Configurer des clusters dans HDInsight avec Apache Hadoop, Spark, Kafka et autres
Dans cet article, vous allez découvrir comment installer et configurer Apache Hadoop, Apache Spark, Apache Kafka, Interactive Query ou Apache HBase dans Azure HDInsight. Vous apprendrez également à personnaliser les clusters et à ajouter une couche de sécurité en les joignant à un domaine.
Un cluster Hadoop est constitué de plusieurs machines virtuelles (également appelées nœuds) destinées à assurer le traitement distribué des tâches. HDInsight gère les détails de la mise en œuvre de l’installation et de la configuration des nœuds individuels. Vous fournissez uniquement les informations de configuration générales.
Important
La facturation du cluster HDInsight démarre après la création du cluster et s’arrête à sa suppression. La facturation étant calculée au prorata par minute, veillez à toujours supprimer votre cluster lorsqu’il n’est plus utilisé. Apprenez comment supprimer un cluster.
Si vous utilisez plusieurs clusters ensemble, vous avez tout intérêt à créer un réseau virtuel. Si vous utilisez un cluster Spark, vous pouvez aussi utiliser le connecteur Hive Warehouse Connector. Pour plus d’informations, consultez Planifier un réseau virtuel pour Azure HDInsight et Intégrer Apache Spark et Apache Hive à Hive Warehouse Connector.
Méthodes de configuration du cluster
La table suivante présente les différentes méthodes que vous pouvez utiliser pour configurer un cluster HDInsight.
| Clusters créés avec | un navigateur Web | Ligne de commande | API REST | Kit SDK |
|---|---|---|---|---|
| Azure portal | ✅ | |||
| Azure Data Factory. | ✅ | ✅ | ✅ | ✅ |
| Azure CLI | ✅ | |||
| Azure PowerShell | ✅ | |||
| cURL | ✅ | ✅ | ||
| Modèles Microsoft Azure Resource Manager | ✅ |
Cet article vous guide à travers la configuration du portail Azure, où vous pouvez créer un cluster HDInsight.
Concepts de base
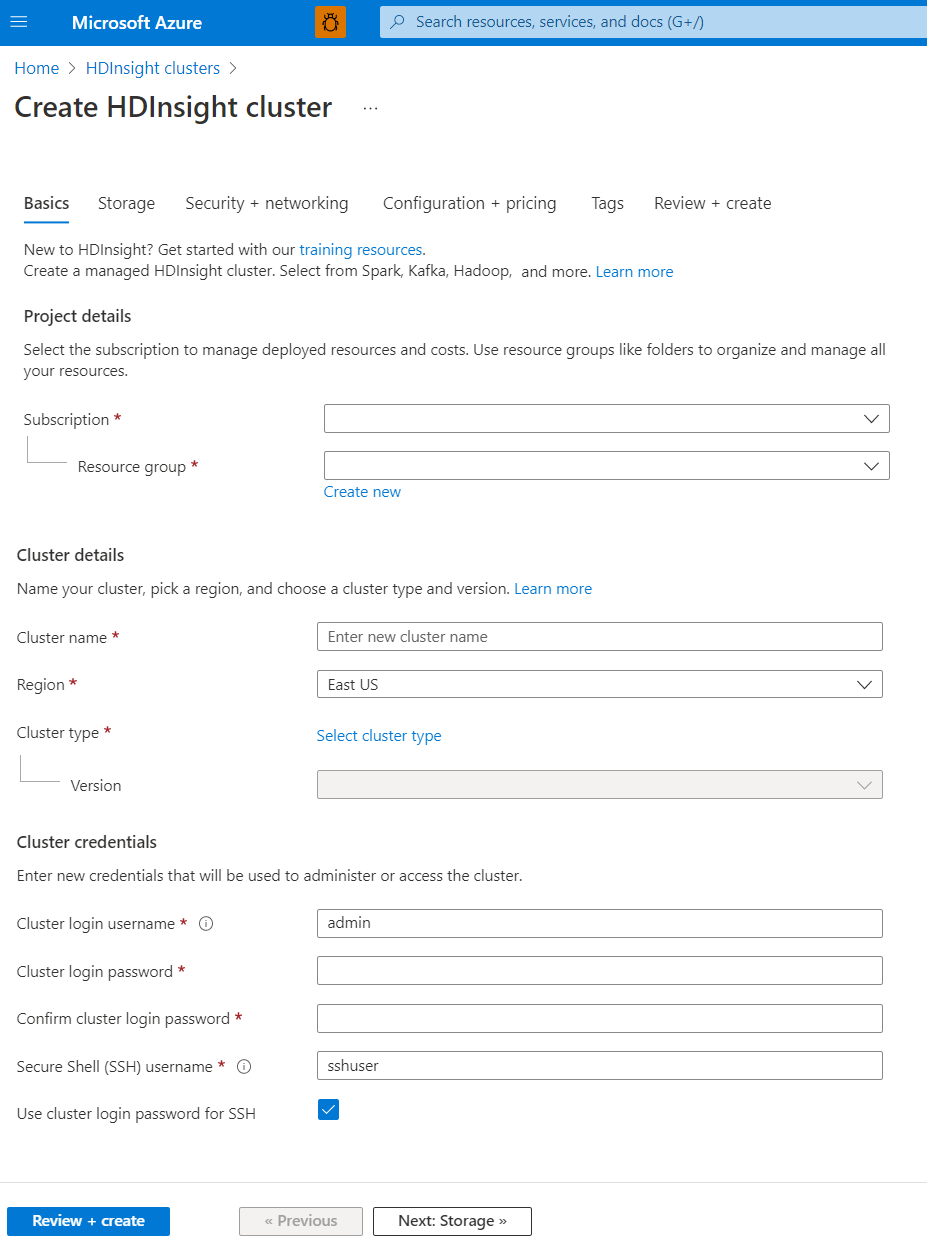
Détails du projet
Azure Resource Manager vous permet d’utiliser les ressources de votre application sous forme de groupe, qui est également appelé groupe de ressources Azure. Vous pouvez déployer, mettre à jour, surveiller ou supprimer toutes les ressources de votre application dans le cadre d’une opération unique et coordonnée.
Détails du cluster
Les détails du cluster comprennent le nom, la région, le type et la version.
Nom du cluster
Les noms des clusters HDInsight présentent les restrictions suivantes :
- Caractères autorisés : a-z, 0-9 et A-Z
- Longueur maximale : 59
- Noms réservés : apps
- Nommage de cluster : l’étendue porte sur l’intégralité d’Azure, pour tous les abonnements. Le nom du cluster doit être unique à l’échelon mondial. Les six premiers caractères doivent être uniques au sein d’un réseau virtuel.
Région
Vous n’avez pas besoin de spécifier explicitement l’emplacement du cluster. Le cluster se trouve au même emplacement que le stockage par défaut. Pour obtenir la liste des régions prises en charge, sélectionnez la liste déroulante Région dans Tarification HDInsight.
Type de cluster
Le tableau suivant présente les différents types de cluster actuellement disponibles avec HDInsight, chacun avec un ensemble de composants pour offrir certaines fonctionnalités.
Important
Les clusters HDInsight sont disponibles dans différents types, chacun d’eux pour une charge de travail ou une technologie unique. Il n’existe aucune méthode prise en charge qui permette de créer un cluster associant plusieurs types, comme HBase, sur un même cluster. Si votre solution nécessite des technologies qui sont réparties sur plusieurs types de clusters HDInsight, un réseau virtuel Azure peut connecter les types de cluster requis.
| Type de cluster | Fonctionnalités |
|---|---|
| Hadoop | Requête et analyse en mode batch des données stockées. |
| HBase | Traitement de grandes quantités de données NoSQL sans schéma. |
| Interactive Query | mise en cache pour des requêtes Hive interactives et plus rapides. |
| Kafka | Plateforme de diffusion en continu distribuée qui permet de créer des applications et des pipelines de données de diffusion en continu en temps réel. |
| Spark | Traitement en mémoire, requêtes interactives, traitement de flux par micro-lots. |
Version
Choisissez la version de HDInsight pour ce cluster. Pour plus d’informations, voir Versions de HDInsight prises en charge.
Informations d’identification du cluster
Les clusters HDInsight vous permettent de configurer deux comptes d’utilisateur lors de la création :
- Nom d’utilisateur de connexion du cluster : le nom d’utilisateur par défaut est admin. Il utilise la configuration de base sur le portail Azure. Il est également appelé utilisateur du cluster ou utilisateur HTTP.
- Nom d’utilisateur SSH (Secure Shell) : permet de se connecter au cluster via SSH. Pour en savoir plus, voir Utilisation de SSH avec Hadoop Linux sur HDInsight depuis Linux, Unix ou OS X.
Le nom d’utilisateur HTTP présente les restrictions suivantes :
- Caractères spéciaux autorisés : _ et @
- Caractères non autorisés : #;."',/:!*?$(){}[]<>|&--=+%~^espace
- Longueur maximale : 20
Le nom d’utilisateur SSH présente les restrictions suivantes :
- Caractères spéciaux autorisés : _ et @
- Caractères non autorisés : #;."',/:!*?$(){}[]<>|&--=+%~^espace
- Longueur maximale : 64
- Noms réservés : hadoop, users, oozie, hive, mapred, ambari-qa, zookeeper, tez, hdfs, sqoop, yarn, hcat, ams, hbase, administrator, admin, user, user1, test, user2, test1, user3, admin1, 1, 123, a, actuser, adm, admin2, aspnet, backup, console, David, guest, John, owner, root, server, sql, support, support_388945a0, sys, test2, test3, user4, user5, spark
Stockage
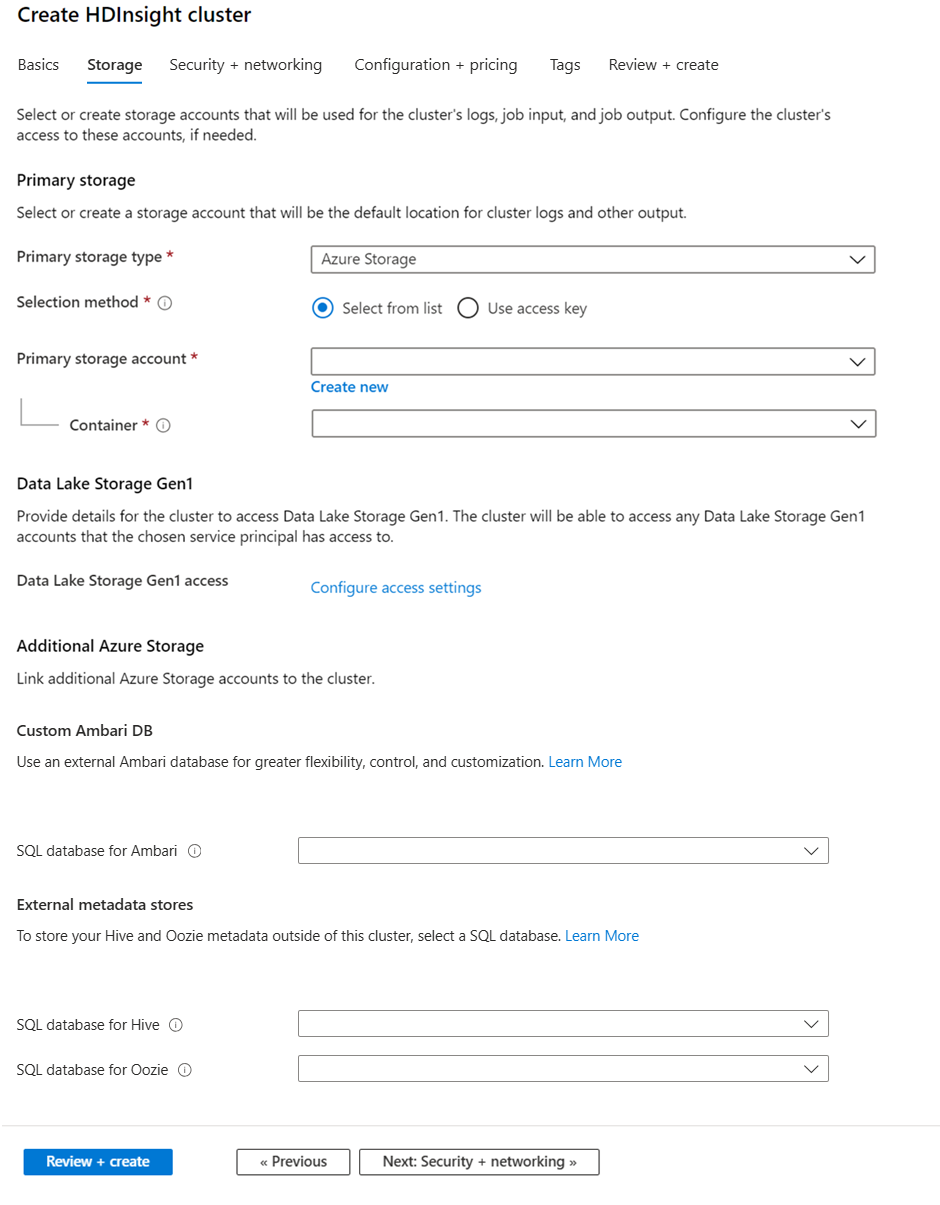
Même si, dans le cas d’une installation locale de Hadoop, le système de fichiers distribués Hadoop (HDFS) est utilisé pour le stockage sur le cluster, dans le cloud, vous utilisez les points de terminaison de stockage connectés au cluster. L’utilisation du stockage cloud signifie que vous pouvez supprimer sans risque les clusters HDInsight utilisés pour le calcul tout en conservant vos données.
Les clusters HDInsight peuvent utiliser les options de stockage suivantes :
- Azure Data Lake Storage Gen2
- Stockage Azure Usage général v2
- Objet blob de blocs Stockage Azure (pris en charge uniquement comme stockage secondaire)
Pour plus d’informations sur les options de stockage avec HDInsight, voir Comparer les options de stockage à utiliser avec les clusters Azure HDInsight.
L’utilisation de comptes de stockage supplémentaires à un emplacement différent de celui du cluster HDInsight n’est pas prise en charge.
Pendant la configuration, vous devez spécifier un conteneur blob de compte de stockage ou Data Lake Storage pour le point de terminaison de stockage par défaut. Le stockage par défaut contient les journaux des applications et du système. Vous pouvez éventuellement spécifier d’autres comptes de stockage et comptes Data Lake Storage liés auxquels le cluster peut accéder. Le cluster HDInsight et les comptes de stockage dépendants doivent être situés au même emplacement Azure.
Notes
La fonctionnalité qui exige un transfert sécurisé applique toutes les demandes à votre compte par le biais d’une connexion sécurisée. Seul un cluster HDInsight version 3.6 ou plus récente prend en charge cette fonctionnalité. Pour plus d’informations, consultez Créer un cluster Apache Hadoop à l’aide de comptes de stockage avec transfert sécurisé dans Azure HDInsight.
N’activez pas le transfert de stockage sécurisé après avoir créé un cluster, car l’utilisation de votre compte de stockage peut occasionner des erreurs. Il est préférable de créer un cluster avec un compte de stockage sur lequel le transfert sécurisé est déjà activé.
HDInsight n’assure pas le transfert, le déplacement ou la copie automatiques de vos données stockées dans le compte de stockage d’une région à une autre.
Paramètres du metastore
Vous pouvez créer des metastores Hive ou Apache Oozie facultatifs. Tous les types de clusters ne prennent pas en charge les metastores, et Azure Synapse Analytics n’est pas compatible avec les metastores.
Pour plus d’informations, consultez Utiliser des magasins de métadonnées externes dans Azure HDInsight.
Lorsque vous créez un metastore personnalisé, n’utilisez pas un nom de base de données contenant des traits d’union, des tirets ou des espaces. car la présence de ces caractères peut faire échouer le processus de création du cluster.
Base de données SQL pour Hive
Nous vous recommandons d’utiliser un metastore personnalisé si vous souhaitez conserver vos tables Hive après la suppression de votre cluster HDInsight. Vous pourrez joindre ce metastore à un autre cluster HDInsight.
Un metastore HDInsight créé pour une version de cluster HDInsight déterminée ne peut pas être partagé avec d’autres versions de cluster HDInsight. Pour obtenir la liste des versions de HDInsight, consultez la section Versions de HDInsight prises en charge.
Vous pouvez utiliser des identités managées pour vous authentifier auprès de la base de données SQL pour Hive. Si vous souhaitez en savoir plus, veuillez consulter Utiliser une identité managée pour l’authentification des bases de données SQL dans HDInsight.
Le metastore par défaut fournit une base de données SQL avec une limite de 5 DTU du niveau De base (sans mise à niveau possible). Il convient à des fins de tests élémentaires. Pour les charges de travail volumineuses ou de production, nous vous recommandons de migrer vers un metastore externe.
Base de données SQL pour Oozie
Pour accroître le niveau de performance lorsque vous utilisez Oozie, utilisez un metastore personnalisé. Un metastore permet également d’accéder aux données de travail Oozie après la suppression de votre cluster.
Vous pouvez utiliser des identités managées pour vous authentifier auprès de la base de données SQL pour Oozie. Si vous souhaitez en savoir plus, veuillez consulter Utiliser une identité managée pour l’authentification des bases de données SQL dans HDInsight.
Base de données SQL pour Ambari
Ambari permet de surveiller les clusters HDInsight, d’apporter des modifications à la configuration et de stocker des informations de gestion de cluster et l’historique des travaux. Avec la fonctionnalité de base de données Ambari personnalisée, vous pouvez déployer un nouveau cluster et configurer Ambari dans une base de données externe que vous gérez. Si vous souhaitez en savoir plus, veuillez consulter Base de données Ambari personnalisée.
Vous pouvez utiliser des identités managées pour vous authentifier auprès de la base de données SQL pour Ambari. Si vous souhaitez en savoir plus, veuillez consulter Utiliser une identité managée pour l’authentification des bases de données SQL dans HDInsight.
Vous ne pouvez pas réutiliser un metastore Oozie personnalisé. Pour utiliser un metastore Oozie personnalisé, vous devez fournir une base de données SQL vide au moment de créer le cluster HDInsight.
Sécurité + mise en réseau
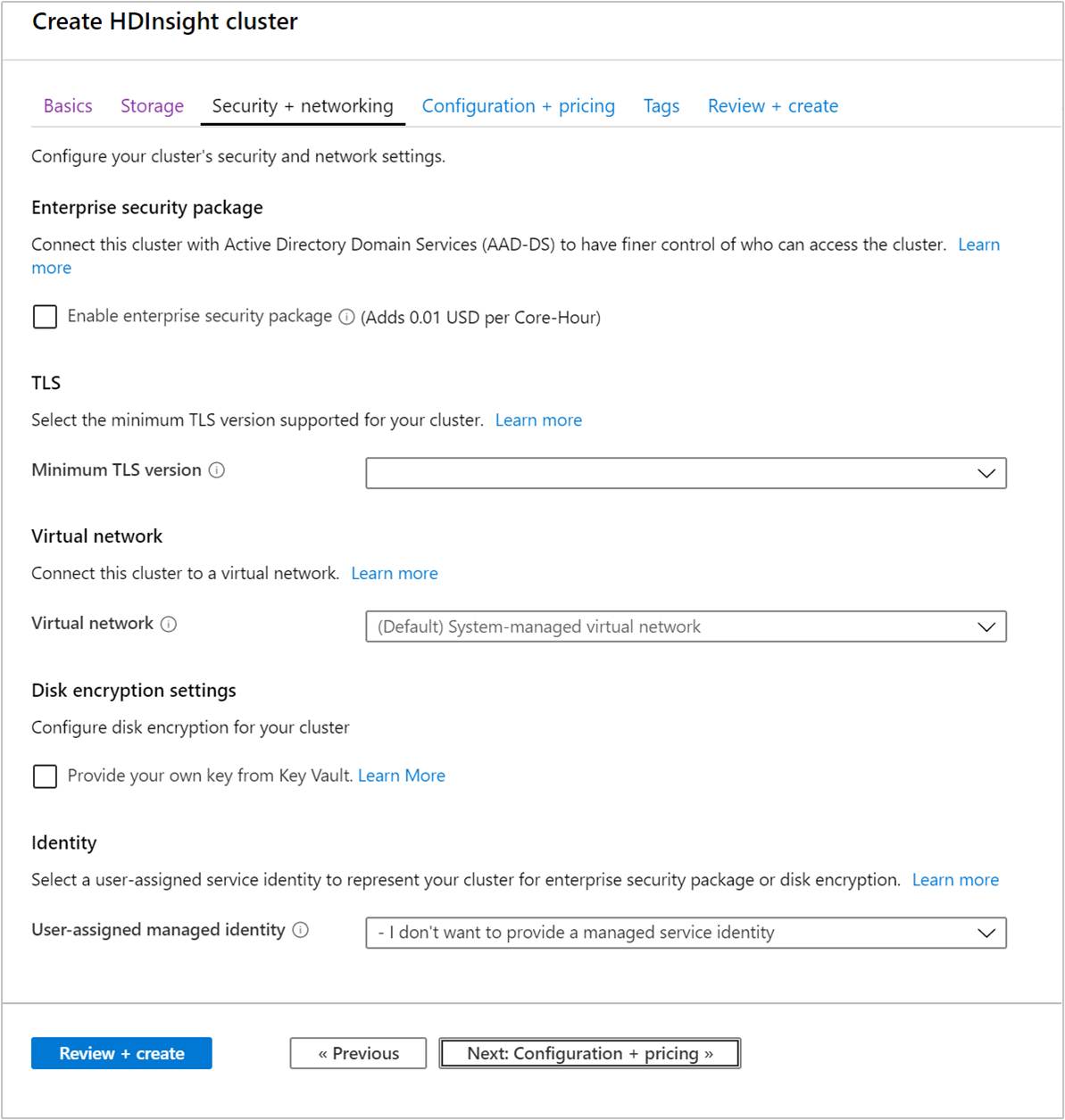
Package de sécurité d’entreprise
Pour les types de cluster Hadoop, Spark, HBase, Kafka et Interactive Query, vous pouvez choisir d’activer le Pack Sécurité Entreprise. Ce pack vous permet de bénéficier d’une installation de cluster mieux sécurisée en utilisant Apache Ranger et en opérant une intégration à Microsoft Entra. Pour plus d’informations, consultez Vue d’ensemble de la sécurité d’entreprise dans Azure HDInsight.
Avec le Pack Sécurité Entreprise, vous pouvez intégrer HDInsight à Microsoft Entra et Apache Ranger. Vous pouvez vous servir du Pack Sécurité Entreprise pour créer plusieurs utilisateurs.
Si vous souhaitez en savoir plus sur la création d’un cluster HDInsight joint au domaine, veuillez consulter Créer un environnement de bac à sable HDInsight joint à un domaine.
Protocole Transport Layer Security (TLS)
Pour plus d’informations, consultez TLS.
Réseau virtuel
Si votre solution nécessite des technologies qui sont réparties sur plusieurs types de clusters HDInsight, un réseau virtuel Azure peut connecter les types de cluster requis. Cette configuration permet aux clusters, et au code déployé sur ces clusters, de communiquer directement entre eux.
Pour plus d’informations sur l’utilisation d’un réseau virtuel Azure avec HDInsight, consultez Planifier un réseau virtuel pour HDInsight.
Pour voir un exemple d’utilisation de deux types de clusters au sein d’un réseau virtuel Azure, consultez Utiliser Apache Spark Structured Streaming avec Kafka. Pour plus d’informations sur l’utilisation de HDInsight avec un réseau virtuel, notamment la configuration spécifique requise pour le réseau virtuel, consultez Planifier un réseau virtuel pour HDInsight.
Paramètres de chiffrement des disques
Pour plus d’informations, consultez Chiffrement de disque avec clé gérée par le client.
Proxy REST Kafka
Ce paramètre est disponible uniquement pour le type de cluster Kafka. Pour plus d’informations, consultez Utilisation d’un proxy REST.
Identité
Pour plus d’informations, consultez Identités managées dans Azure HDInsight.
Configuration + prix
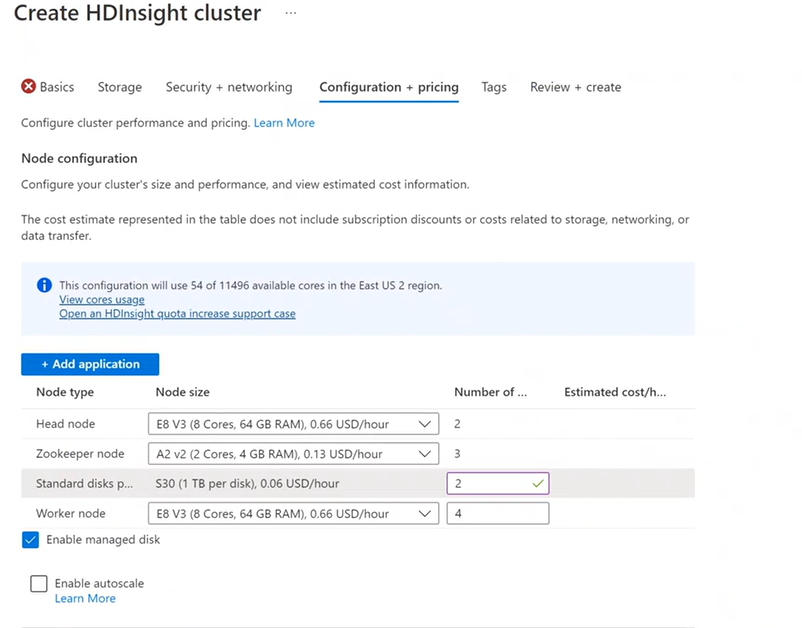
Vous êtes facturé pour l’utilisation du nœud tant que le cluster existe. La facturation démarre une fois le cluster créé et ne s’arrête que lorsque le cluster est supprimé. Les clusters ne peuvent pas être libérés ou mis en attente.
Configuration de nœuds
Chaque type de cluster possède son propre nombre de nœuds, sa terminologie pour les nœuds et la taille de machine virtuelle par défaut. Dans le tableau suivant, le nombre de nœuds pour chaque type de nœud est indiqué entre parenthèses.
| Type | Nœuds | Diagramme |
|---|---|---|
| Hadoop | Nœud principal (2), nœud Worker (1+) |
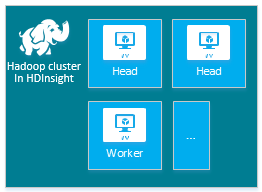
|
| hbase | Serveur principal (2), serveur de région (1+), nœud principal/ZooKeeper (3) |
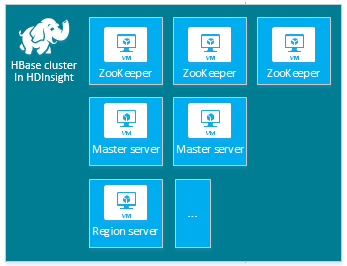
|
| Spark | Nœud principal (2), nœud Worker (1+), nœud ZooKeeper (3) (gratuits pour les machines virtuelles ZooKeeper A1) |
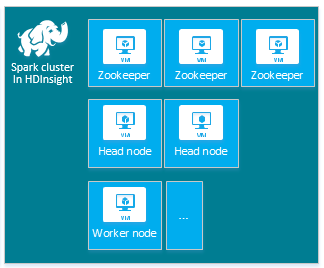
|
Si vous souhaitez en savoir plus, veuillez consulter Configuration de nœud par défaut et tailles de machine virtuelle pour les clusters.
Le coût des clusters HDInsight dépend du nombre de nœuds et des tailles de machine virtuelle pour les nœuds.
Les différents types de clusters ont des types de nœuds, nombres de nœuds et tailles de nœuds différents :
Type de cluster Hadoop par défaut :
- Deux nœuds principaux
- Quatre nœuds Worker
Si vous testez HDInsight, nous vous recommandons d’utiliser un nœud Worker. Pour plus d'informations sur la tarification de HDInsight, consultez la rubrique Tarification HDInsight.
Notes
La limite de taille du cluster varie selon les abonnements Azure. Contactez le support de facturation Azure pour augmenter la limite.
Quand vous utilisez le portail Azure pour configurer le cluster, la taille de nœud est indiquée sous l’onglet Configuration + prix. Dans le portail, vous pouvez également voir le coût associé aux différentes tailles de nœuds.
Tailles de machines virtuelles
Lorsque vous déployez des clusters, choisissez les ressources de calcul en fonction de la solution que vous envisagez de déployer. Les machines virtuelles suivantes sont utilisées pour des clusters HDInsight :
- Machines virtuelles des séries A et D1-4 : Tailles des machines virtuelles Linux à usage général
- Machine virtuelle de la série D11-14 : Tailles de machine virtuelle Linux optimisées pour la mémoire
Pour déterminer la valeur que vous devez utiliser pour spécifier une taille de machine virtuelle au moment de créer un cluster à l’aide des différentes kits SDK ou d’Azure PowerShell, veuillez consulter Tailles de machine virtuelle à utiliser pour les clusters HDInsight. À partir de cet article lié, utilisez la valeur de la colonne Taille des tables.
Important
Si vous avez besoin de plus de 32 nœuds worker dans un cluster, vous devez sélectionner une taille de nœud principal avec au moins 8 cœurs et 14 Go de RAM.
Pour plus d’informations, consultez Tailles des machines virtuelles. Pour plus d’informations sur la tarification des différentes tailles, consultez Tarification de HDInsight.
Attachement de disque
Remarque
Les disques ajoutés sont configurés uniquement pour les répertoires locaux du gestionnaire de nœuds et non pour les répertoires datanode.
Un cluster HDInsight est fourni avec un espace disque prédéfini qui dépend de la version. L'exécution de certaines applications volumineuses peut conduire à un manque d’espace disque, avec l’erreur de disque plein LinkId=221672#ERROR_NOT_ENOUGH_DISK_SPACE et des travaux en échec.
Vous pouvez ajouter des disques supplémentaires en utilisant la nouvelle fonctionnalité de répertoire local de NodeManager. Au moment de créer le cluster Hive et Spark, vous pouvez sélectionner le nombre de disques et les ajouter aux nœuds Worker. Les disques sélectionnés peuvent faire 1 To chacun et font partie de répertoires locaux de NodeManager.
- Sous l’onglet Configuration + tarification, sélectionnez Activer le disque managé.
- Dans Disques standard, entrez le nombre de disques.
- Sélectionnez votre nœud Worker.
Vous pouvez vérifier le nombre de disques sur l’onglet Vérifier + créer, sous Configuration du cluster.
Ajouter l’application
Vous pouvez installer des applications HDInsight sur un cluster HDInsight basé sur Linux. Vous pouvez utiliser des applications fournies par Microsoft ou des tiers ou celles que vous avez développées. Pour plus d’informations, consultez Installer des applications Apache Hadoop tierces sur Azure HDInsight.
La plupart des applications HDInsight sont installées sur un nœud de périmètre vide. Un nœud de périphérie vide est une machine virtuelle Linux qui possède les mêmes outils client que ceux installés dans le nœud principal, avec la même configuration. Vous pouvez utiliser le nœud de périmètre pour accéder au cluster, tester vos applications clientes et héberger vos applications clientes. Pour plus d’informations, consultez Utiliser des nœuds de périmètre vides dans HDInsight.
Actions de script
Vous pouvez installer d’autres composants ou personnaliser la configuration de cluster à l’aide de scripts pendant la création. Ces scripts sont appelés par l’intermédiaire d’actions de script, une option de configuration que vous pouvez utiliser depuis le portail Azure, les cmdlets HDInsight Windows PowerShell ou le kit SDK HDInsight .NET. Si vous souhaitez en savoir plus, veuillez consulter Personnaliser un cluster HDInsight à l’aide d’actions de script.
Certains composants Java natifs, comme Apache Mahout et Cascading, peuvent s’exécuter sur le cluster en tant que fichiers Java Archive (JAR). Vous pouvez distribuer ces fichiers JAR au stockage et les envoyer à aux clusters HDInsight à l’aide des mécanismes de soumission des travaux Hadoop. Pour plus d’informations, consultez Envoi de tâches Apache Hadoop par programmation.
Remarque
En cas de problèmes lors du déploiement ou de l’appel des fichiers JAR sur les clusters HDInsight, contactez le support Microsoft.
HDInsight ne prend pas en charge la mise en cascade et n’est pas éligible au support Microsoft. Pour obtenir la liste des composants pris en charge, consultez la rubrique Nouveautés des versions de cluster fournies par HDInsight.
Vous souhaitez parfois configurer des fichiers de configuration suivants pendant le processus de création :
- clusterIdentity.xml
- core-site.xml
- gateway.xml
- hbase-env.xml
- hbase-site.xml
- hdfs-site.xml
- hive-env.xml
- hive-site.xml
- mapred-site
- oozie-site.xml
- oozie-env.xml
- tez-site.xml
- webhcat-site.xml
- yarn-site.xml
Pour plus d’informations, consultez Personnalisation de clusters HDInsight à l’aide de Bootstrap.