Mettre à l’échelle automatiquement les clusters Azure HDInsight
La fonctionnalité de mise à l’échelle automatique gratuite d’Azure HDInsight peut augmenter ou diminuer automatiquement le nombre de nœuds Worker dans votre cluster en fonction des métriques du cluster et de la stratégie de mise à l’échelle adoptée par les clients. La fonctionnalité de mise à l’échelle automatique consiste à mettre à l’échelle le nombre de nœuds dans des limites prédéfinies, en fonction des métriques de performances ou d’une planification définie d’opérations de scale-up et de scale-down.
Fonctionnement
La fonctionnalité de mise à l’échelle automatique utilise deux types de conditions pour déclencher des événements de mise à l’échelle : des seuils pour diverses métriques de performances de cluster (mise à l’échelle basée sur la charge) et des déclencheurs temporels (mise à l’échelle basée sur la planification). Une mise à l’échelle basée sur la charge modifie le nombre de nœuds dans votre cluster, selon une plage que vous définissez, pour assurer une utilisation optimale de l’UC et réduire les coûts d’exécution. Une mise à l’échelle basée sur la planification change le nombre de nœuds de votre cluster en fonction d’une planification d’opérations de scale-up et de scale-down.
La vidéo suivante fournit une vue d’ensemble des défis que la mise à l’échelle automatique permet de résoudre et comment elle peut vous aider à contrôler les coûts avec HDInsight.
Choix de la mise à l’échelle basée sur la planification ou la charge
La mise à l’échelle basée sur la planification peut être utilisée :
- Lorsque vos travaux sont censés s’exécuter selon des planifications fixes et pendant une durée prévisible ou lorsque vous prévoyez une faible utilisation pendant des heures spécifiques de la journée. Par exemple, les environnements de test et de développement dans les heures post-travail, les travaux de fin de journée.
La mise à l’échelle basée sur la charge peut être utilisée :
- Lorsque les modèles de charge fluctuent de façon significative et imprévisible pendant la journée. Par exemple, le traitement des données de commande avec des fluctuations aléatoires dans les modèles de charge en fonction de divers facteurs.
Métriques de cluster
La mise à l’échelle automatique supervise en permanence le cluster et collecte les métriques suivantes :
| Métrique | Description |
|---|---|
| Total Pending CPU | Nombre total de cœurs nécessaires pour commencer l’exécution de tous les conteneurs en attente. |
| Total Pending Memory | Mémoire totale (en Mo) nécessaire pour commencer l’exécution de tous les conteneurs en attente. |
| Total Free CPU | Somme de tous les cœurs inutilisés sur les nœuds Worker actifs. |
| Total Free Memory | Somme de la mémoire inutilisée (en Mo) sur les nœuds Worker actifs. |
| Used Memory per Node | Charge sur un nœud Worker. Un nœud Worker sur lequel 10 Go de mémoire sont utilisés est considéré comme étant plus sollicité qu’un nœud avec 2 Go de mémoire utilisés. |
| Number of Application Masters per Node | Nombre de conteneurs Application Master (AM) en cours d’exécution sur un nœud Worker. Un nœud Worker hébergeant 2 conteneurs AM est considéré comme plus important qu’un nœud Worker hébergeant 0 conteneur AM. |
Les métriques ci-dessus sont contrôlées toutes les 60 secondes. La fonction de mise à l’échelle automatique prend des décisions de montée en puissance ou de descente en puissance en fonction de ces métriques.
Pour obtenir la liste complète des métriques de cluster, consultez Métriques prises en charge pour Microsoft.HDInsight/clusters.
Conditions de mise à l’échelle basée sur la charge
Lorsque les conditions suivantes sont détectées, la mise à l’échelle automatique émet une requête de mise à l’échelle :
| Scale-up | Scale-down |
|---|---|
| « Total pending CPU » est supérieur à la valeur de « Total free CPU » pendant plus de 3-5 minute. | « Total pending CPU » est inférieur à la valeur de « Total free CPU » pendant plus de 3-5 minutes. |
| « Total pending memory » est supérieur à la valeur de « Total free memory » pendant plus de 3-5 minutes. | « Total pending memory » est inférieur à la valeur de « Total free memory » pendant plus de 3-5 minutes. |
Pour la montée en puissance, la mise à l’échelle automatique émet une demande de montée en puissance pour ajouter le nombre de nœuds requis. La montée en puissance est basée sur le nombre de nœuds Worker nécessaires pour répondre aux besoins actuels en matière d’UC et de mémoire.
Pour la descente en puissance, la mise à l’échelle automatique émet une demande de suppression d’un certain nombre de nœuds. Le scale-down est basé sur le nombre de conteneurs AM (Application Master) par nœud. Et la configuration requise en matière d’UC et de mémoire. Le service détecte également les nœuds à supprimer en fonction de l’exécution des travaux en cours. L’opération de descente en puissance désactive tout d’abord les nœuds, puis les supprime du cluster.
Considérations relatives au dimensionnement de la base de données Ambari pour la mise à l’échelle automatique
Il est recommandé que la base de données Ambari soit correctement dimensionnée pour tirer parti des avantages de la mise à l’échelle automatique. Les clients doivent utiliser le niveau de base de données approprié et utiliser la base de données Ambari personnalisée pour les clusters de grande taille. Lisez les recommandations relatives au dimensionnement de la base de données et du nœud principal.
Compatibilité du cluster
Important
La fonctionnalité de mise à l’échelle automatique d’Azure HDInsight a été mise à la disposition générale le 7 novembre 2019 pour les clusters Spark et Hadoop. Elle incluait des améliorations non disponibles dans la préversion de la fonctionnalité. Si vous avez créé un cluster Spark avant le 7 novembre 2019 et que vous souhaitez utiliser la fonctionnalité de mise à l’échelle automatique dessus, l’approche recommandée consiste à créer un nouveau cluster et enable Autoscale sur le nouveau cluster.
La mise à l’échelle automatique pour Interactive Query (LLAP) a été publiée en vue d’une mise à disposition générale pour HDI 4.0 le 27 août 2020. La mise à l’échelle automatique est disponible uniquement sur les clusters Spark, Hadoop et Interactive Query.
Le tableau suivant décrit les types de cluster et les versions qui sont compatibles avec la fonctionnalité de mise à l’échelle automatique.
| Version | Spark | Hive | Interactive Query | hbase | Kafka |
|---|---|---|---|---|---|
| HDInsight 4.0 sans ESP | Oui | Oui | Oui* | Non | Non |
| HDInsight 4.0 avec ESP | Oui | Oui | Oui* | Non | Non |
| HDInsight 5.0 sans ESP | Oui | Oui | Oui* | Non | Non |
| HDInsight 5.0 avec ESP | Oui | Oui | Oui* | Non | Non |
* Les clusters Interactive Query peuvent uniquement être configurés pour une mise à l’échelle basée sur la planification, et non sur la charge.
Bien démarrer
Créer un cluster avec une mise à l’échelle automatique basée sur la charge
Pour activer la fonctionnalité de mise à l’échelle automatique basée sur la charge, procédez comme suit dans le cadre d’un processus normal de création de cluster :
Sous l’onglet Configuration + tarification, cochez la case
Enable autoscale.Sélectionnez Basé sur la charge sous Type de mise à l’échelle automatique.
Entrez les valeurs prévues pour les propriétés suivantes :
- Nombre de nœuds initial pour le Nœud Worker.
- Nombre min de nœuds Worker.
- Nombre max de nœuds Worker.
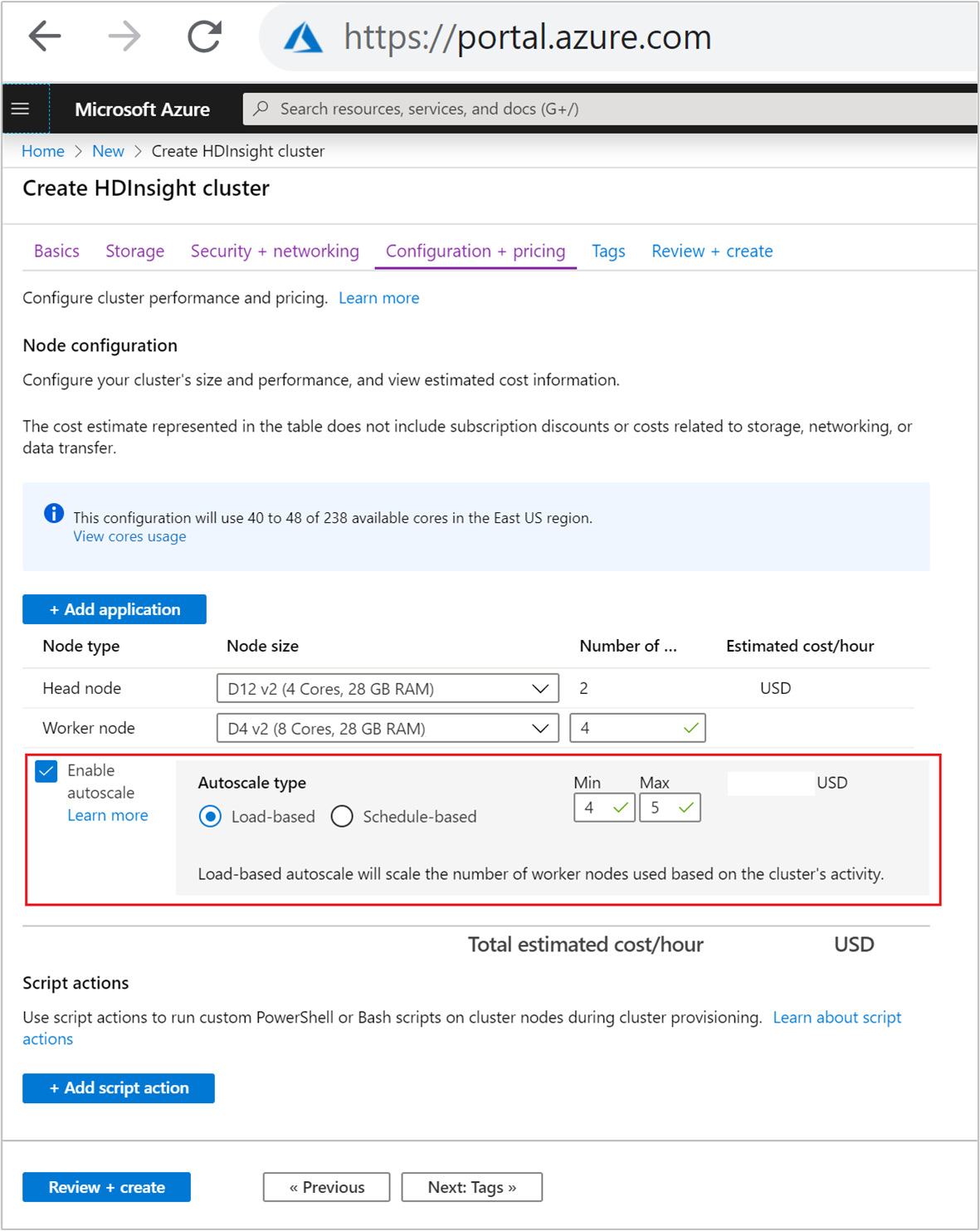
Le nombre initial de nœuds Worker doit se situer entre le minimum et le maximum inclus. Cette valeur définit la taille initiale du cluster lors de sa création. Le nombre minimal de nœuds Worker doit être défini sur au moins trois. La mise à l’échelle de votre cluster à moins de trois nœuds peut entraîner le blocage en mode sans échec en raison d’une réplication de fichiers insuffisante. Pour plus d’informations, consultez Blocage en mode sans échec.
Créer un cluster avec une mise à l’échelle automatique basée sur la planification
Pour activer la fonctionnalité de mise à l’échelle automatique basée sur la planification, procédez comme suit dans le cadre d’un processus normal de création de cluster :
Sous l’onglet Configuration + tarification, cochez la case
Enable autoscale.Entrez le Nombre de nœuds pour le Nœud Worker, qui contrôle la limite de la mise à l’échelle du cluster.
Sélectionnez l’option Basée sur la planification sous Type de mise à l’échelle.
Sélectionnez Configurer pour ouvrir la fenêtre Configuration de la mise à l’échelle automatique.
Sélectionnez votre fuseau horaire, puis cliquez sur + Ajouter une condition
Sélectionnez les jours de la semaine pour lesquels la nouvelle condition doit s’appliquer.
Modifiez l’heure à laquelle la condition doit prendre effet, ainsi que le nombre de nœuds du cluster à mettre à l’échelle.
Ajoutez d’autres conditions si nécessaire.
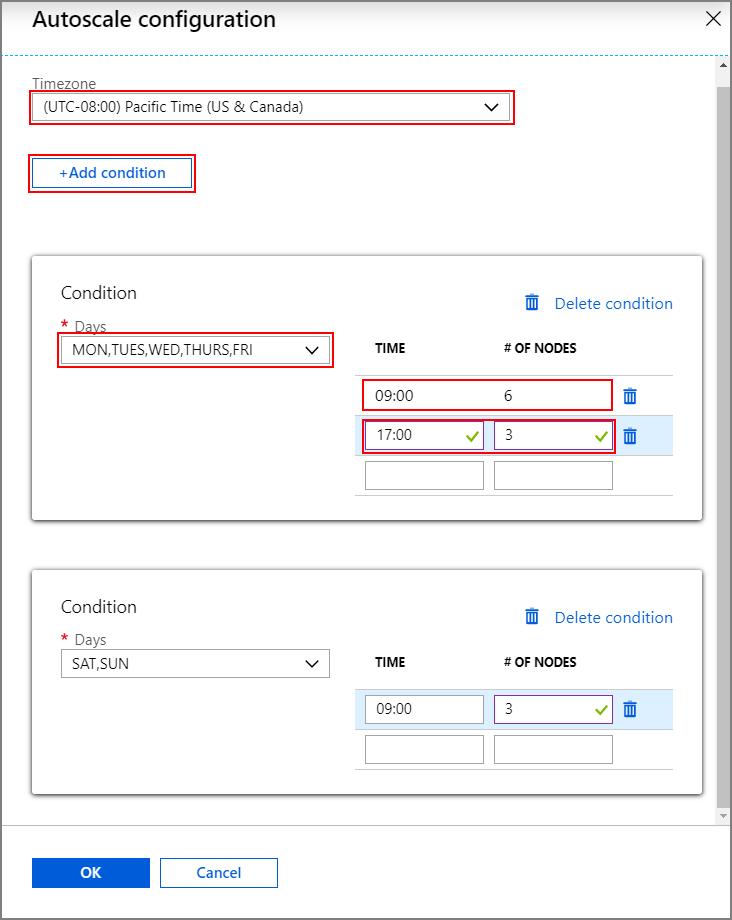
Le nombre de nœuds doit être compris entre 3 et le nombre de nœuds Worker maximal que vous avez entré avant d’ajouter des conditions.
Dernières étapes de la création
Sélectionnez le type de machine virtuelle pour les nœuds Worker en choisissant une machine virtuelle dans la liste déroulante sous Taille du nœud. Après avoir sélectionné le type de machine virtuelle pour chaque type de nœud, vous pouvez voir la fourchette de coûts estimée pour l’ensemble du cluster. Ajustez les types de machine virtuelle selon votre budget.
Votre abonnement a un quota de capacité pour chaque région. Le nombre total de cœurs de vos nœuds principaux et le nombre maximum de nœuds Worker ne peuvent pas dépasser le quota de capacité. Toutefois, ce quota est une limite logicielle ; vous pouvez toujours créer un ticket de support pour l’augmenter aisément.
Notes
Si vous dépassez la limite totale de quota de base, vous recevrez un message d’erreur disant indiquant que le nœud maximum a dépassé les noyaux disponibles dans cette région et que vous devez choisir une autre région ou contacter le support pour augmenter le quota (« the maximum node exceeded the available cores in this region, please choose another region or contact the support to increase the quota »).
Pour plus d’informations sur la création de clusters HDInsight à l’aide du portail Azure, consultez Créer des clusters Linux dans HDInsight à l’aide du portail Azure.
Création d’un cluster avec un modèle Resource Manager
Mise à l’échelle automatique basée sur la charge
Vous pouvez créer un cluster HDInsight avec la mise à l’échelle basée sur la charge d’un modèle Azure Resource Manager en ajoutant un nœud autoscale à la section computeProfile>workernode avec les propriétés minInstanceCount et maxInstanceCount, comme indiqué dans l’extrait de code JSON. Pour obtenir un modèle Resource Manager complet, consultez Modèle de démarrage rapide : Déployer un cluster Spark avec mise à l’échelle automatique basée sur la charge.
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
Mise à l’échelle automatique basée sur la planification
Vous pouvez créer un cluster HDInsight avec la mise à l’échelle basée sur la planification d’un modèle Azure Resource Manager en ajoutant un nœud autoscale à la section computeProfile>workernode. Le nœud autoscale contient un élément recurrence qui a un élément timezone et un élément schedule. Ils vous permettent d’indiquer quand la modification doit avoir lieu. Pour obtenir un modèle Resource Manager complet, consultez Déployer un cluster Spark avec mise à l’échelle automatique basée sur la planification.
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
Activation et désactivation de la mise à l’échelle automatique d’un cluster en cours d’exécution
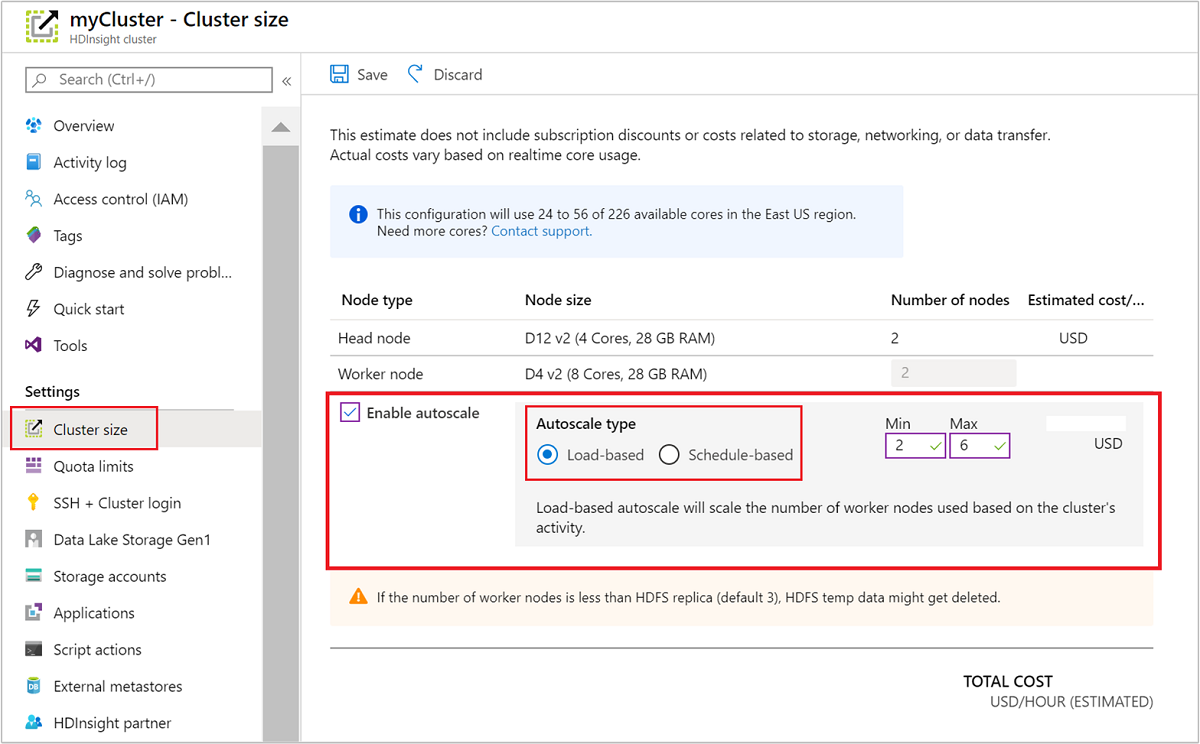
Utilisation du portail Azure
Pour activer la mise à l’échelle automatique sur un cluster en cours d’exécution, sélectionnez Taille du cluster sous Paramètres. Ensuite, sélectionnez Enable autoscale. Choisissez un type de mise à l’échelle automatique, puis entrez les options de mise à l’échelle basée sur la planification ou la charge. Enfin, sélectionnez Enregistrer.
Utilisation de l’API REST
Pour activer ou désactiver la mise à l’échelle automatique sur un cluster en cours d’exécution à l’aide de l’API REST, envoyez une requête POST au point de terminaison de la mise à l’échelle automatique :
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
Utilisez les paramètres appropriés dans la charge utile de la requête. La charge utile JSON ci-dessous peut être utilisée pour enable Autoscale. Utilisez la charge utile {autoscale: null} pour désactiver la mise à l’échelle automatique.
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
Consultez la section précédente sur l’activation de la mise à l’échelle automatique basée sur la charge pour obtenir une description complète de tous les paramètres de charge utile. Il n’est pas recommandé de forcer la désactivation du service de mise à l’échelle automatique sur un cluster en cours d’exécution.
Supervision des activités de mise à l’échelle automatique
État du cluster
L’état du cluster répertorié dans le Portail Microsoft Azure peut vous aider à surveiller les activités de mise à l’échelle automatique.
La liste ci-dessous présente les messages d’état de cluster susceptibles de s’afficher.
| État du cluster | Description |
|---|---|
| Exécution en cours | Le cluster fonctionne normalement. Toutes les activités de mise à l’échelle automatique précédentes sont réussies. |
| Mise à jour | La configuration de la mise à l’échelle automatique du cluster est en cours de mise à jour. |
| Configuration de HDInsight | Une opération de montée ou de descente en puissance de cluster est en cours. |
| Erreur de mise à jour | HDInsight a rencontré des problèmes pendant la mise à jour de la configuration de la mise à l’échelle automatique. Les clients peuvent choisir de réessayer la mise à jour ou de désactiver la mise à l’échelle automatique. |
| Error | Une erreur est survenue dans le cluster. Ce dernier n’est plus utilisable. Supprimez ce cluster et créez-en un autre. |
Pour afficher le nombre actuel de nœuds dans votre cluster, accédez au graphique Taille du cluster sur la page Vue d’ensemble de votre cluster. Ou sélectionnez Taille du cluster sous Paramètres.
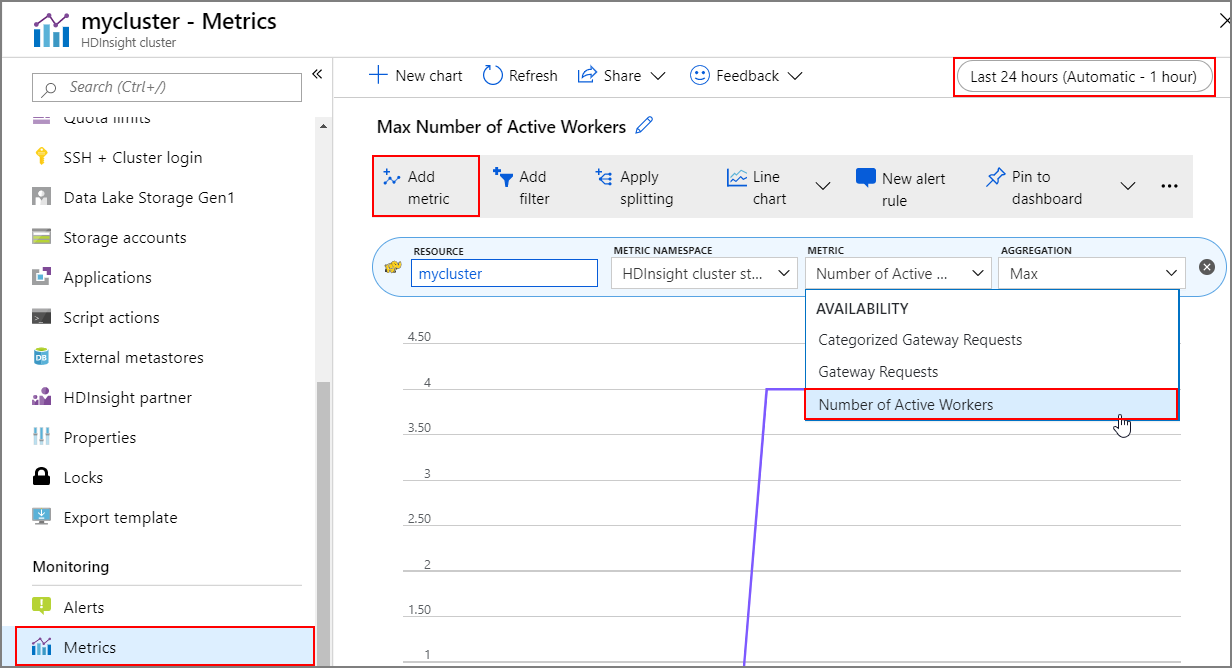
Historique de l’opération
Vous pouvez afficher l’historique de Scale up/Scale down du cluster dans le cadre des métriques de celui-ci. Vous pouvez également dresser la liste de toutes les actions de mise à l’échelle au cours de la journée, de la semaine ou d’une autre période.
Sous Supervision, Métriques. Ensuite, sélectionnez Ajouter une métrique et Nombre de Workers actifs dans la zone de liste déroulante Métrique. Sélectionnez le bouton en haut à droite pour modifier l’intervalle de temps.
Bonnes pratiques
Prendre en compte la latence de la montée et de la descente en puissance
Une opération de mise à l’échelle peut prendre entre 10 et 20 minutes. Intégrez ce délai lorsque vous configurez une planification personnalisée. Par exemple, si vous avez besoin que la taille du cluster soit de 20 à 09h00, définissez le déclencheur de planification sur une heure antérieure, comme 08h30 ou plus tôt, pour que l’opération de mise à l’échelle se termine à 09h00.
Préparation pour la mise à l’échelle vers le bas
Au cours de descente en puissance du cluster, la mise à l’échelle automatique désactivera les nœuds pour atteindre à la taille cible. En cas de mise à l’échelle automatique basée sur la charge, si des tâches sont en cours d’exécution sur ces nœuds, la mise à l’échelle automatique attendra qu’elles soient terminées pour les clusters Spark et Hadoop. Dans la mesure où chaque nœud Worker joue également un rôle dans HDFS, les données temporaires seront décalées vers les nœuds Worker restants. Par conséquent, nous vous conseillons de vérifier que les nœuds restants disposent d’assez d’espace de stockage pour héberger toutes les données temporaires.
Notes
Dans le cas d’une mise à l’échelle automatique basée sur la planification, la désaffectation appropriée n’est pas prise en charge. Cela peut entraîner des échecs de travaux pendant une opération de scale down, et il est recommandé de définir les planifications sur la base des modèles de planification de travail anticipé afin d’inclure suffisamment de temps pour la finalisation des travaux en cours. Vous pouvez définir les planifications en tenant compte de la répartition historique des heures d’achèvement afin d’éviter les échecs de travaux.
Configurer la mise à l’échelle automatique basée sur la planification en fonction du modèle d’utilisation
Vous devez comprendre le modèle d’utilisation de votre cluster au moment de configurer la mise à l’échelle automatique basée sur la planification. Le tableau de bord Grafana peut vous aider à comprendre votre charge de requêtes et vos emplacements d’exécution. Vous pouvez obtenir les emplacements d’exécuteur disponibles et le nombre total d’emplacements d’exécuteur à partir du tableau de bord.
Voici une façon d’estimer le nombre de nœuds Worker qui seront nécessaires. Nous vous recommandons de prévoir une marge supplémentaire de 10 % pour gérer la variation de la charge de travail.
Nombre d’emplacements d’exécuteur utilisés = nombre total d’emplacements d’exécuteur - nombre total d’emplacements d’exécuteur disponibles.
Nombre de nœuds Worker nécessaires = nombre d’emplacements d’exécuteur réellement utilisés / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size).
*hive.llap.daemon.num.executors est configurable et sa valeur par défaut est 4.
*hive.llap.daemon.task.scheduler.wait.queue.size est configurable et sa valeur par défaut est 10.
Actions de script personnalisées
Les actions de script personnalisées sont principalement utilisées pour la personnalisation des nœuds (HeadNode/WorkerNodes) qui permettent à nos clients de configurer certains outils et bibliothèques utilisés par eux. Un cas d’usage courant est que le ou les travaux exécutés sur le cluster peuvent avoir des dépendances sur la bibliothèque tierce appartenant au client et doivent être disponibles sur les nœuds pour que le travail aboutisse. Pour la mise à l’échelle automatique, nous prenons actuellement en charge les actions de script personnalisées qui sont persistantes. Par conséquent, chaque fois que les nouveaux nœuds sont ajoutés au cluster dans le cadre d’une opération de scale-up, ces actions de script persistantes sont exécutées et indiquer que les conteneurs ou travaux leur seraient alloués. Bien que les actions de script personnalisées permettent de démarrer les nouveaux nœuds, il est recommandé de les réduire au minimum, car elles s’ajoutent à la latence globale du scale-up et peuvent avoir un impact sur les travaux planifiés.
Tenez compte de la taille minimale du cluster
Ne mettez pas à l’échelle votre cluster à moins de trois nœuds. La mise à l’échelle de votre cluster à moins de trois nœuds peut entraîner le blocage en mode sans échec en raison d’une réplication de fichiers insuffisante. Pour plus d’informations, consultez Blocage en mode sans échec.
Microsoft Entra Domain Services et opérations de mise à l’échelle
Si vous utilisez un cluster HDInsight avec le Pack Sécurité Entreprise (ESP) qui est joint à un domaine managé par Microsoft Entra Domain Services, nous vous recommandons de limiter la charge sur l’instance Microsoft Entra Domain Services. Dans le cas de la synchronisation étendue de structures de répertoire complexes, nous vous recommandons d’éviter l’impact sur les opérations de mise à l’échelle.
Définissez le nombre maximal de requêtes simultanées dans la configuration Hive pour le scénario d’utilisation maximale
Les événements de mise à l’échelle automatique ne modifient pas la configuration Hive Nombre total maximum de requêtes simultanées dans Ambari. Cela signifie que le service interactif Hive Server 2 ne peut traiter qu’un nombre déterminé de requêtes simultanées à un moment donné, même si le nombre de démons Interactive Query est augmenté et réduit en fonction de la charge et de la planification. La recommandation générale consiste à définir cette configuration pour le scénario d’utilisation maximale afin d’éviter toute intervention manuelle.
Toutefois, vous pouvez rencontrer un échec de redémarrage du serveur Hive 2 s’il n’y a qu’un petit nombre de nœuds Worker et que le nombre maximum total de requêtes simultanées est configuré sur une valeur trop élevée. Au minimum, vous avez besoin du nombre minimal de nœuds Worker pouvant prendre en charge le nombre donné de Tez Ams (égal à la configuration du maximum total de requêtes simultanées).
Limites
Nombre de démons Interactive Query
En cas de clusters Interactive Query avec mise à l’échelle automatique, un événement de scale-up/scale-down automatique augmente ou diminue également le nombre de démons Interactive Query en fonction du nombre de nœuds Worker actifs. La modification du nombre de démons n’est pas conservée dans la configuration num_llap_nodes dans Ambari. Si les services Hive sont redémarrés manuellement, le nombre de démons Interactive Query est réinitialisé conformément à la configuration dans Ambari.
Si le service Interactive Query est redémarré manuellement, vous devez modifier manuellement la configuration num_llap_node (nombre de nœuds nécessaires pour exécuter le démon Interactive Query Hive) sous Advanced hive-interactive-env pour correspondre au nombre de nœuds de Worker actifs. Le cluster Interactive Query prend en charge la mise à l’échelle automatique basée sur la planification uniquement.
Étapes suivantes
En savoir plus sur les instructions de mise à l’échelle manuelle des clusters dans Instructions de mise à l’échelle.