand la mise en cache est utilisée.
SPARK-23623 : L’utilisation simultanée de consommateurs mis en cache doit être évitée dans CachedKafkaConsumer (branch-2.3).
SPARK-23624 : Révision du document de la méthode pushFilters dans Datasource V2.
SPARK-23628 : calculateParamLength ne doit pas retourner 1 + nombre d’expressions.
SPARK-23630 : Autorisation de l’application des personnalisations de configuration hadoop de l’utilisateur.
SPARK-23635 : La variable env d’exécuteur Spark est remplacée par la variable env AM du même nom.
SPARK-23637 : Yarn peut allouer plus de ressources si un même exécuteur est supprimé plusieurs fois.
SPARK-23639 : Obtention du jeton avant l’initialisation du client de metastore dans SparkSQL CLI.
SPARK-23642 : Correction de
scaladocpour la sous-classe AccumulatorV2 isZero.SPARK-23644 : Utilisation d’un chemin absolu pour l’appel REST dans SHS.
SPARK-23645 : ajout des documents RE « pandas_udf » avec le mot clé args.
SPARK-23649 : Les caractères non autorisés sont ignorés dans UTF-8.
SPARK-23658 : InProcessAppHandle utilise la classe incorrecte dans getLogger.
SPARK-23660 : Correction de l’exception en mode de cluster yarn quand l’application s’est terminée rapidement.
SPARK-23670 : Correction de la fuite de mémoire sur SparkPlanGraphWrapper.
SPARK-23671 : Correction de la condition pour activer le pool de threads SHS.
SPARK-23691 : utilisation de l’utilitaire sql_conf dans les tests PySpark si possible.
SPARK-23695 : Correction du message d’erreur pour les tests de streaming Kinesis.
SPARK-23706 : spark.conf.get(value, valeur par défaut=None) doit produire None dans PySpark.
SPARK-23728 : Correction des tests ML avec des exceptions attendues exécutant des tests de streaming.
SPARK-23729 : Respect du fragment d’URI lors de la résolution des modèles Glob.
SPARK-23759 : Impossible de lier l’interface utilisateur de Spark au nom d’hôte/à l’adresse IP spécifique.
SPARK-23760 : CodegenContext.withSubExprEliminationExprs doit enregistrer/restaurer correctement l’état CSE.
SPARK-23769 : Suppression des commentaires qui désactivent inutilement la vérification
Scalastyle.SPARK-23788 : Correction de concurrence dans StreamingQuerySuite.
SPARK-23802 : PropagateEmptyRelation peut laisser un plan de requête dans un état non résolu.
SPARK-23806 : Broadcast.unpersist peut provoquer une exception irrécupérable quand il est utilisé avec l’allocation dynamique.
SPARK-23808 : Définition de la session Spark par défaut dans les sessions spark de test uniquement.
SPARK-23809 : La session SparkSession active doit être définie par getOrCreate.
SPARK-23816 : Les tâches supprimées doivent ignorer FetchFailures.
SPARK-23822 : Amélioration du message d’erreur pour les incompatibilités de schéma Parquet.
SPARK-23823 : Conservation de l’origine dans transformExpression.
SPARK-23827 : StreamingJoinExec doit vérifier que les données d’entrée sont partitionnées en un nombre spécifique de partitions.
SPARK-23838 : La requête SQL en cours d’exécution est affichée comme « terminée » sous l’onglet SQL.
SPARK-23881 : Correction du test non fiable JobCancellationSuite.« itérateur interruptible pour le lecteur aléatoire ».
Sqoop
Cette version fournit Sqoop 1.4.6 sans aucun correctif Apache supplémentaire.
Storm
Cette version fournit Storm 1.1.1 et les correctifs Apache suivants :
STORM-2652 : Exception levée dans la méthode Open JmsSpout.
STORM-2841 : Échec de testNoAcksIfFlushFails UT avec NullPointerException.
STORM-2854 : Exposition d’IEventLogger pour rendre la journalisation des événements enfichable.
STORM-2870 : FileBasedEventLogger divulgue un ExecutorService non-démon, qui empêche le processus de se terminer.
STORM-2960 : Il est préférable de souligner l’importance de la configuration du compte du système d’exploitation approprié pour les processus Storm.
Tez
Cette version fournit Tez 0.7.0 et les correctifs Apache suivants :
- TEZ-1526 : LoadingCache pour TezTaskID lent pour les travaux importants.
Zeppelin
Cette version fournit Zeppelin 0.7.3 sans aucun correctif Apache supplémentaire.
ZEPPELIN-3072 : L’interface utilisateur de Zeppelin ne répond plus ou ralentit s’il existe trop de blocs-notes.
ZEPPELIN-3129 : l’interface utilisateur Zeppelin ne se déconnecte pas dans Internet Explorer.
ZEPPELIN-903 : Remplacement de CXF par
Jersey2.
ZooKeeper
Cette version fournit ZooKeeper 3.4.6 et les correctifs Apache suivants :
ZOOKEEPER-1256 : ClientPortBindTest échoue sur macOS X.
ZOOKEEPER-1901 : [JDK8] Tri des enfants pour la comparaison dans les tests AsyncOps.
ZOOKEEPER-2423 : Mise à niveau de la version de Netty en raison d’une faille de sécurité (CVE-2014-3488).
ZOOKEEPER-2693 : Attaque DOS sur les mots de quatre lettres (4lw) wchp/wchc.
ZOOKEEPER-2726 : Le correctif introduit une condition de concurrence potentielle.
Failles et menaces courantes corrigées
Cette section couvre toutes les failles et menaces courantes (CVE, Common Vulnerabilities and Exposures) qui sont corrigées dans cette version.
CVE-2017-7676
| Résumé : l’évaluation de la stratégie Apache Ranger ignore les caractères après le caractère générique « * » |
|---|
| Gravité : Critique |
| Fournisseur : Hortonworks |
| Versions affectées : versions HDInsight 3.6 notamment Apache Ranger versions 0.5.x/0.6.x/0.7.0 |
| Utilisateurs affectés : environnements qui utilisent des stratégies Ranger avec des caractères après le caractère générique « * », comme my*test, test*.txt |
| Impact : le détecteur de ressource de stratégie ignore les caractères après le caractère générique « * », ce qui peut entraîner un comportement inattendu. |
| Détail de la correction : le détecteur de ressource de stratégie Ranger a été mis à jour pour gérer correctement les correspondances avec un caractère générique. |
| Action recommandée : mise à niveau vers HDI 3.6 (avec Apache Ranger 0.7.1+). |
CVE-2017-7677
| Résumé : l’agent d’autorisation Apache Ranger Hive doit rechercher l’autorisation RWX quand un emplacement externe est spécifié |
|---|
| Gravité : Critique |
| Fournisseur : Hortonworks |
| Versions affectées : versions HDInsight 3.6 notamment Apache Ranger versions 0.5.x/0.6.x/0.7.0 |
| Utilisateurs affectés : environnements qui utilisent un emplacement externe pour des tables Hive |
| Impact : dans les environnements qui utilisent l’emplacement externe pour les tables Hive, l’agent d’autorisation Apache Ranger Hive doit rechercher l’autorisation RWX pour l’emplacement externe spécifié pour create table. |
| Détail de la correction : l’agent d’autorisation Ranger Hive a été mis à jour pour gérer correctement la vérification d’autorisation avec un emplacement externe. |
| Action recommandée : les utilisateurs doivent effectuer la mise à niveau vers HDI 3.6 (avec Apache Ranger 0.7.1+). |
CVE-2017-9799
| Résumé : exécution potentielle de code en tant qu’utilisateur incorrect dans Apache Storm |
|---|
| Gravité : Important |
| Fournisseur : Hortonworks |
| Versions affectées : HDP 2.4.0, HDP-2.5.0, HDP-2.6.0 |
| Utilisateurs affectés : utilisateurs qui emploient Storm en mode sécurisé et utilisent le magasin d’objets blob pour distribuer les artefacts basés sur la topologie ou des ressources de la topologie. |
| Impact : Dans certains cas et certaines configurations de storm, il est théoriquement possible pour le propriétaire d’une topologie de tromper le superviseur afin de lancer un Worker comme utilisateur différent et non-racine. Dans le pire des cas, les informations d’identification sécurisées de l’autre utilisateur pourraient être compromises. Cette vulnérabilité s’applique uniquement aux installations Apache Storm avec la sécurité activée. |
| Atténuation : mise à niveau vers HDP-2.6.2.1, car il n’existe pour l’instant aucune solution de contournement. |
CVE-2016-4970
| Résumé : handler/ssl/OpenSslEngine.java dans Netty 4.0.x avant 4.0.37. Final et 4.1.x avant 4.1.1. Final permet à des attaquants distants de provoquer un déni de service (boucle infinie) |
|---|
| Gravité : Modéré |
| Fournisseur : Hortonworks |
| Versions affectées : HDP 2.x.x à partir de 2.3.x |
| Utilisateurs affectés : tous les utilisateurs qui utilisent HDFS. |
| Impact : l’impact est faible, car Hortonworks n’utilise pas OpenSslEngine.java directement dans le codebase Hadoop. |
| Action recommandée : Effectuez une mise à niveau vers HDP 2.6.3. |
CVE-2016-8746
| Résumé : problème de mise en correspondance des chemins Apache Ranger dans l’évaluation de la stratégie |
|---|
| Gravité : Normal |
| Fournisseur : Hortonworks |
| Versions affectées : toutes les versions HDP 2.5, notamment Apache Ranger versions 0.6.0/0.6.1/0.6.2 |
| Utilisateurs affectés : tous les utilisateurs de l’outil d’administration de stratégie Ranger. |
| Impact : le moteur de stratégie Ranger met incorrectement en correspondance des chemins dans certaines conditions quand une stratégie contient des caractères génériques et des indicateurs récursifs. |
| Détail de la correction : Logique d’évaluation de la stratégie corrigée |
| Action recommandée : les utilisateurs doivent effectuer la mise à niveau vers HDP 2.5.4+ (avec Apache Ranger 0.6.3+) ou HDP 2.6+ (avec Apache Ranger 0.7.0+) |
CVE-2016-8751
| Résumé : problème de scripts intersites stockés dans Apache Ranger |
|---|
| Gravité : Normal |
| Fournisseur : Hortonworks |
| Versions affectées : toutes les versions HDP 2.3/2.4/2.5, notamment Apache Ranger versions 0.5.x/0.6.0/0.6.1/0.6.2 |
| Utilisateurs affectés : tous les utilisateurs de l’outil d’administration de stratégie Ranger. |
| Impact : Apache Ranger est vulnérable aux scripts intersites stockés lors de la saisie des conditions de stratégie personnalisée. Les utilisateurs administrateurs peuvent stocker du code JavaScript arbitraire à exécuter quand des utilisateurs normaux se connectent et accèdent aux stratégies. |
| Détail de la correction : logique ajoutée pour nettoyer l’entrée utilisateur. |
| Action recommandée : les utilisateurs doivent effectuer la mise à niveau vers HDP 2.5.4+ (avec Apache Ranger 0.6.3+) ou HDP 2.6+ (avec Apache Ranger 0.7.0+) |
Problèmes résolus pour le support
Les problèmes résolus représentent des problèmes sélectionnés qui ont été précédemment consignés via le Support Hortonworks, mais sont désormais corrigés dans la version actuelle. Ces problèmes peuvent avoir été signalés dans les versions précédentes dans la section Problèmes connus, ce qui signifie qu’ils ont été signalés par des clients ou identifiés par l’équipe d’ingénierie qualité Hortonworks.
Résultats incorrects
| ID du bogue | Apache JIRA | Résumé |
|---|---|---|
| BUG-100019 | YARN-8145 | yarn rmadmin : getGroups ne retourne pas de groupes mis à jour pour l’utilisateur |
| BUG-100058 | PHOENIX-2645 | Les caractères génériques ne correspondent pas aux caractères de nouvelle ligne |
| BUG-100266 | PHOENIX-3521, PHOENIX-4190 | Résultats incorrects avec les index locaux |
| BUG-88774 | HIVE-17617, HIVE-18413, HIVE-18523 | Échec de query36, nombre de lignes différent |
| BUG-89765 | HIVE-17702 | Gestion incorrecte d’isRepeating dans le lecteur décimal dans ORC |
| BUG-92293 | HADOOP-15042 | Azure PageBlobInputStream.skip() peut retourner une valeur négative quand numberOfPagesRemaining est égal à 0 |
| BUG-92345 | ATLAS-2285 | Interface utilisateur : Recherche enregistrée renommée avec l’attribut de date. |
| BUG-92563 | HIVE-17495, HIVE-18528 | Les statistiques agrégées dans ObjectStore obtiennent un résultat incorrect |
| BUG-92957 | HIVE-11266 | Résultat incorrect de count(*) basé sur les statistiques de table pour les tables externes |
| BUG-93097 | RANGER-1944 | Le filtre d’action pour l’audit administratif ne fonctionne pas |
| BUG-93335 | HIVE-12315 | vectorization_short_regress.q a un problème de résultat incorrect pour un calcul double |
| BUG-93415 | HIVE-18258, HIVE-18310 | Vectorisation : Échec de Reduce-Side GROUP BY MERGEPARTIAL avec des colonnes en double |
| BUG-93939 | ATLAS-2294 | Une « description » de paramètre supplémentaire est ajoutée lors de la création d’un type |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | Les requêtes Phoenix retournent des valeurs Null en raison de lignes partielles HBase |
| BUG-94266 | HIVE-12505 | L’insertion d’overwrite dans la même zone chiffrée ne parvient pas à supprimer des fichiers existants en mode silencieux |
| BUG-94414 | HIVE-15680 | Résultats incorrects quand hive.optimize.index.filter=true et la même table ORC est référencée deux fois dans la requête |
| BUG-95048 | HIVE-18490 | La requête avec EXISTS et NOT EXISTS et un prédicat différent peut produire un résultat incorrect |
| BUG-95053 | PHOENIX-3865 | IS NULL ne retourne pas de résultats corrects quand la première famille de colonnes n’est pas filtrée sur cette valeur |
| BUG-95476 | RANGER-1966 | L’initialisation du moteur de stratégie ne crée pas d’enrichisseurs de contexte dans certains cas |
| BUG-95566 | SPARK-23281 | La requête produit des résultats dans un ordre incorrect quand une clause order by composite fait référence à la fois à des colonnes d’origine et des alias |
| BUG-95907 | PHOENIX-3451, PHOENIX-3452, PHOENIX-3469, PHOENIX-4560 | Résolution des problèmes avec ORDER BY ASC quand la requête a une agrégation |
| BUG-96389 | PHOENIX-4586 | UPSERT SELECT ne prend pas en compte les opérateurs de comparaison pour les sous-requêtes. |
| BUG-96602 | HIVE-18660 | PCR ne fait pas la distinction entre les colonnes de partition et virtuelles |
| BUG-97686 | ATLAS-2468 | Problème de [recherche de base] avec les cas OR quand NEQ est utilisé avec les types numériques |
| BUG-97708 | HIVE-18817 | Exception ArrayIndexOutOfBounds lors de la lecture de la table ACID. |
| BUG-97864 | HIVE-18833 | Échec de fusion automatique quand « insertion dans le répertoire comme orcfile » |
| BUG-97889 | RANGER-2008 | L’évaluation de la stratégie échoue dans des conditions de stratégie multiligne. |
| BUG-98655 | RANGER-2066 | L’accès à la famille de colonnes HBase est autorisé par une colonne étiquetée dans la famille de colonnes |
| BUG-99883 | HIVE-19073, HIVE-19145 | StatsOptimizer peut altérer des colonnes constantes |
Autre
| ID du bogue | Apache JIRA | Résumé |
|---|---|---|
| BUG-100267 | HBASE-17170 | En raison des différences de chargeur de classe, HBase retente également DoNotRetryIOException. |
| BUG-92367 | YARN-7558 | La commande Journaux d’activité YARN ne peut pas obtenir de journaux d’activité pour les conteneurs en cours d’exécution si l’authentification de l’interface utilisateur est activée. |
| BUG-93159 | OOZIE-3139 | Oozie valide le workflow de façon incorrecte |
| BUG-93936 | ATLAS-2289 | Code de démarrage/d’arrêt de serveur kafka/zookeeper incorporé à sortir de l’implémentation KafkaNotification |
| BUG-93942 | ATLAS-2312 | Utilisation d’objets ThreadLocal DateFormat pour éviter l’utilisation simultanée de plusieurs threads |
| BUG-93946 | ATLAS-2319 | Interface utilisateur : La suppression d’une balise située au-delà de la 25è position dans la liste des balises à la fois dans la structure plate et dans l’arborescence nécessite une actualisation. |
| BUG-94618 | YARN-5037, YARN-7274 | Possibilité de désactiver l’élasticité au niveau feuille de file d’attente |
| BUG-94901 | HBASE-19285 | Ajout des histogrammes de latence par table |
| BUG-95259 | HADOOP-15185, HADOOP-15186 | Mise à jour du connecteur adls pour utiliser la version actuelle du SDK ADLS |
| BUG-95619 | HIVE-18551 | Vectorisation : VectorMapOperator essaie d’écrire un trop grand nombre de colonnes de vecteur pour Hybrid Grace |
| BUG-97223 | SPARK-23434 | Spark ne doit pas avertir le « répertoire de métadonnées » d’un chemin de fichier HDFS |
Niveau de performance
| ID du bogue | Apache JIRA | Résumé |
|---|---|---|
| BUG-83282 | HBASE-13376, HBASE-14473, HBASE-15210, HBASE-15515, HBASE-16570, HBASE-16810, HBASE-18164 | Calcul de localité rapide dans l’équilibreur |
| BUG-91300 | HBASE-17387 | Réduction de la surcharge de rapport d’exception dans RegionActionResult pour multi() |
| BUG-91804 | TEZ-1526 | LoadingCache pour TezTaskID lent pour les travaux importants |
| BUG-92760 | ACCUMULO-4578 | L’opération FATE d’annulation du compactage ne libère pas de verrou d’espace de noms |
| BUG-93577 | RANGER-1938 | Solr pour la configuration de l’audit n’utilise pas efficacement les DocValues |
| BUG-93910 | HIVE-18293 | Hive ne parvient pas à compacter les tables contenues dans un dossier qui n’appartient pas à l’identité exécutant HiveMetaStore |
| BUG-94345 | HIVE-18429 | Le compactage doit faire face à l’éventualité où il ne produit aucune sortie |
| BUG-94381 | HADOOP-13227, HDFS-13054 | Gestion de l’ordre RetryAction RequestHedgingProxyProvider : FAIL < RETRY < FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | CompactorMR doit appeler jobclient.close() pour déclencher le nettoyage |
| BUG-94869 | PHOENIX-4290, PHOENIX-4373 | Ligne demandée hors limites pour Get dans HRegion pour la table phoenix « salted » indexée locale. |
| BUG-94928 | HDFS-11078 | Correction de NPE dans LazyPersistFileScrubber |
| BUG-94964 | HIVE-18269, HIVE-18318, HIVE-18326 | Plusieurs correctifs LLAP |
| BUG-95669 | HIVE-18577, HIVE-18643 | Lors de l’exécution de la mise à jour/suppression de la requête sur la table partitionnée ACID, HS2 lit toutes les partitions. |
| BUG-96390 | HDFS-10453 | Le thread ReplicationMonitor pourrait être bloqué longtemps en raison de la concurrence entre la réplication et la suppression du même fichier dans un grand cluster. |
| BUG-96625 | HIVE-16110 | Rétablissement de « Vectorisation : Prise en charge de la valeur 2 CASE WHEN au lieu de revenir à VectorUDFAdaptor » |
| BUG-97109 | HIVE-16757 | L’utilisation du getRows() déprécié au lieu du nouveau estimateRowCount(RelMetadataQuery...) a un sérieux impact sur les performances |
| BUG-97110 | PHOENIX-3789 | Exécution d’appels de maintenance d’index dans plusieurs régions dans postBatchMutateIndispensably |
| BUG-98833 | YARN-6797 | TimelineWriter ne consomme pas complètement la réponse POST |
| BUG-98931 | ATLAS-2491 | Mise à jour du hook Hive pour utiliser des notifications Atlas v2 |
Perte de données potentielle
| ID du bogue | Apache JIRA | Résumé |
|---|---|---|
| BUG-95613 | HBASE-18808 | Vérification de configuration inefficace dans BackupLogCleaner#getDeletableFiles() |
| BUG-97051 | HIVE-17403 | Échec de concaténation pour les tables transactionnelles et non gérées |
| BUG-97787 | HIVE-18460 | Le compacteur ne transmet pas les propriétés des tables au writer Orc |
| BUG-97788 | HIVE-18613 | Extension de JsonSerDe pour prendre en charge le type BINARY |
Échec de la requête
| ID du bogue | Apache JIRA | Résumé |
|---|---|---|
| BUG-100180 | CALCITE-2232 | Erreur d’assertion sur AggregatePullUpConstantsRule lors du réglage des index d’agrégats |
| BUG-100422 | HIVE-19085 | FastHiveDecimal abs(0) définit le signe sur +ve |
| BUG-100834 | PHOENIX-4658 | IllegalStateException : requestSeek ne peut pas être appelé sur ReversedKeyValueHeap |
| BUG-102078 | HIVE-17978 | Les requêtes TPCDS 58 et 83 génèrent des exceptions dans la vectorisation. |
| BUG-92483 | HIVE-17900 | L’analyse des statistiques sur les colonnes déclenchée par le compacteur génère du SQL incorrect avec > 1 colonne de partition |
| BUG-93135 | HIVE-15874, HIVE-18189 | La requête Hive retourne des résultats incorrects quand hive.groupby.orderby.position.alias a la valeur true |
| BUG-93136 | HIVE-18189 | L’ordre selon la position ne fonctionne pas quand cbo est désactivé |
| BUG-93595 | HIVE-12378, HIVE-15883 | Échec de l’insertion de la table mappée HBase dans Hive pour les colonnes binaires et des décimales |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | Les requêtes Phoenix retournent des valeurs Null en raison de lignes partielles HBase |
| BUG-94144 | HIVE-17063 | Échec de l’insertion d’une partition de remplacement sur une table externe quand la partition est supprimée en premier |
| BUG-94280 | HIVE-12785 | La vue avec type d’union et UDF pour « caster » la structure est endommagée |
| BUG-94505 | PHOENIX-4525 | Dépassement d’entier dans l’exécution GroupBy |
| BUG-95618 | HIVE-18506 | LlapBaseInputFormat - index de tableau négatif |
| BUG-95644 | HIVE-9152 | CombineHiveInputFormat : La requête Hive échoue dans Tez avec l’exception java.lang.IllegalArgumentException |
| BUG-96762 | PHOENIX-4588 | L’expression doit également être clonée si ses enfants ont Determinism.PER_INVOCATION |
| BUG-97145 | HIVE-12245, HIVE-17829 | Prise en charge des commentaires de colonne pour une table sauvegardée HBase |
| BUG-97741 | HIVE-18944 | La position des jeux de regroupement est définie de façon incorrecte pendant DPP |
| BUG-98082 | HIVE-18597 | LLAP : Création systématique du package du fichier jar de l’API log4j2 pour org.apache.log4j |
| BUG-99849 | N/A | La création d’une table à partir d’un Assistant de fichier essaie d’utiliser la base de données par défaut |
Sécurité
| ID du bogue | Apache JIRA | Résumé |
|---|---|---|
| BUG-100436 | RANGER-2060 | Proxy Knox avec knox-sso ne fonctionne pas pour ranger |
| BUG-101038 | SPARK-24062 | Interpréteur %Spark Zeppelin, erreur « Connexion refusée », erreur « Une clé secrète doit être spécifiée... » dans HiveThriftServer |
| BUG-101359 | ACCUMULO-4056 | Mise à jour de la version de commons-collection vers 3.2.2 lors de la publication |
| BUG-54240 | HIVE-18879 | L’interdiction de l’élément incorporé dans UDFXPathUtil doit fonctionner si xercesImpl.jar figure dans le classpath |
| BUG-79059 | OOZIE-3109 | Échappement de caractères spécifiques à HTML de streaming de journaux |
| BUG-90041 | OOZIE-2723 | La licence JSON.org est désormais CatX |
| BUG-93754 | RANGER-1943 | L’autorisation Ranger Solr est ignorée quand la collection est vide ou a la valeur Null |
| BUG-93804 | HIVE-17419 | La commande ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS affiche des statistiques calculées pour les tables masquées |
| BUG-94276 | ZEPPELIN-3129 | L’interface utilisateur Zeppelin ne se déconnecte pas dans Internet Explorer |
| BUG-95349 | ZOOKEEPER-1256, ZOOKEEPER-1901 | Mise à niveau de Netty |
| BUG-95483 | N/A | Correctif pour CVE-2017-15713 |
| BUG-95646 | OOZIE-3167 | Mise à niveau de la version tomcat sur Oozie branche 4.3 |
| BUG-95823 | N/A |
Knox : Mise à niveau de Beanutils |
| BUG-95908 | RANGER-1960 | L’authentification HBase ne prend pas en considération l’espace de noms de table pour la suppression de la capture instantanée |
| BUG-96191 | FALCON-2322, FALCON-2323 | Mise à niveau des versions Jackson et Spring pour éviter les failles de sécurité |
| BUG-96502 | RANGER-1990 | Ajout de la prise en charge SSL MySQL unidirectionnel dans Ranger Admin |
| BUG-96712 | FLUME-3194 | Mise à niveau de derby vers la version la plus récente (1.14.1.0) |
| BUG-96713 | FLUME-2678 | Mise à niveau de xalan vers 2.7.2 pour prendre en charge la faille CVE-2014-0107 |
| BUG-96714 | FLUME-2050 | Mise à niveau vers log4j2 (en cas de disponibilité générale) |
| BUG-96737 | N/A | Utilisation de méthodes de système de fichiers d’E/S Java pour accéder aux fichiers locaux |
| BUG-96925 | N/A | Mise à niveau de Tomcat de 6.0.48 vers 6.0.53 dans Hadoop |
| BUG-96977 | FLUME-3132 | Mise à niveau des dépendances de bibliothèque jasper tomcat |
| BUG-97022 | HADOOP-14799, HADOOP-14903, HADOOP-15265 | Mise à niveau de la bibliothèque Nimbus-JOSE-JWT avec la version supérieure à 4.39 |
| BUG-97101 | RANGER-1988 | Correction du caractère aléatoire non sécurisé |
| BUG-97178 | ATLAS-2467 | Mise à niveau de dépendance pour Spring et nimbus-jose-jwt |
| BUG-97180 | N/A | Mise à niveau de Nimbus-jose-jwt |
| BUG-98038 | HIVE-18788 | Nettoyage des entrées dans PreparedStatement JDBC |
| BUG-98353 | HADOOP-13707 | Rétablissement de « Si kerberos est activé alors que HTTP SPNEGO n’est pas configuré, certains liens ne sont pas accessibles » |
| BUG-98372 | HBASE-13848 | Accès aux mots de passe SSL InfoServer via l’API de fournisseur d’informations d’identification |
| BUG-98385 | ATLAS-2500 | Ajout d’autres en-têtes à la réponse Atlas. |
| BUG-98564 | HADOOP-14651 | Mise à jour de la version d’okhttp vers 2.7.5 |
| BUG-99440 | RANGER-2045 | Les colonnes de table Hive sans stratégie d’autorisation explicite sont répertoriées avec la commande 'desc table' |
| BUG-99803 | N/A | Oozie doit désactiver le chargement de classe dynamique HBase |
Stabilité
| ID du bogue | Apache JIRA | Résumé |
|---|---|---|
| BUG-100040 | ATLAS-2536 | NPE dans hook Hive Atlas |
| BUG-100057 | HIVE-19251 | ObjectStore.getNextNotification avec LIMIT doit utiliser moins de mémoire |
| BUG-100072 | HIVE-19130 | NPE est levée quand REPL LOAD a appliqué l’événement de suppression de partition. |
| BUG-100073 | N/A | Trop de connexions close_wait à partir du hiveserver vers le nœud de données |
| BUG-100319 | HIVE-19248 | REPL LOAD ne génère pas d’erreur en cas d’échec de copie de fichiers. |
| BUG-100352 | N/A | CLONE - Purge RM des analyses logiques /znode de registre trop fréquente |
| BUG-100427 | HIVE-19249 | Réplication : La clause WITH ne transmet pas la configuration à la tâche correctement dans tous les cas |
| BUG-100430 | HIVE-14483 | java.lang.ArrayIndexOutOfBoundsException org.apache.orc.impl.TreeReaderFactory$BytesColumnVectorUtil.commonReadByteArrays |
| BUG-100432 | HIVE-19219 | L’opération REPL DUMP incrémentielle doit générer une erreur si les événements demandés sont nettoyés. |
| BUG-100448 | SPARK-23637, SPARK-23802, SPARK-23809, SPARK-23816, SPARK-23822, SPARK-23823, SPARK-23838, SPARK-23881 | Mise à jour de Spark2 vers 2.3.0+ (11/4) |
| BUG-100740 | HIVE-16107 | JDBC : HttpClient doit réessayer une nouvelle fois sur NoHttpResponseException |
| BUG-100810 | HIVE-19054 | Échec de la réplication de fonctions Hive |
| BUG-100937 | MAPREDUCE-6889 | Ajout de l’API Job#close pour arrêter les services clients MR. |
| BUG-101065 | ATLAS-2587 | Définition d’ACL en lecture pour le znode /apache_atlas/active_server_info en haute disponibilité pour une lecture par le proxy Knox. |
| BUG-101093 | STORM-2993 | Le bolt Storm HDFS lève ClosedChannelException quand la stratégie de rotation Time est utilisée |
| BUG-101181 | N/A | PhoenixStorageHandler ne gère pas AND correctement dans le prédicat |
| BUG-101266 | PHOENIX-4635 | Fuite de connexion HBase dans org.apache.phoenix.hive.mapreduce.PhoenixInputFormat |
| BUG-101458 | HIVE-11464 | Informations de lignage manquantes s’il existe plusieurs sorties |
| BUG-101485 | N/A | L’API Thrift de metastore Hive est lente et provoque un délai d’attente client |
| BUG-101628 | HIVE-19331 | Échec de la réplication incrémentielle Hive vers le cloud. |
| BUG-102048 | HIVE-19381 | Échec de la réplication de fonctions Hive vers le cloud avec FunctionTask |
| BUG-102064 | N/A | Échec des tests de réplication \[ onprem to onprem \] Hive dans ReplCopyTask |
| BUG-102137 | HIVE-19423 | Échec des tests de réplication \[ Onprem to Cloud \] Hive dans ReplCopyTask |
| BUG-102305 | HIVE-19430 | Vidages des problèmes de mémoire insuffisante dans le metastore hive et HS2 |
| BUG-102361 | N/A | Plusieurs résultats insert dans un insert unique répliqué vers le cluster hive cible ( onprem - s3 ) |
| BUG-87624 | N/A | L’activation de la journalisation des événements storm entraîne la suppression continue des processus de travail |
| BUG-88929 | HBASE-15615 | Durée de veille incorrecte quand une nouvelle tentative est nécessaire pour RegionServerCallable |
| BUG-89628 | HIVE-17613 | Suppression des pools d’objets pour les allocations courtes sur le même thread |
| BUG-89813 | N/A | SCA : Exactitude du code : Une méthode non synchronisée remplace une méthode synchronisée |
| BUG-90437 | ZEPPELIN-3072 | L’interface utilisateur de Zeppelin ne répond plus ou ralentit s’il existe trop de blocs-notes |
| BUG-90640 | HBASE-19065 | HRegion#bulkLoadHFiles() doit attendre la fin de Region#flush() simultané. |
| BUG-91202 | HIVE-17013 | Suppression de la requête avec une sous-requête basée sur la sélection sur une vue |
| BUG-91350 | KNOX-1108 | Pas de basculement de NiFiHaDispatch |
| BUG-92054 | HIVE-13120 | Propagation de doAs lors de la génération de fractionnements ORC |
| BUG-92373 | FALCON-2314 | Transition de la version de TestNG vers 6.13.1 afin d’éviter la dépendance BeanShell |
| BUG-92381 | N/A | Échec de testContainerLogsWithNewAPI et testContainerLogsWithOldAPI UT |
| BUG-92389 | STORM-2841 | Échec de testNoAcksIfFlushFails UT avec NullPointerException |
| BUG-92586 | SPARK-17920, SPARK-20694, SPARK-21642, SPARK-22162, SPARK-22289, SPARK-22373, SPARK-22495, SPARK-22574, SPARK-22591, SPARK-22595, SPARK-22601, SPARK-22603, SPARK-22607, SPARK-22635, SPARK-22637, SPARK-22653, SPARK-22654, SPARK-22686, SPARK-22688, SPARK-22817, SPARK-22862, SPARK-22889, SPARK-22972, SPARK-22975, SPARK-22982, SPARK-22983, SPARK-22984, SPARK-23001, SPARK-23038, SPARK-23095 | Mise à jour de Spark2 vers 2.2.1 (16 janvier) |
| BUG-92680 | ATLAS-2288 | Exception NoClassDefFoundError pendant l’exécution du script import-hive lors de la création de la table hbase via Hive |
| BUG-92760 | ACCUMULO-4578 | L’opération FATE d’annulation du compactage ne libère pas de verrou d’espace de noms |
| BUG-92797 | HDFS-10267, HDFS-8496 | Réduction des conflits de verrou DataNode dans certains cas d’utilisation |
| BUG-92813 | FLUME-2973 | Interblocage dans le récepteur hdfs |
| BUG-92957 | HIVE-11266 | Résultat incorrect de count(*) basé sur les statistiques de table pour les tables externes |
| BUG-93018 | ATLAS-2310 | En haute disponibilité, le nœud passif redirige la requête avec un encodage d’URL incorrect |
| BUG-93116 | RANGER-1957 | Ranger Usersync ne synchronise pas les utilisateurs ni groupes régulièrement quand la synchronisation incrémentielle est activée. |
| BUG-93361 | HIVE-12360 | Recherche incorrecte dans ORC non compressé avec pushdown de prédicat |
| BUG-93426 | CALCITE-2086 | HTTP/413 dans certaines circonstances en raison des en-têtes d’autorisation volumineux |
| BUG-93429 | PHOENIX-3240 | ClassCastException à partir du chargeur Pig |
| BUG-93485 | N/A | Impossible d’obtenir l’exception mytestorg.apache.hadoop.hive.ql.metadata.InvalidTableException de table : Table introuvable lors de l’exécution de l’analyse de table sur les colonnes dans LLAP |
| BUG-93512 | PHOENIX-4466 | java.lang.RuntimeException : code de réponse 500. Exécution d’un travail Spark pour se connecter à Phoenix Query Server et charger des données |
| BUG-93550 | N/A | Zeppelin %spark.r ne fonctionne pas avec spark1 en raison d’une incompatibilité de version de scala |
| BUG-93910 | HIVE-18293 | Hive ne parvient pas à compacter les tables contenues dans un dossier qui n’appartient pas à l’identité exécutant HiveMetaStore |
| BUG-93926 | ZEPPELIN-3114 | Les notebooks et interpréteurs ne sont pas enregistrés dans zeppelin après >des tests de stress 1d |
| BUG-93932 | ATLAS-2320 | La classification « * » avec la requête lève l’exception de serveur interne 500. |
| BUG-93948 | YARN-7697 | NM rencontre un problème de mémoire insuffisante en raison d’une fuite dans l’agrégation de journaux (partie#1) |
| BUG-93965 | ATLAS-2229 | Recherche DSL : Un attribut qui n’est pas une chaîne orderby lève une exception |
| BUG-93986 | YARN-7697 | NM rencontre un problème de mémoire insuffisante en raison d’une fuite dans l’agrégation de journaux (partie#2) |
| BUG-94030 | ATLAS-2332 | Échec de la création du type avec des attributs ayant un type de données de collection imbriquée |
| BUG-94080 | YARN-3742, YARN-6061 | Les deux RM sont en veille dans un cluster sécurisé |
| BUG-94081 | HIVE-18384 | ConcurrentModificationException dans la bibliothèque log4j2.x |
| BUG-94168 | N/A | Yarn RM tombe en panne avec une erreur indiquant que le Registre de service est en mauvais état |
| BUG-94330 | HADOOP-13190, HADOOP-14104, HADOOP-14814, HDFS-10489, HDFS-11689 | HDFS doit prendre en charge plusieurs KMS Uris |
| BUG-94345 | HIVE-18429 | Le compactage doit faire face à l’éventualité où il ne produit aucune sortie |
| BUG-94372 | ATLAS-2229 | Requête DSL : hive_table name = ["t1","t2"] lève une exception de requête DSL non valide |
| BUG-94381 | HADOOP-13227, HDFS-13054 | Gestion de l’ordre RetryAction RequestHedgingProxyProvider : FAIL < RETRY < FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | CompactorMR doit appeler jobclient.close() pour déclencher le nettoyage |
| BUG-94575 | SPARK-22587 | Échec du travail Spark si fs.defaultFS et le fichier jar d’application sont des URL différentes |
| BUG-94791 | SPARK-22793 | Fuite de mémoire dans le serveur Spark Thrift |
| BUG-94928 | HDFS-11078 | Correction de NPE dans LazyPersistFileScrubber |
| BUG-95013 | HIVE-18488 | Il manque des contrôles de valeur null aux lecteurs ORC LLAP |
| BUG-95077 | HIVE-14205 | Hive ne prend pas en charge le type d’union avec le format de fichier AVRO |
| BUG-95200 | HDFS-13061 | SaslDataTransferClient#checkTrustAndSend ne doit pas approuver un canal partiellement fiable |
| BUG-95201 | HDFS-13060 | Ajout d’un BlacklistBasedTrustedChannelResolver pour TrustedChannelResolver |
| BUG-95284 | HBASE-19395 | [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting échoue avec NPE |
| BUG-95301 | HIVE-18517 | Vectorisation : Correction de VectorMapOperator pour accepter des VRB et vérifier l’indicateur vectorisé correctement pour prendre en charge la mise en cache LLAP |
| BUG-95542 | HBASE-16135 | PeerClusterZnode sous rs du pair supprimé peut ne jamais être supprimé |
| BUG-95595 | HIVE-15563 | L’exception de transition d’état d’opération non conforme doit être ignorée dans SQLOperation.runQuery pour exposer l’exception réelle. |
| BUG-95596 | YARN-4126, YARN-5750 | TestClientRMService échoue |
| BUG-96019 | HIVE-18548 | Correction de l’importation log4j |
| BUG-96196 | HDFS-13120 | La diff de capture instantanée peut être endommagée après la concaténation |
| BUG-96289 | HDFS-11701 | NPE à partir de l’hôte non résolu provoque des échecs DFSInputStream permanents |
| BUG-96291 | STORM-2652 | Exception levée dans la méthode Open JmsSpout |
| BUG-96363 | HIVE-18959 | La création d’un pool de threads supplémentaire dans LLAP doit être évitée |
| BUG-96390 | HDFS-10453 | Le thread ReplicationMonitor pourrait être bloqué longtemps en raison de la concurrence entre la réplication et la suppression du même fichier dans un grand cluster. |
| BUG-96454 | YARN-4593 | Interblocage dans AbstractService.getConfig() |
| BUG-96704 | FALCON-2322 | ClassCastException lors du flux submitAndSchedule |
| BUG-96720 | SLIDER-1262 | Les tests de fonction Slider échouent dans un environnement Kerberized |
| BUG-96931 | SPARK-23053, SPARK-23186, SPARK-23230, SPARK-23358, SPARK-23376, SPARK-23391 | Mise à jour de Spark2 (19 février) |
| BUG-97067 | HIVE-10697 | ObjectInspectorConvertors#UnionConvertor effectue une conversion défectueuse. |
| BUG-97244 | KNOX-1083 | Le délai d’expiration par défaut de HttpClient doit être une valeur raisonnable |
| BUG-97459 | ZEPPELIN-3271 | Option de désactivation du planificateur |
| BUG-97511 | KNOX-1197 | AnonymousAuthFilter n’est pas ajouté quand authentication=Anonymous en service |
| BUG-97601 | HIVE-17479 | Les répertoires intermédiaires ne sont pas nettoyés pour les requêtes de mise à jour/suppression |
| BUG-97605 | HIVE-18858 | Propriétés système dans la configuration du travail non résolues lors de l’envoi du travail MR |
| BUG-97674 | OOZIE-3186 | Oozie ne peut pas utiliser de configuration liée à l’aide de jceks://file/... |
| BUG-97743 | N/A | Exception java.lang.NoClassDefFoundError lors du déploiement de topologie storm |
| BUG-97756 | PHOENIX-4576 | Correction des tests LocalIndexSplitMergeIT en échec |
| BUG-97771 | HDFS-11711 | Le nom de domaine ne doit pas supprimer le bloc selon l’exception « Trop de fichiers ouverts » |
| BUG-97869 | KNOX-1190 | La prise en charge de l’authentification unique Knox pour Google OIDC est interrompue. |
| BUG-97879 | PHOENIX-4489 | Perte de connexion HBase dans les travaux Phoenix MR |
| BUG-98392 | RANGER-2007 | Échec du renouvellement du ticket Kerberos de ranger-tagsync |
| BUG-98484 | N/A | La réplication incrémentielle Hive vers le cloud ne fonctionne pas |
| BUG-98533 | HBASE-19934, HBASE-20008 | La restauration de capture instantanée HBase échoue en raison d’une exception de pointeur Null |
| BUG-98555 | PHOENIX-4662 | NullPointerException dans TableResultIterator.java sur le renvoi de cache |
| BUG-98579 | HBASE-13716 | Arrêt de l’utilisation des FSConstants de Hadoop |
| BUG-98705 | KNOX-1230 | Plusieurs demandes simultanées à Knox entraînent l’altération des URL |
| BUG-98983 | KNOX-1108 | Pas de basculement de NiFiHaDispatch |
| BUG-99107 | HIVE-19054 | La réplication de fonction doit utiliser « hive.repl.replica.functions.root.dir » en tant que racine |
| BUG-99145 | RANGER-2035 | Erreurs d’accès aux servicedefs avec implClass vide et le backend Oracle |
| BUG-99160 | SLIDER-1259 | Slider ne fonctionne pas dans les environnements multirésidents |
| BUG-99239 | ATLAS-2462 | L’importation de Sqoop pour toutes les tables lève NPE si aucune table n’est fournie dans la commande |
| BUG-99301 | ATLAS-2530 | Nouvelle ligne au début de l’attribut de nom de hive_process et hive_column_lineage |
| BUG-99453 | HIVE-19065 | La vérification de la compatibilité du client de metastore doit inclure syncMetaStoreClient |
| BUG-99521 | N/A | ServerCache pour HashJoin n’est pas recréé quand les itérateurs sont réinstanciés |
| BUG-99590 | PHOENIX-3518 | Fuite de mémoire dans RenewLeaseTask |
| BUG-99618 | SPARK-23599, SPARK-23806 | Mise à jour de Spark2 vers 2.3.0+ (28/3) |
| BUG-99672 | ATLAS-2524 | Hook Hive avec notifications V2 : gestion incorrecte de l’opération 'alter view as' |
| BUG-99809 | HBASE-20375 | Suppression de l’utilisation de getCurrentUserCredentials dans le module hbase-spark |
Prise en charge
| ID du bogue | Apache JIRA | Résumé |
|---|---|---|
| BUG-87343 | HIVE-18031 | Prise en charge de la réplication pour l’opération Alter Database. |
| BUG-91293 | RANGER-2060 | Proxy Knox avec knox-sso ne fonctionne pas pour ranger |
| BUG-93116 | RANGER-1957 | Ranger Usersync ne synchronise pas les utilisateurs ni groupes régulièrement quand la synchronisation incrémentielle est activée. |
| BUG-93577 | RANGER-1938 | Solr pour la configuration de l’audit n’utilise pas efficacement les DocValues |
| BUG-96082 | RANGER-1982 | Amélioration de la gestion des erreurs pour les métriques d’analytique de Ranger Admin et Ranger Kms |
| BUG-96479 | HDFS-12781 | Après l’arrêt de Datanode, l’onglet In Namenode UI Datanode lève un message d’avertissement. |
| BUG-97864 | HIVE-18833 | Échec de fusion automatique quand « insertion dans le répertoire comme orcfile » |
| BUG-98814 | HDFS-13314 | NameNode doit éventuellement s’arrêter en cas de détection d’une altération de FsImage |
Mettre à niveau
| ID du bogue | Apache JIRA | Résumé |
|---|---|---|
| BUG-100134 | SPARK-22919 | Rétablissement de « Transition des versions httpclient d’Apache » |
| BUG-95823 | N/A |
Knox : Mise à niveau de Beanutils |
| BUG-96751 | KNOX-1076 | Mise à jour de nimbus-jose-jwt vers 4.41.2 |
| BUG-97864 | HIVE-18833 | Échec de fusion automatique quand « insertion dans le répertoire comme orcfile » |
| BUG-99056 | HADOOP-13556 | Modification de Configuration.getPropsWithPrefix pour utiliser getProps au lieu de l’itérateur |
| BUG-99378 | ATLAS-2461, ATLAS-2554 | Utilitaire de migration pour exporter des données Atlas dans la base de données graphique Titan |
Usage
| ID du bogue | Apache JIRA | Résumé |
|---|---|---|
| BUG-100045 | HIVE-19056 | IllegalArgumentException dans FixAcidKeyIndex quand le fichier ORC contient 0 ligne |
| BUG-100139 | KNOX-1243 | Normalisation des noms de domaine nécessaires qui sont configurés dans le service KnoxToken |
| BUG-100570 | ATLAS-2557 | Correctif permettant de lookup des groupes hadoop ldap quand les groupes provenant d’UGI sont mal définis ou ne sont pas vides |
| BUG-100646 | ATLAS-2102 | Améliorations apportées à l’interface utilisateur d’Atlas : Page de résultats de recherche |
| BUG-100737 | HIVE-19049 | Ajout de la prise en charge de l’ajout de colonnes dans une instruction ALTER TABLE pour Druid |
| BUG-100750 | KNOX-1246 | Mise à jour de la configuration de service dans Knox pour prendre en charge les dernières configurations pour Ranger. |
| BUG-100965 | ATLAS-2581 | Régression avec notifications de hook Hive V2 : Déplacement de table vers une autre base de données |
| BUG-84413 | ATLAS-1964 | Interface utilisateur : Prise en charge du tri de colonnes dans la table de recherche |
| BUG-90570 | HDFS-11384, HDFS-12347 | Ajout d’une option pour que l’équilibreur répartisse les appels getBlocks afin d’éviter le pic rpc.CallQueueLength de NameNode |
| BUG-90584 | HBASE-19052 | FixedFileTrailer doit reconnaître la classe CellComparatorImpl dans branch-1.x |
| BUG-90979 | KNOX-1224 | Proxy KnoxHADispatcher pour prendre en charge Atlas en haute disponibilité. |
| BUG-91293 | RANGER-2060 | Proxy Knox avec l’authentification unique knox ne fonctionne pas pour ranger |
| BUG-92236 | ATLAS-2281 | Enregistrement des requêtes de filtre d’attribut Balise/Type avec des filtres Null/Non Null. |
| BUG-92238 | ATLAS-2282 | La recherche favorite enregistrée s’affiche uniquement lors de l’actualisation après la création quand il existe plus de 25 recherches favorites. |
| BUG-92333 | ATLAS-2286 | Le type prédéfini « kafka_topic » ne doit pas déclarer l’attribut « topic » comme unique |
| BUG-92678 | ATLAS-2276 | La valeur de chemin pour l’entité de type hdfs_path est définie en minuscules à partir de hive-bridge. |
| BUG-93097 | RANGER-1944 | Le filtre d’action pour l’audit administratif ne fonctionne pas |
| BUG-93135 | HIVE-15874, HIVE-18189 | La requête Hive retourne des résultats incorrects quand hive.groupby.orderby.position.alias a la valeur true |
| BUG-93136 | HIVE-18189 | L’ordre selon la position ne fonctionne pas quand cbo est désactivé |
| BUG-93387 | HIVE-17600 | enforceBufferSize d’OrcFile doit être paramétrable par l’utilisateur. |
| BUG-93495 | RANGER-1937 | Ranger tagsync doit traiter la notification ENTITY_CREATE pour prendre en charge la fonctionnalité d’importation Atlas |
| BUG-93512 | PHOENIX-4466 | java.lang.RuntimeException : code de réponse 500. Exécution d’un travail Spark pour se connecter à Phoenix Query Server et charger des données |
| BUG-93801 | HBASE-19393 | HTTP 413 FULL HEAD lors de l’accès à l’interface utilisateur de HBase à l’aide de SSL. |
| BUG-93804 | HIVE-17419 | La commande ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS affiche des statistiques calculées pour les tables masquées |
| BUG-93932 | ATLAS-2320 | La classification « * » avec la requête lève l’exception de serveur interne 500. |
| BUG-93933 | ATLAS-2286 | Le type prédéfini « kafka_topic » ne doit pas déclarer l’attribut « topic » comme unique |
| BUG-93938 | ATLAS-2283, ATLAS-2295 | Mises à jour de l’interface utilisateur pour les classifications |
| BUG-93941 | ATLAS-2296, ATLAS-2307 | Amélioration de la recherche de base pour exclure éventuellement les entités de sous-type et les types de classification secondaire |
| BUG-93944 | ATLAS-2318 | Interface utilisateur : En cliquant à deux reprises sur la balise enfant, la balise parente est sélectionnée |
| BUG-93946 | ATLAS-2319 | Interface utilisateur : La suppression d’une balise située au-delà de la 25è position dans la liste des balises à la fois dans la structure plate et dans l’arborescence nécessite une actualisation. |
| BUG-93977 | HIVE-16232 | Prise en charge du calcul de statistiques pour les colonnes dans QuotedIdentifier |
| BUG-94030 | ATLAS-2332 | Échec de la création du type avec des attributs ayant un type de données de collection imbriquée |
| BUG-94099 | ATLAS-2352 | Le serveur Atlas doit fournir la configuration afin de spécifier la validité pour Kerberos DelegationToken |
| BUG-94280 | HIVE-12785 | La vue avec type d’union et UDF pour « caster » la structure est endommagée |
| BUG-94332 | SQOOP-2930 | L’exécution du travail Sqoop ne remplace pas les propriétés génériques du travail enregistrées |
| BUG-94428 | N/A | Prise en charge Knox de l’API REST Dataplane Profiler Agent |
| BUG-94514 | ATLAS-2339 | Interface utilisateur : La modification de « columns » dans l’affichage du résultat de recherche de base affecte également DSL. |
| BUG-94515 | ATLAS-2169 | La demande de suppression échoue quand la suppression définitive est configurée |
| BUG-94518 | ATLAS-2329 | L’interface utilisateur d’Atlas « Multiple Hovers » s’affiche si l’utilisateur clique sur une autre balise qui est incorrecte |
| BUG-94519 | ATLAS-2272 | Enregistrement de l’état des colonnes déplacées à l’aide de l’API d’enregistrement de la recherche. |
| BUG-94627 | HIVE-17731 | Ajout d’une option de compat descendante pour les utilisateurs externes à HIVE-11985 |
| BUG-94786 | HIVE-6091 | Des fichiers pipeout vides sont créés pour créer/fermer la connexion |
| BUG-94793 | HIVE-14013 | La table Describe n’affiche pas correctement unicode |
| BUG-94900 | OOZIE-2606, OOZIE-2658, OOZIE-2787, OOZIE-2802 | Définition de spark.yarn.jars pour corriger Spark 2.0 avec Oozie |
| BUG-94901 | HBASE-19285 | Ajout des histogrammes de latence par table |
| BUG-94908 | ATLAS-1921 | Interface utilisateur : Recherche à l’aide d’attributs d’entité et de caractéristique : L’interface utilisateur n’effectue pas de contrôle de plage et autorise l’indication de valeurs en dehors des limites pour les types de données intégraux et float. |
| BUG-95086 | RANGER-1953 | Amélioration du référencement de page de groupe d’utilisateurs |
| BUG-95193 | SLIDER-1252 | L’agent Slider échoue avec des erreurs de validation SSL avec Python 2.7.5-58 |
| BUG-95314 | YARN-7699 | queueUsagePercentage arrive sous forme d’INF pour l’appel d’API REST getApp |
| BUG-95315 | HBASE-13947, HBASE-14517, HBASE-17931 | Affectation de tables système à des serveurs avec la version la plus récente |
| BUG-95392 | ATLAS-2421 | Mises à jour des notifications pour prendre en charge les structures de données V2 |
| BUG-95476 | RANGER-1966 | L’initialisation du moteur de stratégie ne crée pas d’enrichisseurs de contexte dans certains cas |
| BUG-95512 | HIVE-18467 | Prise en charge des événements de base de données vider/charger + créer/supprimer pour tout l’entrepôt |
| BUG-95593 | N/A | Extension des utilitaires de base de données Oozie pour prendre en charge la création de sharelibSpark2 |
| BUG-95595 | HIVE-15563 | L’exception de transition d’état d’opération non conforme doit être ignorée dans SQLOperation.runQuery pour exposer l’exception réelle. |
| BUG-95685 | ATLAS-2422 | Exportation : Prise en charge de l’exportation basée sur le type |
| BUG-95798 | PHOENIX-2714, PHOENIX-2724, PHOENIX-3023, PHOENIX-3040 | Ne pas utiliser d’indications pour l’exécution de requêtes en série |
| BUG-95969 | HIVE-16828, HIVE-17063, HIVE-18390 | Échec de la vue partitionnée avec FAILED : IndexOutOfBoundsException Index : 1, Size : 1 |
| BUG-96019 | HIVE-18548 | Correction de l’importation log4j |
| BUG-96288 | HBASE-14123, HBASE-14135, HBASE-17850 | Rétroportage de sauvegarde/restauration HBase 2.0 |
| BUG-96313 | KNOX-1119 | Le principal Pac4J OAuth/OpenID doit être configurable |
| BUG-96365 | ATLAS-2442 | L’utilisateur avec l’autorisation en lecture seule sur la ressource d’entité ne peut pas effectuer de recherche de base |
| BUG-96479 | HDFS-12781 | Après l’arrêt de Datanode, l’onglet In Namenode UI Datanode lève un message d’avertissement. |
| BUG-96502 | RANGER-1990 | Ajout de la prise en charge SSL MySQL unidirectionnel dans Ranger Admin |
| BUG-96718 | ATLAS-2439 | Mise à jour du hook Sqoop pour utiliser des notifications V2 |
| BUG-96748 | HIVE-18587 | Un événement d’insertion DML peut tenter de calculer une somme de contrôle sur les répertoires |
| BUG-96821 | HBASE-18212 | En mode autonome avec le système de fichiers local, HBase enregistre le message d’avertissement : Impossible d’appeler la méthode ’unbuffer’ dans la classe org.apache.hadoop.fs.FSDataInputStream |
| BUG-96847 | HIVE-18754 | REPL STATUS doit prendre en charge la clause 'with' |
| BUG-96873 | ATLAS-2443 | Capture des attributs d’entités nécessaires dans les messages DELETE sortants |
| BUG-96880 | SPARK-23230 | Quand hive.default.fileformat représente d’autres types de fichiers, la création de table textfile provoque une erreur serde |
| BUG-96911 | OOZIE-2571, OOZIE-2792, OOZIE-2799, OOZIE-2923 | Amélioration de l’analyse des options Spark |
| BUG-97100 | RANGER-1984 | Les enregistrements de journal d’audit HBase peuvent ne pas afficher toutes les étiquettes associées à une colonne sollicitée |
| BUG-97110 | PHOENIX-3789 | Exécution d’appels de maintenance d’index dans plusieurs régions dans postBatchMutateIndispensably |
| BUG-97145 | HIVE-12245, HIVE-17829 | Prise en charge des commentaires de colonne pour une table sauvegardée HBase |
| BUG-97409 | HADOOP-15255 | Prise en charge de la conversion des majuscules/minuscules pour les noms de groupe dans LdapGroupsMapping |
| BUG-97535 | HIVE-18710 | Extension d’inheritPerms à ACID dans Hive 2.X |
| BUG-97742 | OOZIE-1624 | Modèle d’exclusion pour les fichiers JAR de sharelib |
| BUG-97744 | PHOENIX-3994 | La priorité RPC de l’index dépend toujours de la propriété de fabrique de contrôleur dans hbase-site.xml |
| BUG-97787 | HIVE-18460 | Le compacteur ne transmet pas les propriétés des tables au writer Orc |
| BUG-97788 | HIVE-18613 | Extension de JsonSerDe pour prendre en charge le type BINARY |
| BUG-97899 | HIVE-18808 | Le compactage doit être plus solide en cas d’échec de la mise à jour des statistiques |
| BUG-98038 | HIVE-18788 | Nettoyage des entrées dans PreparedStatement JDBC |
| BUG-98383 | HIVE-18907 | Création d’un utilitaire pour résoudre le problème d’index de clé ACID depuis HIVE-18817 |
| BUG-98388 | RANGER-1828 | Bonne pratique de codage, ajout d’en-têtes supplémentaires dans ranger |
| BUG-98392 | RANGER-2007 | Échec du renouvellement du ticket Kerberos de ranger-tagsync |
| BUG-98533 | HBASE-19934, HBASE-20008 | La restauration de capture instantanée HBase échoue en raison d’une exception de pointeur Null |
| BUG-98552 | HBASE-18083, HBASE-18084 | Définition du nombre de threads du nettoyage de fichiers de petite/grande taille comme configurable dans HFileCleaner |
| BUG-98705 | KNOX-1230 | Plusieurs demandes simultanées à Knox entraînent l’altération des URL |
| BUG-98711 | N/A | NiFi Dispatch ne peut pas utiliser SSL bidirectionnel sans modifications de service.xml |
| BUG-98880 | OOZIE-3199 | La restriction de propriété système doit être configurable |
| BUG-98931 | ATLAS-2491 | Mise à jour du hook Hive pour utiliser des notifications Atlas v2 |
| BUG-98983 | KNOX-1108 | Pas de basculement de NiFiHaDispatch |
| BUG-99088 | ATLAS-2511 | Fourniture d’options permettant d’importer de manière sélective une base de données/des tables à partir de Hive dans Atlas |
| BUG-99154 | OOZIE-2844, OOZIE-2845, OOZIE-2858, OOZIE-2885 | Échec de la requête Spark avec l’exception « java.io.FileNotFoundException: hive-site.xml (autorisation refusée) » |
| BUG-99239 | ATLAS-2462 | L’importation de Sqoop pour toutes les tables lève NPE si aucune table n’est fournie dans la commande |
| BUG-99636 | KNOX-1238 | Correction des paramètres TrustStore personnalisés pour la passerelle |
| BUG-99650 | KNOX-1223 | Le proxy Knox de Zeppelin ne redirige pas /api/ticket comme prévu |
| BUG-99804 | OOZIE-2858 | HiveMain, ShellMain et SparkMain ne doivent pas remplacer les propriétés et fichiers de configuration localement |
| BUG-99805 | OOZIE-2885 | L’exécution d’actions Spark ne doit pas nécessiter Hive dans le classpath |
| BUG-99806 | OOZIE-2845 | Remplacement du code basé sur la réflexion qui définit la variable dans HiveConf |
| BUG-99807 | OOZIE-2844 | Augmentation de la stabilité des actions Oozie quand log4j.properties est manquant ou illisible |
| RMP-9995 | AMBARI-22222 | Basculement de Druid pour utiliser le répertoire /var/druid au lieu de /apps/druid sur le disque local |
Changements de comportement
| Composant Apache | Apache JIRA | Résumé | Détails |
|---|---|---|---|
| Spark 2.3 | N/A | Modifications décrites dans les notes de publication Apache Spark | - Il existe un document « Dépréciation » et un guide « Changement de comportement », https://spark.apache.org/releases/spark-release-2-3-0.html#deprecations - Pour la partie SQL, il existe un autre guide « Migration » détaillé (de 2.2 vers 2.3), https://spark.apache.org/docs/latest/sql-programming-guide.html#upgrading-from-spark-sql-22-to-23| |
| Spark | HIVE-12505 | Le travail Spark se termine correctement, mais il y a une erreur de quota de disque HDFS saturé |
Scénario : Exécution d’insert overwrite quand un quota est défini sur le dossier Corbeille de l’utilisateur qui exécute la commande. Comportement précédent : La tâche réussit même si elle ne parvient pas à déplacer les données vers la Corbeille. Le résultat peut contenir à tort certaines des données auparavant présentes dans la table. Nouveau comportement : En cas d’échec du déplacement vers le dossier Corbeille, les fichiers sont supprimés définitivement. |
| Kafka 1.0 | N/A | Modifications décrites dans les notes de publication Apache Spark | https://kafka.apache.org/10/documentation.html#upgrade_100_notable |
| Hive/ Ranger | Autre stratégie Ranger Hive nécessaire pour INSERT OVERWRITE |
Scénario : Autre stratégie Ranger Hive nécessaire pour INSERT OVERWRITE Comportement précédent : Les requêtes Hive INSERT OVERWRITE réussissent comme d’habitude. Nouveau comportement : Les requêtes Hive INSERT OVERWRITE échouent inopinément après la mise à niveau vers HDP-2.6.x avec l’erreur : Erreur lors de la compilation d’instruction : FAILED: HiveAccessControlException Autorisation refusée : l’utilisateur jdoe ne dispose pas de privilège WRITE sur /tmp/*(state=42000,code=40000) À compter de HDP-2.6.0, les requêtes Hive INSERT OVERWRITE nécessitent une stratégie d’URI Ranger pour permettre les opérations d’écriture, même si l’utilisateur dispose du privilège d’écriture accordé via la stratégie HDFS. Solution de contournement/Action attendue du client : 1. Créez une stratégie sous le dépôt Hive. 2. Dans la liste déroulante où vous voyez Base de données, sélectionnez URI. 3. Mettez à jour le chemin (exemple : /tmp/*) 4. Ajoutez les utilisateurs et le groupe, puis enregistrez. 5. Réessayez la requête Insert. |
|
| HDFS | N/A | HDFS doit prendre en charge plusieurs KMS Uris |
Comportement précédent : La propriété dfs.encryption.key.provider.uri a été utilisée pour configurer le chemin du fournisseur KMS. Nouveau comportement : La propriété dfs.encryption.key.provider.uri est maintenant dépréciée en faveur de hadoop.security.key.provider.path pour configurer le chemin du fournisseur KMS. |
| Zeppelin | ZEPPELIN-3271 | Option de désactivation du planificateur |
Composant concerné : Zeppelin-Server Comportement précédent : Dans les versions précédentes de Zeppelin, aucune option ne permettait de désactiver le planificateur. Nouveau comportement : Par défaut, les utilisateurs ne voient plus le planificateur, car il est désactivé par défaut. Solution de contournement/Action attendue du client : Si vous souhaitez activer le planificateur, vous devez ajouter azeppelin.notebook.cron.enable avec la valeur true sous le site zeppelin personnalisé dans les paramètres Zeppelin à partir d’Ambari. |
Problèmes connus
Intégration de HDInsight avec ADLS Gen 2 : il existe deux problèmes sur les clusters HDInsight ESP utilisant Azure Data Lake Storage Gen 2 avec les autorisations et répertoires d’utilisateurs :
Les répertoires de base pour les utilisateurs ne sont pas créés sur le nœud principal 1. Pour résoudre ce problème, créez les répertoires manuellement et affectez comme propriétaire le nom UPN de l’utilisateur correspondant.
Les autorisations sur le répertoire /hdp ne sont actuellement pas définies sur 751. Elles doivent être définies comme suit :
chmod 751 /hdp chmod –R 755 /hdp/apps
Spark 2.3
[SPARK-23523][SQL] Résultat incorrect provoqué par la règle OptimizeMetadataOnlyQuery
[SPARK-23406] Bogues dans les jointures réflexives entre flux
Les exemples de notebooks Spark ne sont pas disponibles quand Azure Data Lake Storage (Gen2) est le stockage par défaut du cluster.
Pack Sécurité Entreprise
- Le serveur Spark Thrift n’accepte pas les connexions à partir de clients ODBC.
Étapes de la solution de contournement :
- Attendez environ 15 minutes après la création du cluster.
- Vérifiez dans l’interface utilisateur de ranger l’existence de hivesampletable_policy.
- Redémarrez le service Spark. La connexion STS devrait maintenant fonctionner.
- Le serveur Spark Thrift n’accepte pas les connexions à partir de clients ODBC.
Étapes de la solution de contournement :
Solution de contournement pour l’échec de vérification du service Ranger
RANGER-1607 : Solution de contournement pour l’échec de vérification du service Ranger lors de la mise à niveau vers HDP 2.6.2 à partir de précédentes versions HDP.
Notes
Uniquement quand SSL est activé dans Ranger.
Ce problème survient quand vous tentez une mise à niveau vers HDP-2.6.1 à partir de précédentes versions HDP via Ambari. Ambari utilise un appel curl pour effectuer une vérification du service Ranger dans Ambari. Si la version du kit JDK utilisée par Ambari est JDK 1.7, l’appel curl échoue avec l’erreur ci-dessous :
curl: (35) error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failureLa raison de cette erreur est que la version de tomcat utilisée dans Ranger est Tomcat-7.0.7*. L’utilisation de JDK 1.7 est en conflit avec les chiffrements par défaut fournis dans Tomcat-7.0.7*.
Vous pouvez résoudre ce problème de deux manières :
Mettez à jour le kit JDK utilisé dans Ambari de JDK 1.7 vers JDK 1.8 (consultez la section Modifier la version du kit JDK dans le Guide de référence Ambari).
Si vous souhaitez continuer la prise en charge d’un environnement JDK 1.7 :
Ajoutez la propriété ranger.tomcat.ciphers à la section ranger-admin-site de votre configuration Ambari Ranger avec la valeur ci-dessous :
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Si votre environnement est configuré pour Ranger-KMS, ajoutez la propriété ranger.tomcat.ciphers à la section ranger-kms-site de votre configuration Ambari Ranger avec la valeur ci-dessous :
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Remarque
Les valeurs indiquées sont des exemples d’utilisation et peuvent ne pas être représentatives de votre environnement. Vérifiez que la façon dont vous définissez ces propriétés correspond à la configuration de votre environnement.
RangerUI : Échappement de texte de condition de stratégie entré dans le formulaire de stratégie
Composant concerné : Ranger
Description du problème
Si un utilisateur souhaite créer une stratégie avec des conditions de stratégie personnalisée et que le texte ou l’expression contient des caractères spéciaux, l’application de la stratégie ne sera pas possible. Avant d’enregistrer la stratégie dans la base de données, les caractères spéciaux sont convertis en ASCII.
Caractères spéciaux : & <> " ` '
Par exemple, la condition condition tags.attributes['type']='abc' est convertie en ce qui suit une fois que la stratégie est enregistrée.
tags.attds['dsds']='cssdfs'
Vous pouvez voir la condition de stratégie avec ces caractères en ouvrant la stratégie en mode édition.
Solution de contournement
Option no 1 : Créer/mettre à jour la stratégie via l’API REST Ranger
URL REST : http://<hôte>:6080/service/plugins/policies
Création de stratégie avec la condition de stratégie :
L’exemple suivant crée une stratégie avec des balises comme « tags-test » et l’affecte au groupe « public » avec la condition de stratégie astags.attr['type']=='abc' en sélectionnant toutes les autorisations de composant Hive comme select, update, create, drop, alter, index, lock, all.
Exemple :
curl -H "Content-Type: application/json" -X POST http://localhost:6080/service/plugins/policies -u admin:admin -d '{"policyType":"0","name":"P100","isEnabled":true,"isAuditEnabled":true,"description":"","resources":{"tag":{"values":["tags-test"],"isRecursive":"","isExcludes":false}},"policyItems":[{"groups":["public"],"conditions":[{"type":"accessed-after-expiry","values":[]},{"type":"tag-expression","values":["tags.attr['type']=='abc'"]}],"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}]}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"service":"tagdev"}'Mise à jour de stratégie existante avec la condition de stratégie :
L’exemple suivant met à jour une stratégie avec des balises comme « tags-test » et l’affecte au groupe « public » avec la condition de stratégie astags.attr['type']=='abc' en sélectionnant toutes les autorisations de composant Hive comme select, update, create, drop, alter, index, lock, all.
URL REST : http://<nom-hôte>:6080/service/plugins/policies/<policy-id>
Exemple :
curl -H "Content-Type: application/json" -X PUT http://localhost:6080/service/plugins/policies/18 -u admin:admin -d '{"id":18,"guid":"ea78a5ed-07a5-447a-978d-e636b0490a54","isEnabled":true,"createdBy":"Admin","updatedBy":"Admin","createTime":1490802077000,"updateTime":1490802077000,"version":1,"service":"tagdev","name":"P0101","policyType":0,"description":"","resourceSignature":"e5fdb911a25aa7f77af5a9546938d9ed","isAuditEnabled":true,"resources":{"tag":{"values":["tags"],"isExcludes":false,"isRecursive":false}},"policyItems":[{"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}],"users":[],"groups":["public"],"conditions":[{"type":"ip-range","values":["tags.attributes['type']=abc"]}],"delegateAdmin":false}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"dataMaskPolicyItems":[],"rowFilterPolicyItems":[]}'Option 2 : Appliquer les modifications JavaScript
Étapes pour mettre à jour le fichier JS :
Recherchez le fichier PermissionList.js sous /usr/hdp/current/ranger-admin
Recherchez la définition de la fonction renderPolicyCondtion (ligne numéro 404).
Supprimez la ligne suivante de cette fonction, c’est-à-dire sous la fonction d’affichage (ligne numéro 434)
val = _.escape(val);//Line No:460
Après avoir supprimé la ligne ci-dessus, l’interface utilisateur de Ranger vous permettra de créer des stratégies avec la condition de stratégie qui peut contenir des caractères spéciaux et l’évaluation de la stratégie sera réussie pour la même stratégie.
Intégration de HDInsight à ADLS Gen 2 : problème de répertoires utilisateur et d’autorisations avec les clusters ESP 1. Les répertoires de base pour les utilisateurs ne sont pas créés sur le nœud principal 1. La solution de contournement consiste à les créer manuellement et à affecter comme propriétaire le nom UPN de l’utilisateur correspondant. 2. Les autorisations sur /hdp ne sont actuellement pas définies sur 751. Cela doit être défini sur a. chmod 751 /hdp b. chmod –R 755 /hdp/apps
Dépréciation
Portail OMS : Nous avons supprimé le lien de la page des ressources HDInsight qui pointait vers le portail OMS. Les journaux Azure Monitor utilisaient initialement son propre portail appelé « portail OMS » pour gérer sa configuration et analyser les données collectées. Toutes les fonctionnalités accessibles depuis ce portail ont été déplacées vers le portail Azure où elles continueront d’être développées. HDInsight a déprécié la prise en charge du portail OMS. Les clients utiliseront l’intégration des journaux Azure Monitor HDInsight dans le portail Azure.
Spark 2.3 :Dépréciation de Spark 2.3.0
Mise à niveau
Toutes ces fonctionnalités sont disponibles dans HDInsight 3.6. Pour obtenir la dernière version de Spark, Kafka et R Server (Machine Learning Services), choisissez la version Spark, Kafka, ML Services quand vous créez un cluster HDInsight 3.6. Pour obtenir de l’aide pour ADLS, vous pouvez choisir le type de stockage ADLS comme option. Les clusters existants ne sont pas automatiquement mis à niveau vers ces versions.
Tous les nouveaux clusters créés après juin 2018 bénéficient automatiquement de plus de 1 000 correctifs de bogues sur tous les projets open source. Suivez ce guide pour connaître les bonnes pratiques concernant la mise à niveau vers une version plus récente de HDInsight.