Procedimientos recomendados para usar Azure Data Lake Storage
En este artículo se proporcionan directrices de procedimientos recomendados que le ayudarán a optimizar el rendimiento, reducir los costes y proteger su cuenta de Azure Storage habilitada para Data Lake Storage.
Para obtener sugerencias generales sobre la estructuración de un lago de datos, vea estos artículos:
- Introducción a Azure Data Lake Storage para el escenario de administración y análisis de datos
- Aprovisionamiento de tres cuentas de Azure Data Lake Storage para cada zona de aterrizaje de datos
Localización de documentación
Azure Data Lake Storage no es un servicio dedicado ni un tipo de cuenta. Se trata de un conjunto de funcionalidades que admiten cargas de trabajo analíticas de alto rendimiento. La documentación de Data Lake Storage proporciona procedimientos recomendados e instrucciones para usar estas funcionalidades. Para ver todos los demás aspectos de la administración de cuentas, como la configuración de la seguridad de red, el diseño de alta disponibilidad y la recuperación ante desastres, consulte el contenido de la documentación de Blob Storage.
Evaluación de la compatibilidad de las características y los problemas conocidos
Use el siguiente patrón a medida que configure la cuenta para usar las características de Blob Storage.
Revise el artículo Compatibilidad con la característica Blob Storage en cuentas de Azure Storage para determinar si una característica es totalmente compatible con su cuenta. Algunas características aún no se admiten o tienen compatibilidad parcial en las cuentas habilitadas para Data Lake Storage. La compatibilidad con características siempre se expande, así que asegúrese de revisar periódicamente este artículo para ver si hay actualizaciones.
Revise el artículo Problemas conocidos con Azure Data Lake Storage para ver si hay alguna limitación o guía especial sobre la característica que pretende usar.
Examine los artículos de características para obtener instrucciones específicas para las cuentas habilitadas para Data Lake Storage.
Información sobre los términos usados en la documentación
A medida que se mueve entre conjuntos de contenido, observa algunas pequeñas diferencias de terminología. Por ejemplo, el contenido destacado en la documentación de Blob Storage usará el término blob en lugar del archivo. Técnicamente, los archivos que ingiere en la cuenta de almacenamiento se convierten en blobs en su cuenta. Por lo tanto, el término es correcto. Sin embargo, el término blob puede causar confusión si está acostumbrado al término archivo. También verá el término contenedor, que se usa para hacer referencia a un sistema de archivos. Puede considerar estos términos como sinónimos.
Consideración prémium
Si las cargas de trabajo requieren una latencia coherente baja o un gran número de operaciones de salida de entrada por segundo (IOP), considere la posibilidad de usar una cuenta de almacenamiento de blobs en bloques prémium. Este tipo de cuenta hace que los datos estén disponibles a través de hardware de alto rendimiento. Los datos se almacenan en unidades de estado sólido (SSD) que están optimizadas para baja latencia. Las SSD ofrecen mayor rendimiento en comparación con las unidades de disco duro tradicionales. Los costos de almacenamiento del rendimiento prémium son mayores, pero los costos de transacción son menores. Por lo tanto, si las cargas de trabajo ejecutan una gran cantidad de transacciones, una cuenta de blob en bloques de rendimiento premium puede ser económica.
Si la cuenta de almacenamiento se va a usar para el análisis, se recomienda usar Azure Data Lake Storage junto con una cuenta de almacenamiento de blobs en bloques Premium. Esta combinación de uso de cuentas de almacenamiento de blobs en bloques prémium junto con una cuenta habilitada para Data Lake Storage se conoce como el nivel prémium para Azure Data Lake Storage.
Optimización para la ingesta de datos
Al ingerir datos de un sistema de origen, el hardware de origen, el hardware de red de origen o la conectividad de red a la cuenta de almacenamiento pueden provocar un cuello de botella.
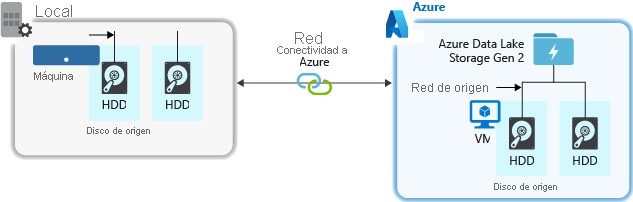
Hardware de origen
Tanto si usa máquinas locales como máquinas virtuales en Azure, asegúrese de seleccionar cuidadosamente el hardware adecuado. En el caso del hardware de disco, considere la posibilidad de usar unidades de estado sólido (SSD) y seleccionar los hardware de disco que tengan los ejes más rápidos. En cuanto al hardware de red, use los controladores de interfaz de red (NIC) más rápidos posibles. En Azure, se recomienda que las máquinas virtuales de Azure D14 tengan el hardware de red y de disco con la capacidad apropiada.
Conectividad de red con la cuenta almacenamiento
La conectividad de red entre los datos de origen y la cuenta datos de almacenamiento a veces puede provocar un cuello de botella. Cuando los datos de origen están en un entorno local, considere la posibilidad de usar un vínculo dedicado con Azure ExpressRoute. Si los datos de origen están en Azure, el rendimiento será el óptimo cuando los datos se encuentren en la misma región de Azure que la cuenta habilitada para Data Lake Storage.
Configuración de herramientas de ingesta de datos para lograr una paralelización máxima
Para lograr el mejor rendimiento, emplee todo el rendimiento disponible realizando tantas lecturas y escrituras en paralelo como sea posible.
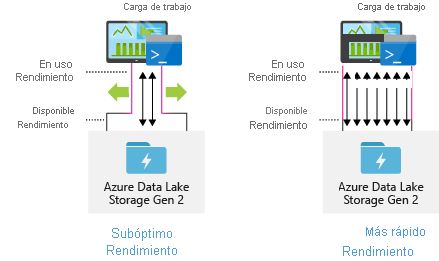
En la tabla siguiente se resume la configuración básica de varias herramientas de ingesta populares.
| Herramienta | Configuración |
|---|---|
| DistCp | -m (mapper) |
| Azure Data Factory | parallelCopies |
| Sqoop | fs.azure.block.size, -m (mapper) |
| AzCopy | AZCOPY_CONCURRENCY_VALUE |
Nota:
El rendimiento general de las operaciones de ingesta depende de otros factores específicos de la herramienta que se usa para ingerir datos. Para obtener una guía actualizada, consulte la documentación de cada herramienta que vaya a utilizar.
Su cuenta se puede escalar para ofrecer el rendimiento necesario para todos los escenarios de análisis. De manera predeterminada, una cuenta habilitada para Data Lake Storage proporciona el rendimiento suficiente en su configuración predeterminada para satisfacer las necesidades de una amplia variedad de casos de uso. Si llega al límite predeterminado, la cuenta Data Lake Storage Gen2 se puede configurar para proporcionar más rendimiento. En ese caso, póngase en contacto con el equipo de Soporte técnico de Azure.
Conjuntos de datos de estructura
Considere la posibilidad de planear previamente la estructura de los datos. El formato de archivo, el tamaño de archivo y la estructura de directorios pueden afectar al rendimiento y al coste.
Formatos de archivo
Los datos se pueden ingerir en distintos formatos. Los datos pueden aparecer en formatos legibles por personas, como JSON, CSV o XML, o como formatos binarios comprimidos, como .tar.gz. Los datos también pueden tener distintos tamaños. Los datos pueden estar compuestos por archivos de gran tamaño (unos pocos terabytes), como los datos de una exportación de una tabla SQL desde los sistemas locales. Los datos también pueden tener la forma de un gran número de archivos diminutos (unos pocos kilobytes), como los datos de eventos en tiempo real de una solución del Internet de las cosas (IoT). Puede optimizar la eficacia y los costes si elige un formato y un tamaño de archivo adecuados.
Hadoop admite un conjunto de formatos de archivo optimizados para almacenar y procesar datos estructurados. Algunos formatos comunes son: Avro, Parquet y Optimized Row Columnar (ORC). Todos estos formatos son formatos de archivo binario legibles por máquina. Se comprimen para ayudarle a administrar el tamaño del archivo. Tienen un esquema incrustado en cada archivo, lo que los hace autodescriptivos. La diferencia entre estos formatos radica en la forma en que se almacenan los datos. Avro almacena los datos en un formato basado en filas y los formatos Parquet y ORC almacenan los datos en formato de columnas.
Considere la posibilidad de utilizar el formato de archivo Avro en los casos en que los patrones de E/S incluyan más actividad de escritura o cuando los patrones de consulta favorezcan la recuperación de varias filas de registros en su totalidad. Por ejemplo, el formato Avro funciona bien con un bus de mensajes como Event Hubs o Kafka que escriben varios eventos o mensajes sucesivos.
Considere la posibilidad de utilizar formatos de archivo Parquet y ORC cuando los patrones de E/S sean más de lectura intensiva y cuando los patrones de consulta se centren en un subconjunto de columnas de los registros. Las transacciones de lectura pueden optimizarse para recuperar columnas específicas en lugar de leer todo el registro.
Apache Parquet es un formato de archivo de código abierto optimizado para canalizaciones de análisis de lectura intensa. La estructura de almacenamiento en columnas de Parquet permite omitir los datos no relevantes. Las consultas son mucho más eficaces porque pueden limitar el ámbito de los datos que se van a enviar desde el almacenamiento hasta el motor de análisis. Además, dado que los tipos de datos similares (para una columna) se almacenan juntos, Parquet admite esquemas de codificación y compresión de datos eficaces que pueden reducir los costos de almacenamiento de datos. Servicios como Azure Synapse Analytics, Azure Databricks y Azure Data Factory tienen funcionalidades nativas que aprovechan los formatos de archivo Parquet.
Tamaño de archivo
Los archivos de mayor tamaño permiten mejorar el rendimiento y reducir los costes.
Normalmente, los motores de análisis como HDInsight tienen una sobrecarga por archivo que implica tareas como enumerar, comprobar el acceso y realizar varias operaciones de metadatos. Si los datos se almacenan en muchos archivos pequeños, puede afectar desfavorablemente al rendimiento. En general, organice los datos en archivos de mayor tamaño para mejorar el rendimiento (tamaño de 256 MB a 100 GB). Algunos motores y aplicaciones podrían tener problemas para procesar eficazmente los archivos que tienen un tamaño superior a 100 GB.
Aumentar el tamaño del archivo también puede reducir los costes de las transacciones. Las operaciones de lectura y escritura se facturan en incrementos de 4 megabytes, por lo que se le cobrará por la operación independientemente de si el archivo contiene 4 megabytes o solo unos pocos kilobytes. Para obtener información sobre precios, consulte Azure Data Lake Storage pricing (Precios de Azure Data Lake Storage).
A veces, las canalizaciones de datos ejercen un control limitado sobre los datos sin procesar, que tienen una gran cantidad de archivos pequeños. En general, se recomienda que el sistema tenga algún tipo de proceso para agregar archivos pequeños en otros más grandes y que así puedan usarlos aplicaciones de nivel inferior. Si está procesando datos en tiempo real, puede usar un motor de transmisión en tiempo real (como Azure Stream Analytics o Spark Streaming) junto con un agente de mensajes (como Event Hubs o Apache Kafka) para almacenar los datos como archivos más grandes. A medida que agrega archivos pequeños en archivos más grandes, considere la posibilidad de guardarlos en un formato optimizado para lectura, como Apache Parquet, para procesarlos en dirección descendente.
Estructura de directorios
Aunque cada carga de trabajo tiene distintos requisitos con respecto al consumo de los datos, estos son algunos diseños habituales que deben tenerse en cuenta al trabajar con escenarios de Internet de las cosas y lotes o cuando se optimiza para los datos de series temporales.
Estructura de IoT
En las cargas de trabajo de IoT, pueden ingerirse una gran cantidad de datos que abarquen numerosos productos, dispositivos, organizaciones y clientes. Es importante planificar previamente el diseño de directorios con el fin de garantizar la organización, la seguridad y un procesamiento eficaz de los datos para los consumidores de nivel inferior. Una plantilla general a tener en cuenta podría tener el siguiente diseño:
- {Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
Por ejemplo, la telemetría de aterrizaje de un motor de un avión del Reino Unido podría ser parecida a la estructura siguiente:
- UK/Planes/BA1293/Engine1/2017/08/11/12/
En este ejemplo, al colocar la fecha al final de la estructura de directorios, puede usar ACL para proteger más fácilmente regiones y asuntos para usuarios y grupos específicos. Si coloca la estructura de fecha al principio, resultará mucho más difícil proteger estas regiones y estos asuntos. Por ejemplo, si quisiera proporcionar acceso solo a los datos del Reino Unido o a determinados planos, tendría que aplicar un permiso independiente para numerosos directorios en cada directorio de hora. Esta estructura también aumentaría exponencialmente el número de directorios con el paso del tiempo.
Estructura de trabajos por lotes
Un enfoque que se usa habitualmente en el procesamiento por lotes es colocar los datos en un directorio "in". Posteriormente, una vez procesados los datos, coloque los nuevos datos en un directorio "out" para que los consuman los procesos de nivel inferior. Esta estructura de directorios se usa a veces con trabajos que requieren el procesamiento de archivos individuales, pero puede que no requieran un procesamiento paralelo masivo con grandes conjuntos de datos. Al igual que en la estructura de IoT que se recomienda anteriormente, una estructura adecuada cuenta con directorios de nivel primario para elementos como regiones o asuntos (por ejemplo, organización, producto o productor). Considere la posibilidad de usar la fecha y la hora en la estructura para permitir una mejor organización, búsquedas filtradas, seguridad y automatización del procesamiento. El nivel de granularidad de la estructura de fecha viene determinado por el intervalo en el que los datos se cargan o procesan como, por ejemplo, cada hora, cada día o incluso mensualmente.
En algunas ocasiones, el procesamiento de archivos es incorrecto debido a datos dañados o a formatos imprevistos. En tales casos, podría resultar útil que la estructura de directorios tuviera una carpeta /bad a la que mover los archivos para inspeccionarlos más a fondo. El trabajo por lotes también puede controlar el informe o notificación de estos archivos incorrectos para una posterior intervención manual. Tenga en cuenta la siguiente estructura de plantilla:
- {Region}/{SubjectMatter(s)}/In/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Out/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Bad/{yyyy}/{mm}/{dd}/{hh}/
Por ejemplo, una empresa de marketing recibe a diario extractos de datos de actualizaciones de los clientes de Norteamérica. Podría tener el aspecto del siguiente fragmento de código antes y después del procesamiento:
- NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
En el caso habitual de procesamiento de datos por lotes directamente en bases de datos como Hive o instancias tradicionales de SQL Database, no se necesitan directorios /in o /out, ya que la salida ya va a una carpeta independiente de la tabla de Hive o la base de datos externa. Por ejemplo, los extractos diarios de los clientes llegarían a sus respectivos directorios. A continuación, un servicio como Azure Data Factory, Apache Oozieo Apache Airflow desencadenaría un trabajo diario de Hive o Spark para procesar y escribir los datos en una tabla de Hive.
Estructura de datos de series temporales
En las cargas de trabajo de Hive, la eliminación de las particiones de los datos de serie temporal puede ayudar a algunas consultas a leer solo un subconjunto de los datos, lo que mejora el rendimiento.
Aquellas canalizaciones que ingieren datos de serie temporal suelen ubicar sus archivos con una nomenclatura estructurada para los archivos y las carpetas. A continuación se muestra un ejemplo común para los datos estructurados por fecha:
/DataSet/YYYY/MM/DD/datafile_YYYY_MM_DD.tsv
Observe que la información de fecha y hora aparece tanto en las carpetas como en el nombre de archivo.
Para la fecha y la hora, el siguiente es un patrón común
/DataSet/YYYY/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
De nuevo, su elección de organización de los archivos y carpetas debería ser la que consiga un tamaño de archivo mayor y un número razonable de archivos en cada carpeta.
Configuración de la seguridad
Empiece por revisar las recomendaciones del artículo Recomendaciones de seguridad para Blob Storage. Encontrará instrucciones de procedimientos recomendados sobre cómo proteger los datos contra borrados accidentales o malintencionados, proteger los datos detrás de un firewall y utilizar Microsoft Entra ID como base de la administración de identidades.
A continuación, revise el artículo Modelo de control de acceso de Azure Data Lake Storage para obtener instrucciones específicas de las cuentas habilitadas para Data Lake Storage. Este artículo le ayuda a comprender cómo usar roles de control de acceso basado en rol (Azure RBAC) junto con las listas de control de acceso (ACL) para aplicar permisos de seguridad en los directorios y archivos de su sistema de archivos jerárquico.
Ingesta, proceso y análisis
Hay muchos orígenes de datos diferentes así como formas en las que esos datos se pueden ingerir en una cuenta habilitada para Data Lake Storage.
Por ejemplo, puede ingerir grandes conjuntos de datos de clústeres de HDInsight y Hadoop o de conjuntos más pequeños de datos ad hoc para la creación de prototipos de aplicaciones. También puede ingerir datos transmitidos que se hayan generado en diversos orígenes, como aplicaciones, dispositivos y sensores. En este tipo de datos, puede usar herramientas para capturar y procesar los datos evento por evento en tiempo real y, a continuación, escribir los eventos por lotes en su cuenta. También puede ingerir registros de servidor web que contengan información como el historial de solicitudes de página. En cuanto a los datos de registro, considere la posibilidad de escribir scripts o aplicaciones personalizados para cargar estos datos, de modo que tenga la flexibilidad de incluir su componente de carga de datos como parte de la aplicación de macrodatos más grande.
Una vez que los datos están disponibles en la cuenta, puede ejecutar análisis sobre esos datos, crear visualizaciones e incluso descargar datos a su máquina local o a otros repositorios, como una base de datos de Azure SQL o una instancia de SQL Server.
En la tabla siguiente se recomiendan herramientas que puede usar para ingerir, analizar, visualizar y descargar datos. Use los vínculos de esta tabla para buscar instrucciones sobre cómo configurar y usar cada herramienta.
Nota:
Esta tabla no refleja la lista completa de servicios de Azure que admiten Data Lake Storage. Para ver una lista de los servicios de Azure admitidos y su nivel de compatibilidad, consulte Servicios de Azure que admiten Azure Data Lake Storage.
Supervisión de la telemetría
La supervisión del uso y el rendimiento es una parte importante de la puesta en marcha del servicio. Algunos ejemplos son las operaciones frecuentes, las operaciones con latencia alta o las operaciones que provocan una limitación del servicio.
Toda la telemetría de la cuenta de almacenamiento está disponible a través de los registros de Azure Storage en Azure Monitor. Esta característica integra la cuenta de almacenamiento con Log Analytics y Event Hubs, al tiempo que permite archivar los registros en otra cuenta de almacenamiento. Para ver la lista completa de registros de métricas y recursos y su esquema asociado, consulte Referencia de datos de supervisión de Azure Storage.
El lugar en el que decida almacenar los registros dependerá de cómo piense acceder a ellos. Por ejemplo, si desea acceder a los registros casi en tiempo real y poder correlacionar los eventos de los registros con otras métricas de Azure Monitor, puede almacenar los registros en un área de trabajo de Log Analytics. Después, consulte los registros mediante consultas KQL y de autor que enumeran la tabla StorageBlobLogs en el área de trabajo.
Si desea almacenar los registros tanto para consultarlos casi en tiempo real como para conservarlos a largo plazo, puede configurar las opciones de diagnóstico para enviar registros a un área de trabajo de Log Analytics y a una cuenta de almacenamiento.
Si desea acceder a los registros a través de otro motor de consultas como Splunk, puede configurar las opciones de diagnóstico para enviar registros a un centro de eventos e ingerir registros desde el centro de eventos al destino elegido.
Los registros de Azure Storage en Azure Monitor pueden habilitarse a través de las plantillas de Azure Portal, PowerShell, CLI de Azure y Azure Resource Manager. En el caso de las implementaciones a escala, Azure Policy se puede usar con compatibilidad total para las tareas de corrección. Para más información, consulte ciphertxt/AzureStoragePolicy.